はじめに
Evision に Nx バックエンドが実装されました
試してみたいと思います
2023/08/02
Evision の 0.1.33 がリリースされたため、更新
実装コード
バックエンドの実装はこちら
CPU で実行
ノートブックの全量はこちら
CPU 実行環境
- MacBook Pro 13 inch, 2019
- CPU 2.4 GHz クアッドコアIntel Core i5
- メモリ 16 GB
- Elixir 1.15.4
- Erlang 26.0.2
- Livebook 0.10.0
セットアップ
まずセットアップします
他のバックエンドと比較するため、 EXLA や Torchx、 Benchee を入れています
Mix.install([
{:benchee, "~> 1.1"},
{:nx, "~> 0.5"},
{:exla, "~> 0.5"},
{:torchx, "~> 0.5"},
{:evision, "~> 0.1.33"},
{:kino, "~> 0.10"}
])
バックエンドの動作確認
各バックエンドが動作することを確認します
バイナリバックエンド
tensor = Nx.tensor([1, 2, 3], type: :f64, backend: Nx.BinaryBackend)
Nx.add(tensor, tensor)
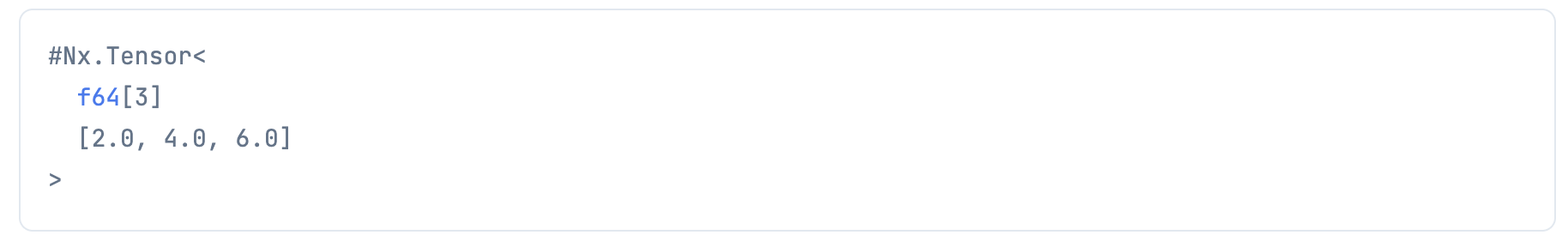
EXLA バックエンド
tensor = Nx.tensor([1, 2, 3], type: :f64, backend: EXLA.Backend)
Nx.add(tensor, tensor)
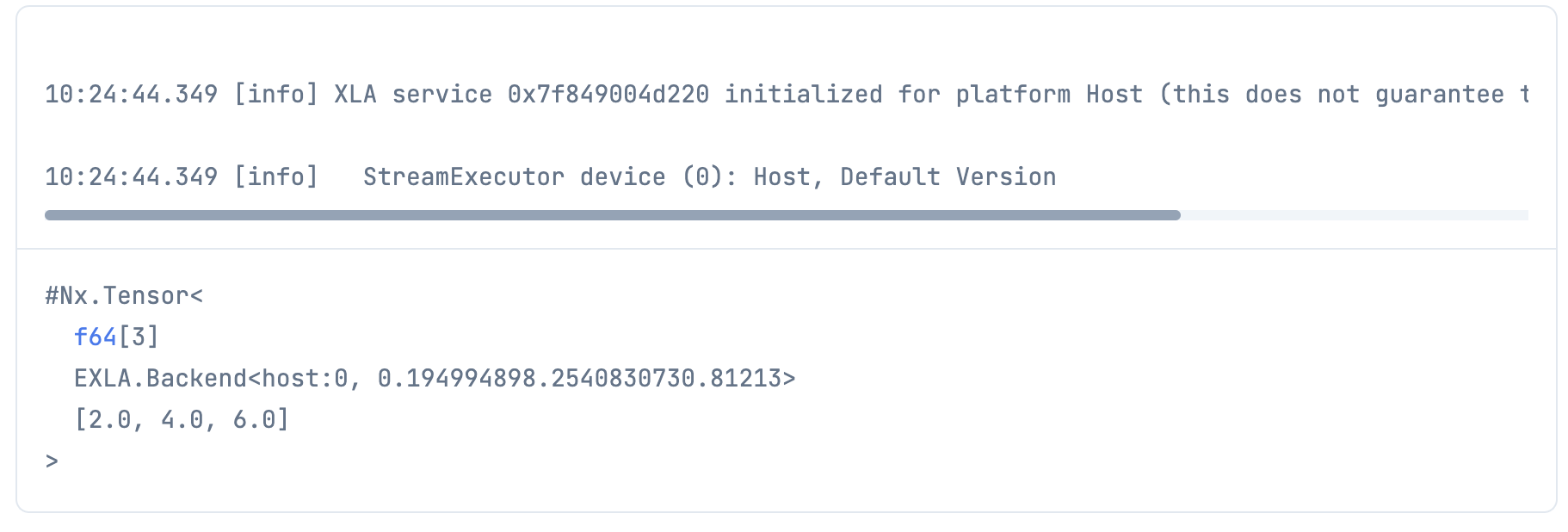
Torchx バックエンド
tensor = Nx.tensor([1, 2, 3], type: :f64, backend: Torchx.Backend)
Nx.add(tensor, tensor)
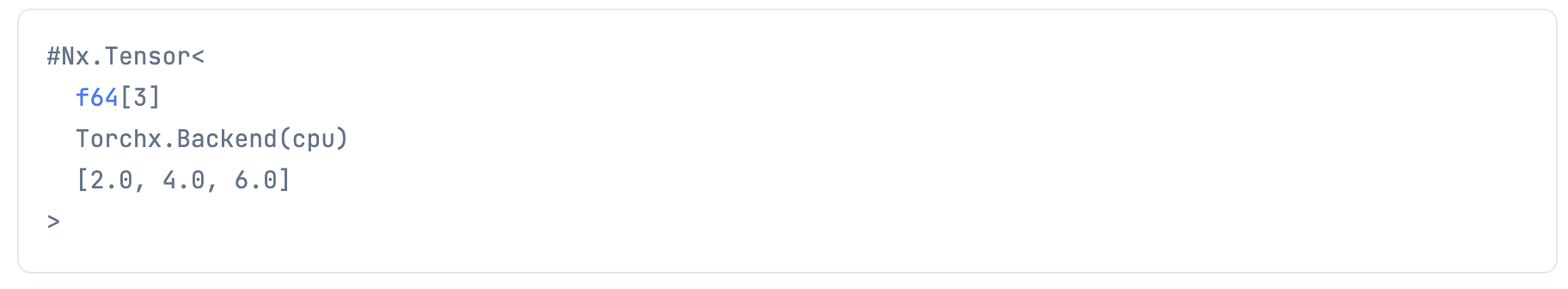
Evision バックエンド
tensor = Nx.tensor([1, 2, 3], type: :f64, backend: Evision.Backend)
Nx.add(tensor, tensor)
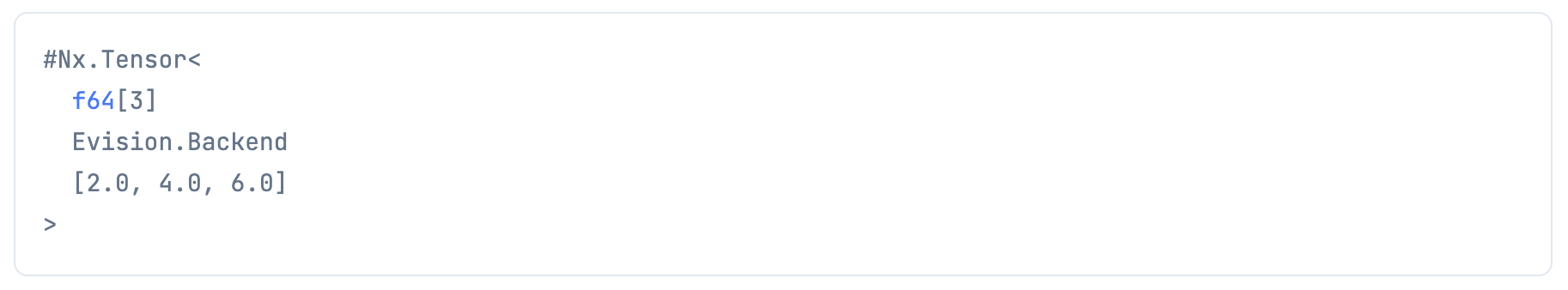
ちなみに、以下の場合はエラーになります
tensor = Nx.tensor([1, 2, 3], backend: Evision.Backend)
Nx.add(tensor, tensor)
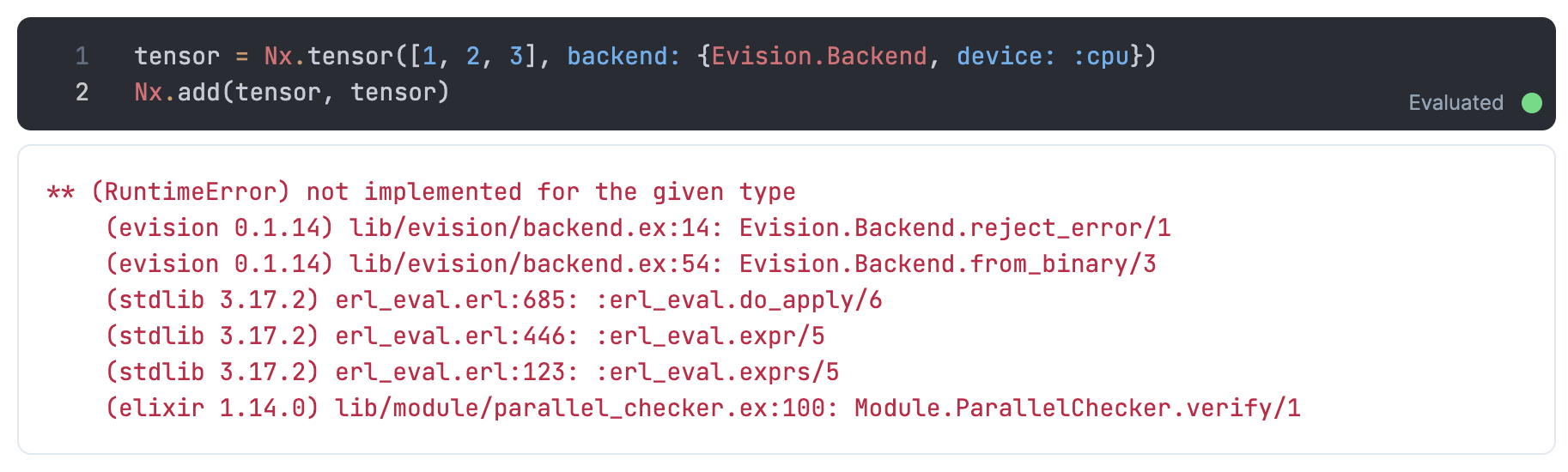
Evision.Backend が s64 型をサポートしていないためです
また、以下の場合もエラーになります
tensor = Nx.tensor([1, 2, 3], type: :f64, backend: Evision.Backend)
Nx.concatenate([tensor, tensor])

これは Evision.Backend が実装していない関数だからです
CPU 環境でのベンチマーク
比較するためにベンチマーク用の関数を用意します
bench = fn backend ->
tensor =
{200, 200}
|> Nx.iota(type: :f64, backend: backend)
Nx.add(tensor, tensor)
end
実行してみます
Benchee.run(%{
"binary" => fn -> bench.(Nx.BinaryBackend) end,
"exla" => fn -> bench.(EXLA.Backend) end,
"torchx" => fn -> bench.(Torchx.Backend) end,
"evision" => fn -> bench.(Evision.Backend) end
})
以下のような結果になりました
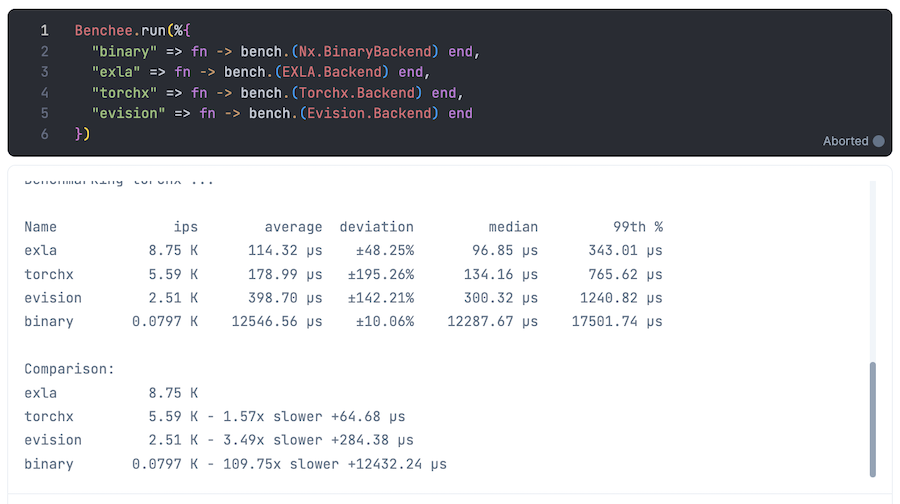
| バックエンド | 実行時間(最速との比) |
|---|---|
| EXLA | 最速 |
| Torchx | 1.57 |
| Evision | 3.49 |
| Binary | 109.75 |
GPU で実行
以下の記事でやったように Google Colaboratory 上で Livebook を起動し、 GPU で動かしてみました
GPU環境のセットアップ
Mix.install(
[
{:benchee, "~> 1.1"},
{:nx, "~> 0.5"},
{:exla, "~> 0.5"},
{:torchx, "~> 0.5"},
{:evision, "~> 0.1.33"},
{:kino, "~> 0.10"}
],
system_env: [
{"XLA_TARGET", "cuda118"},
{"EXLA_TARGET", "cuda"},
{"LIBTORCH_TARGET", "cu116"},
{"EVISION_ENABLE_CUDA", "true"},
{"EVISION_ENABLE_CONTRIB", "true"},
{"EVISION_CUDA_VERSION", "118"}
]
)
GPU環境用ベンチマーク関数
bench = fn backend ->
tensor = Nx.iota({200, 200}, type: :f64, backend: backend)
Nx.add(tensor, tensor)
end
GPU環境ベンチマーク実行
Torchx は CPU も使えるため、 CPU 版も計測しています
Benchee.run(%{
"binary" => fn -> bench.(Nx.BinaryBackend) end,
"exla" => fn -> bench.({EXLA.Backend, device_id: 0}) end,
"torchx_cpu" => fn -> bench.({Torchx.Backend, device: :cpu}) end,
"torchx" => fn -> bench.({Torchx.Backend, device: :cuda}) end,
"evision" => fn -> bench.(Evision.Backend) end
})
GPU環境ベンチマーク実行結果
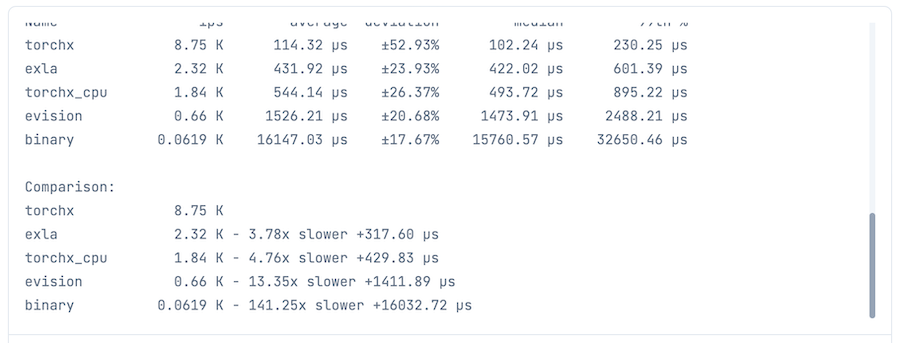
| バックエンド | 実行時間(最速との比) |
|---|---|
| Torchx | 最速 |
| EXLA | 3.78 |
| Torchx(CPU) | 4.76 |
| Evision | 13.35 |
| Binary | 141.25 |
Torchx の CPU と GPU で結構差が出ていますね
まとめ
CPU でも GPU でも Evision.Backend を動かすことができました
型や関数のサポートが一部ないことは気をつけないといけませんね