はじめに
Livebook から AWS のサービスを操作するシリーズです
今回は Amazon Athena を操作します
Athena は S3 上に保存したテキストファイル(CSVやTSV、JSON)を RDB のテーブルに見立て、 SQL を実行できるサービスです
SQL クエリによって 1 TB スキャンしたら $5 という金額なので、かなり安く利用できます
実は私もつい最近このサービスを知ったのですが、いちいちデータベースを作りたくないときに便利そうです
今回は Livebook から S3 上に CSV をアップロードし、 Athena から SQL クエリを実行してみます
実装したノートブックはこちら
事前作業
AWS のアカンウトと、 S3 の権限を持った IAM ユーザーと、その認証情報(ACCESS_KEY_ID と SECRET_ACCESS_KEY)が必要です
実行環境
Livebook 0.7.2 の Docker イメージを元にしたコンテナで動かしました
コンテナ定義はこちらを参照
セットアップ
前回は ex_aws を使いましたが、 ex_aws_athena の最終コミットが4年前でアーカイブされていたため、今回は aws-elixir の方を使ってみます
README には以下のように書いてあります
Most of the code is generated using the aws-codegen library from the JSON descriptions of AWS services provided by Amazon. They can be found in lib/aws/generated.
実は aws-elixir のコードは aws-sdk-go の仕様から自動生成されたものです
ほぼ全てのの AWS サービスをカバーしている代わりに、ドキュメントがあまり親切ではありません
ほとんどの関数の第2引数が input で、これだけ見ても何を渡せばいいのか分かりません
input の詳細な内容は各 API の仕様を見ましょう
Mix.install([
{:aws, "~> 0.13"},
{:uuid, "~> 1.1"},
{:hackney, "~> 1.18"},
{:explorer, "~> 0.3"},
{:kino, "~> 0.7"}
])
エイリアス等の準備をします
alias Explorer.DataFrame
alias Explorer.Series
require Explorer.DataFrame
認証
入力エリアを用意し、そこに IAM ユーザーの認証情報を入力します
ACCESS_KEY_ID と SECRET_ACCESS_KEY は秘密情報なので、値が見えないように Kino.Input.password を使います
access_key_id_input = Kino.Input.password("ACCESS_KEY_ID")
secret_access_key_input = Kino.Input.password("SECRET_ACCESS_KEY")
リージョンもここで入力しておきましょう
region_input = Kino.Input.text("REGION")
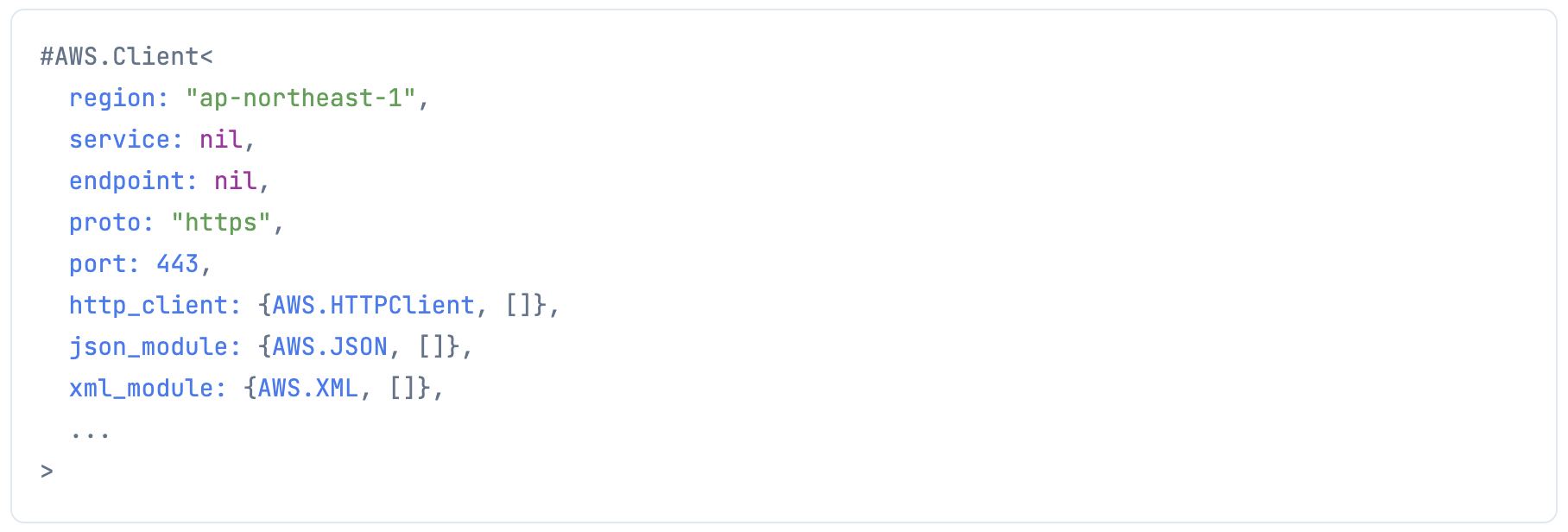
各認証情報を使って、 aws-elixir で AWS にリクエストを投げるためのクライアントを生成します
client =
AWS.Client.create(
Kino.Input.read(access_key_id_input),
Kino.Input.read(secret_access_key_input),
Kino.Input.read(region_input)
)
データ作成
今回は Explorer からワインデータセットを使用します
wine_df = Explorer.Datasets.wine()
wine_df
|> Kino.DataTable.new()

CSV に保存します
csv_filename = "wine.csv"
wine_df
|> DataFrame.to_csv(csv_filename)
データアップロード
アップロード先の S3 バケットを確認します
buckets_res =
client
|> AWS.S3.list_buckets()
|> elem(1)

これでは見にくいので、データテーブルで表示します
buckets_res["ListAllMyBucketsResult"]["Buckets"]["Bucket"]
|> Kino.DataTable.new()

バケット名を入力します
bucket_name_input = Kino.Input.text("BUCKET_ANME")

CSV アップロード先のバケットとパスを指定します
bucket_name = Kino.Input.read(bucket_name_input)
athena_prefix = "athena/"
CSV ファイルを S3 にアップロードします
file = File.read!(csv_filename)
md5 = :crypto.hash(:md5, file) |> Base.encode64()
client
|> AWS.S3.put_object(
bucket_name,
athena_prefix <> csv_filename,
%{"Body" => file, "ContentMD5" => md5}
)

データベース定義
まずデータベースを作成します
(作成せずに default データベースを使っても良いです)
Athena では SQL を実行する度に一意のトークンを求められます
AWS CLI の場合は内部的に生成してくれているのですが、 API を直接呼ぶ場合は自分で生成しないといけません
トークンは 32 〜 128 文字ということなので、 UUID を使います
create_db_query = "CREATE DATABASE athena_sample"
create_db_token = UUID.uuid1()

クエリを実行します
ResultConfiguration の OutputLocation に S3 バケットを指定します(指定しないとエラーになります)
クエリは非同期に実行されるため、即結果が返ってきません
実行結果の QueryExecutionId を使って実行状態を取得する必要があります
exec_id =
client
|> AWS.Athena.start_query_execution(%{
"QueryString" => create_db_query,
"ClientRequestToken" => create_db_token,
"ResultConfiguration" => %{
"OutputLocation" => "s3://#{bucket_name}"
}
})
|> elem(1)
|> then(& &1["QueryExecutionId"])

実行状況を確認します
client
|> AWS.Athena.get_query_execution(%{"QueryExecutionId" => exec_id})
|> elem(1)
|> then(& &1["QueryExecution"]["Status"]["State"])

成功したようです
SQL 実行関数定義
毎回書くのは面倒なので、 SQL 実行と実行状況確認の関数を作っておきます
exec_query = fn query ->
client
|> AWS.Athena.start_query_execution(%{
"QueryString" => query,
"ClientRequestToken" => UUID.uuid1(),
"ResultConfiguration" => %{
"OutputLocation" => "s3://#{bucket_name}"
}
})
|> elem(1)
|> then(& &1["QueryExecutionId"])
end
get_state = fn exec_id ->
client
|> AWS.Athena.get_query_execution(%{"QueryExecutionId" => exec_id})
|> elem(1)
|> then(& &1["QueryExecution"]["Status"]["State"])
end
テーブル作成
次にテーブルを作成します
CSV からよしなに作ってほしいところですが、自分で定義してあげないといけません
再実行時にエラーにならないよう、もしテーブルがあれば削除しておきます
exec_id = exec_query.("DROP TABLE IF EXISTS athena_sample.wine_table")
get_state.(exec_id)

CREATE 文の列名と型をいちいち書きたくないので、データフレームから生成します
列名とタイプのタプル配列を生成します
(列の順序が合っていないといけないため、 names で取得する順で並ぶようにしています)
types =
wine_df
|> DataFrame.names
|> Enum.map(fn name ->
{name, DataFrame.dtypes(wine_df)[name]}
end)

# CREATE 文の列定義を生成
table_columns =
types
|> Enum.map(fn {name, type} ->
name <>
" " <>
case type do
:integer ->
"int"
:float ->
"float"
end
end)
|> Enum.join(",")

CREATE 文を定義して実行します
詳細についてはこちらの記事をご参照ください
exec_id = exec_query.("
CREATE EXTERNAL TABLE
athena_sample.wine_table (#{table_columns})
ROW FORMAT
SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SerDeProperties (
'serialization.format' = ',',
'field.delim' = ','
)
STORED AS TEXTFILE
LOCATION
's3://#{bucket_name}/#{athena_prefix}'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
)
")
CSV の場合、 ROW FORMAT ... 以降を指定しておけばおおよそ問題ありません
LOCATION で CSV をアップロードしたバケット、パスを指定します
get_state.(exec_id)

データ取得
いよいよ SQL でデータを取得してみます
まずは全件全項目です
exec_id = exec_query.("
SELECT
*
FROM
athena_sample.wine_table
")
get_state.(exec_id)

とりあえず成功はしましたが、結果はまた別途取得しないといけません
results =
client
|> AWS.Athena.get_query_results(%{"QueryExecutionId" => exec_id})
|> elem(1)

何やら色々返ってきていますが、 ResultSet の中の ResultSetMetadata に結果の列情報が入っています
ここから各列の名前と型を取得します
# 列名と型を取得
types =
results
|> then(& &1["ResultSet"]["ResultSetMetadata"]["ColumnInfo"])
|> Enum.map(fn info ->
{
info["Name"],
case info["Type"] do
"integer" ->
:integer
"float" ->
:float
_ ->
:string
end
}
end)

また、 ResultSet の Rows に結果の各行が入っています
ただし、先頭行はヘッダーなので無視します
扱いやすいようにデータフレームにしておきましょう
# データを取得
results_df =
results
|> then(& &1["ResultSet"]["Rows"])
|> Enum.map(& &1["Data"])
|> then(fn columns ->
[headers | values] = columns
headers
|> Enum.map(& &1["VarCharValue"])
|> Enum.with_index()
|> Enum.reduce(%{}, fn {col_name, index}, acc ->
col_values =
Enum.map(values, fn each_values ->
each_values
|> Enum.at(index)
|> then(& &1["VarCharValue"])
end)
%{col_name => col_values}
|> Map.merge(acc)
end)
end)
|> DataFrame.new()

取得してきた時点では全列が文字列型になっているので、型情報を元に変換します
parsed_df =
types
|> Enum.reduce(results_df, fn {col_name, col_type}, df ->
DataFrame.mutate_with(df, &%{col_name => Series.cast(&1[col_name], col_type)})
end)

データテーブルで表示してみましょう
parsed_df
|> Kino.DataTable.new()

アップロードした元データと同じく、 178 件取得できました
データ取得も何かと面倒なので、関数化しておきます
get_results = fn exec_id ->
results =
client
|> AWS.Athena.get_query_results(%{"QueryExecutionId" => exec_id})
|> elem(1)
results_df =
results
|> then(& &1["ResultSet"]["Rows"])
|> Enum.map(& &1["Data"])
|> then(fn columns ->
[headers | values] = columns
headers
|> Enum.map(& &1["VarCharValue"])
|> Enum.with_index()
|> Enum.reduce(%{}, fn {col_name, index}, acc ->
col_values =
Enum.map(values, fn each_values ->
each_values
|> Enum.at(index)
|> then(& &1["VarCharValue"])
end)
%{col_name => col_values}
|> Map.merge(acc)
end)
end)
|> DataFrame.new()
results
|> then(& &1["ResultSet"]["ResultSetMetadata"]["ColumnInfo"])
|> Enum.map(fn info ->
{
info["Name"],
case info["Type"] do
"integer" ->
:integer
"float" ->
:float
_ ->
:string
end
}
end)
|> Enum.reduce(results_df, fn {col_name, col_type}, df ->
DataFrame.mutate_with(df, &%{col_name => Series.cast(&1[col_name], col_type)})
end)
end
次は WHERE や ORDER BY を使ってみましょう
exec_id = exec_query.("
SELECT
class,
color_intensity,
flavanoids
FROM
athena_sample.wine_table
WHERE
color_intensity < 5.0
AND flavanoids >= 2.0
ORDER BY
class
")
exec_id
|> get_results.()
|> Kino.DataTable.new()

見事に抽出、ソートができているようです
GROUP BY も使ってみましょう
exec_id = exec_query.("
SELECT
class,
max(alcohol) AS alcohol
FROM
athena_sample.wine_table
GROUP BY
class
ORDER BY
alcohol DESC
")
exec_id
|> get_results.()
|> Kino.DataTable.new()

しっかり集計できていますね
テーブル削除
テーブルを消しておきます
exec_id = exec_query.("DROP TABLE wine_table")
get_state.(exec_id)

データベース削除
データベースを消しておきます
exec_id = exec_query.("DROP DATABASE athena_sample")
get_state.(exec_id)
DataFrame で同じ動作
SQL と同じことを DataFrame でそのままやってみましょう
wine_df
|> DataFrame.filter(color_intensity < 5)
|> DataFrame.filter(flavanoids >= 2.0)
|> DataFrame.arrange(class)
|> DataFrame.select(["class", "color_intensity", "flavanoids"])
|> Kino.DataTable.new()

wine_df
|> DataFrame.group_by("class")
|> DataFrame.summarise(alcohol: max(alcohol))
|> DataFrame.arrange(desc: alcohol)
|> Kino.DataTable.new()

当然できますね
まとめ
というわけで、よほど大きいデータでローカルで開けない、というような事情でもない限り、 Athena は使わないと思います
DataFrame なら SQL 以上に複雑な操作も可能ですしね
(ここまで書いておいて)