コードなしで機械学習できるautoMLの一つ
rapidminerを触ってみたのでその備忘録とイントロ紹介
登録後
ユーザー登録を行って最初の画面は以下のような感じ
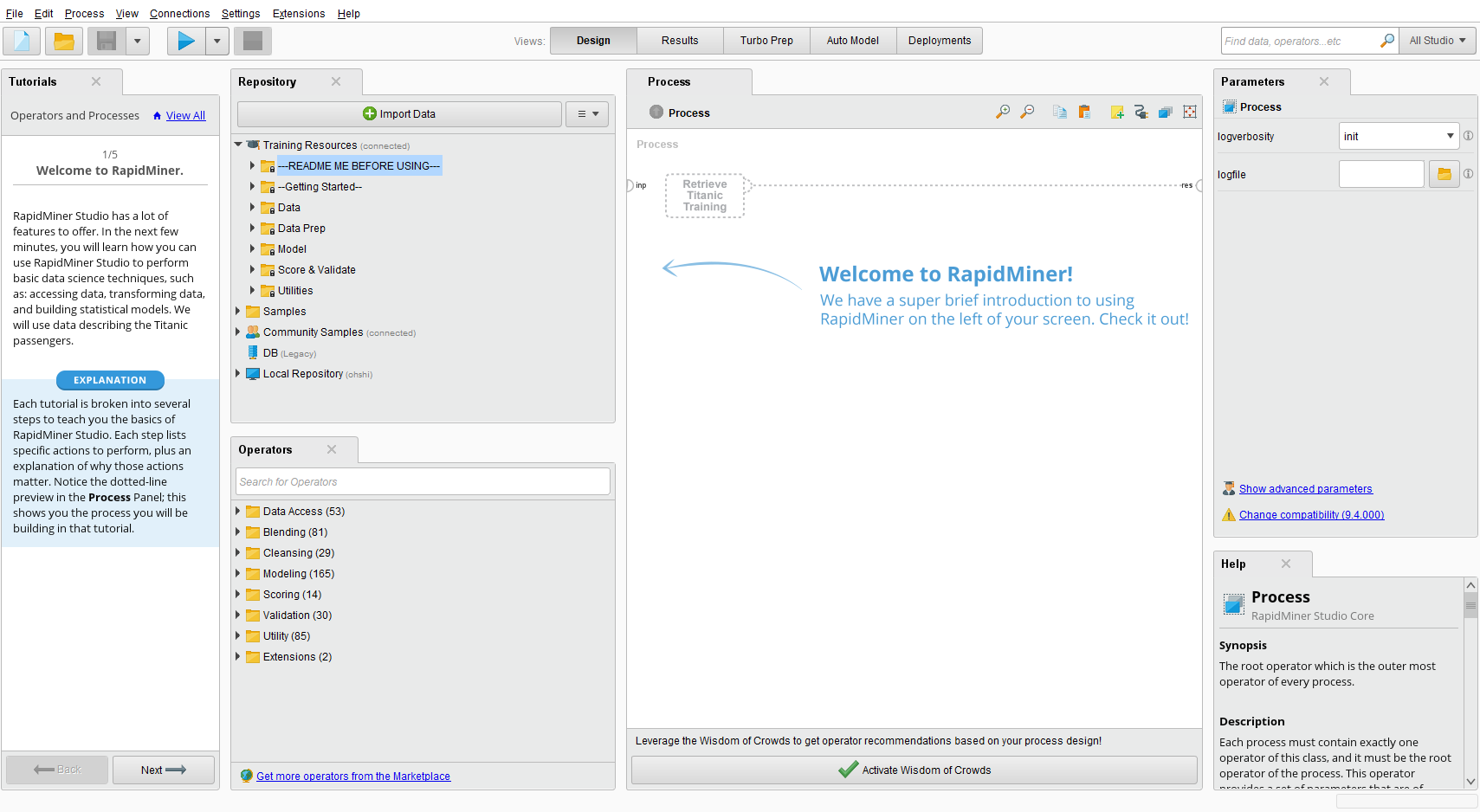
データは左のrepositoryから選択やimportできる。
今回はdataフォルダの中からzip codesというデータセットを使って機械学習を試してみることにする。
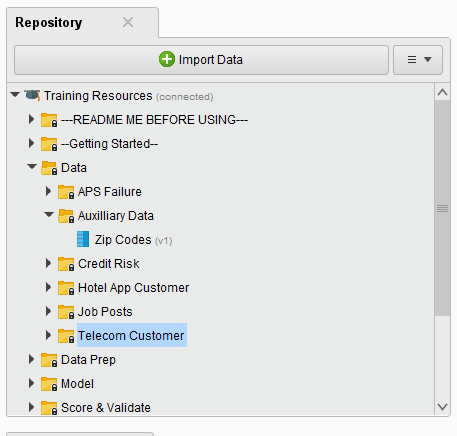
選んでみるとデータの内容一覧を観覧できる。
量的なのか質的なのか、欠損地の有無が表示される。
この場で特徴量の生成や変換ができて、基本的な機能は左の選択項目に乗っている。
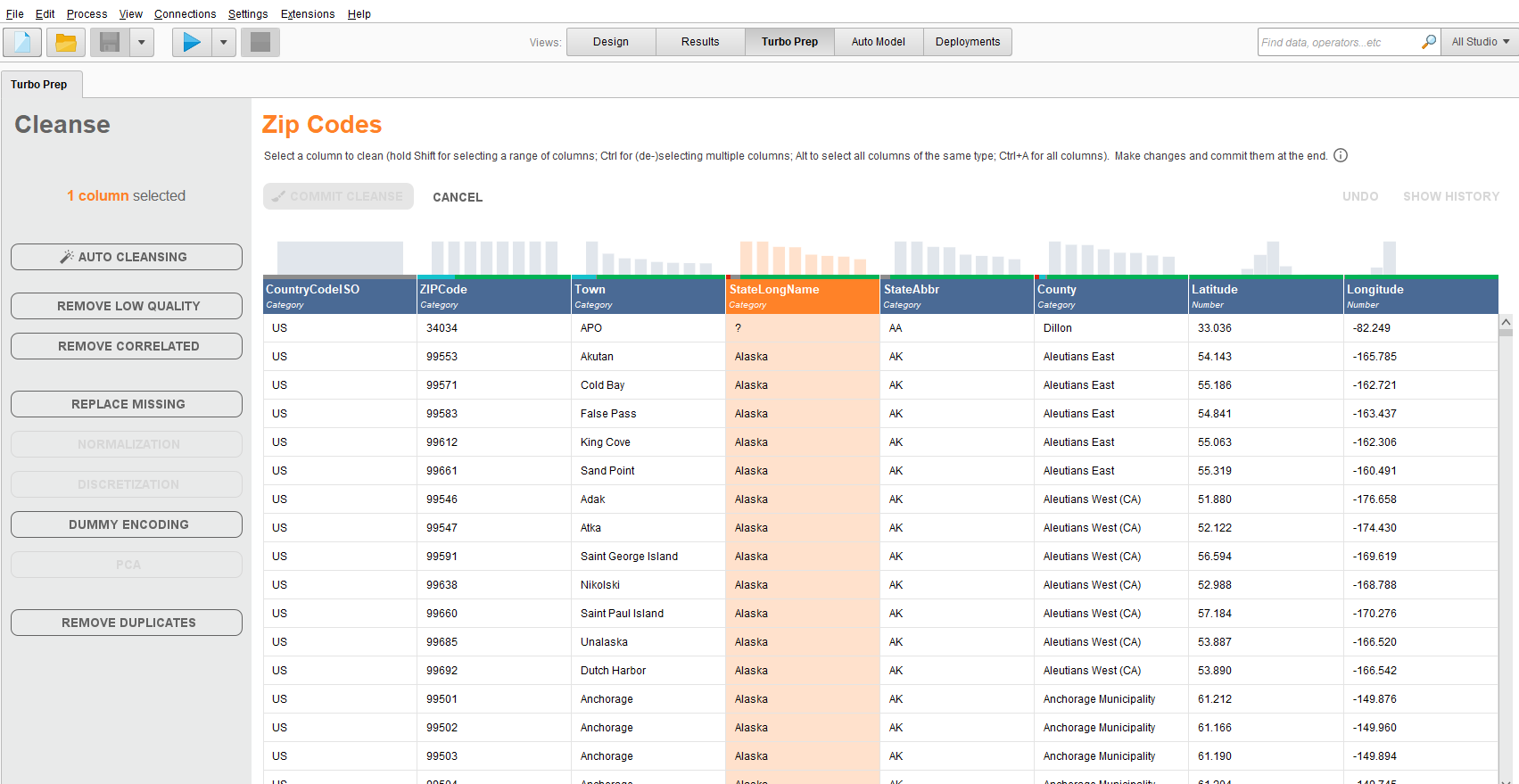
たとえば列を指定してdummy encodingをせんたくすると
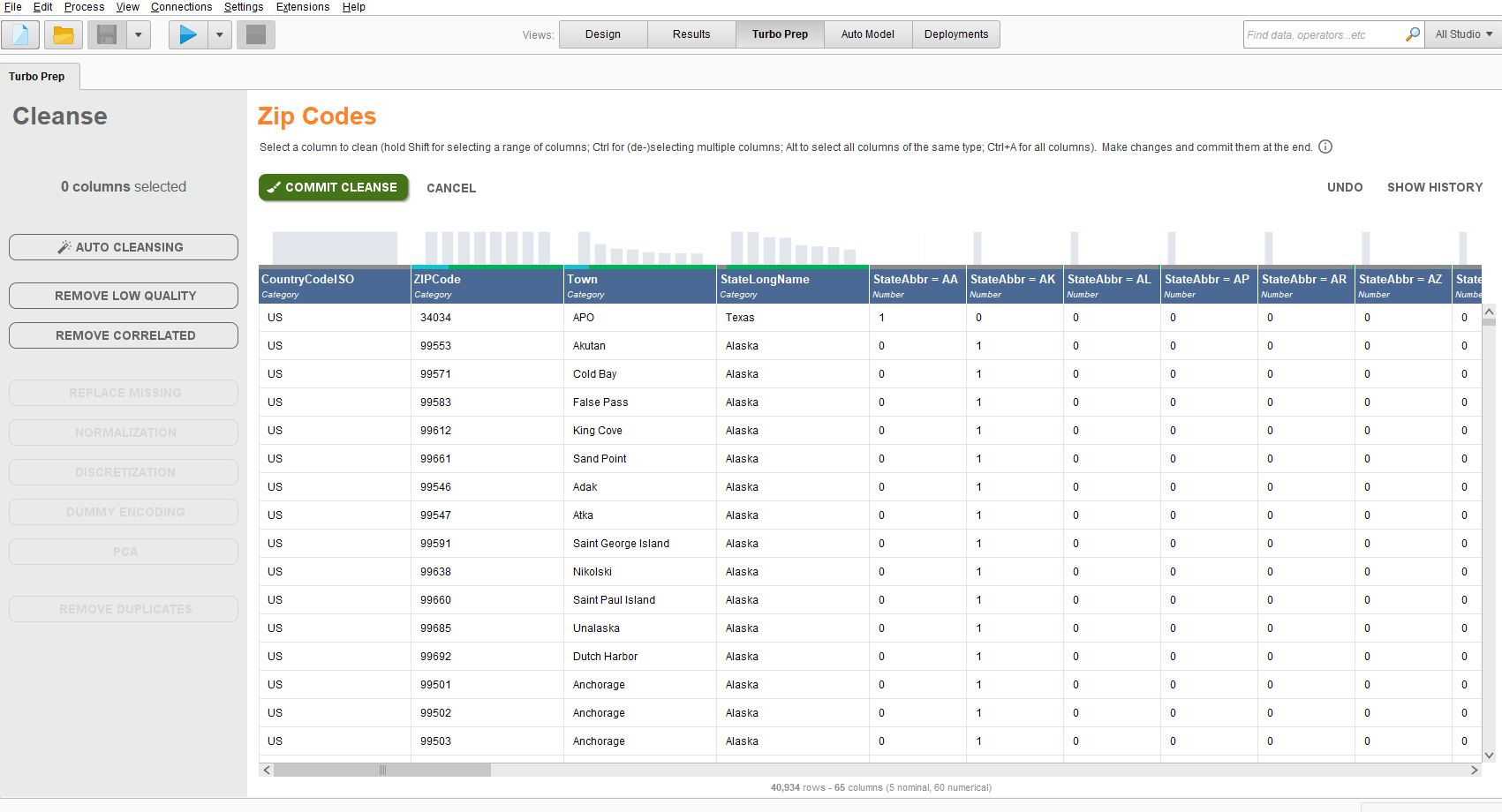
5列目からダミー化されている。
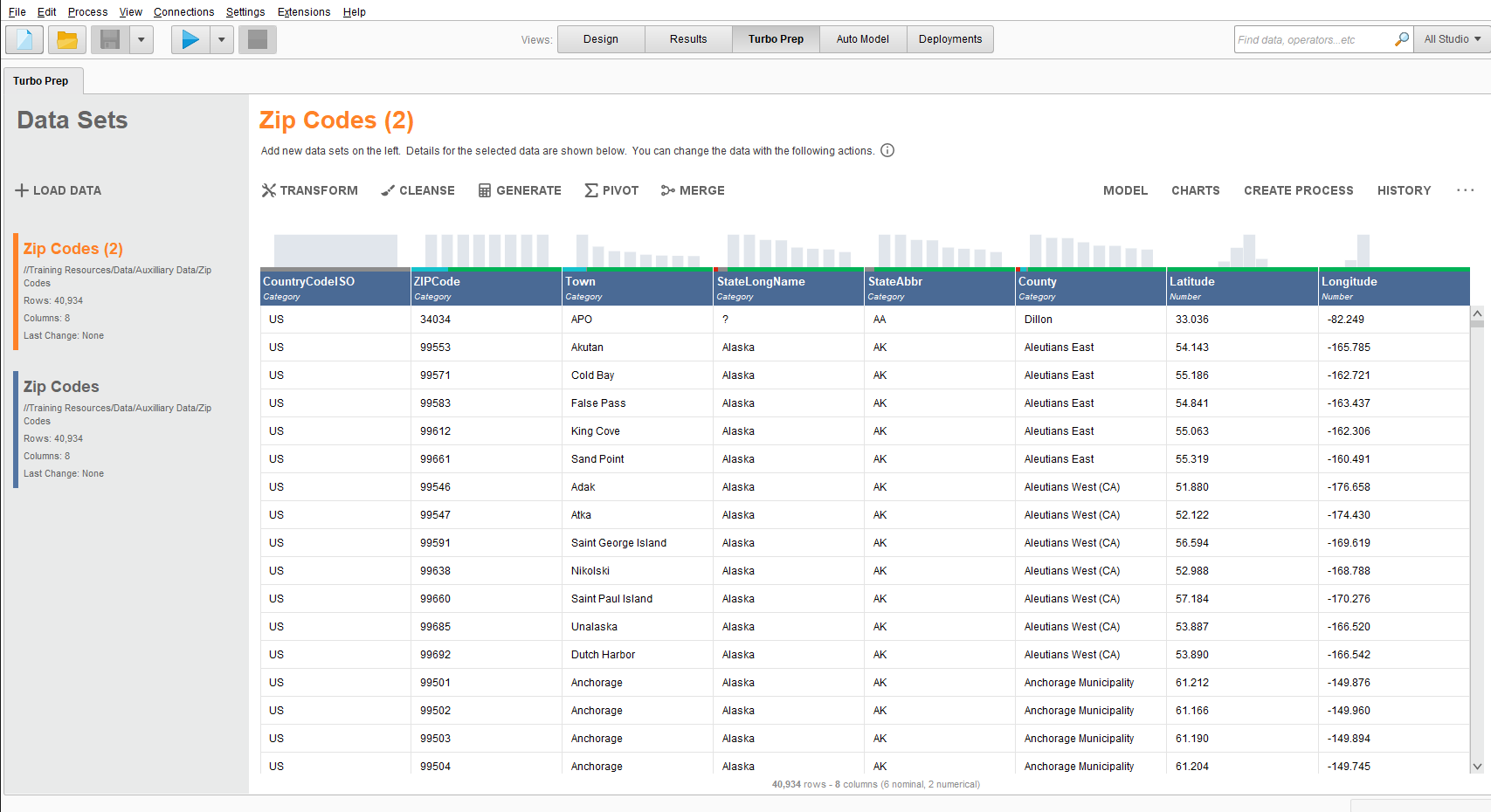
欠損地があれば変数の名前部分に赤色の警告がでているので、欠損地補間もしてみる。
欠損地を含んでいる列を選択して、
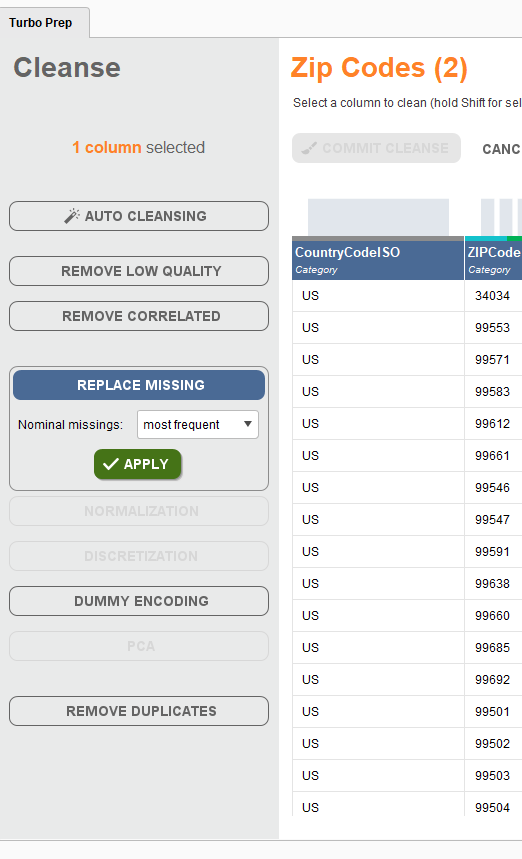
高頻度の項目名で補填するか、平均値にするか?などを選択できる。
特徴量をいじり終わったら上タブから「auto model」を選択する。
すると、被説明変数をどれにするか?予測か?クラスタリングか?などを選択できるようになる。
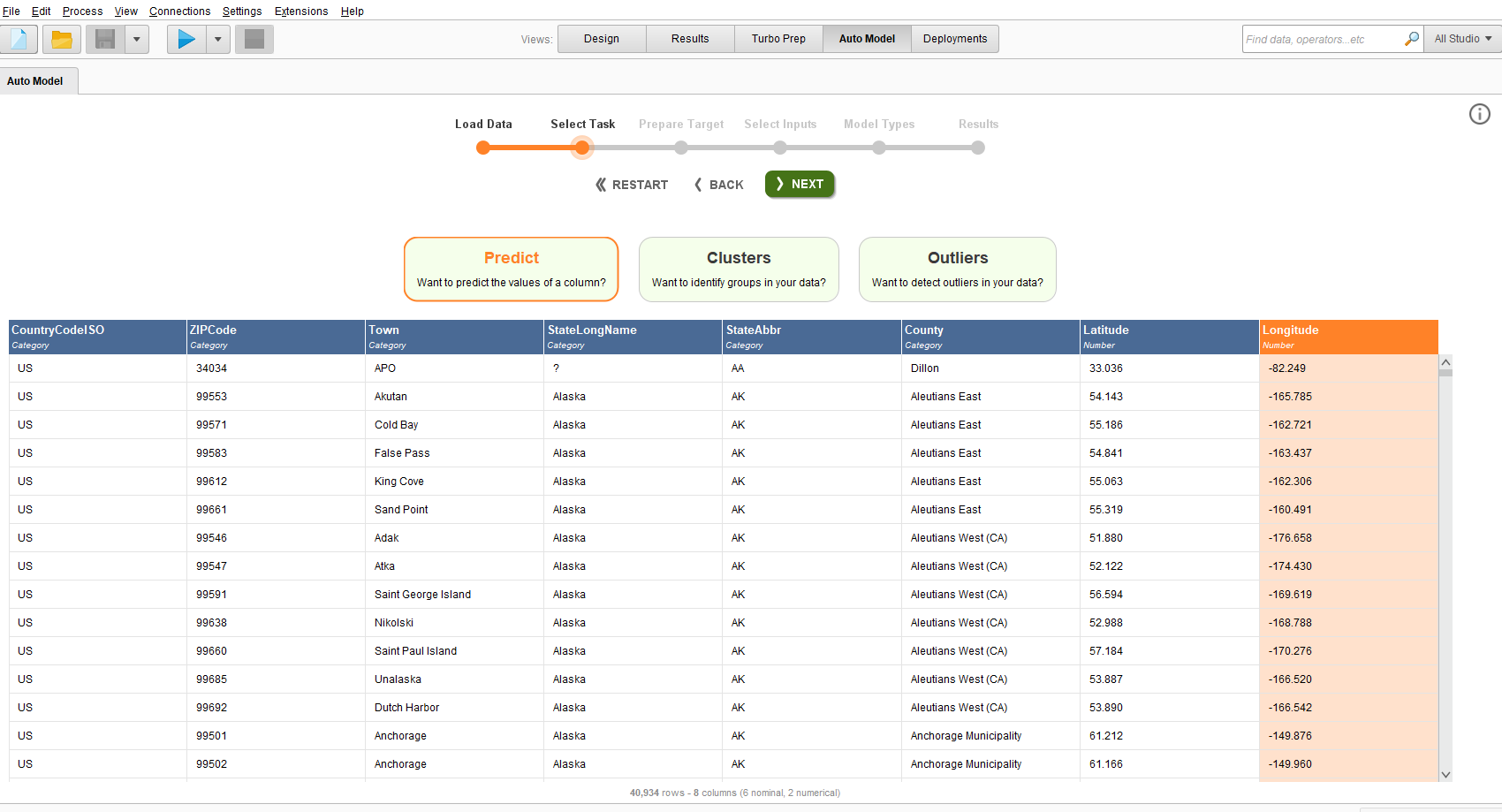
今回はpredictとして数値予測をしてもらう。
モデルの選択としていくつかの候補が出てくる。
今回は決定木やGBDT、ディープラーニング、が選択できる。
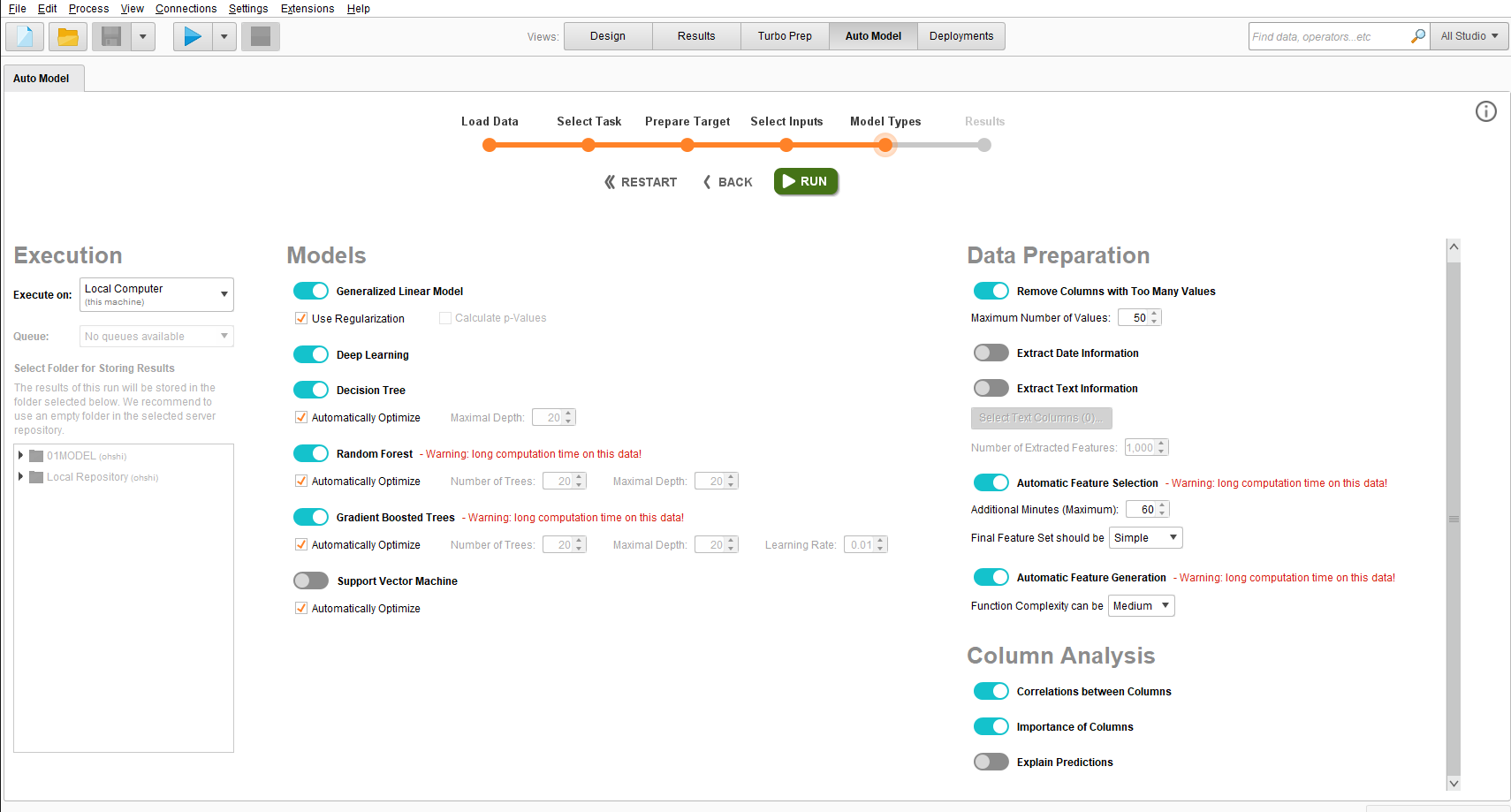
予測に使うモデルを選択し終え、runで学習させる。
学習し終わると、モデルの精度などが比較できるような画面がでてくる。
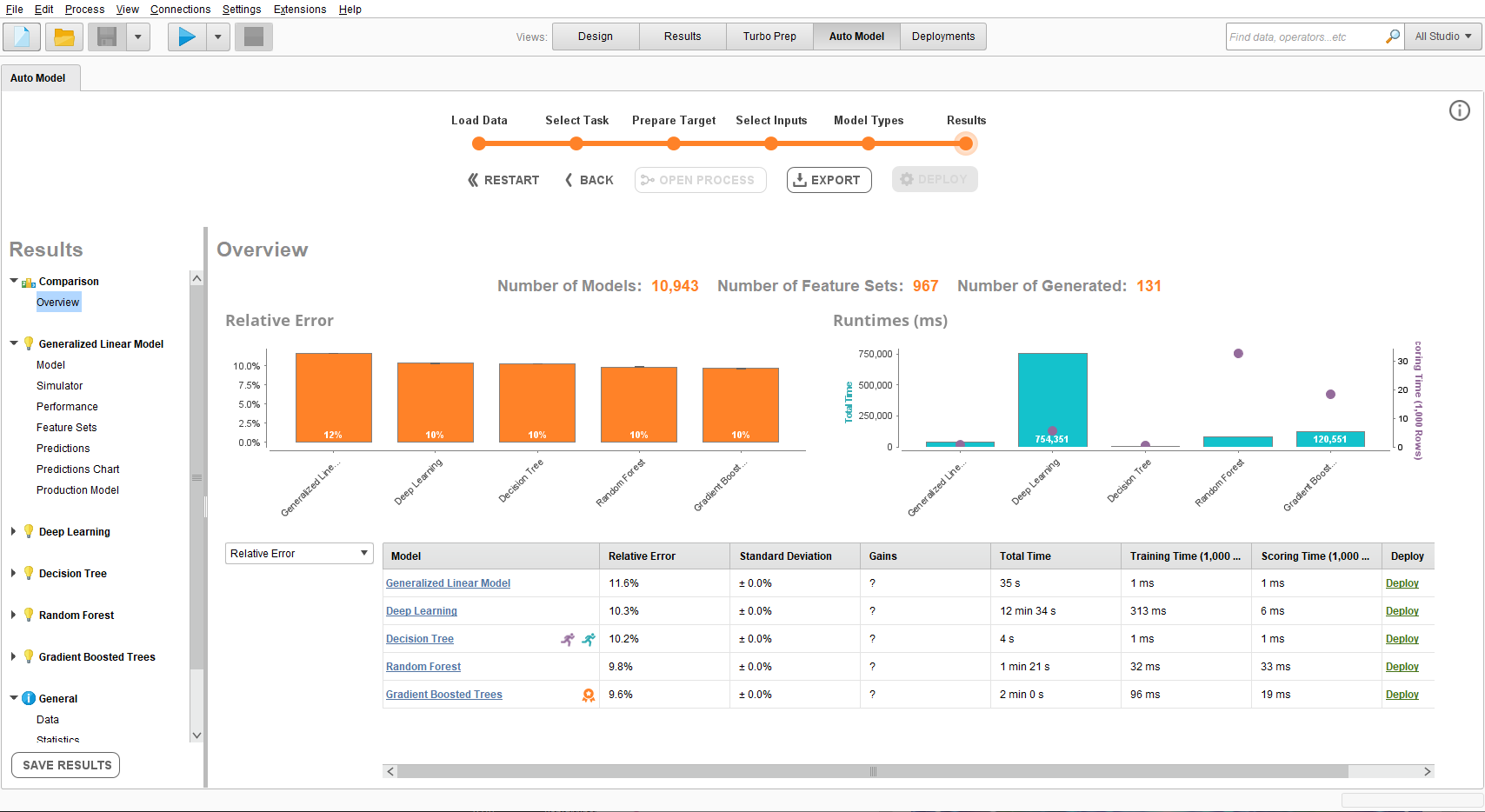
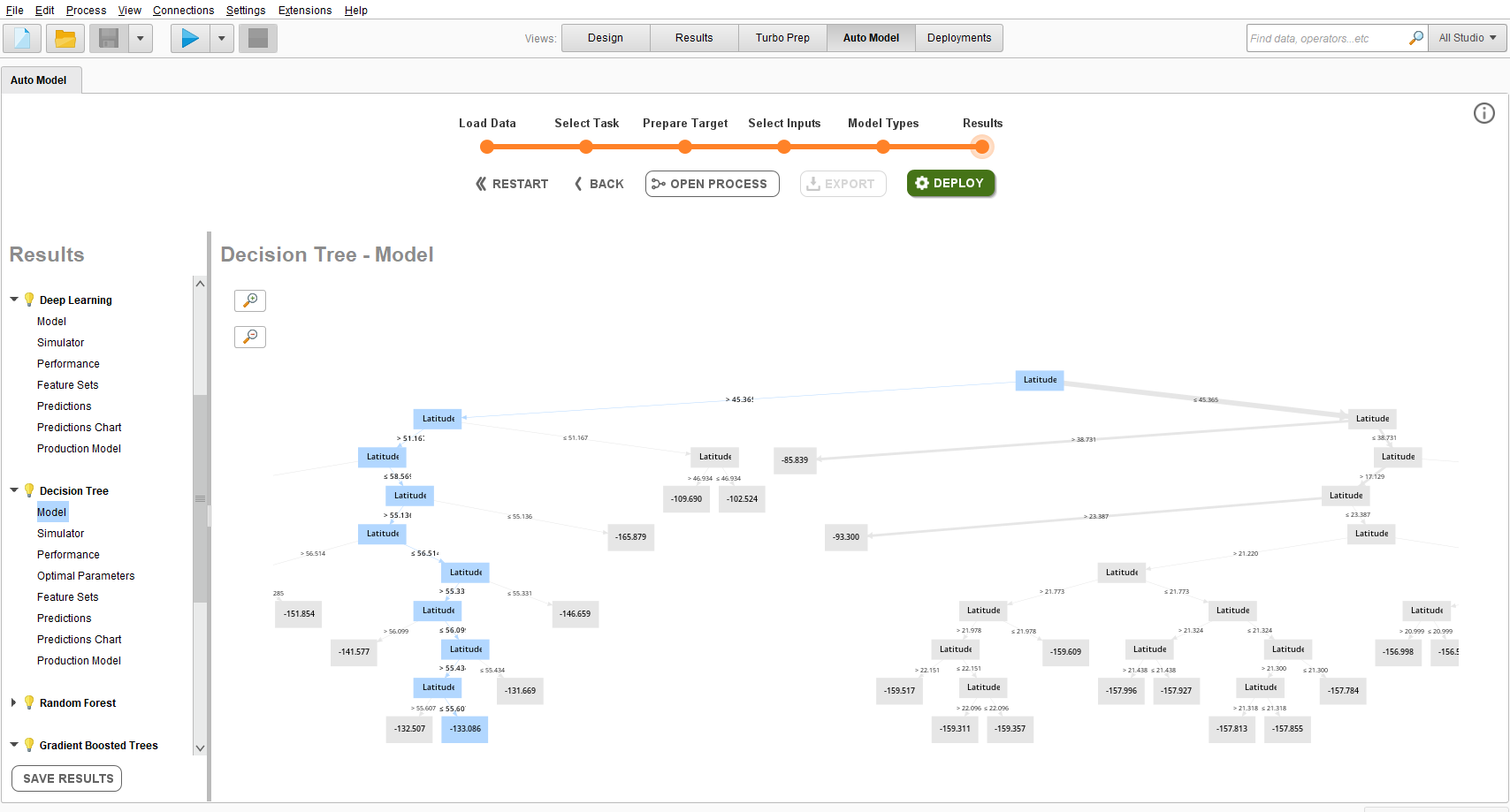
学習後のモデルを選択してみると、決定木モデルならば決定木が可視化できる。
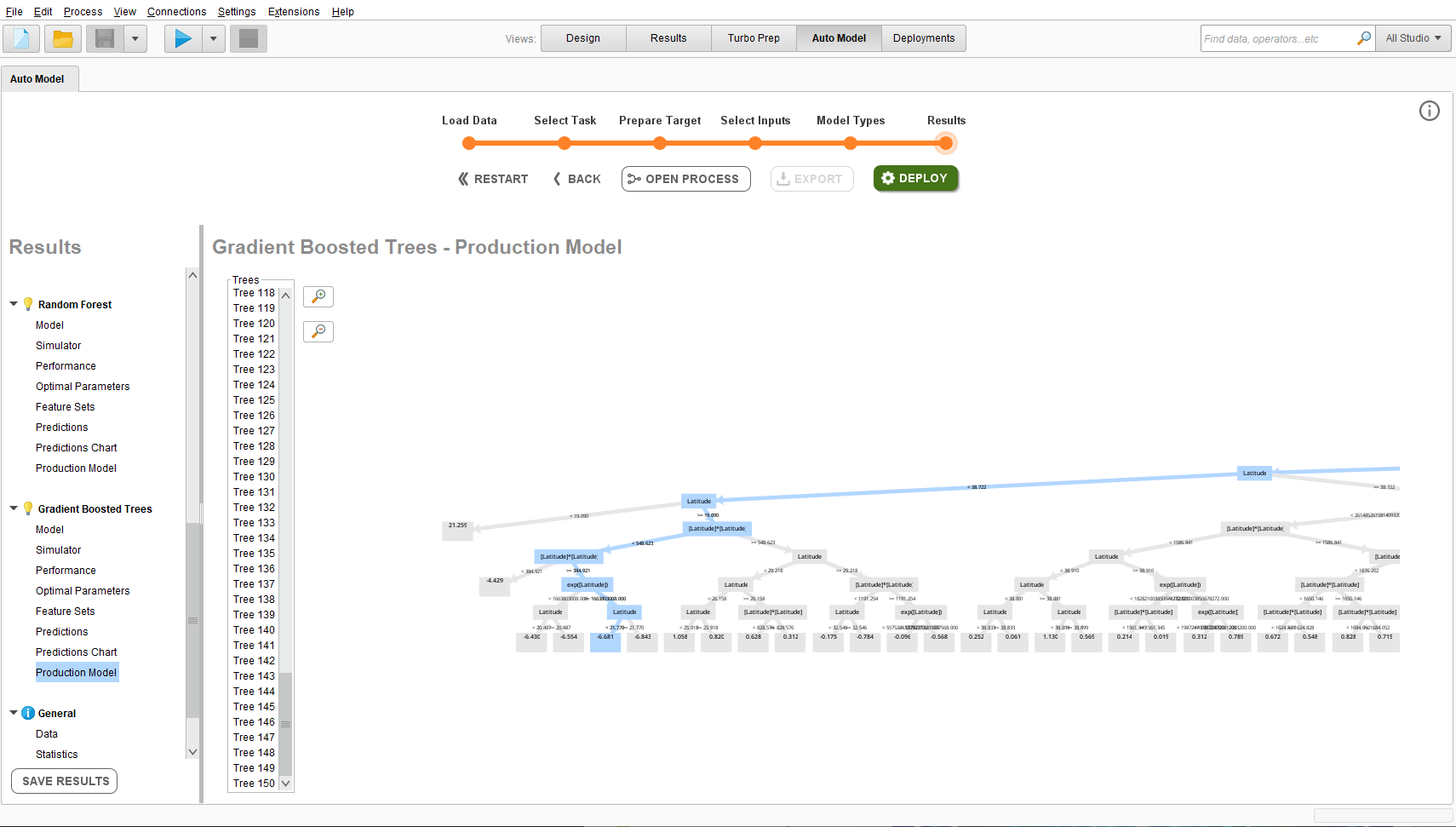
さらに、GBDTだと学習過程で出来ている決定木がすべて確認できたりするのがすごい。
この画像だと150本の木を確認できる。
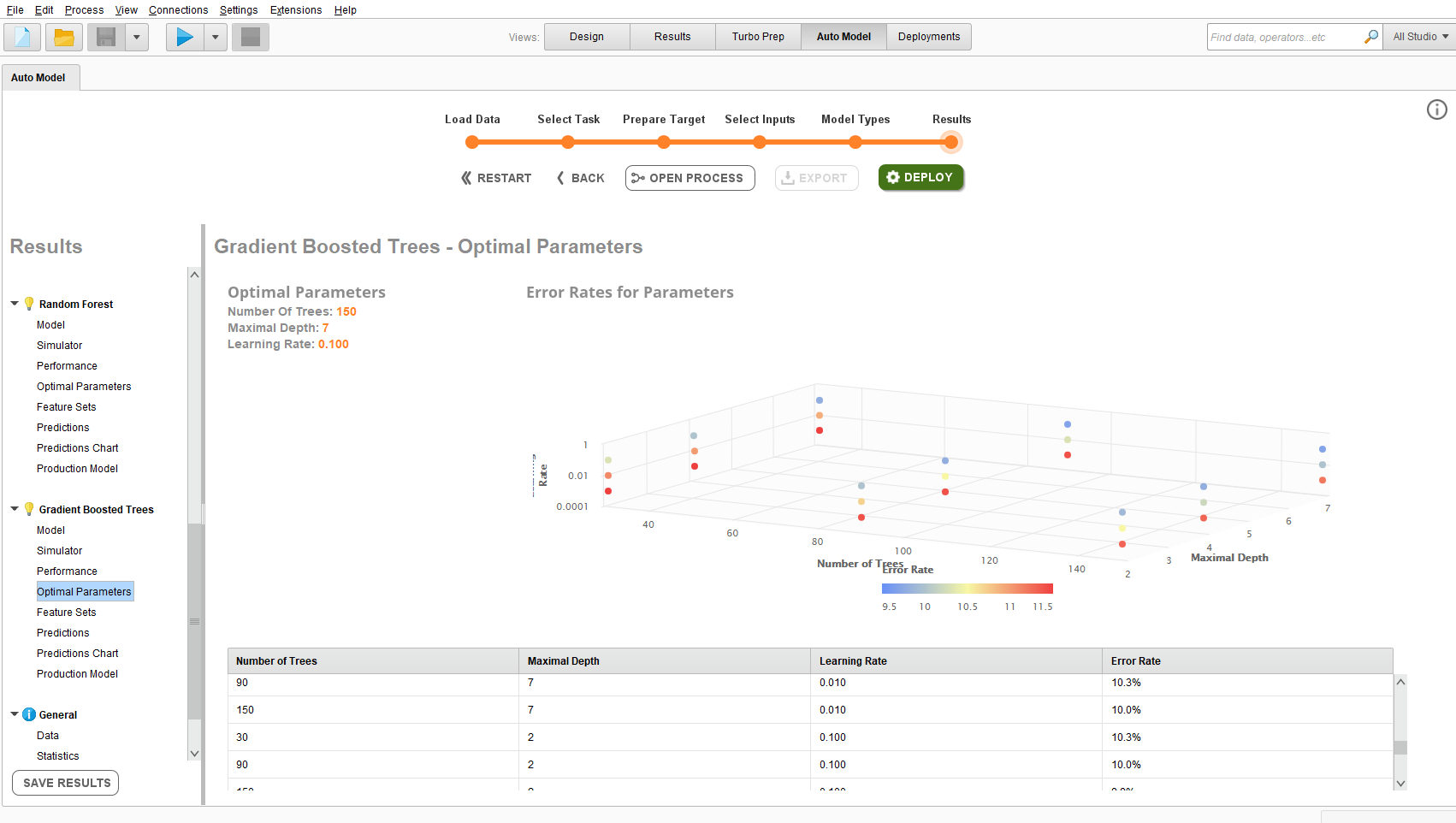
もちろんグリッドサーチの結果も表示してくれる。
作ったモデルを実運用していったらdeployボタンで実用できるようになるそうだけど・・・
無料版なのでここまで。
おわり
はやくpythonコーディングから解放されたいんじゃ~