2021年1月,生まれて初めてニューラルネットワークを実装してみました.
まぁ,やってることは書籍やwebページの真似事なんですけどね.
I am a 初心者. なのでキビシイつっこみはご勘弁を![]()
参考にしたwebページはこちら
参考にした書籍は → PyTorchニューラルネットワーク 実装ハンドブック
ここからサンプルコードがダウンロードできますので,それをベースに部分的に改変していきました.
1. 画像の準備
Yahoo画像検索のスクレイピングで,各ラケットの画像を収集します.
ここのページを参考にしました↓
以下の2行を自分の好きなように変えるだけでOKです![]()
バドミントンラケット,スカッシュラケット,テニスラケットの検索ワードで画像を収集します.
word = "スカッシュラケット" # 検索するワード
save_dir = "./images/Squash" # スクレイピングした画像を保存するディレクトリパス
次に,収集した画像を64×64ピクセルに一括リサイズします.
ここのページを参考にしました↓
知識も技術も無い私は,ネットからパクることしかできません.
パクりながら学習していく現代学習のスタイル~(否,古代から続く伝統的な学習スタイルかw).
最終的に,訓練データとして(3種のラケットあわせて)717枚,テストデータは種類毎に50枚(=計150枚)用意しました.訓練データを5枚だけ例示します:

左から,テニス,バドミントン,スカッシュ,スカッシュ,テニスです.
2. ニューラルネットワークの構築
Pytorchでニューラルネットワークを2種類つくりました.
一つ目はAlexNetの構造を真似したネットワークで,二つ目はシンプルな2層の畳み込みと2層の全結合層をつなげたものです.
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=256, out_features=3, bias=True)
)
)
ConvNet(
(features): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): ReLU()
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): Dropout2d(p=0.25, inplace=False)
(5): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): ReLU()
(8): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Dropout2d(p=0.25, inplace=False)
)
(classifier): Sequential(
(0): Linear(in_features=10816, out_features=200, bias=True)
(1): ReLU()
(2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=200, out_features=3, bias=True)
)
)
3. 学習&推論
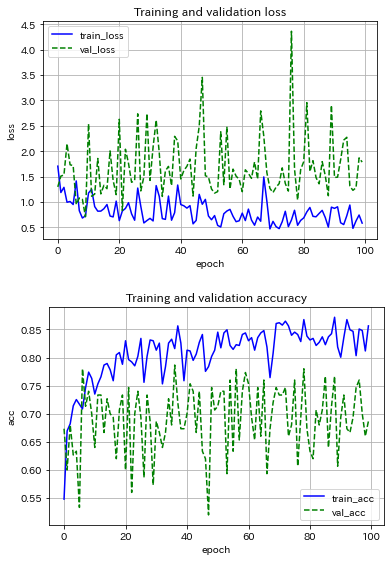
まずは,AlexNetライクなCNNモデル(最適化アルゴリズムはSGD)を用いて,ミニバッチサイズの影響を調べました.サイズを5, 10, 20と変えてみた場合の結果を以下に示します.
(クリックすると拡大表示されます![]() )
)
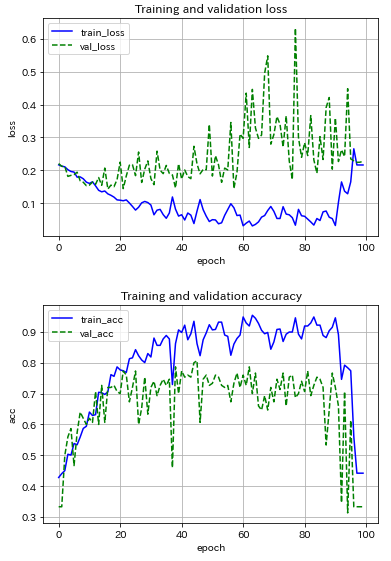 |
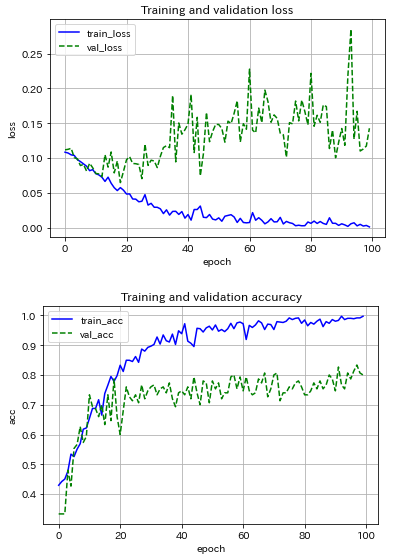 |
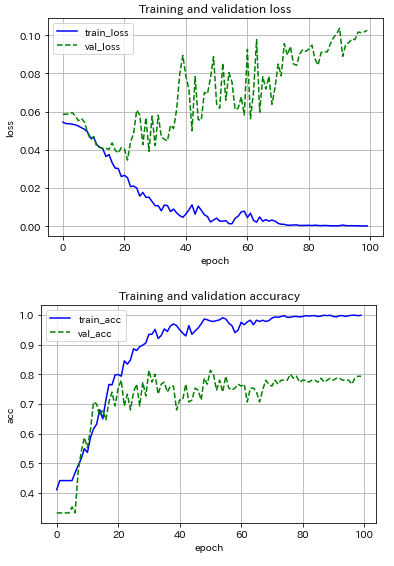 |
|---|---|---|
| ミニバッチサイズ=5 | ミニバッチサイズ=10 | ミニバッチサイズ=20 |
サイズ5だと結果が不安定,オンライン学習寄りの結果だろうから当然か.サイズ数を増すほど結果の振動が抑制され,サイズ20の場合では約70エポックで収束している.テストデータに対する推論精度が80%程度で頭打ち.え~,こんなもんなの~?!90%は超えたい!
次に,ミニバッチサイズを20に固定して,最適化アルゴリズムをAdamに変えてみた.学習率をSGDの10分の1で与えているにもかかわらず,収束の程度がSGDと比べて早い.ただ,推論精度は落ちてしまった(局所最適解で留まっている?)ので,SGDの方が良いのかな![]() .
.
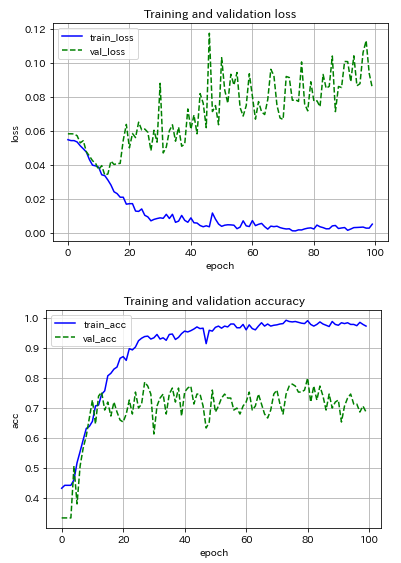
次に,シンプルなCNNモデルを用いて,ミニバッチサイズ20に固定し,最適化アルゴリズムの影響を調べました.試したのはSGD, Adam, RMSpropの3種の神器.
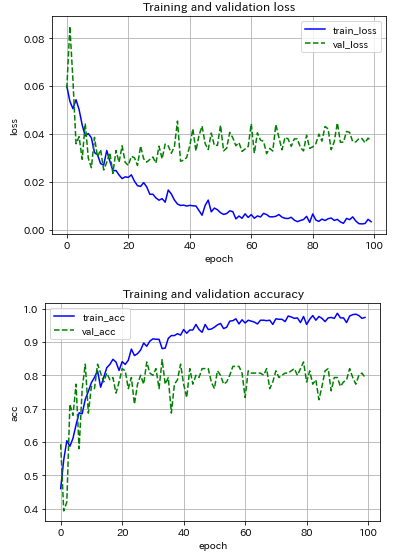 |
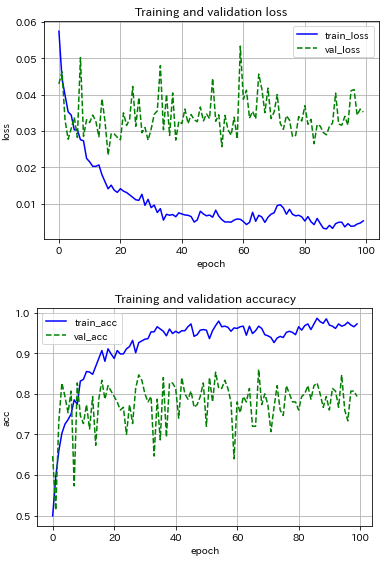 |
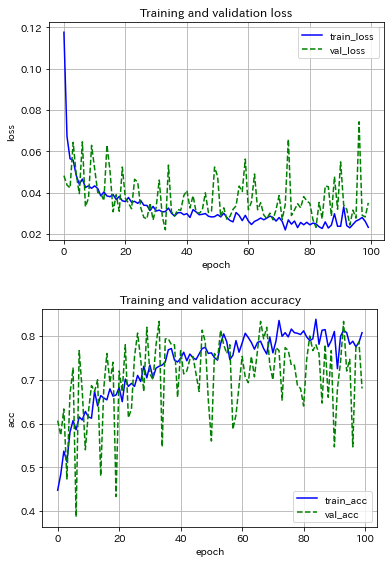 |
|---|---|---|
| SGD | Adam | RMSprop |
RMSpropは問題外として,SGDとAdamの結果を比較すると,推論精度は同程度だが,Adamは精度の振り幅が大きく,本分類問題ではメリットが感じられません.
CNNモデルの構造の違いに着目すると,シンプルなCNNモデルにはバッチ正規化とDropout(p=0.25)を導入しているが,過学習の程度があまり改善していない(もっとtrain_accとval_accが近づいても良いのだが...).推論の精度は両者とも約80%...
テニスラケットとスカッシュラケットの区別は素人では難しいですからね.そう考えると上出来と考えてよいのでしょうか.下記のように,正解ラベルと推論結果を1つ1つ比べても,特段,判別が難しいラケットの種類は無いようで,バドミントンもスカッシュもテニスも同程度の割合で誤判別しているみたい.
数字の意味 → 0: バドミントン,1: スカッシュ,2: テニス
テストデータ数 = ラケット種毎に50 × 3種 = 150
ミニバッチサイズ = 20 なので,150 ÷ 20 = 7 余り10
よって,バッチ番号8のみデータ数10になっています↓
Batch # 1
画像の正解ラベル: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
画像の推論結果: tensor([0, 0, 0, 0, 0, 0, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
-----------------------------------------------------------
Batch # 2
画像の正解ラベル: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
画像の推論結果: tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 2, 0, 0])
-----------------------------------------------------------
Batch # 3
画像の正解ラベル: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
画像の推論結果: tensor([2, 0, 0, 0, 0, 2, 0, 0, 1, 0, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1])
-----------------------------------------------------------
Batch # 4
画像の正解ラベル: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
画像の推論結果: tensor([1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 0, 2, 0, 1, 2, 1, 2, 1])
-----------------------------------------------------------
Batch # 5
画像の正解ラベル: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
画像の推論結果: tensor([1, 1, 2, 1, 1, 1, 1, 2, 2, 1, 1, 0, 1, 2, 1, 1, 1, 1, 1, 1])
-----------------------------------------------------------
Batch # 6
画像の正解ラベル: tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
画像の推論結果: tensor([2, 2, 1, 2, 2, 2, 1, 2, 2, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2])
-----------------------------------------------------------
Batch # 7
画像の正解ラベル: tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
画像の推論結果: tensor([2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2, 1, 2, 2, 2, 1])
-----------------------------------------------------------
Batch # 8
画像の正解ラベル: tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
画像の推論結果: tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
-----------------------------------------------------------
どうしても納得がいかないので,ResNet18を使った転移学習に踏み切りました.
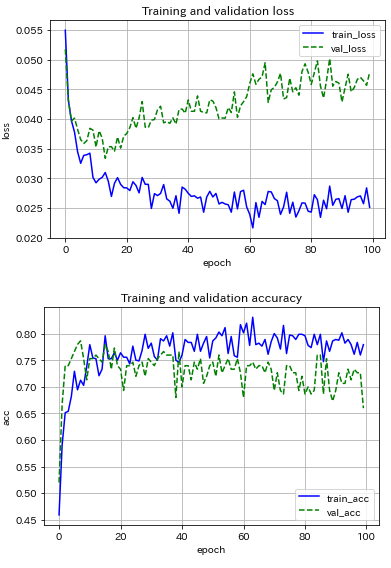
うーん…最終層以外の重みを凍結している(つまり,最終層の重みだけ更新している)ので,この予測器の表現力はこの程度か.過学習の程度は改善したかな.ちなみに,AlexNetを使った転移学習もしましたが,もっとダメでした↓
4. 特徴マップを見てみたかったので
シンプルなCNNモデルに対して,中間層の特徴マップを可視化しました.
ここにあるコードをパクりました![]()
特徴抽出に用いた画像はこのバドミントンラケットです↓

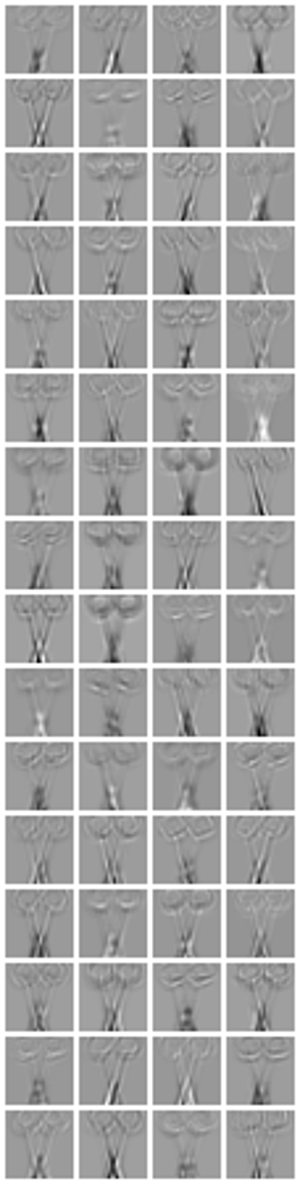
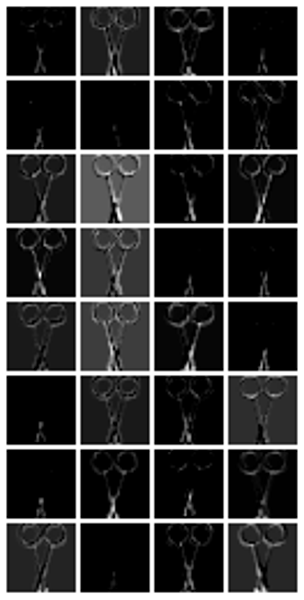
まずは第2畳込み層の特徴マップを示します(26×26ピクセルで64枚).
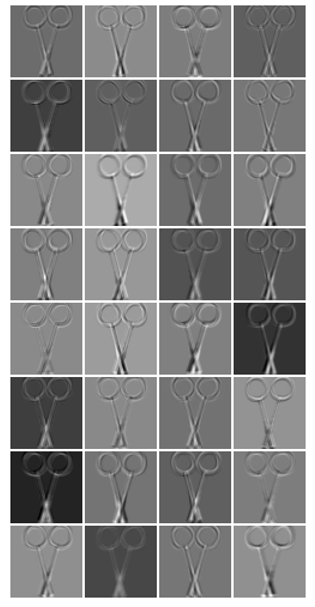
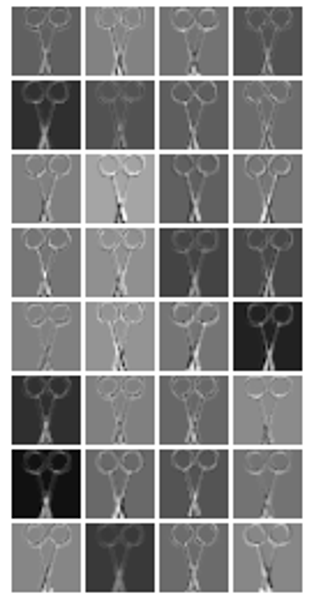
第1畳込み層,それにMaxプーリングを施したもの,さらにReLUを通した後の特徴マップを順に示すとこんな感じ
 |
 |
 |
|---|---|---|
| 第1畳込み層後 | Maxプーリング後 | ReLU通過後 |
それぞれサイズが60×60ピクセル,30×30ピクセル,30×30ピクセルで各32枚です.
正直,特徴マップのグレースケール画像を見ても,各カーネルがどの特徴を炙り出しているのか判別できるレベルに私は至っていません.←ネ申のレベルと呼ばせていただきたい,ほんと.
5. あとがき
今回,ハイパーパラメタはネット情報などを参考に適当に決めました.模範解答としてはグリッドサーチ+クロスバリデーションでチューニングするのでしょうが,正直言いますとここは完全に手抜きしました.これからOptunaを勉強しますっ(^^ゞ
以上,ニューラルネットワークの初めての実装報告でした.
「学ぶことは真似ることから始まる」と申しますし,この記事に学術的な価値は無いと思いますが,私自身はこの課題に取り組むことで実装の力が多少はついたと思います.押忍!