本記事では、Palantir FoundryのLightweight Transforms機能が、Merckのようなグローバル企業でどのようにデータ処理の効率を劇的に向上させているかを紹介します。従来のSparkに依存したアプローチから、DuckDBのような最新のコンピューティングエンジンを活用することで、処理時間を最大10分の1に短縮し、大幅なコスト削減を実現した事例を深掘りします。
目次
- Part 1: 現代のデータパイプラインが直面する課題
- Part 2: Lightweight Transformsによる解決策
- Part 3: Merckにおける成功事例
- Part 4: なぜ高速化が可能なのか?技術的背景
- Part 5: 未来への展望
- まとめ
Part 1: 現代のデータパイプラインが直面する課題
Core Message: 大規模なデータ処理は、従来の分散処理エンジンだけでは非効率な場合があり、時間とコストの増大という課題を抱えています。
Chapter 1.1: 伝統的な分散処理のオーバーヘッド
多くの企業では、ビッグデータ処理の標準としてApache Sparkのような分散コンピューティングエンジンを利用してきました。これらのエンジンは、複数のコンピュータに処理を分散させることで、テラバイト級の巨大なデータセットを扱う能力に長けています。
しかし、この「分散」というアプローチには、本質的に調整のためのオーバーヘッドが伴います。
-
メタファーを用いた解説 🚚:
Sparkを巨大なトラックの輸送隊に例えることができます。国を横断して大量の家具を運ぶような大規模なタスクには最適です。しかし、近所のスーパーへ少量の買い物に行くために、この輸送隊を動かすのは非効率です。ガソリン(リソース)を無駄にし、時間もかかります。
データパイプラインの多くは、実はこの「近所の買い物」のような比較的小規模なタスクです。それにもかかわらず、すべての処理に巨大な分散エンジンを適用することは、リソースの浪費と処理の遅延につながる可能性があります。
Chapter 1.2: Merckにおけるデータ処理の規模
グローバルなサイエンスとテクノロジーの企業であるMerckでは、データがビジネスの根幹を支えています。彼らのPalantir Foundryプラットフォームでは、1日に約100,000回ものデータ変換(ビルド)が実行されています。
この規模になると、たとえ数分の遅延やわずかなリソースの非効率性であっても、積み重なると莫大な時間とコストの損失につながります。Merckは、この課題を解決し、データパイプラインをより高速かつ効率的にする必要がありました。
Part 2: Lightweight Transformsによる解決策
Core Message: Palantirの
Lightweight Transformsは、単一のエンジンに固執するのではなく、ワークロードの特性に応じて最適なコンピューティングエンジンを選択する「Full-Spectrum Compute」という柔軟性を提供します。
Chapter 2.1: 「適材適所」のコンピューティング
Lightweight Transformsは、Palantir Foundry内でSparkやFlinkといった従来の分散エンジンに加えて、さまざまなコンピューティングエンジンを利用できるようにする機能です。
これにより、開発者は処理するデータのサイズや内容に応じて、最適なツールを選択できます。
-
DuckDB: シングルノードでの高速な分析処理に特化したインプロセスのOLAPデータベース。 -
Polars:Rustで構築された高速なDataFrameライブラリ。 - Bring Your Own Engine: 独自のエンジンを持ち込むことも可能。
このアプローチは、すべての問題を同じ道具で解決しようとするのではなく、タスクに最も適した道具を選ぶという、シンプルかつ強力な思想に基づいています。
Chapter 2.2: Full-Spectrum Computeの概念
Lightweight Transformsが実現する世界観は、Full-Spectrum Compute(全領域コンピューティング)と呼ばれます。これは、データ処理の要件に応じて、スペクトラム(領域)の中から最適なエンジンを選択できるという考え方です。
以下のMindmapは、この概念の全体像を示しています。

Part 3: Merckにおける成功事例
Core Message: Merckは
Lightweight TransformsとDuckDBを導入することで、データパイプラインの実行時間を劇的に短縮し、リソース消費量を削減することに成功しました。
Chapter 3.1: 驚異的なパフォーマンス向上
Merckは、既存のPySparkで書かれたデータパイプラインの一部をLightweight Transforms上でDuckDBエンジンを使って実行するように移行しました。その結果は目覚ましいものでした。
結論として、全体で平均10倍のパフォーマンス向上が見られました。
-
キーポイント1: 管理会計領域のパイプライン
-
Before:
Sparkを使用し、6〜7時間かかっていた処理。 -
After:
DuckDBに移行後、30分未満で完了。
-
Before:
-
キーポイント2: SAPの巨大テーブル(MSEG)の処理
-
Before:
Sparkを使用し、1〜3時間かかっていた処理。 -
After:
DuckDBに移行後、30〜40分で完了。
-
Before:
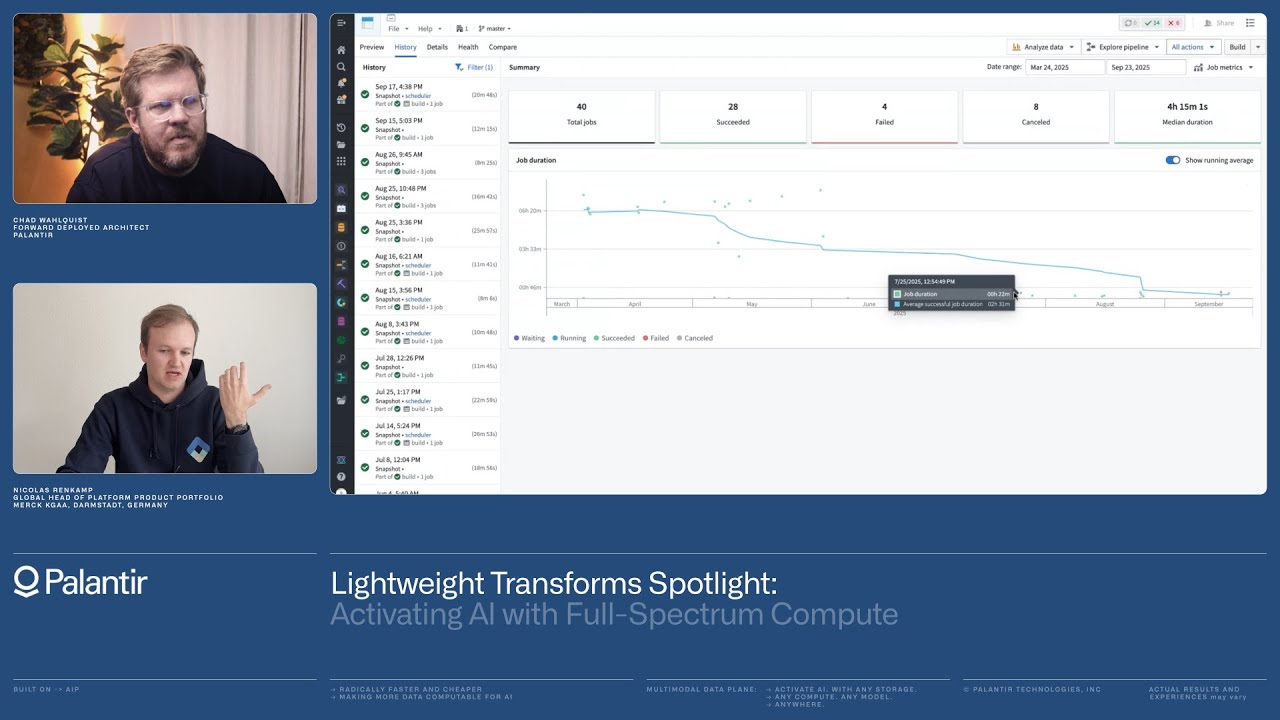
以下の図は、あるパイプラインの実行時間(Compute Seconds)が、DuckDBへの移行(2023年6月頃)を境に劇的に低下している様子を示しています。
(動画内のグラフを参考に作成したイメージです)
Chapter 3.2: コストとリソースの最適化
パフォーマンスの向上は、そのままコスト削減に直結します。
- 実行時間の短縮: コンピューティングリソースを占有する時間が短くなります。
-
リソース使用量の削減: 従来の
Sparkジョブが8〜16ノードを必要としていたのに対し、DuckDBを使ったジョブは**わずか1ノード(2〜8 CPU)**で実行可能です。
これにより、Merckはプラットフォーム全体の運用コストを大幅に削減し、空いたリソースを新しいAIユースケースやデータプロダクトの開発に振り向けることができるようになりました。
Part 4: なぜ高速化が可能なのか?技術的背景
Core Message:
Lightweight Transformsの成功は、ストレージとコンピュートを分離する先進的なアーキテクチャと、DuckDBのような最新エンジンの高い効率性によって支えられています。
Chapter 4.1: 最新コンピューティングエンジンの効率性
DuckDBのようなエンジンがSparkよりも高速に処理できるのには、いくつかの理由があります。
-
シングルノードへの最適化:
Merckの事例では、ワークロードの98%が分散処理を必要としないものでした。DuckDBは、単一のマシン上で動作するように徹底的に最適化されており、分散システム特有の通信や調整のオーバーヘッドがありません。 -
最新ハードウェアの活用:
NVMe SSDのような高速なディスクや大容量メモリを最大限に活用する設計になっています。 -
効率的な実行方式(Vectorized Execution):
データを一行ずつ処理するのではなく、大きな塊(ベクトル)として一度に処理するため、CPUの能力を最大限に引き出します。 -
ストリーミングベースの処理:
データがメモリに収まらない場合でも、ディスクとメモリ間で効率的にデータをやり取り(ジャグリング)するため、メモリ不足(Out of Memory)エラーが発生しにくく、安定しています。
Chapter 4.2: アーキテクチャの変革:S3 APIによる分離
この柔軟性を技術的に可能にしているのが、Palantir Foundryのアーキテクチャです。
重要なポイント: Foundryは、データストレージへのアクセス方法として、標準的なS3 APIをインターフェースとして採用しました。
これは、コンピュートエンジンとストレージ層を完全に分離することを意味します。
-
メタファーを用いた解説 🔌:
これは「ユニバーサル電源アダプター」のようなものです。以前は、各エンジンが独自のプラグ(専用API)を必要としていました。しかし、標準的なS3 APIというアダプターを用意することで、どんなエンジン(デバイス)でもFoundryのデータストレージ(コンセント)に接続できるようになったのです。
このアーキテクチャの変更が、DuckDBやPolarsなど、S3 APIを話せるエンジンであればどれでも利用できるという、Lightweight Transformsの強力な基盤となっています。

Part 5: 未来への展望
Core Message:
Lightweight Transformsは、オープンな標準技術を基盤とすることで、将来にわたって持続可能で柔軟なデータエコシステムを構築するための重要な一歩です。
Chapter 5.1: オープンスタンダードと相互運用性
MerckとPalantirのパートナーシップは、単なるパフォーマンス向上にとどまりません。彼らは、Apache Icebergのようなオープンなテーブルフォーマットの採用にも積極的に取り組んでいます。
Icebergは、異なるエンジン間でのデータ共有を容易にし、真の相互運用性を実現します。これにより、特定のベンダーや技術にロックインされることなく、将来登場するであろう新しいエンジンも容易にエコシステムに取り込むことが可能になります。
Chapter 5.2: 真のマルチモーダルデータプレーンへ
Lightweight TransformsとIcebergの組み合わせが目指すのは、**「真のマルチモーダルデータプレーン」**の実現です。
- Any Storage: どこにデータがあっても良い。
- Any Compute: どんなエンジンでも使える。
- Anywhere: どこからでもアクセスできる。
これは、ビジネスの要求に応じて、最も価値を生み出すツールを自由に選択し、組み合わせることができる、究極的に柔軟なデータ基盤の姿です。Merckの事例は、その未来がすでに現実のものであることを示しています。
まとめ
Palantir FoundryのLightweight Transformsは、データ処理の世界に大きな変革をもたらしています。Merckの成功事例は、ワークロードに応じてDuckDBのような最適なエンジンを選択することが、いかにパフォーマンス向上とコスト削減に直結するかを明確に示しました。
- 結論: データパイプラインの効率化は、もはや単一の万能エンジンに頼る時代ではありません。
-
キーポイント:
-
10倍の高速化:
SparkからDuckDBへの移行で、数時間かかっていた処理が数十分に短縮。 - 大幅なコスト削減: 少ないリソースで高速に処理できるため、コンピューティングコストが削減。
- 柔軟なアーキテクチャ: S3互換APIが、多様なエンジンの利用を可能にする鍵。
-
未来志向:
Icebergなどのオープンスタンダードとの組み合わせで、将来の拡張性も確保。
-
10倍の高速化:
あなたの組織でも、データパイプラインの実行時間に悩んでいませんか?
Lightweight Transformsのようなアプローチは、その解決策となるかもしれません。適切なタスクに適切なツールを適用することで、データから価値を引き出すまでの時間を大幅に短縮できる可能性があります。