Power Automate Desktop とは
ローコード開発プラットフォームの Power Platform のうち自動化を担当する Power Automate ですが、APIがない、既存のデスクトップアプリケーションやWebサービスなども、クラウド連携したいという要望に応えるために、RPA機能として追加されたものが、Power Automate Desktop です。
このような形で、アプリケーションの操作を指定し、クラウドサービスである、Power Automate から呼び出し、実行結果を取得することで、既存のアプリケーションも簡単にクラウド連携ができるようになりました。
OCR アクション
Power Automate Desktop は、アプリケーションの代行操作以外にも、様々なアクションが用意されています。
その中で、OCRというアクションがあるので開いてみましょう。
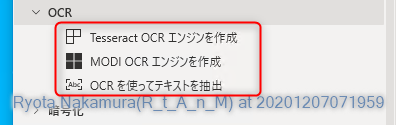
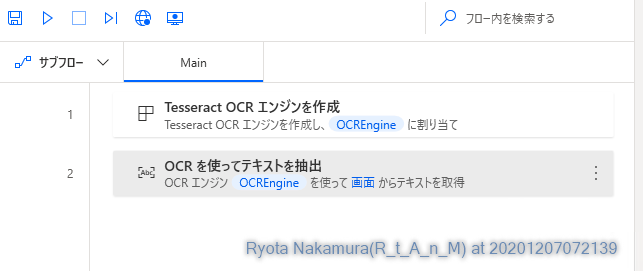
アクションを見る限りだと
Tesseract OCR もしくは MODI OCR のエンジンを作成して、そのエンジンを使ってテキスト抽出を行うという流れのようですね。
試しに簡単な英文の画像を使って抽出してみましょう。
Tesseract OCR
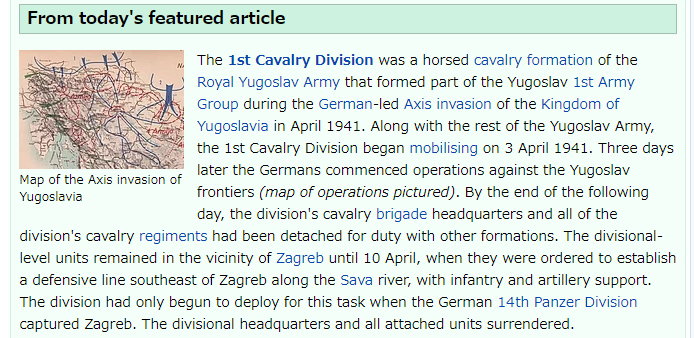
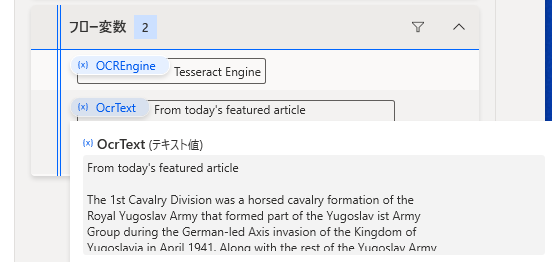
とりあえず、英語の Wikipedia のトップページにあるこちらの画像を Tesseract OCRを使って読み込ませてみます。
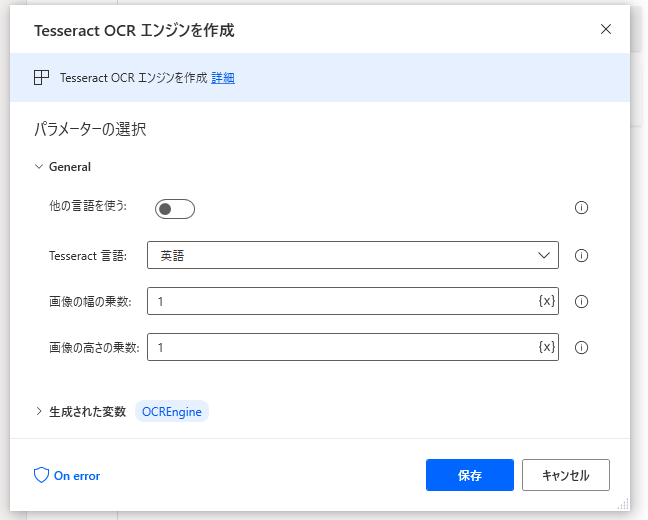
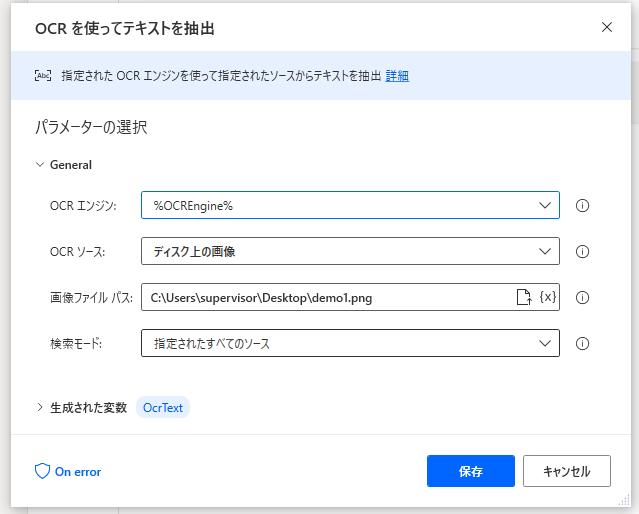
各アクションの設定値はこんな感じです
実行した結果は・・・うまく取れてますね!
MODI OCR
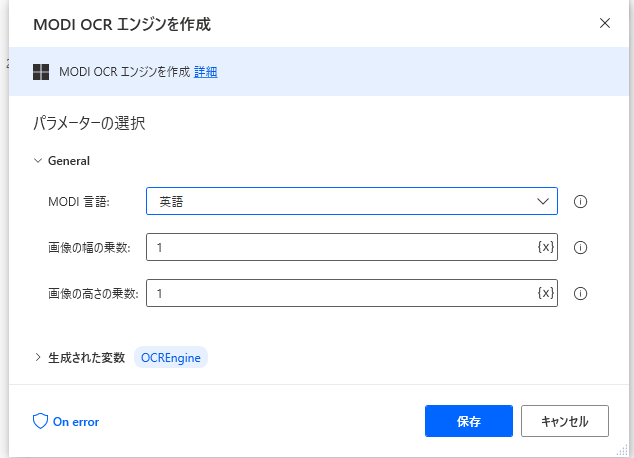
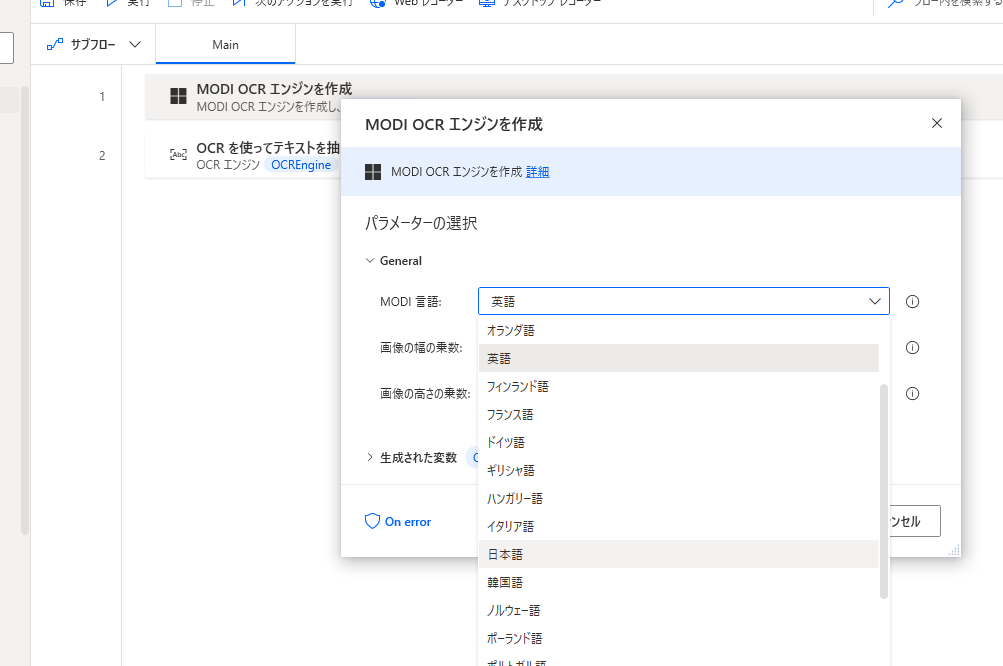
今度は、MODI OCRエンジンを使ってみます。
MODI OCRのエンジン設定はこんな感じです。
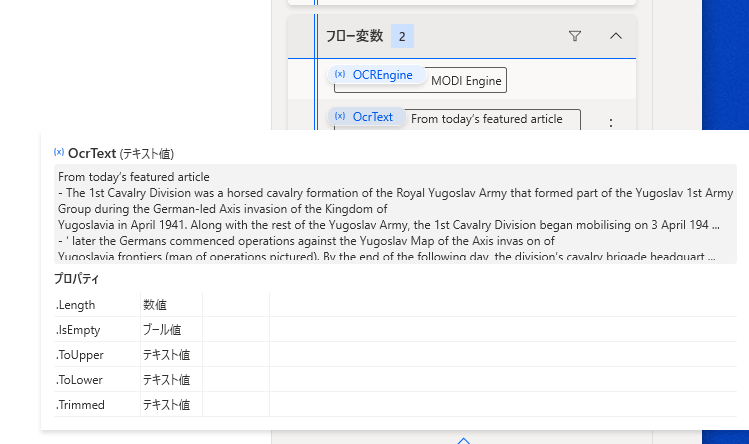
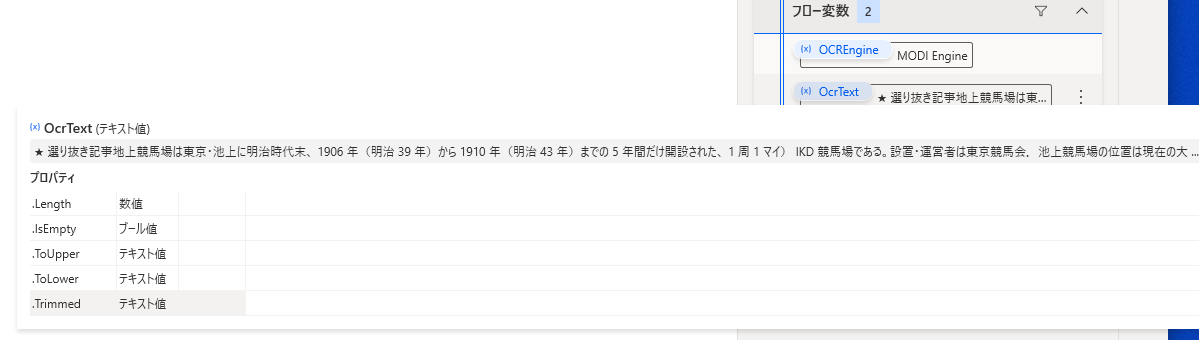
実行してみると・・・

あらま、ランタイムエラー・・・
そもそもMODI OCRってなんぞ?
MODI とは Microsoft Office Document Imaging という機能だそうで、 Office 2007 までは標準で入っていた機能のようです。
Wikipedia の情報だとこちら
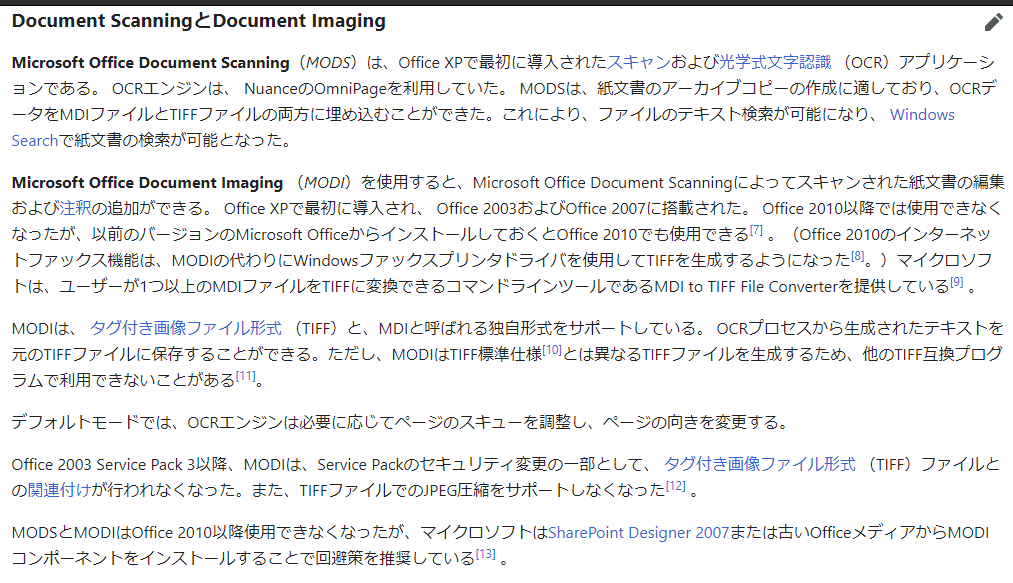
出典元:Wikipedia Microsoft Office ツール
とりあえず、Office 2007 をインストールした上でもう一度試してみたところ、問題なく抽出することができました。
SharePoint Designer 2007 にも含まれているようです。
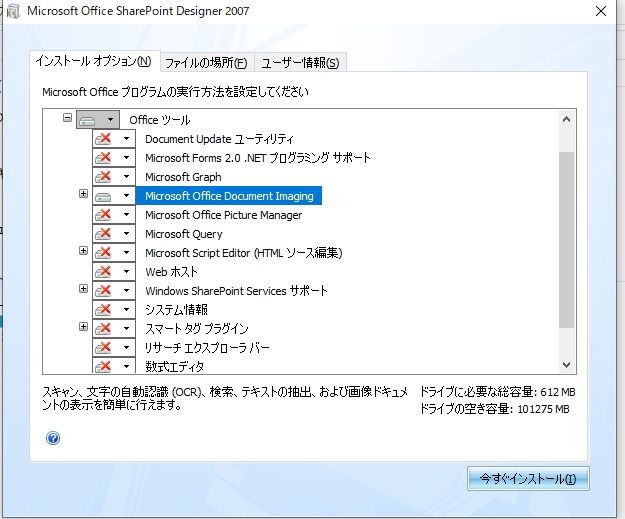
・・・が、既にサポート終了につき配布されていません。
MSDNライブラリからダウンロードすることは今のところ可能ですので、契約されている方はこちらからダウンロードしましょう。
日本語のテキストを抽出
MODIの場合は、日本語も標準で抽出できるようです。
というわけで、今度は日本語Wikipedia のこちらを読み込ませてみます。

MODI OCR
Tesseract OCR
標準だと日本語が入っていません。
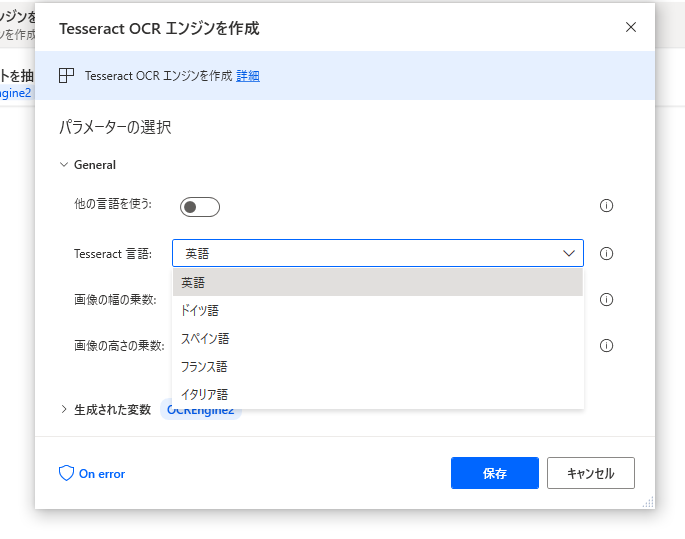
ほかの言語を使うを有効化すると、言語データを求められます。
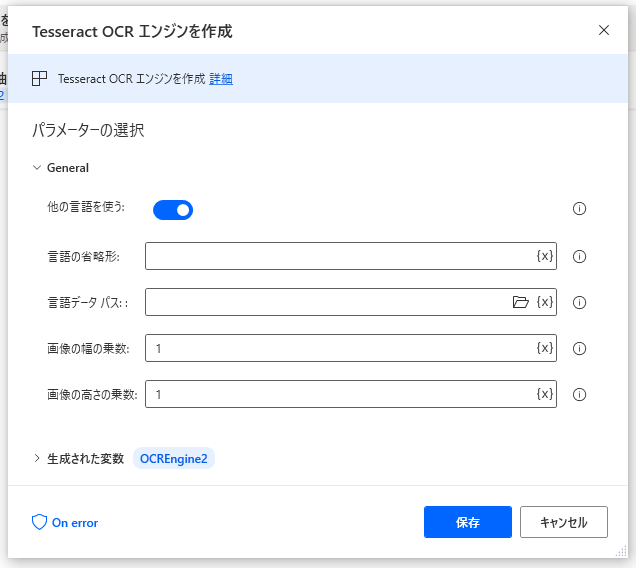
言語データは、Tesseract の github ページのインストーラーに含まれているようです。
GitHub - Tesseract at UB Mannheim
上記リンクからインストーラーをダウンロードし、インストールしてみましょう。
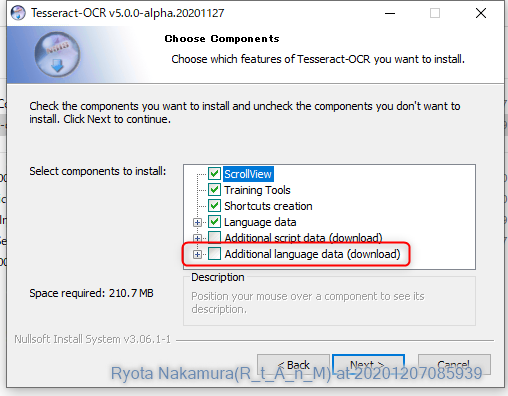
インストール時は、この Additional language data にチェックを入れることをお忘れなく
インストールが完了したら、言語データパスに、インストール先のフォルダの tessdata を指定します。
更に、言語の省略形として jpn を指定します。
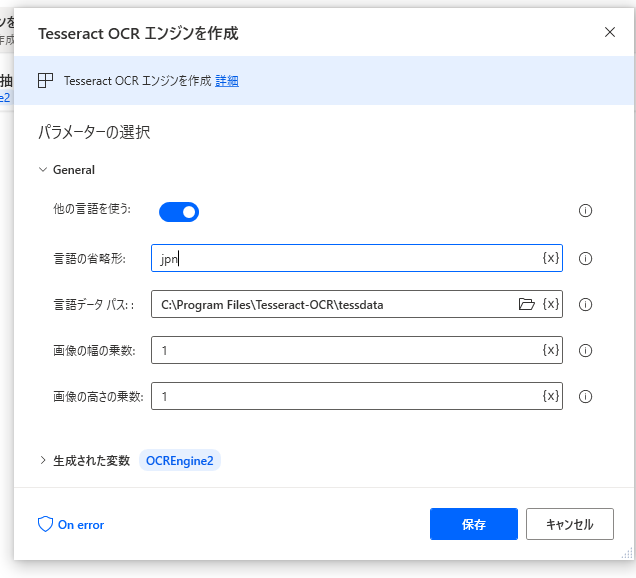
では、試してみましょう。

まとめ
Power Automate Desktop にて OCR アクションを使うやり方をまとめてみました。
実際には、画像ファイルだけでなく、画面全体や、アクティブウィンドウの画面もOCRの対象にすることができたりと、かなり幅広い設定ができるようですので、皆さんもぜひ色々試してみてください!