注:所感・ポエム要素もアリ
モデル作りって面倒くさい
以下はkaggle daysで使われた「最終的なモデルにたどり着くまでの試行錯誤」を表した一枚のスライドですが、
機械学習モデルを作る過程って前処理を除いてもこんな手数がかかるものだったりします。
(実社会の整備していないデータからモデル,実装を考えると中々頭が痛い。)
GMのdottさんでも、これだけFailしてるのか…#kaggledaystokyo pic.twitter.com/Vc6s6h8Fdf
— rinascimento (@rinascimento741) December 11, 2019
ただ実問題はkaggleほどの厳密さを求められなかったり、ひとまず導入・ひとまず数%の改善でもよかったりするざっくりとした案件(一面)もあります。
作業自動化したいなぁ
モデル作りも慣れてくると同じようなEDA(探査的データ解析)と同じようなモデリング(ベースライン→研磨)になってきますので、
これを簡単にしたいと思い、ある程度自由に変更できる簡略スクリプトを作ってみました。
まず図だけで説明し、スクリプトは後半にまとめてます。
モデル作りのプロセス
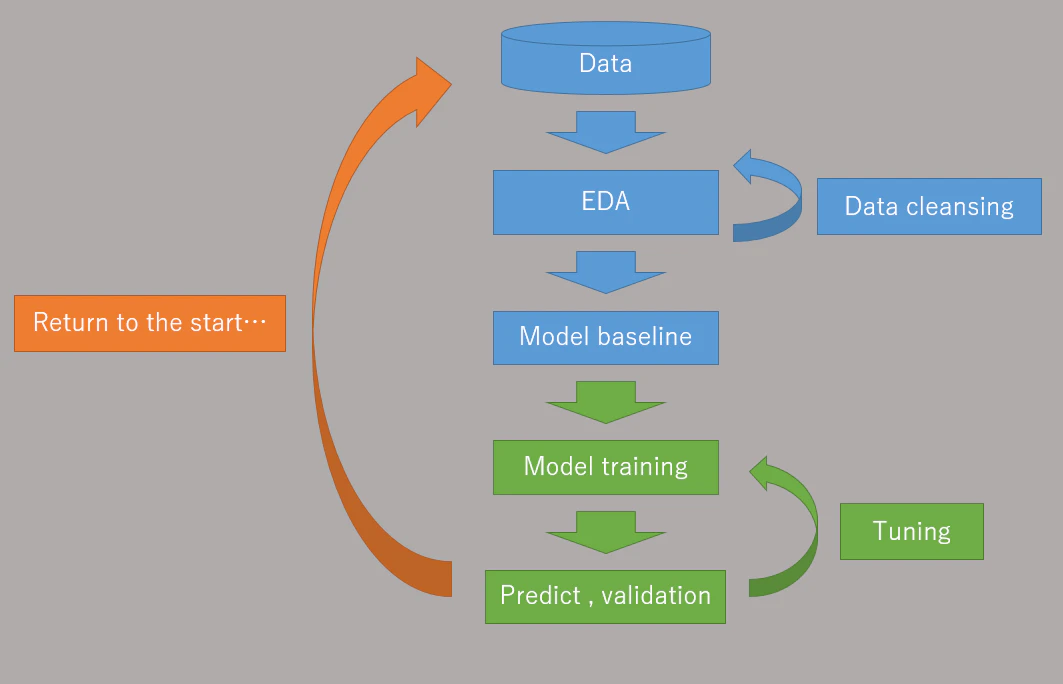
- EDA → cleansing
- まずデータを見て、可視化して、NAやNULL処理、ID列を消す、などの処理をしてから予測に使えるよう成形します。
- 実問題ではこの前にDataBaseにつないでjoinして整合性を確かめて個人情報を消す処理などが入ります。
- EDA → model(base line)
- ある程度知識がある人ならばデータと課題から使えそうなモデル候補が頭に浮かびます
- いくつかのモデルを比較して、どのモデルが一番良いかを決めるため、ある程度デフォルト設定値で問題を解かせてみます
- これをbaselineのモデルと言います
- 各アルゴリズムのbaselineを比較しながらどのアルゴリズムで行くか決めます
- model → training
- 候補として取り上げたモデルに絞り、パラメータのtuningや交差検証などを行い精度を上げます
- training → predict
- 学習が終わったモデルを使って実際に予測に使います。
- ダメなら別のアルゴリズムからアプローチをします
- そもそも抽出したデータが間違っていたり、タスクの設定のし直しがあれば振り出しに戻ります
水色部分を簡略化した
基本的な可視化とアルゴリズム比較だけ行って、課題解決までの手間を簡略化します。
1.最小限の全体俯瞰を行って
2.ダミー化・列削除・testsplitして
3.デフォルト・パラメータ変更したモデルでbaselineを決めます
(LGBMがClassifierになってますがregressionの問題です)

使い慣れたパッケージを自分好みにカスタムしながら並列で試せるスクリプトを作ってみました。
というのもモデルをリストにしてfor文で回しているだけなんですが、一つ一つ使うよりも体系的にまとめたスクリプトを組んだほうが楽だろうなと安易な発想で書いたわけです。(以下抜粋)
models = [
SGDRegressor(max_iter=1000, tol=1e-3),
Lasso(alpha=0.1),
ElasticNet(random_state=0),
Ridge(alpha=.5),
SVR(gamma='auto', kernel='linear'),
SVR(gamma='auto', kernel='rbf'),
BaggingRegressor(),
BaggingRegressor(KNeighborsClassifier(), max_samples=0.5, max_features=0.5),
NuSVR(gamma='auto'),
RandomForestRegressor(random_state=0, n_estimators=300),
xgb.XGBRegressor(),
LinearRegression(),
lgb.LGBMRegressor(num_leaves=80)
]
for model in models:
model.fit(x_train, y_train)
y_res = model.predict(x_val)
mse = mean_squared_error(y_val, y_res)
score = model.score(x_val, y_val)
table.add_row([type(model).__name__, format(mse, '.2f'), format(score, '.2f')])
print(table)
それ以降はチューニングと予測になるわけですが、今回のモデル比較ではRandom Forestが一番いい値なのでRFから掘り進めていくことになると思います。
一応予測パートもスクリプトとしてつけておきましたので興味があれば一番下を参照してください。
pycaretの紹介
似たような方法としてもっと楽なのはpycaretというライブラリがあり、これはもっと簡単に実行できます。
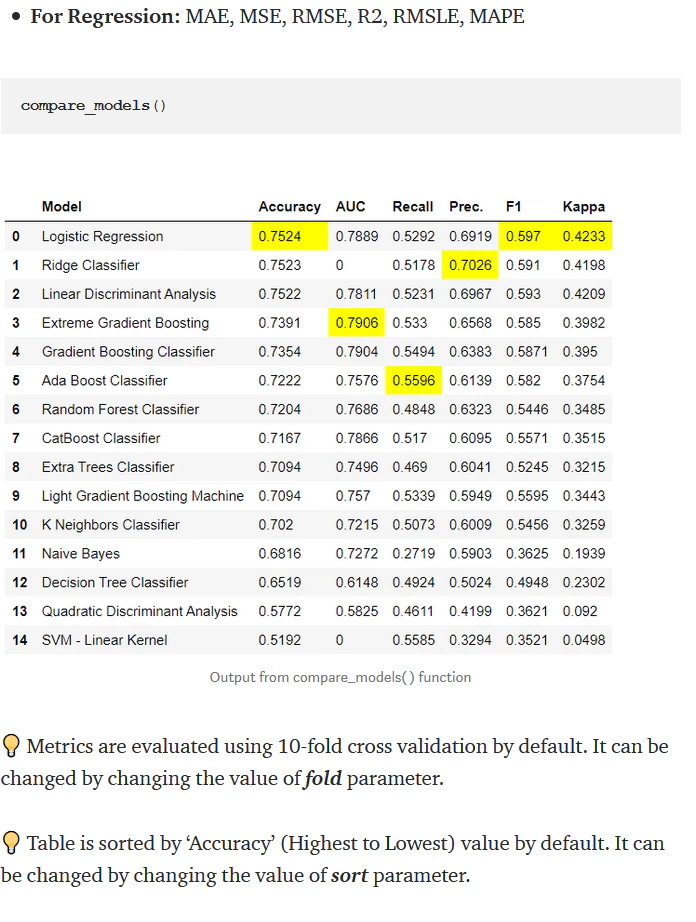
ただ、やはり自分好みのカスタムコーディング要素を残しつつ、自動化していく方法として今回記事を書きました。
AutoMLとどう違うのか
たとえば今回の手順のような
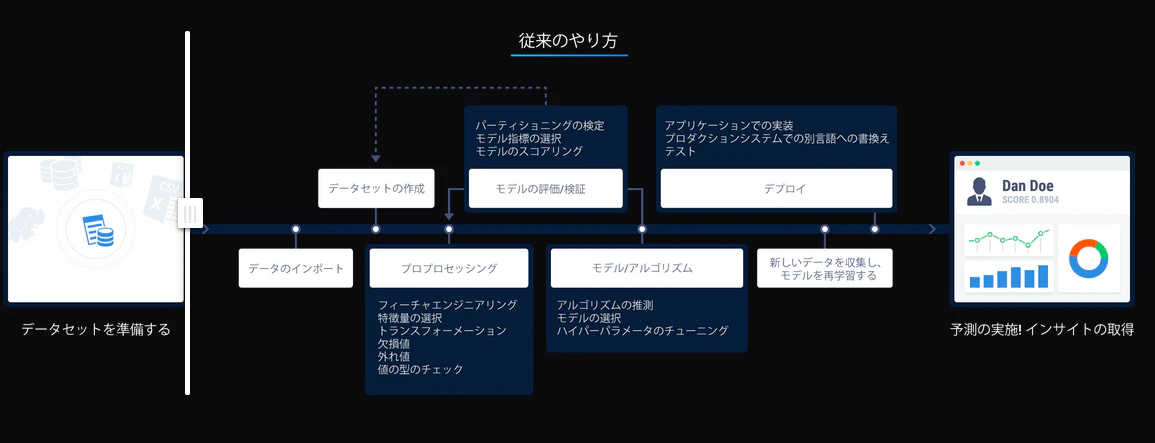
がチェックボックスを弄って進めることで
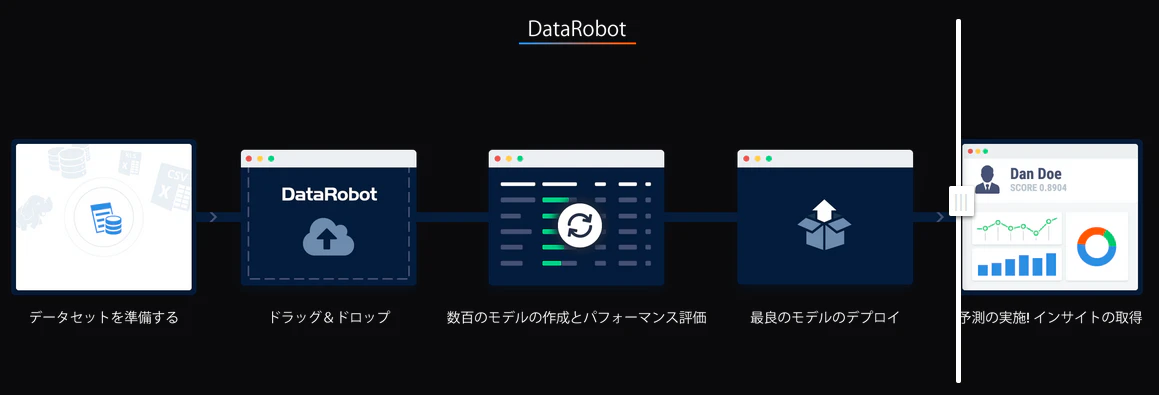
のように簡単になるものです。
出典:DataRobot
データのクレンジング、変数の選択も選べますし、ダミー化したい変数を選択しておくと内部で何百パターンの使えそうな変数を作って比較してくれたりもします。
今回のように複数のアルゴリズムを並列に走らせて比較、チューニングするという機能もあります。
使いこなせたら便利そうですね。
(試用できるAutoMLも過去記事で紹介しているので興味があれば。)
AutoMLの話が挙がるとよく出る誤解と所感
???「コーディング不要だから非エンジニアでも使えて、導入できればデータサイエンティストは不要」
???「作ったモデルがすぐ実運用に使えるから外注コスト削減になる」
???「データさえ入れたらいい感じの答えが出てくる」
一番言ってほしくない偉い人たちに限って誤解してたりします。
そういう場合にはまだまだ議論や現状整理が足りて無いので、データサイエンティスト不要とか言わずにデータがわかる事業整理・業務改革コンサルでも入れるべきです。
AutoML以前に現状整理すべきことで出てくる問題は
- MLで解決したい案件がそれだけあるのか (財布買っても中身は空状態)
- データの質・整形について議論できるか (有効な変数やテーブルが結合できているのか)
- 検証と評価が正しく出来るか (決定係数やMSEで比較するのって適しているのか、検証セットに標本何割割いていいか)
- 抽出データ・学習の粒度が目的に合っているのか (一か月先を知りたいのに一日先しか予測できないモデルになっている)
- データ収集,DXから入らなければならない状態ではないのか (そもそも使えるレベルのデータでない)
- 保守・運用できるのか (各自各部署勝手に作り出して技術的負債・BlackBox化,RPA出始めでも起こる)
- そもそもAIを魔法の杖と思ってないか (AutoMLは魔法の杖が無限に出てくる四次元ポケットではない)
- などなど...
上記が問題なく議論されていれば、後は懐事情との相談で導入するか判断したらいいと思います。
ML課題がデータサイエンティストに対して過剰で、AutoMLの中のライブラリが解決方法につながっている場合はバッチリ活用できると思います。
間違いなく今、Pythonを使っているようなエンジニアの助けになります。
参照データ・記事
この記事もkaggleのカーネルで学んでいる時に作り始めたのですが、刺激を受けたカーネルがわからず参照に乗せられていません。
わかり次第追加します。
以上
以下コード
# import
import pandas as pd
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import mean_squared_error, mean_squared_log_error
from sklearn.linear_model import Lasso, ElasticNet, Ridge, SGDRegressor
from sklearn.svm import SVR, NuSVR
from sklearn.ensemble import BaggingRegressor, RandomForestRegressor
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from prettytable import PrettyTable
import lightgbm as lgb
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
# ダミー化関数の定義
def generate_dummies(df, dummy_column):
dummies = pd.get_dummies(df[dummy_column], prefix=dummy_column)
df = pd.concat([df, dummies], axis=1)
return df
# データ読み込み
train = pd.read_csv('C:/Users/train.tsv',sep='\t')
test = pd.read_csv('C:/Users/test.tsv',sep='\t')
train.head()
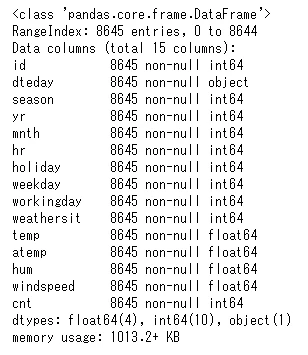
# 特徴量の名前や欠損を調べる
train.info()
# データの特徴量が量的か質的か判断、使わないものも選んでおく
category_features = ['season','yr', 'mnth', 'hr','holiday', 'weekday', 'workingday', 'weathersit']
number_features = ['temp', 'atemp', 'hum', 'windspeed']
remove_features = ['atemp','id','dteday','yr']
target = ['cnt']
features= category_features + number_features
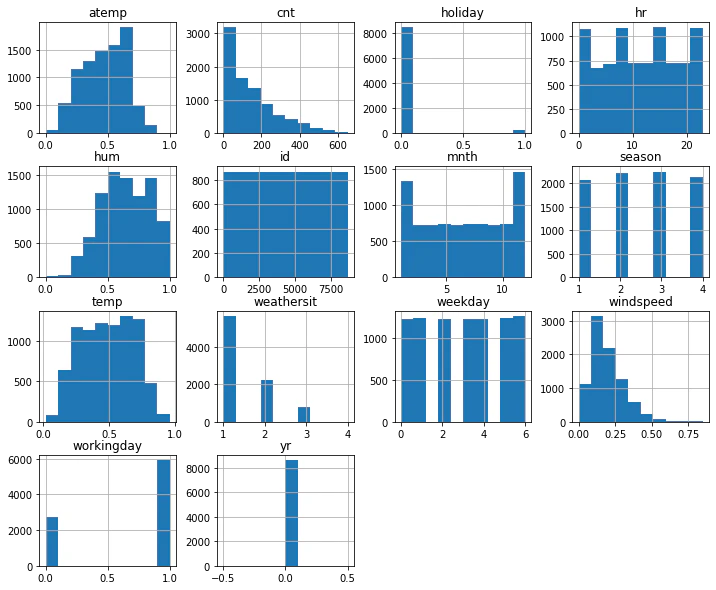
# 最低限の可視化 hist
train.hist(figsize=(12,10))
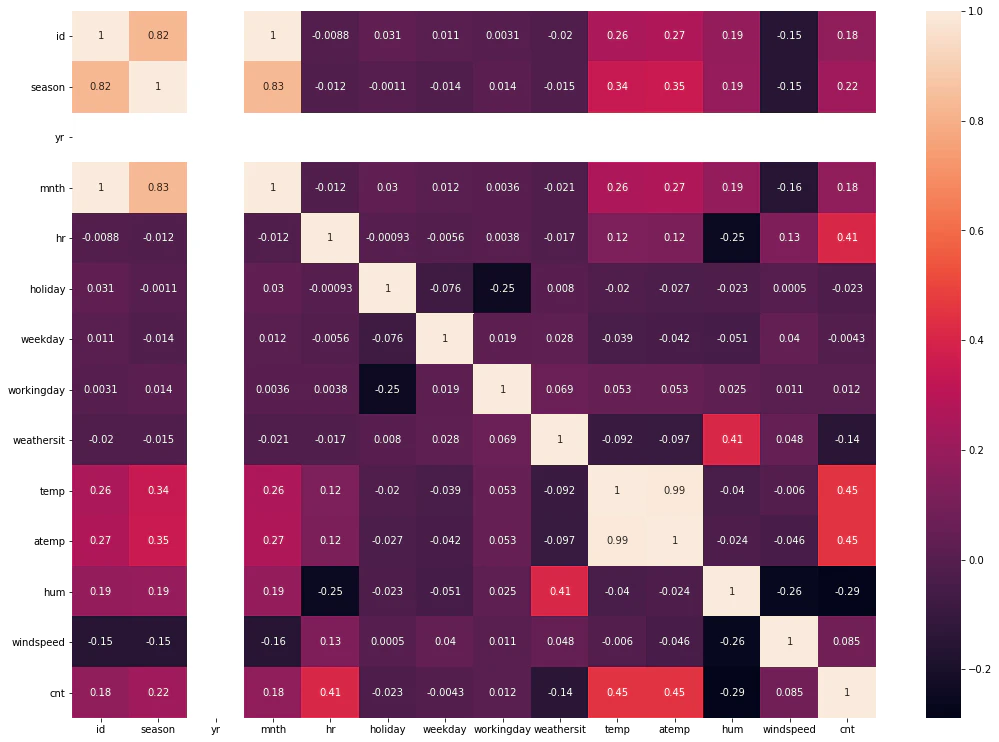
# 最低限の可視化 相関
matrix = train[number_features + target].corr()
heat = np.array(matrix)
heat[np.tril_indices_from(heat)] = False
fig,ax= plt.subplots()
fig.set_size_inches(20,10)
sns.heatmap(matrix, mask=heat,vmax=1.0, vmin=0.0, square=True,annot=True, cmap="Reds")
# test train splitと変数削除
X = pd.DataFrame.copy(train)
y = X[target]
for dummy_column in category_features:
X = generate_dummies(X, dummy_column)
X = X.drop(category_features+target+remove_features, axis=1)
x_train, x_val, y_train, y_val = train_test_split(X, y, random_state = 22, test_size = 0.2)
# アルゴリズムの比較用テーブル
table = PrettyTable()
table.field_names = ["Model", "MSE", "R-sq"]
# アルゴリズムの比較
models = [
SGDRegressor(max_iter=1000, tol=1e-3),
Lasso(alpha=0.1),
ElasticNet(random_state=0),
Ridge(alpha=.5),
SVR(gamma='auto', kernel='linear'),
SVR(gamma='auto', kernel='rbf'),
BaggingRegressor(),
BaggingRegressor(KNeighborsClassifier(), max_samples=0.5, max_features=0.5),
NuSVR(gamma='auto'),
RandomForestRegressor(random_state=0, n_estimators=300),
xgb.XGBRegressor(),
LinearRegression(),
lgb.LGBMRegressor(num_leaves=80)
]
for model in models:
model.fit(x_train, y_train)
y_res = model.predict(x_val)
mse = mean_squared_error(y_val, y_res)
score = model.score(x_val, y_val)
table.add_row([type(model).__name__, format(mse, '.2f'), format(score, '.2f')])
print(table)
# 一番良かったモデルを検証データで精度確認
table = PrettyTable()
table.field_names = ["Model", "Dataset", "MSE", 'RMSLE', "R-sq"]
model = RandomForestRegressor( random_state=0, n_estimators=100)
model.fit(x_train, y_train)
def evaluate(x, y, dataset):
pred = model.predict(x)
mse = mean_squared_error(y, pred)
score = model.score(x, y)
rmsle = np.sqrt(mean_squared_log_error(y, pred))
table.add_row([type(model).__name__, dataset, format(mse, '.2f'), format(rmsle, '.2f'), format(score, '.2f')])
evaluate(x_train, y_train, 'training')
evaluate(x_val, y_val, 'validation')
print(table)
# パラメータ探索を定義
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4]
bootstrap = [True, False]
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
print(random_grid)
# 探索実行
rf = RandomForestRegressor()
model = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=0)
model.fit(x_train, y_train)
print(model)
# 一番良かったパラメータを確認
model.best_params_
# 改めて表にする
table = PrettyTable()
table.field_names = ["Model", "Dataset", "MSE", 'RMSLE', "R-sq"]
evaluate(x_train, y_train, 'training')
evaluate(x_val, y_val, 'validation')
print(table)
# 重要度の計算
importances = rf.feature_importances_
std = np.std([tree.feature_importances_ for tree in rf.estimators_], axis=0)
indices = np.argsort(importances)[::-1]
dummy_features = x_train.columns.values
for f in range(dummy_features.shape[0]):
print("%d. feature %s (%f)" % (f + 1, dummy_features[indices[f]], importances[indices[f]]))
# 重要度の作図
# Plot the feature importances of the forest
plt.figure(figsize=(18,5))
plt.title("Feature importances")
plt.bar(range(dummy_features.shape[0]), importances[indices], color="cornflowerblue", yerr=std[indices], align="center")
plt.xticks(range(dummy_features.shape[0]), [dummy_features[i] for i in indices])
plt.xlim([-1, dummy_features.shape[0]])
plt.show()