はじめに
平安の世はやることも少なく、昼は庭を、夜は月を見ながら時に音楽に合わせて歌を詠んだそうな。
王朝貴族たちは歌を送り気持ちを伝え返歌を返す、時には歌合を開催し勝負したり連歌を作りあったそうな。
私も現在は田舎に住んでおり、暇を持て余し星空を見上げながらラップを聞く日々を送っております。
ラップの中でもフリースタイル(ラップバトル)と呼ばれるものをよく聞いておりまして、これは音楽に合わせて即興で作った歌詞(ライム)を吐き出し、相手のライムに沿った歌詞を返し(アンサー)そのライムの構成のうまさや韻の踏み方、音楽との親和性の高さなどを基準に"フロアの盛り上がり"で勝敗を決めるゲームのことです。
(ご参考動画:R-指定 vs 晋平太 [ADRENALINE 2019 FINAL])
ここで必要なのが歌詞を載せるための音楽なのですが、この音楽のことを「ビート」であったり「トラック」と呼びます。
ビートとは
一般にラップバトルにおいて使われるビートは「メロディー(主旋律)」があり、これに一定のリズムを加えたものになります。
そのため、ラップのビートを聞いていると大抵の曲は周期的なドラムやベースのパターンが表れることに気づかれるかと思います。
大抵のラップ用ビートは2小節で一つのリズムが構成され、これが4回繰り返されます(もちろん例外も沢山ありますが説明の便宜上)。
下図の縦線での区切りが1小節で、下の楽譜は合計で8小節です。

この楽譜では4分の4拍子のリズムとなります。
一定のリズムで手をたたいた時に4回たたくと1小節が過ぎている計算になります。
この「拍(Beats)」の「間隔(速度,tempo)」を一分間あたりに何拍入れるかという「BPM(Beats Per Minute)」で表します。
ラップバトルと8小節の関係
バトルの中で「8小節4本」「16小節2本」のように呼ばれる場面は、「8小節にライムをのせて喋る→相手がアンサーを返す」これを四回繰り返すか、長い16小節で戦うか、を決めている場面です。
ラップバトルで頻繁に登場する楽曲としてSOUL SCREAMの「蜂と蝶」とよばれる楽曲がありますが、youtubeリンクの43秒から始まる「蝶のように舞い~ブンブンバァ」の二回の繰り返しで流れているBGMが8小節の一本として使われるビートになり、8小節の最後にはDJのスクラッチ音が入り相手のターンとなります。
音でいうと「E4→C#5→B4→C#5→B4」の繰り返し部分です。(鍵盤を弾けるサイト置いておきます)
8小節がどんなものかまだ理解できていなければ、8小節トラックアワードなるものがあったので、こちらを共有しておきます。
4拍のリズムを数えながら、合計32拍感じられれば8小節の概要が理解できているかと思います。
AIでビート作れないかなぁ
繰り返しのパターンがあれば、AI(機械学習)はパターンを学習して出力するアルゴリズムがあるので再現できそうだなぁ。とアイデアレベルで考えておりました。
趣味レベルで音声をスペクトログラムを使って分析していたタイミングだったので、ビートもスペクトログラムで解析しヒートマップを作ってみたところ、以下の画像のようにある程度のパターンが見られることがわかりました。
※スペクトログラムの説明は本記事ではいたしません

上図:蜂と蝶(SOUL SCREAM) のメルスペクトログラム

上図:合法的トビ方ノススメ(Creepy Nuts) のメルスペクトログラム
音楽の生成についての技術調査
音楽とAIについて調べているとMIDI(Musical Instrument Digital Interface)を使った「楽器音をどのタイミング、つなぎ順で繋ぐか」といった音楽の生成の事例はあるものの、MIDI化されていない波形データの生成はあまり見当たりませんでした。
やはり音楽のような波形生成はWaveNetやLSTMのような系列に特化したアルゴリズムで行うのかなぁ、と調べていたところSpecGANやMelGANなる手法を発見。
趣味なので効率も何も関係なく、メルスペクトログラムを画像として生成する方法について試してみることにしました。
データの収集
- 8小節のビート、wav形式、196曲分
- BPMの縛り無し
- スペクトログラムで同一長に整える
- ボーカルが入っていない
- スクラッチ音アリも可とする(スクラッチ音も再現したら面白そう)
- 音質のこだわり無し
- 楽曲のジャンルの縛り無し
上記のようなデータを収集しました。
楽曲ファイルはだいたい19秒~25秒のwavファイルです。
librosaパッケージを使ってメルスペクトログラムに変換後、128×880のデータになるように調節したものを学習データとしました。
ネットワークの構築
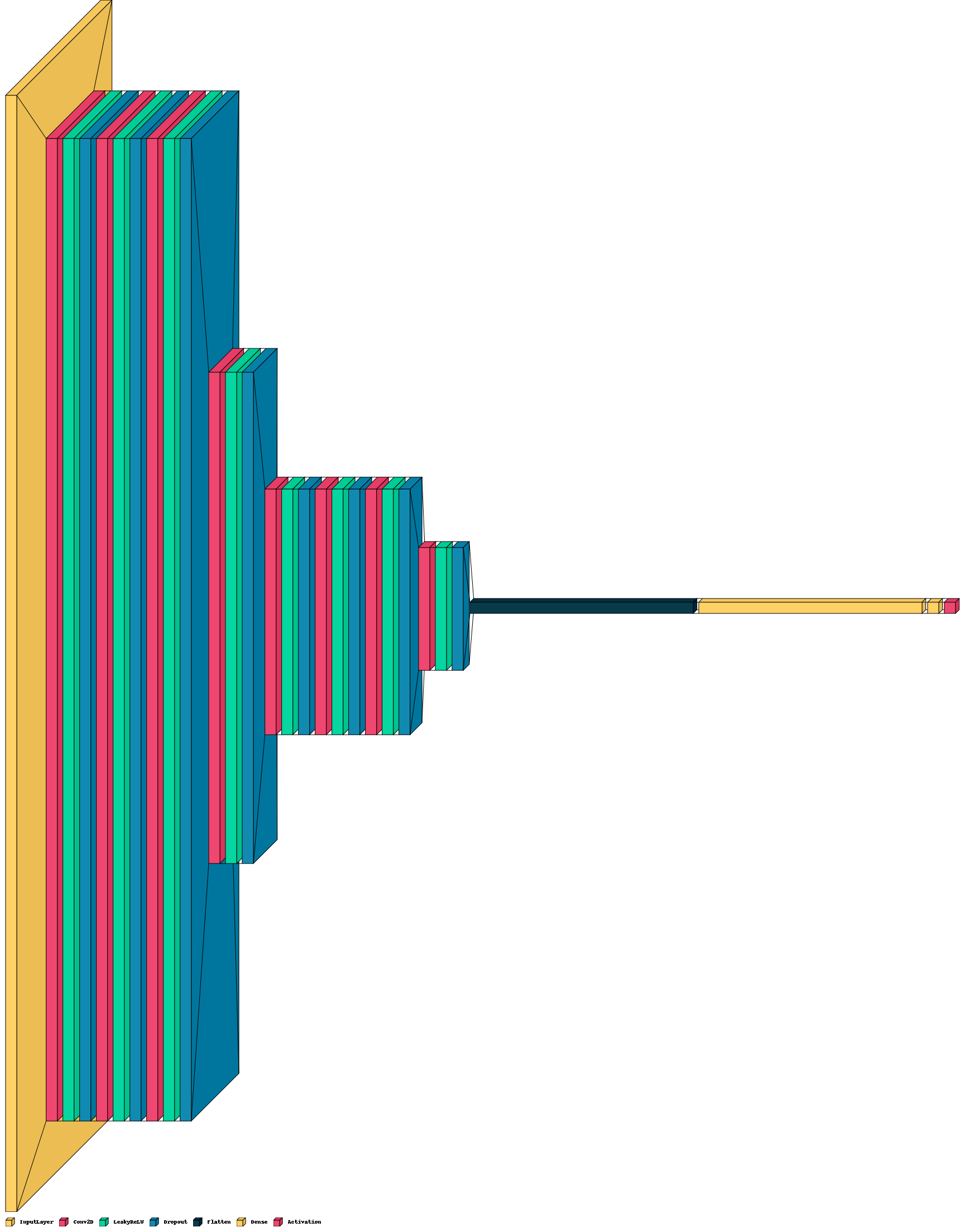
リファクタリングもしていないのでコード全文はさらしませんが、いくつかネットワークを試す中で最も良かったネットワークだけを載せておきます。
ネットワークはDCGANをもとに作成しています。
間違いご指摘大歓迎です。
def discriminator_model():
init = RandomNormal(stddev=0.02)
inputs = Input(shape=(128, 880, 1))
outputs = Conv2D(filters=64,kernel_size=(5, 5),padding="same",strides=(1, 1))(inputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=64,kernel_size=(5, 5),padding="same",strides=(1, 1))(inputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=64,kernel_size=(5, 5), padding="same",strides=(2, 2))(inputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32,kernel_size=(5, 5), padding="same",strides=(1, 1))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32,kernel_size=(5, 5),padding="same", strides=(1, 1))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32, kernel_size=(5, 5), padding="same", strides=(2, 2))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32,kernel_size=(5, 5), padding="same",strides=(2, 2))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32,kernel_size=(5, 5),padding="same",strides=(1, 1))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32,kernel_size=(5, 5),padding="same",strides=(1, 1))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Conv2D(filters=32, kernel_size=(5, 5), padding="same",strides=(2, 2))(outputs)
outputs = LeakyReLU()(outputs)
outputs = Dropout(0.2)(outputs)
outputs = Flatten()(outputs)
outputs = Dense(units=5000)(outputs)
outputs = Dense(units=1,kernel_initializer=init,bias_initializer=init)(outputs)
outputs = Activation("sigmoid")(outputs)
model = Model(inputs=inputs, outputs=outputs)
return model
def make_generator_model():
init = RandomNormal(stddev=0.02)
inputs = keras.Input(shape=(15000,))
outputs = Dense(8*55*32, use_bias=False)(inputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU(alpha=0.2)(outputs)
outputs = Reshape((8, 55, 32))(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(2, 2), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32,kernel_size= (5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(2, 2), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32,kernel_size= (5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32,kernel_size= (5, 5), strides=(2, 2), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(filters=32, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False)(outputs)
outputs = BatchNormalization()(outputs)
outputs = LeakyReLU()(outputs)
outputs = Conv2DTranspose(1, kernel_size=(5, 5), strides=(2, 2), padding='same', use_bias=False)(outputs)
outputs = ReLU()(outputs)
model = Model(inputs=inputs, outputs=outputs)
return model
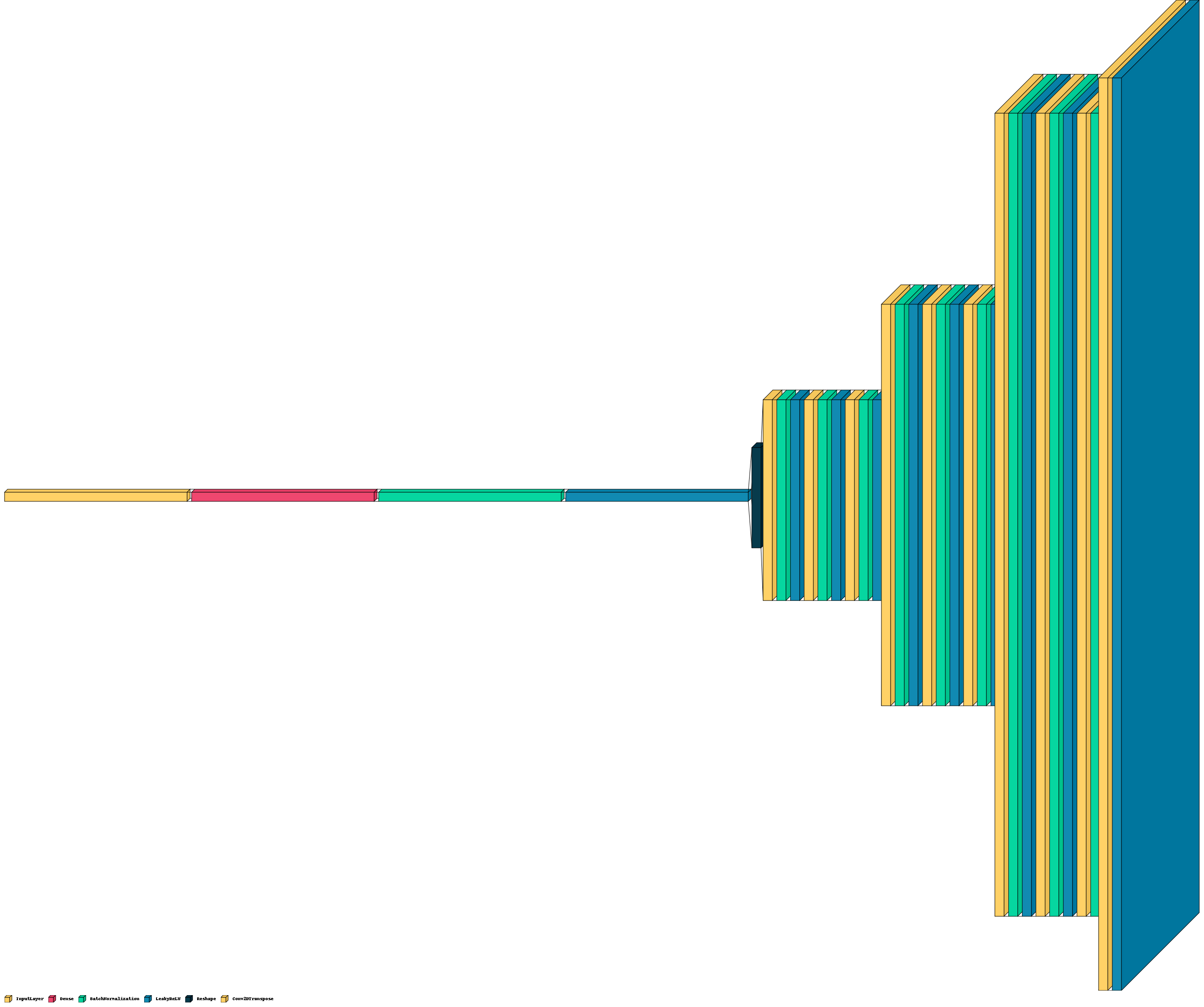
調節しながら確かめた項目のため細かい検証や、再現性の確認はしていませんが、以下のようなことが経験的にわかってきました。
- フィルタは5よりも大きくすると高音域やメロディーラインを生成できなくなる
- ノイズは5000程度でもリズムっぽいものは生成可能
- generatorの出力にLeakyReLUを使用すると出力にマイナスが生まれるものの、4拍のリズムが生成しやすいように感じる
学習の際のコスト関数に関してはkerasドキュメントそのままを使っています。
学習データのバッチはランダムで選んだ5曲をひとまとめにして入力しました。
作ってみたから。ビートモクソモネェけど聞きな(parody of DJ RYOW)
生成したメルスペクトログラムをエポック毎に逆フーリエ変換しました。
学習回数が増えるにつれて、どのような曲になったか聞いていただきましょう。
生成したメルスペクトラムを楽曲に直して、よさげな生成結果だけをつなげて動画にしました。
import librosa
#wavの変換
#y, sr = librosa.load(wav_file)
#mel_spec = librosa.feature.melspectrogram(y=y, sr=sr)
#生成画像の変換
generated_image = generator(noise, training=False)
S_inv = librosa.feature.inverse.mel_to_stft(np.array(generated_image), sr=sr)
inv_y = librosa.griffinlim(S_inv)
wavをメルスペクトログラムに変換すると、デフォルトでは128列、0以上の数値、が生成されます。
reluを活性化関数とした場合
画像生成の最終出力層を0以上になるreluで変換した結果、以下のようになりました。
- 動画内 1分48秒 epoch = 57 のころからノイズよりはリズムを感じるような音になってきます。
- 動画内 2分50秒 epoch = 116 では拍に合わせたビートではないですが、ベースのような低い音が聞こえ始め、リズムさえ合えばビートのようになるのではないかと感じられます。
- 動画内 3分36秒 epoch = 132 ではベースだけでなくクラップ音が聞こえ始めてきました。スペクトログラムも今まで上辺付近だけが赤色でしたが、図の中央付近まで赤色が伸びてきています。元の音源も同様の波形が見られるため良い兆候です。
- 動画内 4分13秒 epoch = 160 ではゆがんだキックドラムのような音が聞こえます。16ビートのような細かいビートを刻んでいるようにも聞こえます。
- 動画内 5分32秒 epoch = 256 では4拍のなかで裏拍もとりながらリズムを作り出しています。
ベース、クラップ、甘く聞き取ればハイハットのような高い音も聞き取ることができました。ただ、主旋律になる部分はまだまだ生成できないようで、最低限の共通するリズムを生成するだけのようです。
leakyreluを活性化関数とした場合
leakyrelu を活性化関数とする場合、負の小さな値が発生してしまうのですが、これも一応試してみたところ以下のようになりました。
- 生成初期のころのコメントは上記reluと同じなので省略します。
- 動画内 2分45秒 epoch = 138 および epoch = 157 では曲がダークメロディのようなスローテンポのビートになってきています。入力に使った楽曲の中でもダークメロディが多かったので、leakyreluのほうがビートの特徴をとらえやすいのかもしれないと感じ始めました。また、どちらも曲の終わりにスクラッチ音のようなものが聞こえます。reluではスクラッチ音まで再現できた曲はあまりなく、これもleakyreluの強みなのかもしれません。
- 動画内 5分12秒 epoch = 195 ノイズが多いですが、低音、中低音、クラップ、それぞれがリズムを持ってはっきりと聞こえてきます。
- 動画内 6分14秒 epoch = 253 ではノイズも小さく、拍に対してベースを入れるタイミングもバッチリなように聞こえます。
全ての音が聞きたい方はこちら。
さいごに
DCGANにはそこまで期待していませんでしたが、「ヒップホップのビート」を生成しようと頑張ってみたところ、主旋律はムリでもベース音をリズムを持ったまま生成することはできたのかなぁと思います。
(親バカの甘々判定ですかね?)
ネットワークの構造がMelGANでは工夫されているので、それを試してみたり、データのさらなる追加収集や今回行わなかったデータ水増し等も試してみたいと思います。
層の構造は今回のままでも活性化関数やフィルターの調整を行うことで生成された楽曲にどのような違いが出るかは確認してみたいところです。
本件をベースとし、今後改良していきたいと考えておりますが、、、、、、、
改良版については次回の記事をお待ちください。
(失踪しなければ)
余談
データを使った記事ということで、ちゃっかりdelikaのプログラムに本記事をエントリしようと思います。