はじめに
Livebook から AWS のサービスを操作するシリーズです
今回は AWS S3 を操作します
S3 はクラウドストレージサービスで、低コストで安全・簡単にファイルを保存することができます
今回は Livebook から S3 のファイル一覧を取得して一覧表示したり、画像ファイルをダウンロードしてきて画像処理したりします
実装したノートブックはこちら
事前作業
AWS のアカンウトと、 S3 の権限を持った IAM ユーザーと、その認証情報(ACCESS_KEY_ID と SECRET_ACCESS_KEY)が必要です
実行環境
Livebook 0.7.2 の Docker イメージを元にしたコンテナで動かしました
コンテナ定義はこちらを参照
セットアップ
ExAWS.S3 の hexdocs を参考に必要なモジュールをインストールします
また、ファイル一覧などを表にするために Explorer 、画像ファイルを画像処理するために Evision などもインストールします
Mix.install([
{:ex_aws, "~> 2.0"},
{:ex_aws_s3, "~> 2.0"},
{:poison, "~> 5.0"},
{:hackney, "~> 1.18"},
{:sweet_xml, "~> 0.7"},
{:explorer, "~> 0.3"},
{:evision, "~> 0.1"},
{:download, "~> 0.0.4"},
{:kino, "~> 0.7"},
])
エイリアス等の準備をします
alias ExAws.S3
alias Explorer.DataFrame
alias Explorer.Series
require Explorer.DataFrame
認証
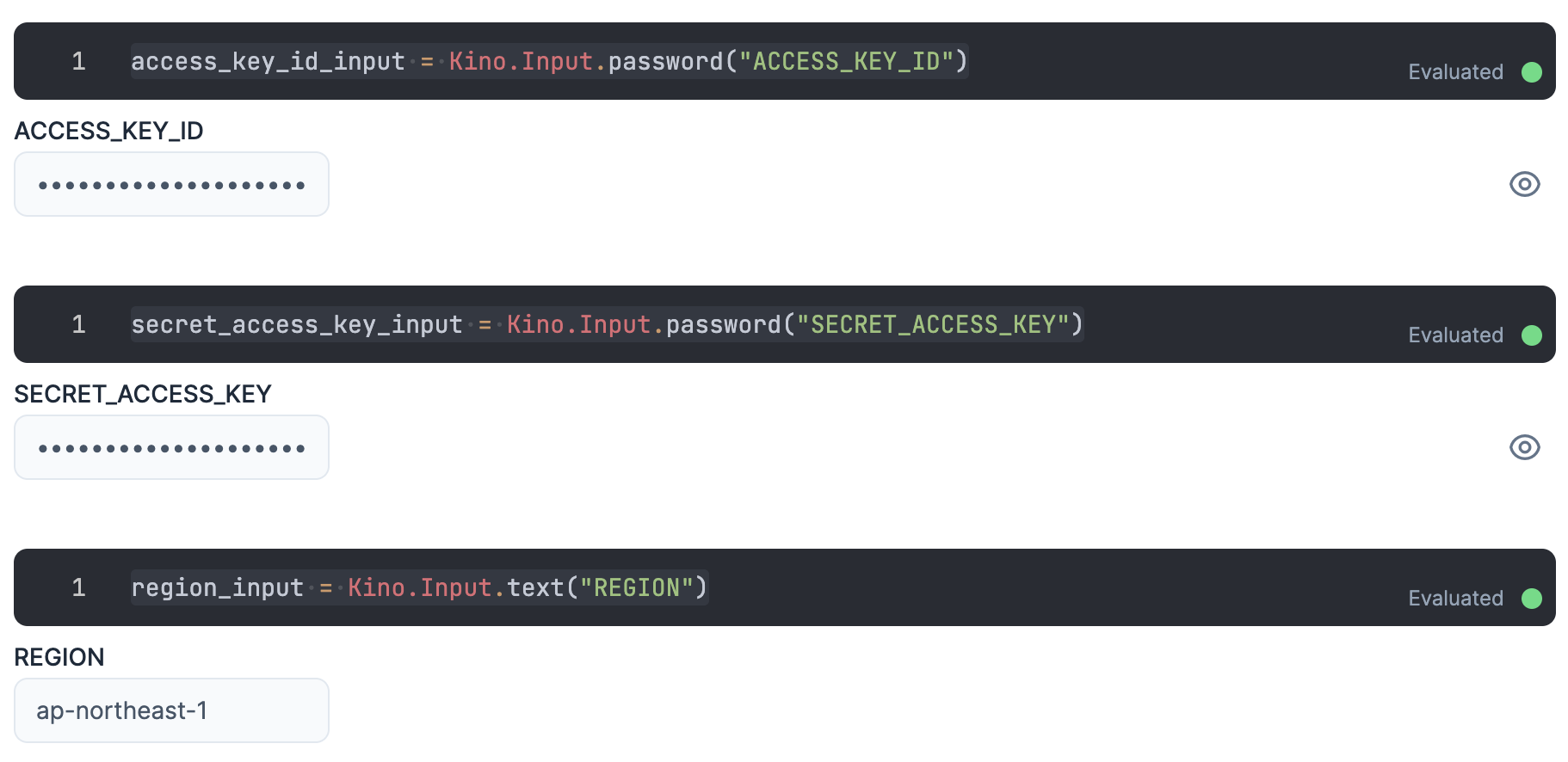
入力エリアを用意し、そこに IAM ユーザーの認証情報を入力します
ACCESS_KEY_ID と SECRET_ACCESS_KEY は秘密情報なので、値が見えないように Kino.Input.password を使います
access_key_id_input = Kino.Input.password("ACCESS_KEY_ID")
secret_access_key_input = Kino.Input.password("SECRET_ACCESS_KEY")
操作対象にする S3 のバケットのリージョンもここで入力しておきましょう
region_input = Kino.Input.text("REGION")
各認証情報を ExAws に渡すためにまとめておきます
秘密情報が実行結果に現れないよう、セルの最後には "dummy" を入れておきましょう
auth_config = [
access_key_id: Kino.Input.read(access_key_id_input),
secret_access_key: Kino.Input.read(secret_access_key_input),
region: Kino.Input.read(region_input)
]
"dummy"
バケット一覧の取得
操作は基本的に AWS CLI の aws s3api と同じように実行できます
操作を指定するコードの後に ExAws.request を入れることで、実行されます
このとき第2引数に認証情報を渡します
S3.list_buckets()
|> ExAws.request(auth_config)
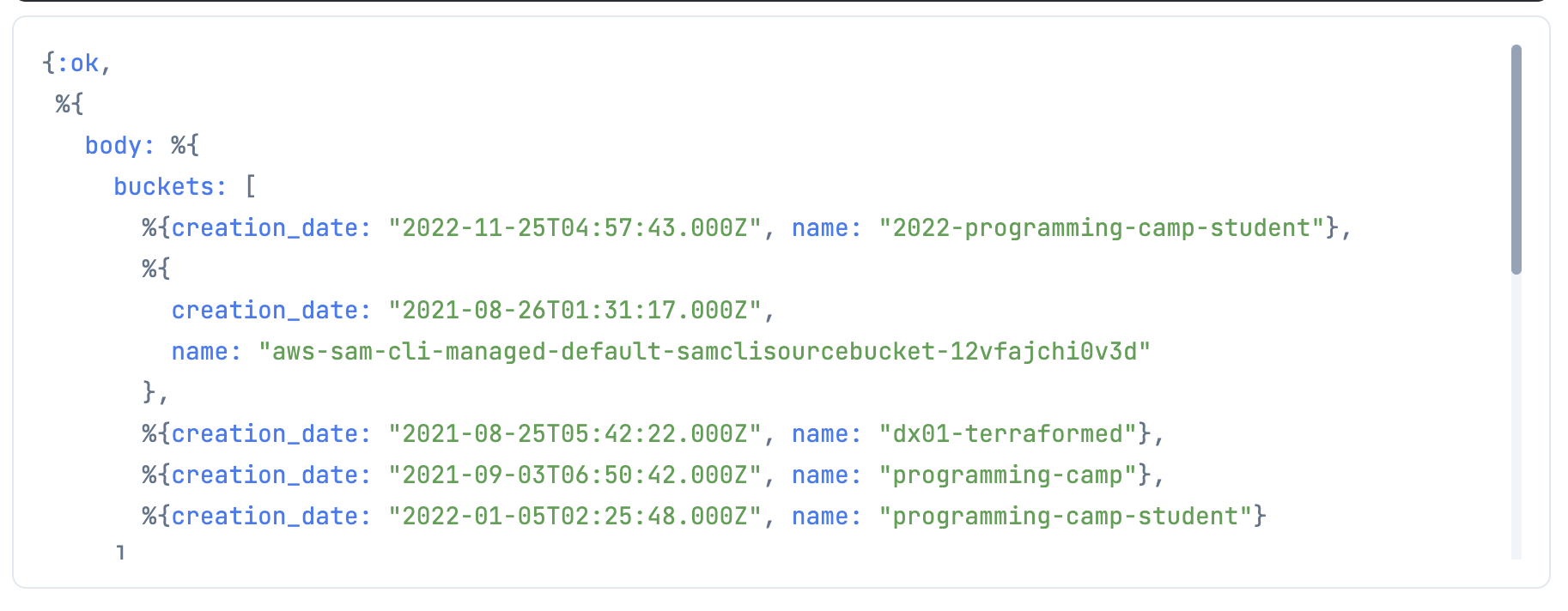
body の buckets の中にバケットの一覧が返ってきていますね
これだと見にくいので、 Explorer を使って一覧を表にしましょう
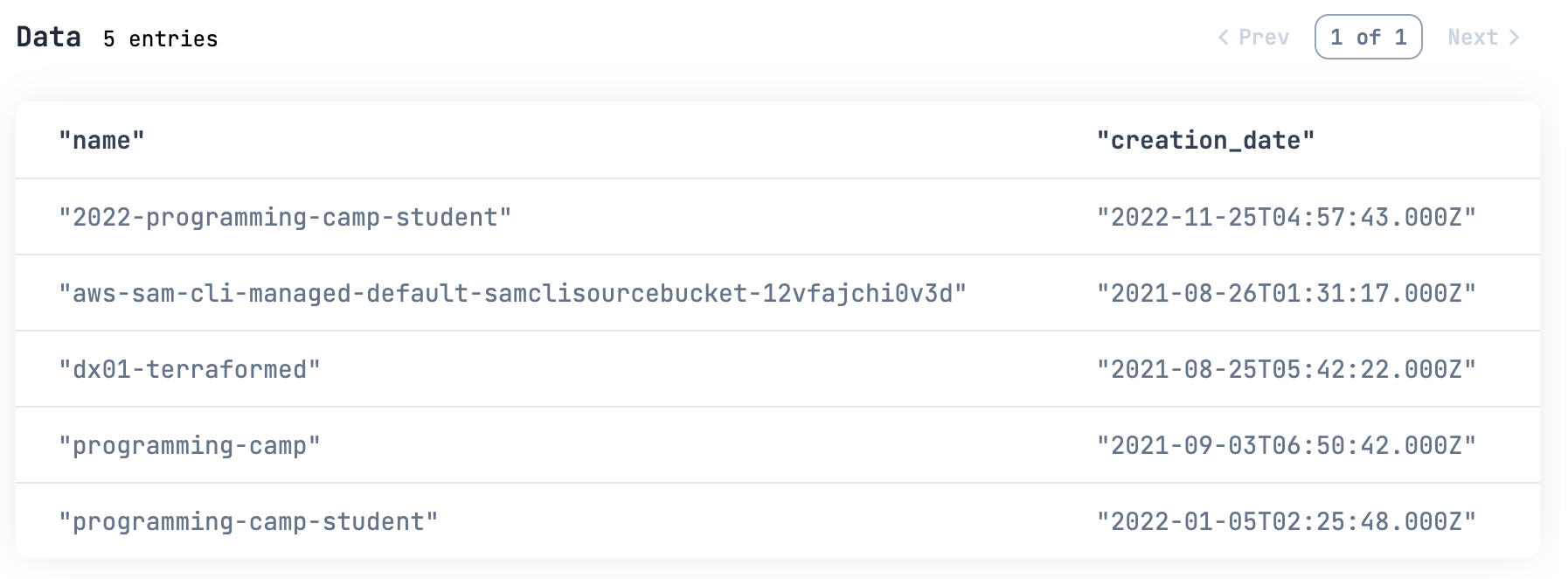
S3.list_buckets()
|> ExAws.request!(auth_config)
|> then(& &1.body.buckets)
|> DataFrame.new()
|> DataFrame.select(["name", "creation_date"])
|> Kino.DataTable.new()
ファイル一覧の取得
バケット名を入力します
bucket_name_input = Kino.Input.text("BUCKET_ANME")
S3.list_objects_v2 を使って、バケット内のファイル一覧を取得します
今回使ったバケットは実際にはファイルが 100 件未満なので、 max_keys をあえて指定して、最初の 20 件だけを取得してみましょう
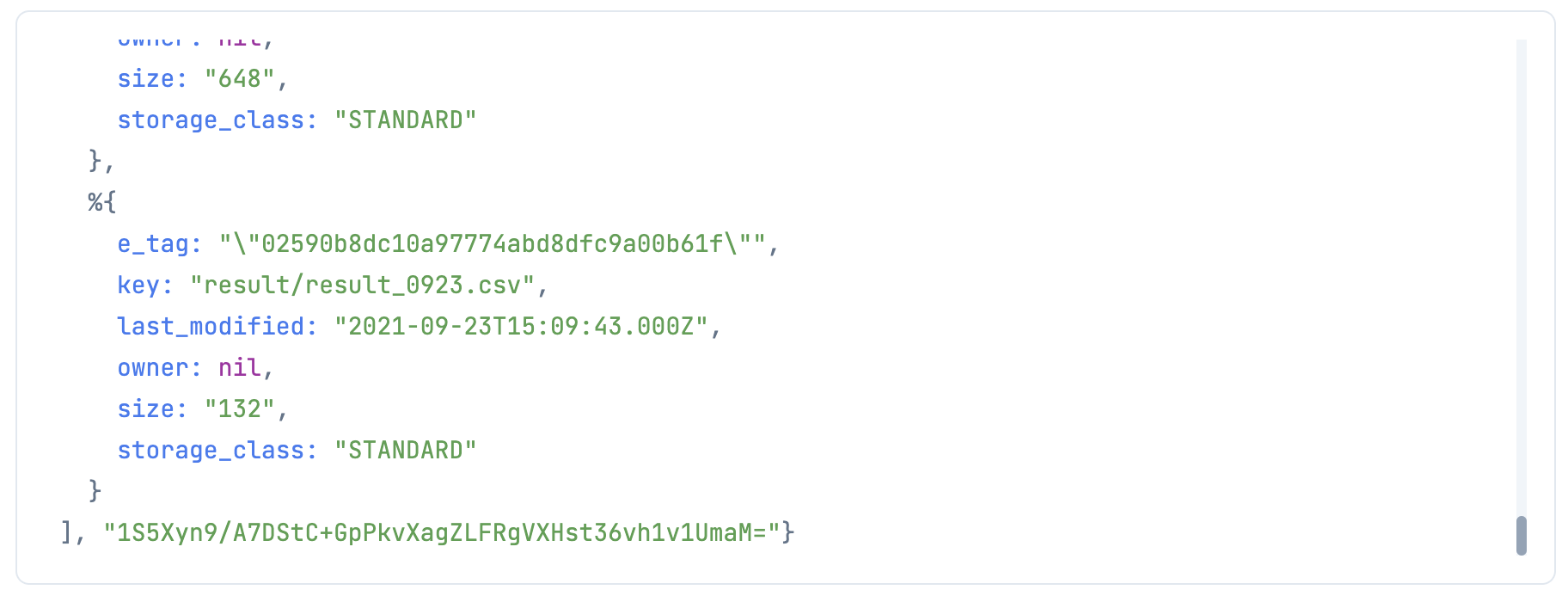
{contents, next_continuation_token} =
bucket_name_input
|> Kino.Input.read()
|> S3.list_objects_v2(max_keys: 20)
|> ExAws.request!(auth_config)
|> then(&{&1.body.contents, &1.body.next_continuation_token})
body.contents にファイルの一覧、 body.next_continuation_token に、次のページを取得するためのトークンが入っています
continuation_token に取得したトークンを渡して、次の 20 件を取得してみましょう
bucket_name_input
|> Kino.Input.read()
|> S3.list_objects_v2(max_keys: 20, continuation_token: next_continuation_token)
|> ExAws.request!(auth_config)
|> then(&{&1.body.contents, &1.body.next_continuation_token})

ファイルは40件以上あるため、まだ次のページ用トークンが返ってきます
全件取得するためには、トークンが空文字になるまで再帰的に呼び出さなければなりません
再帰処理用のモジュールを作ります
defmodule S3LS do
def get_contents(continuation_token, bucket_name, auth_config) do
bucket_name
|> S3.list_objects_v2(max_keys: 20, continuation_token: continuation_token)
|> ExAws.request!(auth_config)
|> then(&{&1.body.contents, &1.body.next_continuation_token})
end
def get_contents_cyclic(continuation_token, bucket_name, auth_config) do
{contents, next_token} =
get_contents(continuation_token, bucket_name, auth_config)
case next_token do
# 空であれば次ページを取得しない
"" ->
contents
# 空以外の場合は次ページを取得する
_ ->
contents ++ get_contents_cyclic(next_token, bucket_name, auth_config)
end
end
def get_all_contents(bucket_name, auth_config) do
get_contents_cyclic(nil, bucket_name, auth_config)
end
end
実行してみましょう
all_contents =
bucket_name_input
|> Kino.Input.read()
|> S3LS.get_all_contents(auth_config)
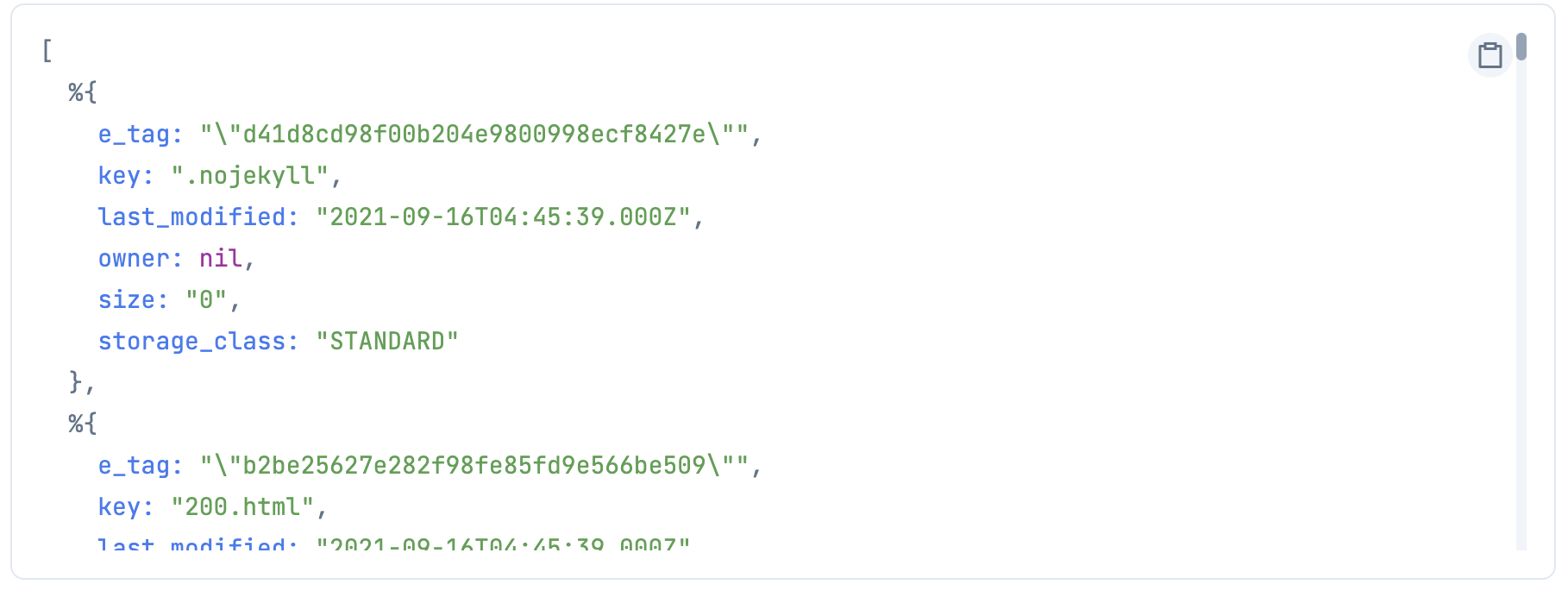
ちゃんと全件取れたか分からないので、これも表にしてみましょう
また、このままだとファイルサイズや最終更新日が文字列になっているため、数値と日時に変換しておきます
all_contents_df =
all_contents
|> DataFrame.new()
|> DataFrame.select(["key", "last_modified", "size"])
# サイズを数値に変換
|> DataFrame.mutate(size: cast(size, :float))
# 最終更新日を日付に変換
|> then(fn df ->
DataFrame.put(
df,
"last_modified",
df["last_modified"]
|> Series.transform(fn input ->
NaiveDateTime.from_iso8601!(input)
end)
)
end)
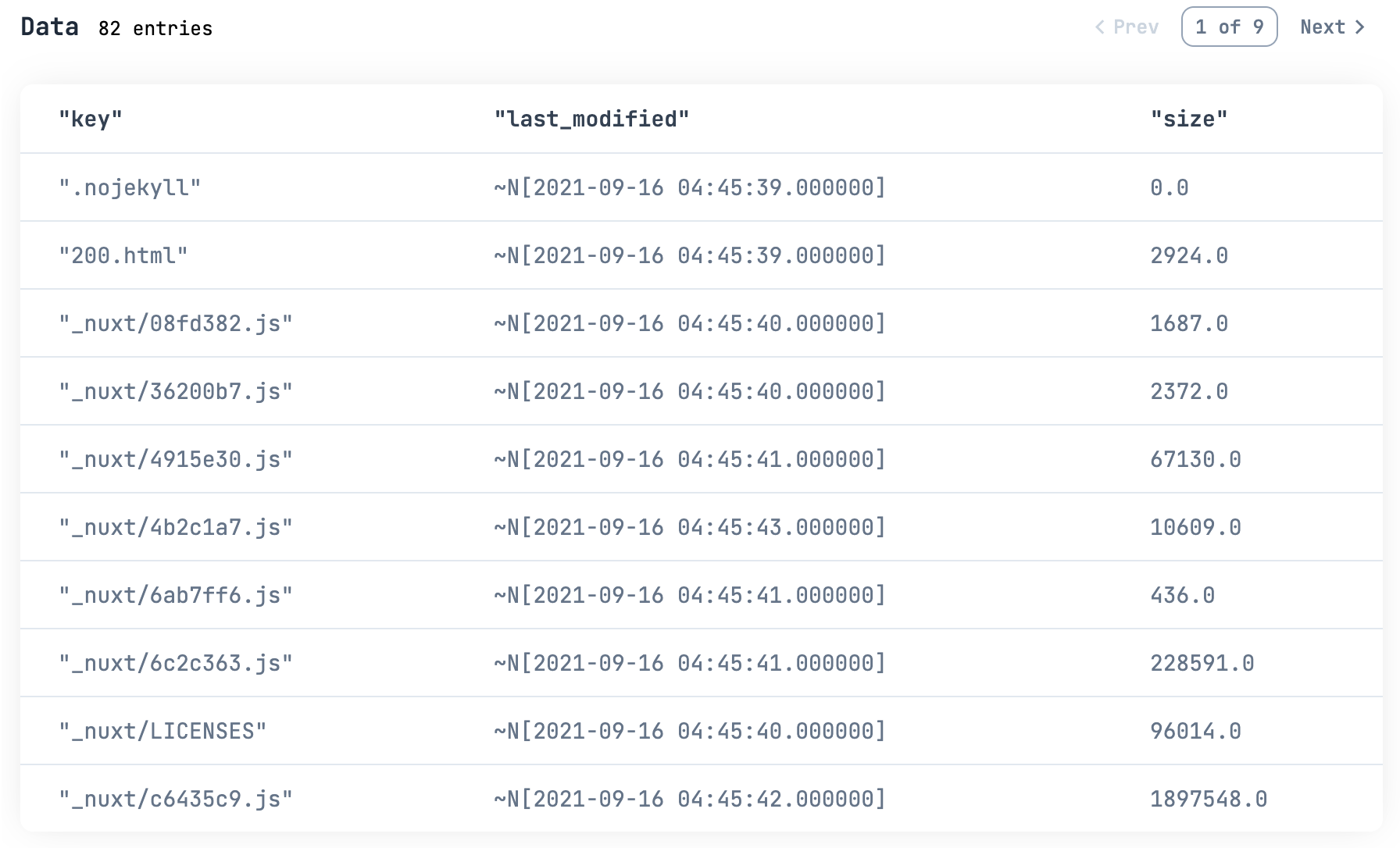
all_contents_df
|> Kino.DataTable.new()
ファイルは 82 件、全部取れたようです
ファイルサイズの合計を見てみましょう
all_contents_df["size"]
|> Series.sum()

およそ 26.5 MB です
続いて最大サイズ
all_contents_df["size"]
|> Series.max()

およそ 1.8 MB です
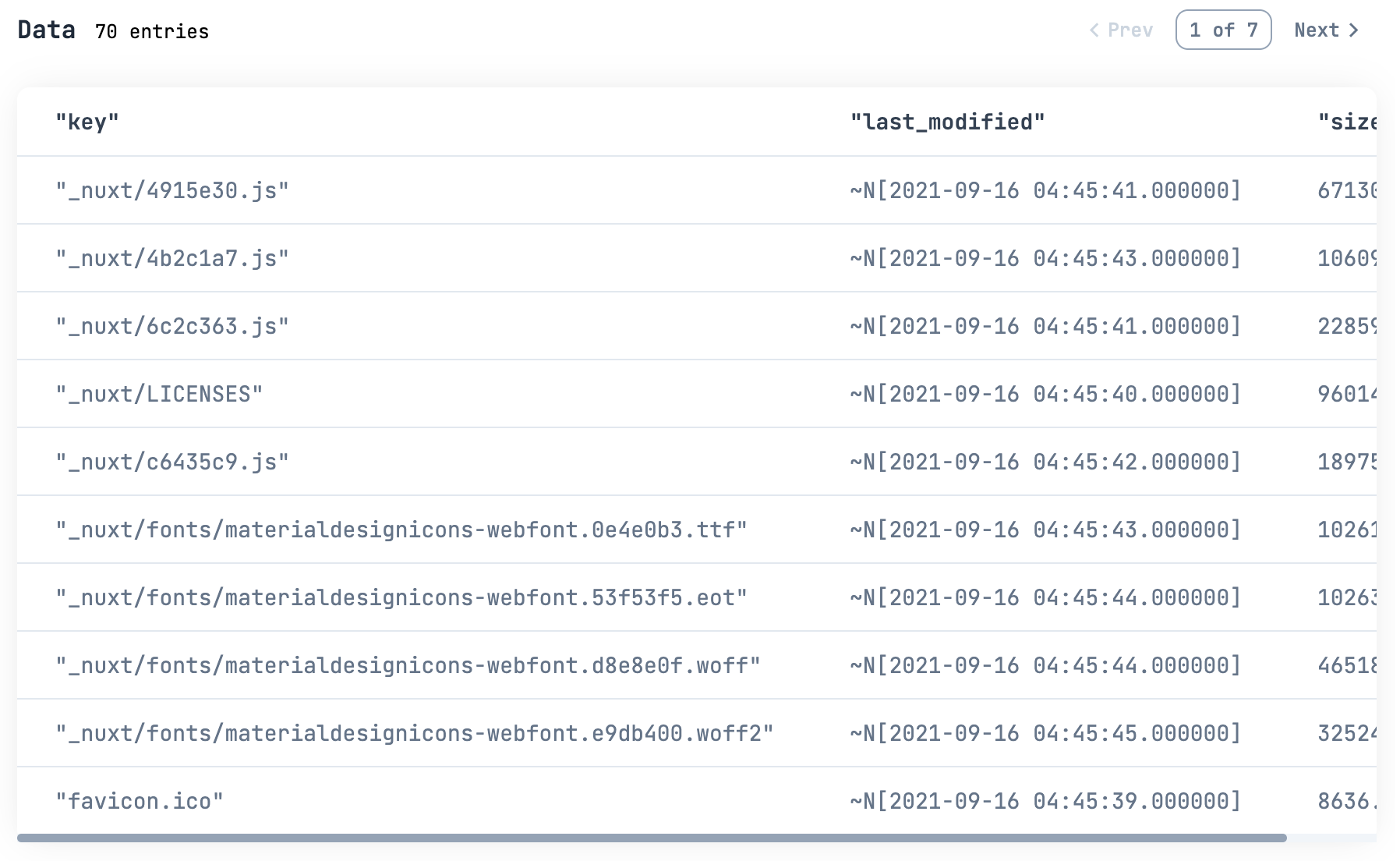
例えば 5,000 バイト以上のファイル一覧を見たい場合は
all_contents_df
|> DataFrame.filter(size > 5_000)
|> Kino.DataTable.new()
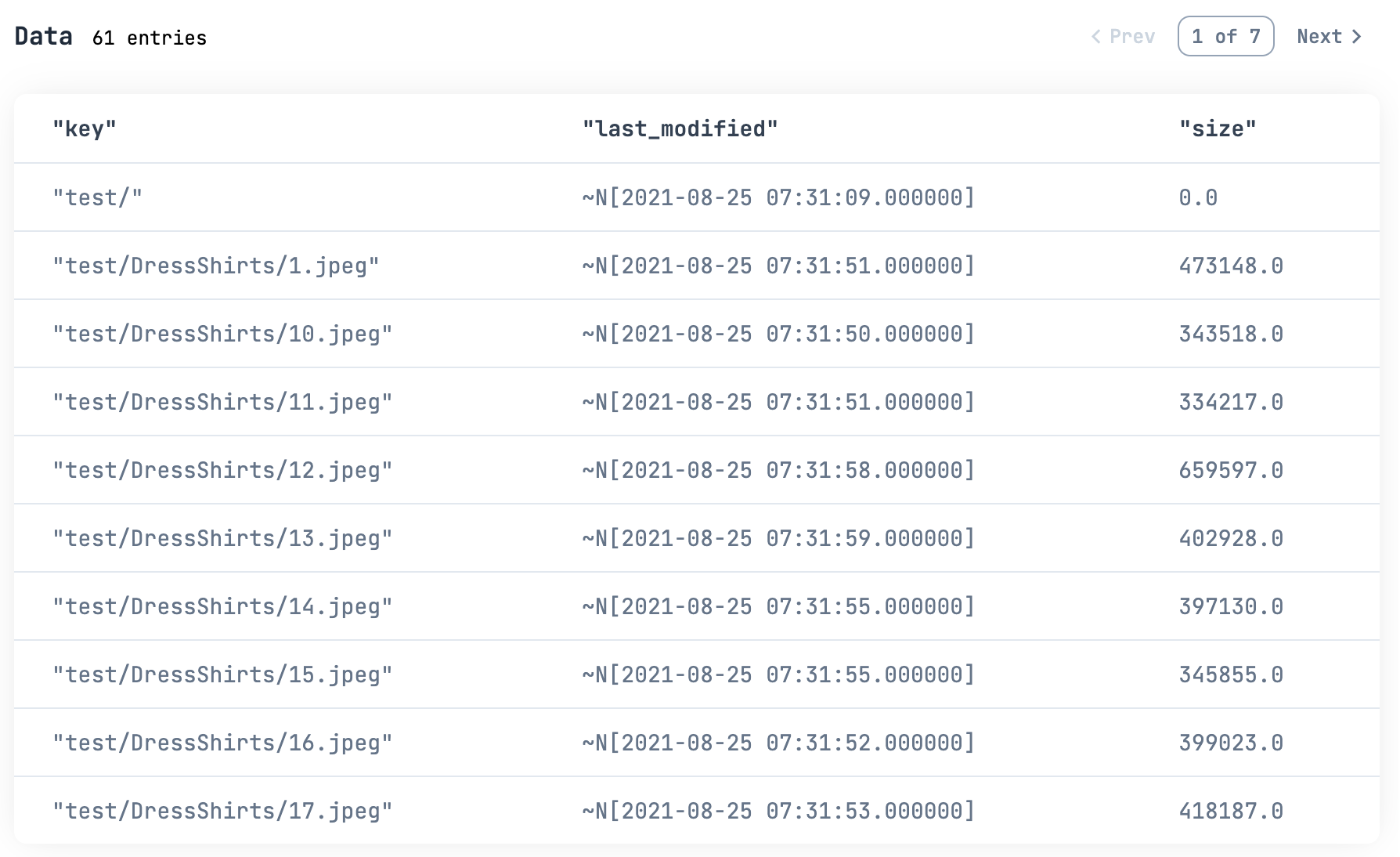
2021/9/1 以降更新されていないファイルは
all_contents_df
|> DataFrame.filter(last_modified < ~N[2021-09-01 00:00:00])
|> Kino.DataTable.new()
一番上の階層毎のファイル数、ファイルサイズ合計は
all_contents_df
|> then(fn df ->
DataFrame.put(
df,
"dir",
df["key"]
|> Series.transform(fn input ->
paths = String.split(input, "/")
case Enum.count(paths) do
1 ->
""
_ ->
Enum.at(paths, 0)
end
end)
)
end)
|> DataFrame.group_by(["dir"])
|> DataFrame.summarise(size: sum(size))
|> DataFrame.arrange(desc: size)
|> Kino.DataTable.new()
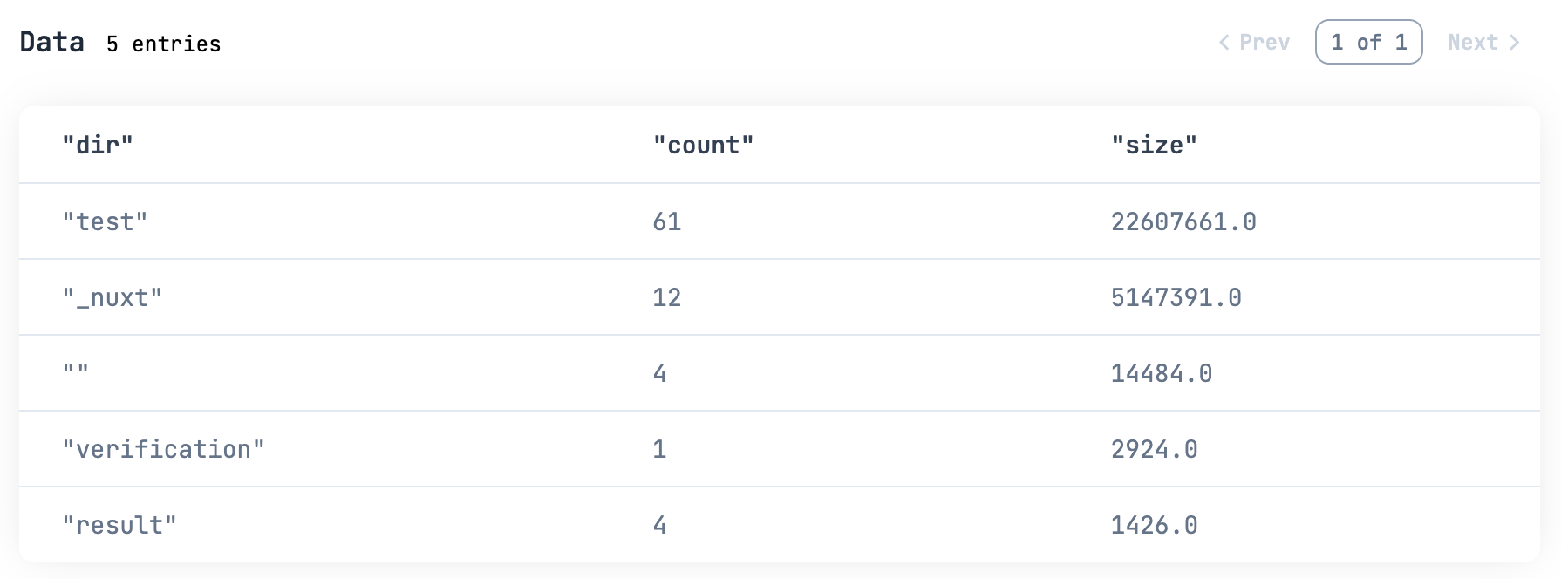
こんな感じで色々分析できます
ファイルアップロード
S3 にファイルをアップロードします
まず、アップロード用のファイル(いつもの Lenna さん)をインターネット上からダウンロードしてきます
File.rm("Lenna_%28test_image%29.png")
lenna =
Download.from("https://upload.wikimedia.org/wikipedia/en/7/7d/Lenna_%28test_image%29.png")
|> elem(1)

lenna がファイル名になりました
ファイル名を指定してファイルをアップロードします
lenna
|> S3.Upload.stream_file
|> S3.upload(Kino.Input.read(bucket_name_input), "lenna.png")
|> ExAws.request!(auth_config)
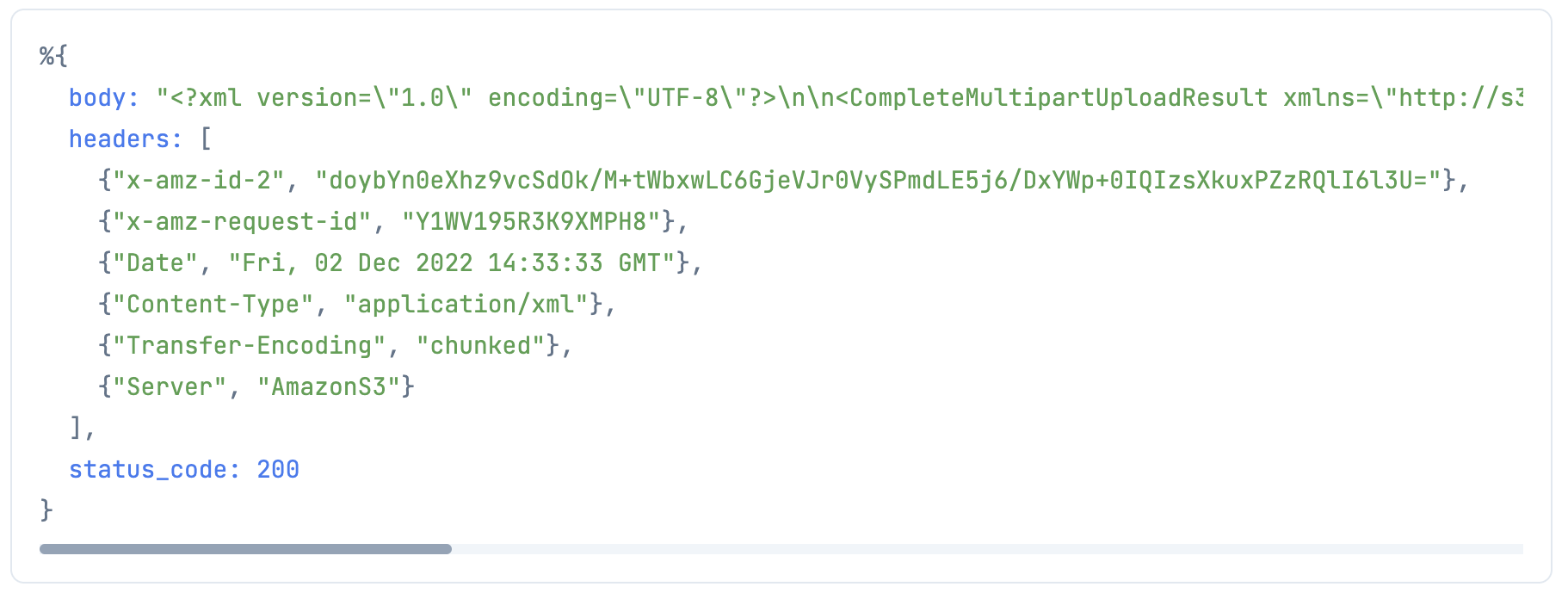
status_code が 200 なので、成功したようです
続いて、インメモリに読み込んだバイナリデータをアップロードします
(これができれば、一々ローカルにファイルを保存せずにアップロードできます)
まず、ファイルを Evision で読み込みます
mat = Evision.imread(lenna)
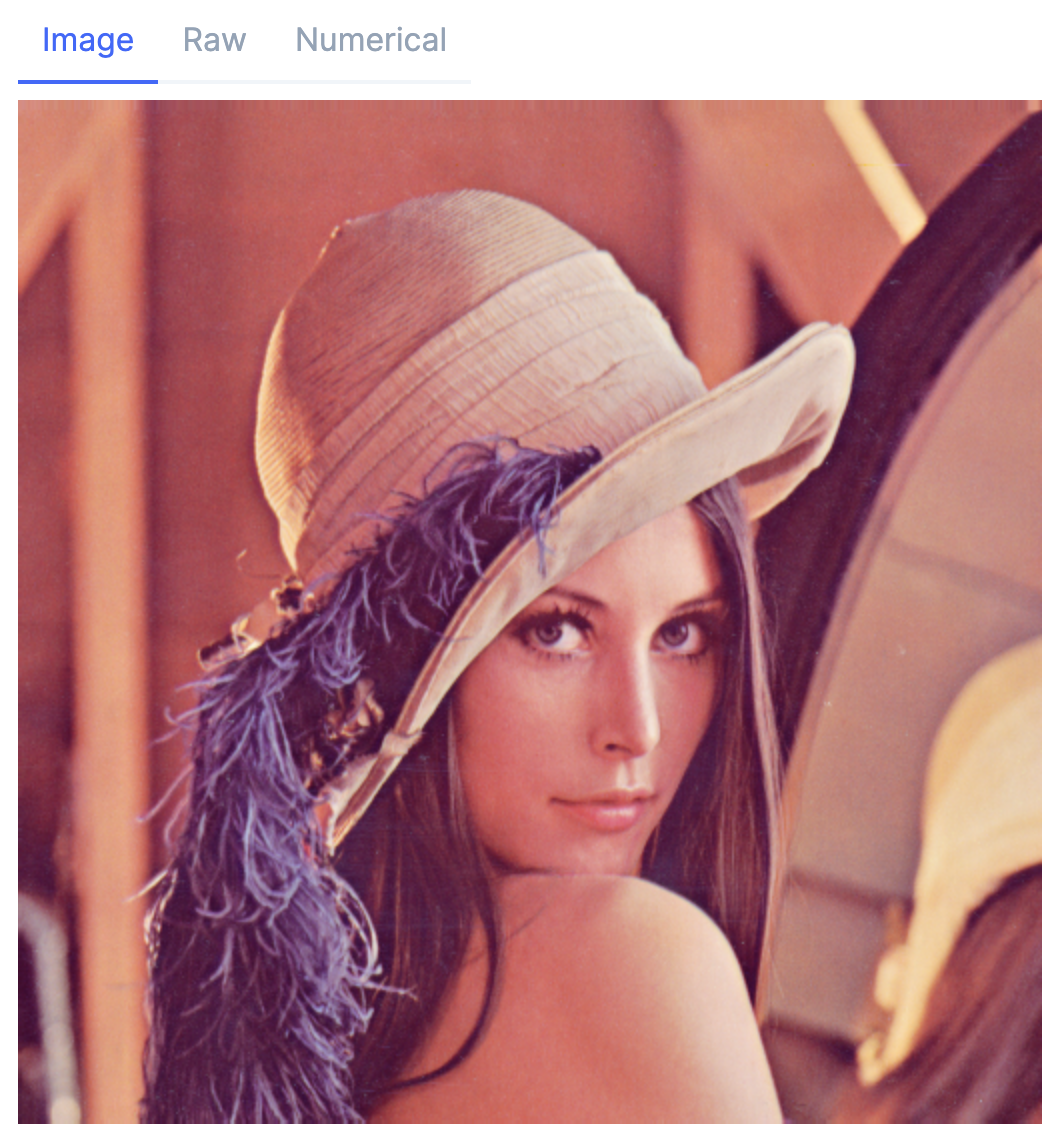
では、この mat を S3 にアップロードしましょう
Evision.imencode で画像をバイナリにして S3.put_object で S3 にアップロードします
bucket_name_input
|> Kino.Input.read()
|> S3.put_object("lenna_2.png", Evision.imencode(".png", mat))
|> ExAws.request!(auth_config)
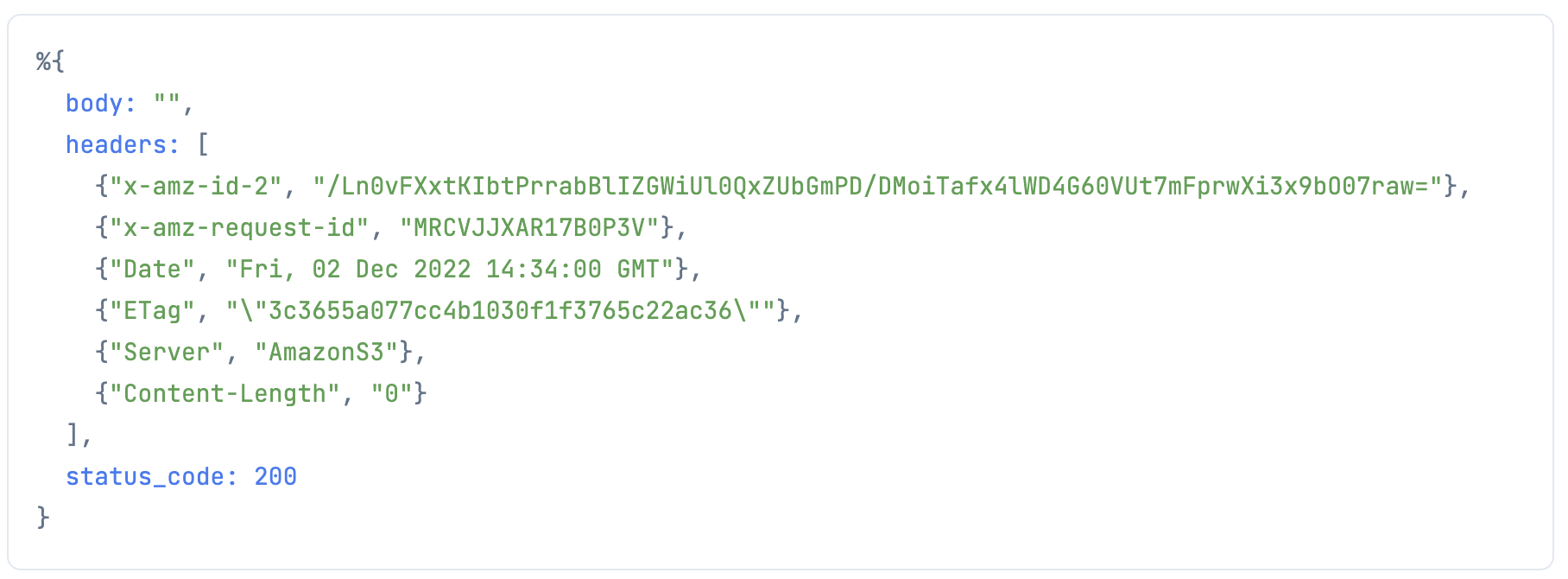
こちらも成功したようです
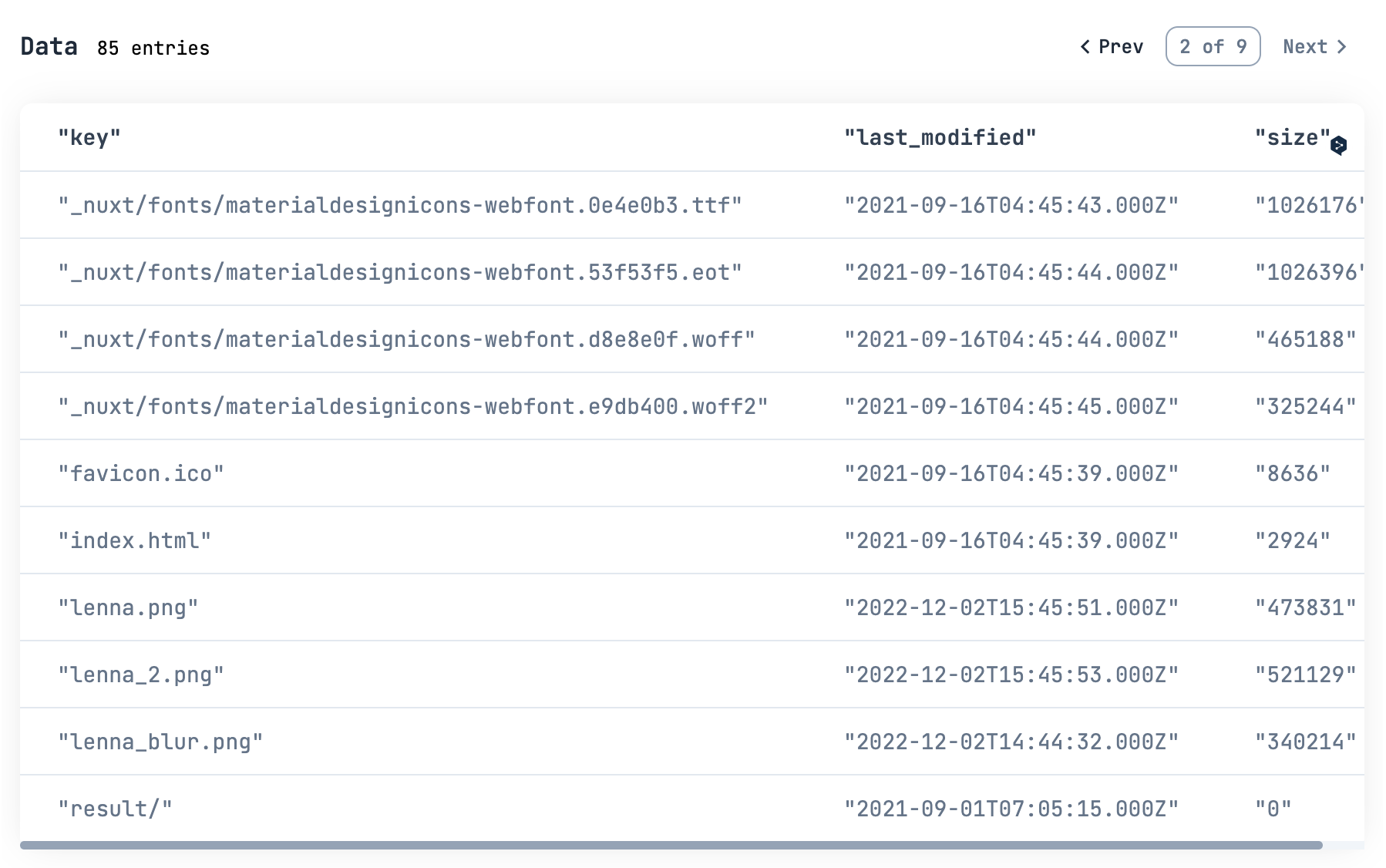
確認のため、もう一度ファイル一覧を取得します
bucket_name_input
|> Kino.Input.read()
|> S3LS.get_all_contents(auth_config)
|> DataFrame.new()
|> DataFrame.select(["key", "last_modified", "size"])
|> Kino.DataTable.new()
確かにアップロードできていますね
ファイルダウンロード
今度はファイルをダウンロードしてみましょう
bucket_name_input
|> Kino.Input.read()
|> S3.download_file("lenna.png", "lenna_downloaded.png")
|> ExAws.request!(auth_config)
ダウンロードできたか、ファイルを開いて確認します
mat = Evision.imread("lenna_downloaded.png")

画像を見たいだけでストレージに保存したくない場合は S3.get_object でバイナリを取得します
Evision.imdecode でバイナリを開けば画像が表示できます
bucket_name_input
|> Kino.Input.read()
|> S3.get_object("lenna.png")
|> ExAws.request!(auth_config)
|> then(&Evision.imdecode(&1.body, Evision.Constant.cv_IMREAD_COLOR))

最後に、画像をバイナリでダウンロードして画像処理したのち、ストレージには保存せずアップロードします
今までの組み合わせですね
bucket_name =
bucket_name_input
|> Kino.Input.read()
bucket_name
|> S3.get_object("lenna.png")
|> ExAws.request!(auth_config)
|> then(&Evision.imdecode(&1.body, Evision.Constant.cv_IMREAD_COLOR))
|> Evision.blur({9, 9})
|> then(&S3.put_object(bucket_name, "lenna_blur.png", Evision.imencode(".png", &1)))
|> ExAws.request!(auth_config)
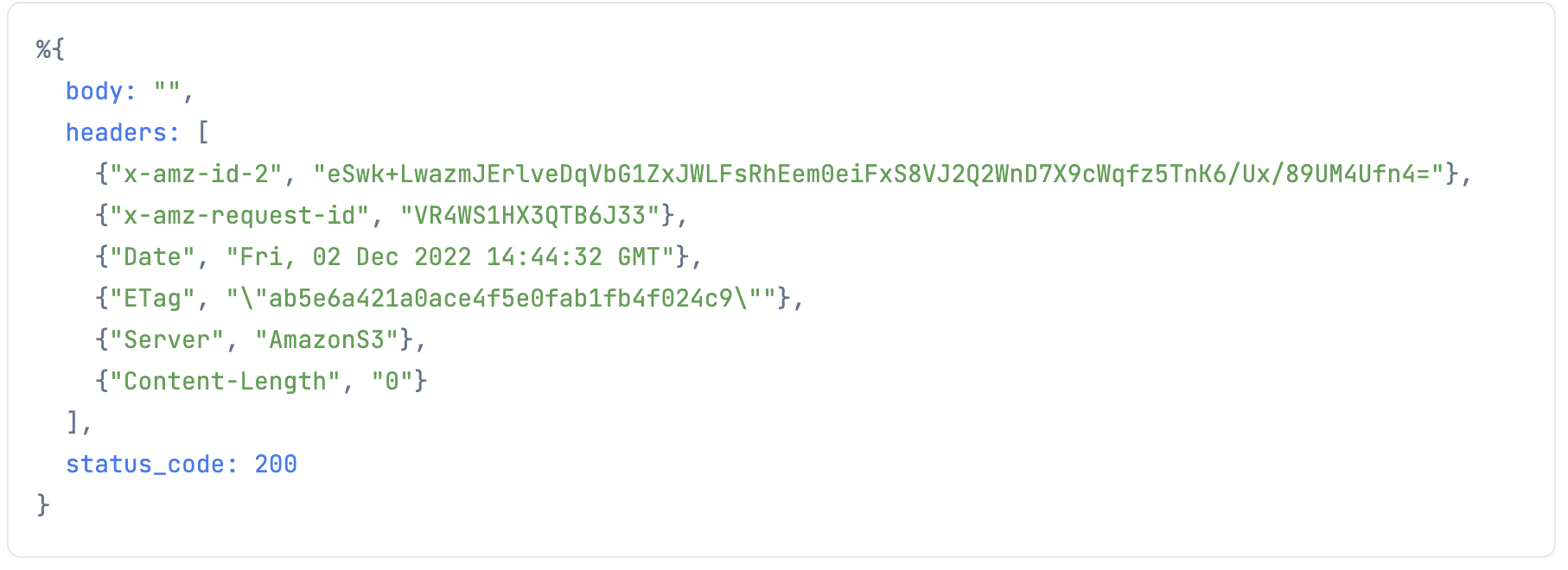
はい、できました
処理した画像を S3 から取得して見てみましょう
bucket_name_input
|> Kino.Input.read()
|> S3.get_object("lenna_blur.png")
|> ExAws.request!(auth_config)
|> then(&Evision.imdecode(&1.body, Evision.Constant.cv_IMREAD_COLOR))
ちゃんと blur ぼかし処理されていますね

まとめ
通常の Elixir プロジェクトでは AWS の認証情報は config に記載しますが、 Livebook だと認証情報直書きはまずいので、 Kino.Input を使ってリクエスト時に付加する方式にしました
今後も同じ方式で他の AWS サービスをバンバン Livebook から呼び出します
本当に Jupyter でやってたことなら Livebook で何でもできますね