カーネル法は求められる前提知識がいくつかあるので、未知で入門本を読んでも頭に入ってこなかった。
「カーネル法入門」を読む以前の問題だったので学んだことまとめとく。
初心者による初心者のための記事
係数ベクトルの話
線形回帰の幾何的な解釈で回帰係数を求めることについて少し記述した。
回帰係数は訓練データXを係数で増減させてラベルYへ近づけるものだった。
Y = \beta X \\\
もしXが二次元のデータならば次のようになる。
Xは簡単化のため0,1のみの基本的なベクトルとしている。
ラベルは11だったとする。
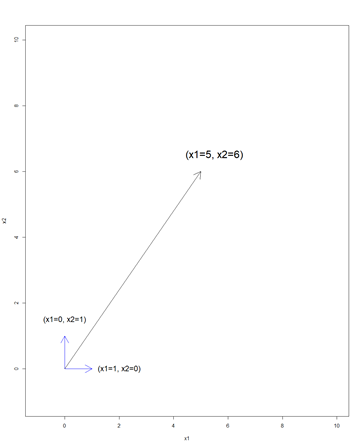
Xを列ベクトル、係数ベクトルを並べて表現するならば

上図のようになる。
ここで、少しだけ「基底」の話に触れる。
「基底の張る空間」とは、Xをもとに線形結合(定数倍)して表現できる空間のことで、
その空間を作り出すための最低限のベクトルを「基底」と呼ぶ。
この図でいえば、二次元空間を表現するためには縦軸横軸が必要なので、2つの基底が張る空間が議論の対象になる。
係数ベクトル[5,6]を見てみると、基底の定数倍の合成になっている。
つまり「係数ベクトル」も「2つの基底の2つの係数倍」で表現できることがわかる。
Y = \beta X \\\
Y = \alpha X^{T} X \\\
\beta = \alpha X^{T}
係数βはデータXの変数の数(次元数)だけあったが、αはデータXの基底の数(行数)だけ値を持っている
データXがM次元Nサンプル(行)ならば
\begin{pmatrix}
\beta_1 & \beta_2 & ... \beta_M
\end{pmatrix} =
\begin{pmatrix}
\alpha_1 & \alpha_2 & ... \alpha_n
\end{pmatrix}
\begin{pmatrix}
X_{11} & ... X_{M1} \\
X_{12} & ... X_{M2} \\
... & ... \\\
X_{1n} & ... X_{Mn}
\end{pmatrix}
正確には基底の数は必ずしもnであるとは言えない。
(データn個を全て基底とみなしても、一方を基底とみなすと表現できてしまうデータも存在するので)
一般化線形モデルの話(非線形)
一般化線形モデルは1970年代に登場し、カーネル法の登場する1990年代までに使われていた手法で、
その考え方の違いを紹介する。
データXとYの関係が非線形関係であったとき
x1=seq(1,10,0.1)
y= x1^3
plot(x1,y)
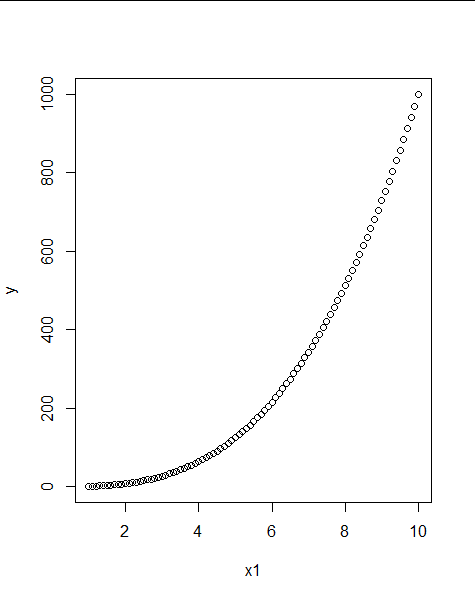
これを線形モデルで表すのは難しい
数学に詳しければ図を見ただけで
Y = X^3
のモデルが妥当かと見当つくかもしれない
実データはもっと複雑で、次元数も一次元ではない
そんな中から理想的なX,Yの関係を推測することはいくら数学に詳しくても無理
そこで、非線形モデル(関数)の候補をいくつか考えて、足し合わせたりすることで説明しよう
というのが「一般化線形モデル」の考え方
Y = a_1 X + a_2 X^2 + a_3 X^3 + ...
あとは複雑になったモデルに対してバイアス・バリアンス考えながら係数を推定していく
カーネル法の考え方
カーネル法の考えでは、「非線形なモデル」を考えると複雑になりがちなので、
「データの方を非線形変換して線形モデルを当てはめる」のである。
(一見やってることは一般化線形モデルと同じ。考え方が違うので後にデータを内積に拡張できたのかも。)
この「非線形変換する関数」を「カーネル関数」と呼びカーネル関数を使った手法群を「カーネル法」と呼ぶ。
(カーネル関数の定義は正確には違うので後で付け足す。カーネル法も様々あるが、SVM,カーネルPCA,ガウス過程回帰などなど。)
非線形変換して線形モデルとは、
X =
\begin{pmatrix}
x_{11} \\
x_{12} \\
... \\
x_{1n}
\end{pmatrix}
new X =
\begin{pmatrix}
x_{11}^3 \\
x_{12}^3 \\
... \\
x_{1n}^3
\end{pmatrix}
Y = \beta * new X
new_x1=x1^3
plot(new_x1,y)

となる。
特徴量エンジニアリングの話
kaggleなどで、有用な特徴量を探す行為を見たことがある人もいるかもしれない。
特徴量エンジニアリングの目的とはデータから新しくラベルYを説明するような変数を作る事である。
一般化線形モデルでは「モデルを複雑な非線形モデルとする」
カーネル法では「データを非線形変換する」
という行為が行われたが、どちらも「どれだけ複雑にしたらいいか、どんな非線形変換を施すべきか」という問題が付きまとう。
トコトン非線形にしてやろう、と思ったらどこまででもできる。
非線形にしたらしただけデータにはフィットする。
Y = .... + β_{10000} X^{10000} + ....
仮に10000次元まで拡張したとする。
一般化線形モデルでは、10000次元に拡張したデータXと、10000個の係数ベクトルβを所持していなければならない。
Y = \beta X \\\
ここで先ほどの基底で係数の話を思い出すと、
βはαとXで表現することができ、αはデータ行数n個だけで済んだ。
そしてYはXの内積とαで表現できていた。
Y = \alpha X^{T} X \\\
もし手元のデータが100行であったならば、どれだけデータを複数次元に拡張しようとも、100個のαとn×n行列のデータの内積行列だけ所持していればいい。
(2次の)多項式カーネルの例
もし、2変数x1,x2があった時、これを
(1,\sqrt{2}x_1,\sqrt{2}x_2,\sqrt{2}x_1 x_2, x_1 ^2 , x_2 ^2)
という拡張をして内積を得たならば
df<-data.frame(x1=iris$Sepal.Length[iris$Species=="versicolor"],
x2=iris$Sepal.Width[iris$Species=="versicolor"],
x3=iris$Petal.Length[iris$Species=="versicolor"])
d2 <- data.frame(L1=1,
L2=sqrt(2)*df$x1,
L3=sqrt(2)*df$x2,
L4=sqrt(2)*df$x2*df$x1,
L5=(df$x1)^2,
L6=(df$x2)^2)
d2$y <- df$x3
mod_1 <- lm(d2$y~as.matrix(d2[,colnames(d2)!=c('y')]))
summary(mod_1)
n=nrow(d2)
KK <- matrix(0,nrow=n,ncol=n)
for(i in 1:n){
for(j in 1:n){
KK[i,j]<- as.matrix(d2[i,colnames(d2)!="y"]) %*% t(as.matrix(d2[j,colnames(d2)!="y"]))
}
}
mod_2 <- lm(d2$y ~ KK)
summary(mod_2)
pred_lm <- predict(mod_1,as.data.frame(d2[,colnames(d2)!=c('y')]))
pred_KK <- predict(mod_2,as.data.frame(KK))
plot(c(1:length(d2$y)),d2$y)
points(c(1:length(d2$y)),pred_KK,col="red",type="p")
points(c(1:length(d2$y)),pred_lm,col="blue",type="l")

青い線が得られる。
(ランク落ちしてるし正しいか不明。修正案モトム。)
カーネル関数とカーネルトリック
係数βを求めるために10000次元の逆行列を求めなくていいのはだいぶ楽だけど、100行100列を扱うのも結構大変。
しかし、「データXを拡張して内積を計算する」という行為をしなくとも、
ある計算を順番にしていけば、「計算し終わった内積の結果が得られる」というのがカーネル関数の魅力的な性質。
このような関数が計算負荷を非常に軽くするため、まさにトリックということでカーネルトリックと呼ばれる。
特によく使われるのが、RBF(動径基底,ガウシアン)カーネルと呼ばれるもので、
これは10000次元どころか無限次元の特徴量を合成してから内積を取った結果と一致することから、
かなり複雑なモデルを考えることができる。
exp(-\gamma ||x-x'||^2)
(もちろん正則化がなければオーバーフィットしてしまう)
正則化が成り立つことに関してはリプレゼンター定理を調べて。
カーネル関数もなんでもいいわけではないが、ある性質を満たせば自分で設計することもできる。
変換後の行列が準正定行列となることが求められる。
自分でカーネル関数を作れるということは、数値以外にも言語モデルでは文字処理に都合のいい特徴量エンジニアリングを行うためのカーネルが設計できる、等、拡張の幅も広い。
以上
こういう説明が欲しかったけど見つからなかったので自分で作ってみた。
あとはカーネル法の本を読んで難しすぎて絶望するところまでが楽しみということで。
間違い等ご指摘大歓迎(オナシャス)