要約
PyTorchを使用して、 Gymnasiumの CartPole-v1 タスクで強化学習の有名なDeep Q Learning (DQN) エージェントをトレーニングする方法を説明します。
強化学習の用語
- 方策 (Policy):環境に対して行動を起こす学習者。強化学習では、このエージェントが環境に対して様々な試行を繰り返すことで行動を最適化していきます。
- 環境 (Environment): エージェントの行動に対して状態の更新と報酬の付与を行います。強化学習では、与えられた「環境」における価値を最大化するように「エージェント」を学習させます。
- 状態 ($s_t$): 環境が保持する環境の様子で、エージェントが起こす行動によって変化します。
- 行動 (a): エージェントがある状態のときに取ることができる行動のことです。
- 報酬 (r): エージェントの行動に対する環境からの報酬です。
Q-learningとは?
Q学習は、状態と行動の価値をQテーブルで管理し、行動ごとにQ値を更新する手法です。学習時にはQテーブルを更新し、経験に基づいた知識を記録します。Q値の計算式は報酬と次の状態における最大Q値を考慮しています。この方法により、どの状態でも最適な行動を取ることが可能になります。
- Qを求める計算式:$ Q(s, a) = R(s, a)+ \gamma * \max Q(s', a') $
これをすべてのアクションとステートのペアに計算をしていき、テーブルを更新していきます。
そうすることによって、どのような状態においても最適なアクションを取り続けることが可能になります。
何がダメなの?
Qテーブルは、行動や状態数が膨大な時に(推薦エンジン等のアクションの数がとても多い時など)、Qテーブルの必要なメモリ空間が大きくなりすぎてしまうという問題が起きます。
DQNとは?
DQN(Deep Q-Network)は、Q学習においてニューラルネットワークを活用する手法です。従来のQ学習ではQテーブルを使用してQ値を学習しましたが、DQNではQテーブルの代わりにニューラルネットワークを使用してQ値を近似します。これにより、メモリ空間の問題を回避することができます。DQNでは最適な行動価値関数をニューラルネットワークで近似し、特定の状態における各行動のQ値を推定します。そして、最も高いQ値を持つ行動を選択することで最適な行動を決定します。具体的には、入力として状態$s_t$を与え、出力層のノードが行動$a_t$となるようなニューラルネットワークを使用してQ(s_t, a_t)の値を計算します。
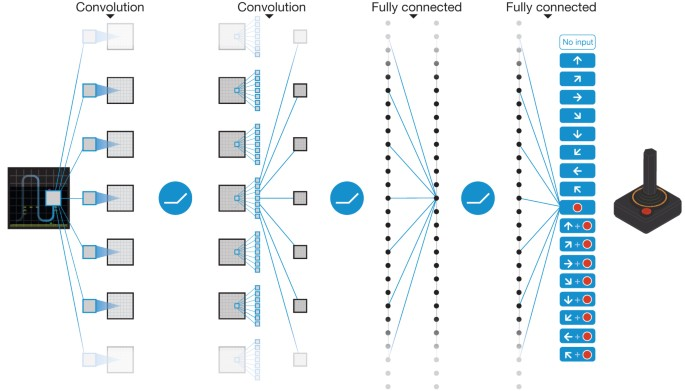
実際のアルゴリズムを見る前に、いくつか用語をさらっておきましょう。
DQNの用語
ε-greedy法
ε-greedy法は、他の良い行動が存在するか探索するために、一定の割合でランダムに行動を選択する手法です。強化学習では、最適な行動を見つけるために高いQ値の行動を選ぶことが重要ですが、それだけではデメリットがあります。なぜなら、最初の試行で偶然に高いQ値の行動を見つけると、その行動に偏ってしまう可能性があるからです。しかし、Q値が高いと必ずしも最適な行動とは限りません。ε-greedy法では、ある定数(例えばε=0.3)を設定し、行動選択時に0から1の乱数を生成し、その値がε以下の場合にランダムに行動を選択します。つまり、基本的には高いQ値の行動を選びつつも、時折他の行動も試してみるというアプローチです。
Experience Replay Buffer
Experience Replayは、従来のQ学習とは異なる方法で学習を行う手法です。通常のQ学習では、1ステップごとにその内容を学習しますが、Experience Replayでは、各ステップの内容をメモリに保存し、ランダムに取り出してニューラルネットワークに学習させます。
1ステップごとに学習すると、時間的に相関が高い内容が連続して学習されるため、学習の安定性が低下しやすくなります(つまり、過学習が起こりやすい)。Experience Replayは、この問題を解決するための工夫です。
Target Network
$Q(s_t, a_t)$ の更新が増加方向に行われると、通常は$Q(s_{t+1}, a)$ も増加します(パラメータを共有しているため)。その結果、予測値が増加するため、さらに$Q(s_t, a_t)$ も増加することがあります。このような更新が繰り返されると、値が発散したりポリシーが不安定になる可能性があります。
そのため、古いパラメータを使用して予測値を計算することで、遅延が発生し、発散や振動のリスクが大幅に低減されます。これにより、学習の安定性が向上します。
DQN algorithm
下記が実際のアルゴリズムです (From Lec.8 by Sergey Levine from UCB)。

- Eps-greedy法にのっとり、探索か最適なアクションをとります、そのうえで、環境から $(s_t, a_t, s_{t+1}, r_t)$のタプルを取得し、experience replay buffer ($\mathcal{B}$) に蓄積します。
- $\mathcal{B}$より、ミニバッチサンプリングをして、Q-valueの更新の準備をします。
- 先に見たTarget networkを使用して、ワンステップ先から計算できる将来価値 (Q-value)を計算します。ここでは、$Q_{\phi'}$の$\phi'$がTarget networkで使われているweightを示してます。
- 最後に、L4の $y$を使用して、実際のQ-networkを更新します。
- Target networkとメインのネットワークをシンクします。
実際にDQNを使ってみる
Cartpole問題とは
CartPoleは、棒が設置された台車を倒れないように制御する問題です。エージェントは環境の現在の状態を観察し、アクションを選択します。環境は新しい状態に進み、選択されたアクションの結果として報酬が与えられます。タスクでは、時間が経過するごとに報酬が+1され、棒が倒れたり、台車が中心から離れたりすると環境が終了します。より長期間の実行と大きな利益を目指すより高性能なシナリオがあります。
タスク設定:Action, State, Reward etc
- Action: 台を左に押す(0)か 右に押す(1)の二択になります。
- State: 観測値は、台車の位置、台車の速度、棒の角度、棒の先端の速度の4つになります。
- 台車の位置 [-2.4, 2.4]
- 台車の速度 [-inf, inf]
- 棒の角度 [-41.8°, 41.8°]
- 棒の先端の速度 [-inf, inf]
- Reward: 報酬としては1を与え続けます。
- エピソードの終了判定: 以下のどれかの条件を満たした場合に、エピソードが終了したと判定されます。
- ポールのアングルが±12°以内
- 台車の位置が±2.4以内
- エピソードの長さが200以上
環境
- numpy
- gym
- pytorch
- matplotlib
実装
まずは、学習に必要なパラメータを設定します。
上記のコードは、OpenAI Gymを使用して強化学習の環境を作成するためのインポート文や、ハイパーパラメータの設定、乱数のシード設定などが含まれています。具体的には、gymモジュールのインポート、数学や乱数生成に関するモジュールのインポート、データ構造や深層学習のためのモジュールのインポート、ハイパーパラメータの定義などが行われています。また、乱数のシード設定に関する処理も含まれています。
import gym
import math
import random
import numpy as np
from collections import deque
import torch
from torch import nn
import torch.nn.functional as F
GAMMA = 0.95
LEARNING_RATE = 0.001
MEMORY_SIZE = 1000000
BATCH_SIZE = 64
EPS_START = 1.0
EPS_END = 0.05
EPS_DECAY = 1000
TOTAL_TS = 10000
SYNC_FREQ = 10
seed = 2023
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
次に、Replay Bufferを定義します。
下記のコードは、再生バッファ(Replay Buffer)と呼ばれるクラスの定義です。このクラスは、エージェントの経験を保存し、ランダムにサンプリングするための機能を提供します。
- クラスのコンストラクタ(init)では、バッファのサイズを指定し、空のバッファとインデックスを初期化します。
- appendメソッドは、経験をバッファに追加します。バッファが指定されたサイズを超える場合、古い経験を削除します。バッファが指定されたサイズと同じ場合は、バッファ内の要素を上書きします。それ以外の場合は、単に経験を追加します。
- sizeメソッドは、バッファ内の経験の数を返します。
- sampleメソッドは、バッファから指定されたバッチサイズの経験をランダムにサンプリングして返します。バッファのサイズがバッチサイズより小さい場合は、バッファ内のすべての経験をサンプリングします。サンプリングされた経験は、それぞれの要素ごとにテンソルに変換され、リストとして返されます。
このクラスは、深層強化学習においてエージェントの経験再利用とサンプリングを行うために使用されます。
class ReplayBuffer(object):
def __init__(self, buffer_size):
self.buffer_size = buffer_size
self.buffer = []
self.index = 0
def append(self, obj):
if self.size() > self.buffer_size:
print('buffer size larger than set value, trimming...')
self.buffer = self.buffer[(self.size() - self.buffer_size):]
elif self.size() == self.buffer_size:
self.buffer[self.index] = obj
self.index += 1
self.index %= self.buffer_size
else:
self.buffer.append(obj)
def size(self):
return len(self.buffer)
def sample(self, batch_size, device="cpu"):
if self.size() < batch_size:
batch = random.sample(self.buffer, self.size())
else:
batch = random.sample(self.buffer, batch_size)
res = []
for i in range(5):
k = np.stack(tuple(item[i] for item in batch), axis=0)
res.append(torch.tensor(k, device=device))
return res[0], res[1], res[2], res[3], res[4]
最初に、GPUデバイスを選択し、CartPole環境を作成し、状態空間の次元数と行動空間の次元数を取得します。また、ReplayBufferを呼び出し、メインのQネットワーク(main_net)を定義します。main_netは、全結合層からなるニューラルネットワークで、状態を入力とし、行動の期待値を出力します。損失関数とオプティマイザも定義されています。
次に、main_netと同じ構造のターゲットネットワーク(target_net)を作成しますが、初期化時はメインと一緒にしたいので、意図気にコピーしてます。
device = "cuda" # "cpu"
env = gym.make("CartPole-v1")
n_observations = env.observation_space.shape[0]
n_actions = env.action_space.n
buffer = ReplayBuffer(buffer_size=MEMORY_SIZE)
main_net = nn.Sequential(
nn.Linear(n_observations, 128), nn.ReLU(),
nn.Linear(128, 128), nn.ReLU(),
nn.Linear(128, n_actions)
).to(device)
criterion = nn.MSELoss()
optimiser = torch.optim.Adam(main_net.parameters())
from copy import deepcopy
target_net = deepcopy(main_net)
ここからは少々長いですが、学習のメイン部分を一気に記載します。
学習のメインループでは、エピソードごとに環境をリセットし、エピソード内の各ステップで行動を選択します。ε-greedy法を使用してランダムに行動を選択するか、main_netを使用して最適な行動を選択します。選択した行動に基づいて環境を進め、報酬を受け取ります。この経験サンプルをバッファに保存し、次の状態に進みます。エピソードが終了したら、報酬を記録します。
バッファのサイズが指定のバッチサイズ以上である場合は、バッファからランダムにサンプリングしてネットワークを最適化します。また、一定の間隔でターゲットネットワークとメインネットワークの重みを同期させます。
全体のタイムステップが指定の上限に達するまで、エピソードを繰り返します。
num_episode = global_ts = 0
ep_rewards = list()
while global_ts <= TOTAL_TS:
state, done = env.reset(), False
ep_reward, ep_ts = 0.0, 0
while not done:
eps = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * global_ts / EPS_DECAY)
if np.random.rand() < eps:
action = np.random.choice(n_actions)
else:
with torch.no_grad():
q = main_net(torch.tensor(state[None, :], device=device)).detach().cpu().numpy()
action = np.argmax(q[0])
next_state, reward, done, info = env.step(action)
ep_reward += reward
reward = reward if not done else -reward
buffer.append((state, action, reward, next_state, done))
state = next_state
if done:
ep_rewards.append(ep_reward)
if (num_episode == 0) or ((num_episode + 1) % 50 == 0):
print(f"Ep-{num_episode + 1} {global_ts + 1}/{TOTAL_TS} Eps: {eps:.2f}, Reward: {ep_reward}")
break
if buffer.size() >= BATCH_SIZE:
obses_t, actions, rewards, obses_tp1, dones = buffer.sample(BATCH_SIZE, device)
# Optimize the model
with torch.no_grad():
target_q = target_net(obses_tp1).detach().max(1)[0]
target = rewards + GAMMA * target_q * (1 - dones.float())
val_t = main_net(obses_t).gather(1, actions.unsqueeze(1)).squeeze(1)
loss = F.mse_loss(val_t.float(), target.float())
optimiser.zero_grad()
loss.backward()
optimiser.step()
# Periodically sync the target and main networks
if (global_ts + 1) % SYNC_FREQ == 0:
target_net.load_state_dict(main_net.state_dict())
ep_ts += 1
global_ts += 1
num_episode += 1
最後に学習結果のプロットをします。
import matplotlib.pyplot as plt
def moving_average(a, n=5) :
ret = np.cumsum(a, dtype=float)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
plt.plot(moving_average(ep_rewards))
plt.xlabel("#Episode")
plt.ylabel("Ep-Return")
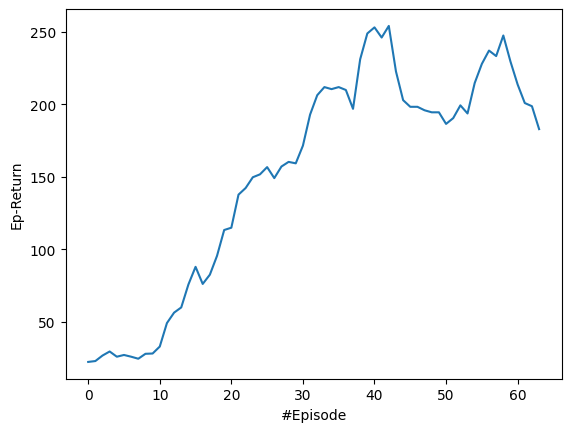
学習初期段階では、想定通りうまく意思決定ができてないですが、時間経過とともに、しっかりとパフォーマンスが改善して向上していることが確認できます。
この先に何があるのか?
最新の研究では、DQNの問題点を改善するために様々なアプローチが試みられています。以下にいくつかの改善点を挙げます。
-
DQNでは、Q値が過剰に評価されることで行動の決定が乱れるという弱点が見つかりました。この問題に対処するため、"Double-DQN" [1] という論文では二つのQネットワークを交互に更新する手法が提案され、過剰評価を防止しました。
-
"Rainbow"[2] では、Double-DQNに加えて、最近提案された多くの改善手法を組み合わせて実装し、過去最高の結果を出しました。
-
[1] van Hasselt, H. A. D. O., A. R. T. H. U. R. Guez, and D. A. V. I. D. Silver. "Deep Reinforcement Learning with Double Q-learning. arXiv e-prints." arXiv preprint arXiv:1509.06461 (2015).
-
[2] Hessel, M., et al. "Rainbow: Combining improvements in deep reinforcement learning. CoRR, abs/1710.02298." arXiv preprint arXiv:1710.02298 (2017).
Reference
- Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." nature 518.7540 (2015): 529-533.
- 実際のGoogle colab Link