
はじめに
「トークン数1Mって、200Kと比べてどれくらい大きいの?」
LLM を使っていると避けて通れない「コンテキスト長」の話。数字で言われてもピンとこない。そこで各AIにtext擬似の横棒グラフで視覚化してもらい、その見た目・見やすさを比較しました。
ワタシの理解では端的に言って
『コンテキスト長=文脈長→保持できる量のことか(!)』
です。
前提
※キャプチャ画像多めの記事です。
※冒頭の画像は「MyEdit」の 画像編集ツール › AI コラージュで作成し、トリミングも画像編集ツール › 切り抜き/回転/反転で行いました
【お得】メンバー登録 & メールマガジンの購読を登録で 15 AIクレジットがもらえる リンク → MyEdit (CyverLink)
※キャプチャ時ダークモードだったのでキャプチャ画像が総じて黒っぽいです。
※この記事中で「モデル」とあるのは「各AIサービスのAIモデル」のことです(例. Claude の Sonnet 4.6)。
※各AIサービスやAIモデル(切り替え可能)は共通して、 無料プラン&初期表示の時のもの です。
目次asページ内リンク
はじめに
今回の結果: 👑 最優秀 Copilot
1M, 200K, 196Kの量感
前記
各AIモデルのコンテキスト長
ポイントは2つ
共通Prompt
結果一覧(表)
備考あれこれ・見やすさのポイント
結果:各AIモデルの描いた横棒グラフ(text擬似)
Gemini
Claude
ChatGPT
Copilot
Perplexity
Google AIモード
後記
トークンについて:説明をAIにしてもらう
今回の結果: 👑 最優秀 Copilot
Copilotが最もtext擬似の横棒グラフとして完成されてる。

{cap: Copilot横棒グラフ部分, text擬似}
用語メモ
- トークン:AIが文章を処理する際の最小単位。単語や文字のかたまりのこと。記事の最後にAIに説明してもらったセクションあり。
- コンテキスト長(文脈長):AIが一度に保持・参照できるトークン数の上限。数値が大きいほど長い文章や会話を扱える。
- 1M:1,000,000(100万)トークン 200K:200,000(20万)トークン 196K:196,000(19万6千)トークン
- マルチモーダル:テキストだけでなく、画像・音声・動画なども扱えること。画像をアップロードしたり音声入力できること(マイクアイコンなどをクリックし話しかける)
- LLM:Large Language Model(大規模言語モデル)。生成AIの中核技術。話し言葉や書き言葉での意図や意味を汲み取り適切な応答を生成すること。人間が「意味を汲み取る」のとちがい、LLMは「膨大なデータに基づくパターン認識」として処理している。
1M, 200K, 196Kの量感
文字にするとこんな感じ。text擬似の横棒グラフ(font: 等幅フォント):
1M | ██████████████████████████████████████████████████████████████████████████
200K | ████████████
196K | ███████████
1M(100万)は 200K(20万)の 5倍。そして 200K と 196K は実はほぼ同じサイズ。このふたつの「差」をどれだけ表現できるか、が今回の見どころのひとつ。
前記
各AIモデルのコンテキスト長
コンテキスト長が気になったきっかけは「各AIモデル比較」を調べていたこと(2025年12月〜1月ごろ)。
| AIモデル | コンテキスト長 | マルチモーダル |
|---|---|---|
| Gemini | 最大 1M | ✅ |
| Claude | 最大 200K | ✅ |
| ChatGPT | 最大 196K | ✅ |
| Copilot | 不明 | ✅ |
| Grok | 最大 1M | ✅ |
| Perplexity | 載ってなかった | — |
| ナントカSeek | 載ってなかった | — |
⚠️現在(2026年5月時点)とはコンテキスト長の値が違います
調べた時の値&この記事に添付のキャプチャ画像もそのときのもの。ここではあくまでtext描画の横棒グラフの比較、という観点で進みます。
参照:MiraLab AI「【2025年最新】5大生成AI比較!ChatGPT・Gemini・Claude・Copilot・Grokの違いと選び方」(↺2025年9月7日 ✎️2025年8月19日)
※このページは同じリンク先(URL)で、「【2026年最新】5大生成AI比較!ChatGPT・Gemini・Claude・Copilot・Grokの違いと選び方」(↺2025年4月6日 ✎️2025年5月1日)
になっていて現在(2026年5月時点)とは、コンテキスト長の値が違う。
ポイントは2つ
- ✅ 開始ラインが揃っているか(左端が一致しているか)
- ✅ 200K と 196K の僅差を表現できているか(ブロック数が変わらず"同じに見える"のはNG)
共通Prompt
各AIモデルに渡した質問文はこちら:
1Mと200Kと196Kの量の多さ比較を、視覚的・直感的に分かるよう図で示して。
できたら棒グラフ(横に伸びる棒グラフ)で、グラフが無理ならtextで擬似的に。
※具体例と比喩を用いて、中学3年生用、高校3年生用、本来の答えのスタイルで
※必ず冒頭に要約(結論)を先に置くこと
「※」マーク部の文章の意図
➡︎「中学3年生用、高校3年生用、本来の答えのスタイルで」について
専門的でなく一般的にわかりやすい回答レベルを二段階くらい持ってきた方が理解しやすいと思って入れた。
✔️ AI回答は質問の種類によっては専門用語バリバリで答えてきがち。今回はそうでもないけど定型文として入れた。
➡︎「必ず冒頭に要約(結論)を先に置くこと」について
長々と解説のあとに結論を持ってくる構成はイヤなので。
✔️ AI回答は結論を最後の最後に持ってきがち。「つまり」「要するに」「一言で言うと」というセクションの、むしろそこだけ知りたい。回答の全体のそこだけ知りたい場合が多い("丁寧な"解説が入る場合、全体分量の1/5〜1/7などの『最後に来るのマジ勘弁』)。
コピペ時の注意
あらかじめtextで一言一句同じプロンプトを用意したわけだが、AIサービスによっては コピペしたら、Prompt欄に改行なしでペーストされる場合も ある。その場合あらためて改行はせずそのまま送信でOK。
結果一覧(表)
先に表で結果とポイントを提示。
各AIごとの横棒グラフの評価:
| AIモデル | 開始ライン | 僅差の表現 | 備考 |
|---|---|---|---|
| Copilot | ✅ 揃ってる | ✅ ブロック変になってない | 👑text版で最も完成されてる |
| Claude | ✅ 揃ってる | ✅ 表せてる(多分) | ビジュアル版は◎、text版は右端が揃ってない |
| ChatGPT | ✅ 揃ってる | ⚠️ ブロックが1つ変じゃないが僅差を表せてない | |
| Perplexity | ✅/❌ 混在 | ❌ ブロックが1つ変 | tableセル内は揃うがコードブロック内はNG |
| Gemini | ❌ 揃ってない | ❌ ブロックが1つ変 | |
| Google AIモード | ✅/❌ 混在 | ❌/✅ 混在 | 試行ごとに大きくばらつく、横スクロールも発生 |
備考あれこれ・見やすさのポイント
備考
-
Claudeのみビジュアルグラフが可能(「アーティファクト」機能)。ただしPythonコード生成の過程がある分、他より時間かかり気味。text擬似のグラフ見た目を見たいのでClaudeには追加指示でtextグラフを描かせた。
-
このPromptでは「棒グラフ → 3通りの説明」という構成を予想・期待していた(Gemini、Claude、ChatGPT、Copilotはその通り)。Perplexityは3通りの説明それぞれにグラフを作ったのでtext擬似のグラフが3つになった。
見やすさのポイント
各AIモデルの出したtext擬似のグラフを見比べてみると、見た目・見やすさの着目ポイントがおのずと出てきた。個人的にはグラフの開始ライン≒スタートラインが揃っている方が良いかな、と思う。
その他、200Kと196Kの僅差を表す"端"部分のみグラフ本体に使った「█(ブロック)」の大きさが異なってたり(Gemini、Perplexity)、僅差を表せてなかったり(Claudeのテキスト版、ChatGPT)した。
共有リンクをつけているのでそれぞれの詳細は個別にCheck可
削除してしまってるみたいでリンク先なくなってたワ!
結果:各AIモデルの描いた横棒グラフ(text擬似)
Gemini

{cap: Geminiの横棒グラフ部分、text擬似}
Claude
アーティファクト版 ⚠︎ただしPythonコード生成の分やや時間かかる
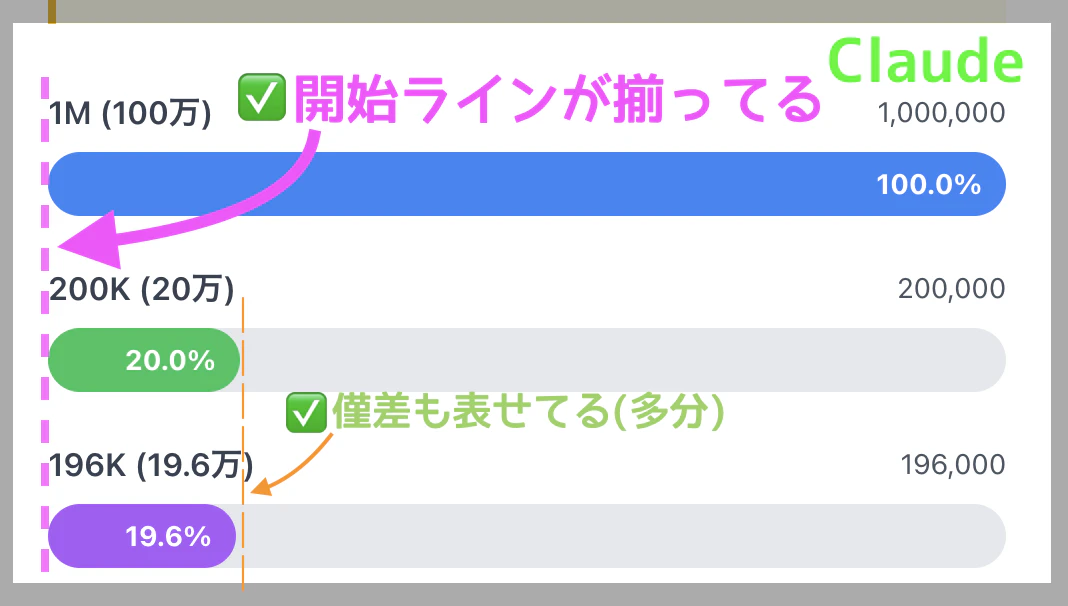
{cap: Claudeの横棒グラフ部分、ビジュアル的}
"textで擬似的に"・"地の文内"と追加指示した場合:
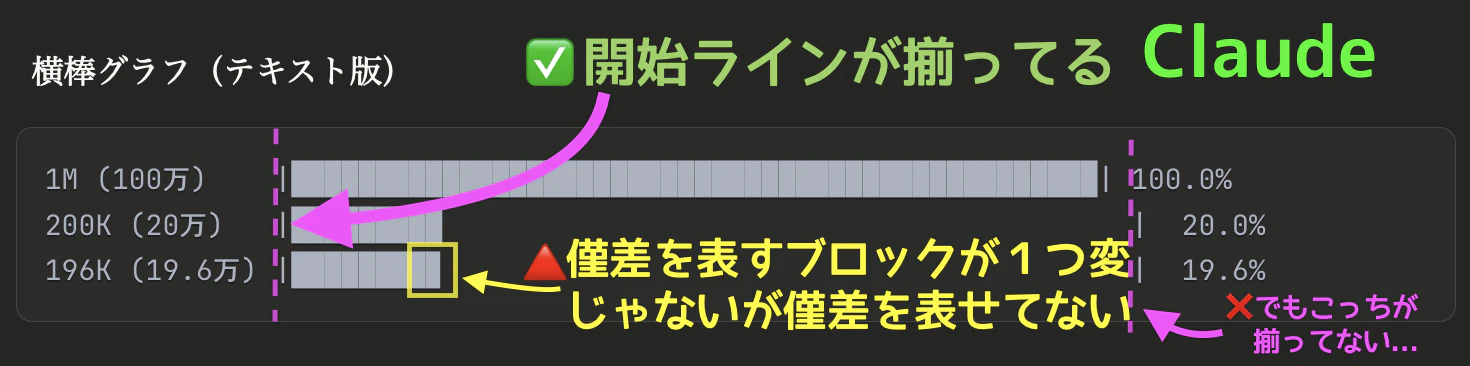
{cap: Claudeの横棒グラフ部分、text擬似}
ChatGPT

{cap: ChatGPTの横棒グラフ部分、text擬似}
Copilot
前述の通り「棒グラフ → 3通りの説明」という構成を予想していたが、Copilotはその通りの構成で来た。(cap画像は再掲)

{cap: Copilotの横棒グラフ部分、text擬似}
Perplexity
前述の通り、3通りの説明それぞれにグラフを作ったのでtext擬似のグラフが3つ。
![[1/3] Perplexityの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2F8265c326-80e9-4739-8ad1-eda54c0738d7.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=919c3a18c143ca339e67f49b6ae05e0f)
{cap: ↑[1/3] Perplexityの横棒グラフ部分、text擬似}
![[2/3] Perplexityの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2Fdaf9bbb0-12b9-413e-ada7-ffa3bb1965d6.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=cbaada77afc18f01699c32ff340767c3)
{cap: ↑[2/3] Perplexityの横棒グラフ部分、text擬似}
![[3/3] Perplexityの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2Fa039b97e-b819-4028-ab7b-ad1381ea8592.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=650e1eb4e6130bd75e7097fc26dc7022)
{cap: ↑[3/3] Perplexityの横棒グラフ部分、text擬似}
Google AIモード
Google検索での挙動:「AIによる概要」と「AIモード」
Google検索での「AIによる概要」でも横棒グラフは描いてくれるけど(しかもグラフ本体に使用するテキストが「■」「#」「=」の3種)、PC画面で見ると領域幅が狭め(右側1/3程空く仕様)なので、横棒グラフがナチュラルに折り返しあり、になっててまるで改行してるかのよう。
棒グラフとして折り返したらダメやろ、と「AIモード」に切り替えたら……
1回目
![[1/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2Fe36ef438-03f3-475f-9840-ed53ce531f4b.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=dd1b2e511fd5d6b3238ba23f89297f8d)
{cap: [1/6] Google AIモードの横棒グラフ部分、text擬似}
え、横スクロール??と思って、やり直すつもりでAIモードの「新しいスレッドを開始」から同じPromptを入力したら、
「新しいスレッドを開始」から同じPromptを入力するたびに違うスタイルのグラフを寄越してくる……。
2回目
![[2/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2F668a3651-4833-4a7d-b003-e3be4d64925f.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=7e1fd6bc6cb8e63f46f9414c5f1ff657)
{cap: ↑[2/6] Google AIモードの横棒グラフ部分、text擬似}
3回目
![[3/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2F55717188-5b09-4b31-8ea6-272d6f7b9691.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=f729e92a95c3f1be0dd36826d30fc60a)
{cap: ↑[3/6] Google AIモードの横棒グラフ部分、text擬似}
4回目
![[4/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2Fa3a86603-c8d8-43a4-a726-980f294fb65b.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=f2c6ddf5a73e21f4c91b291f1e895432)
{cap: ↑[4/6] Google AIモードの横棒グラフ部分、text擬似}
5回目
![[5/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2F9d75d844-10ad-45b5-b095-c0849f6ffd10.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=44feff63adfd68615ab0b52f4907379a)
{cap: ↑[5/6] Google AIモードの横棒グラフ部分、text擬似}
6回目
![[6/6] Google AIモードの横棒グラフ部分 text擬似](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1024463%2F2aba0b48-1bf5-46f6-904d-c12f7e5c29f1.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=17bd847785f6f518fd734e4ed865d88d)
{cap: ↑[6/6] Google AIモードの横棒グラフ部分、text擬似}
後記
今回の結果:Copilotが最も横棒グラフとして完成されてる。
試した時(2025年12月29日かそこら)はキャプチャ画像を見てもわかる通り、横棒グラフは Copilot のtext擬似の描画が最も良かった。
Σしかし、だ。
もしかして新規チャットとして同じ文章をコピペでPromptに入力するたび、ちがう回答を寄越すのかもしれない……。それというのも、何気に最後に「Google AIモードでも試してみよっと」とやってみたら、同じPrompt文でもグラフ部の描き方がイチイチ違うテキスト擬似グラフが出てくる事態になったわけだから。
なので、Gemini、Claude、ChatGPT、Copilot、Perplexityでも同様に、同じPrompt文でも新規チャットとしてスレッド立てるたびテキスト描画グラフのスタイルが違ったりするかもしれない。今回はそこまでは検証していない。
Σあ〜、あと、
ブラウザ設定でフォントを設定する箇所があるので、もしもそこをカスタムして、何か違うフォントにしてたら(特に等幅フォントの設定を変更していたら)結果も違うのかも?関係ないのかも??今回はそこまでは検証していない。
トークンについて:説明をAIにしてもらう
トークンの説明をAIにしてもらいました。(Claude Sonnet 4.6)
トークンは「品詞」でも「単語」でも「文節」でもなく、モデルが学習で決めた"頻度ベースの切れ目"です。
英語の場合、スペース区切りに近いですが完全には一致しません。
"playing" → "play" + "ing" (2トークン)
"cat" → "cat" (1トークン)
日本語はスペースがないので、さらに独特の切れ方をします。
「私は田中です。」の場合(GPT系の実測に近い例):
「私」「は」「田中」「です」「。」
これで5トークン前後。品詞分けに近く見えますが、たまたまそうなっているだけで、品詞が基準ではありません。
「ありがとうございます」の場合:
「ありがとう」「ございます」
「ありがとうございます」は出現頻度が高いので1〜2トークンにまとまることもある。
ポイントは「頻度」です。
学習データに多く出てくる文字の並びほど、1トークンとしてまとめて覚えさせてある。逆に珍しい単語や造語は細かく刻まれます。
「東京」 → 1トークン(よく出る)
「東京都品川区」
→ 「東京」「都」「品川」「区」 (4トークン寄り)
もしくは
→ 「東京都」「品川区」 (2トークン寄り)
「プロンプトエンジニアリング」→「プロンプト」「エンジニア」「リング」など
なのでトークンの切れ目は「文法的な意味の単位」ではなく、 「AIが効率よく処理するための統計的な単位」 と理解するのが正確です。
⚠️ ただし正直に言うと、実際のトークン分割はモデルごとに異なるので、あくまで目安です。
以上、トークンの説明をAIにしてもらいました。(Claude Sonnet 4.6)