お知らせ
2025/6/27(金)19:00~ 開催!!
Microsoft Data Analytics Day(Online) 勉強会にて
「Microsoft Fabric ウェアハウスとレイクハウスの役割の違いを理解する」
というタイトルで発表しました!
本記事では、その発表内容を整理し、Fabricにおけるウェアハウス(以下、Warehouse)とレイクハウス(Lakehouse)の違いについて詳しくご説明します。
Fabric登場直後からこれらの違いに戸惑った方向けに、コンセプトから具体的な機能差までを網羅的にまとめました。
なお、上記のMicrosoft Data Analytics Day勉強会は毎月開催されており、最新のMicrosoft Fabric情報を学べる場となっています。
興味のある方はぜひご参加ください!
イベントの詳細は以下のページから確認できます。
登壇資料とアーカイブ
▽登壇資料
▽アーカイブ
はじめに
昨年新卒で入社した筆者ですが、その頃にはすでに Microsoft Fabric が登場しており、日々新しい情報が飛び交っていました。
正直なところ、当初は Fabric における Warehouse(データウェアハウス)と Lakehouse(レイクハウス)の違いもよく分からず、戸惑っていました。
さらに言えば、研修で学んだ Azure 上の SQL Database や Cosmos DB などとの違い、Azure Synapse Analytics との関係性なども理解が曖昧でした。
- 「Warehouse と Lakehouse は何が違うの?」
- 「FabricにSQLDBやCosmos DBも来たけど何が違うの?」
といった具合でした。💦
そこで、本記事では Microsoft Fabric の Warehouse と Lakehouse の違い にフォーカスし、同じ疑問を持つ方々の助けになるよう整理してみました。
まずは歴史的な背景や基本概念の違いから押さえ、続いて Fabric 上で両者にどんな機能差があるのかを具体的に比較していきます。
筆者自身の学びと気づきを交えつつ解説しますので、「Fabric 導入したけど結局どっちを使えばいいの?」と悩んでいる方の参考になれば幸いです。
FabricのWHとLHの違いを画像付きで先に確認したい方は 「具体的にFabricのWHとLHの機能の違いをキャプチャ付きで紹介」 セクションからご覧ください。
また全体的に長くなってしまったので、気になるセクションからお読みいただくのもおすすめです。
前段:コンセプト理解
Fabricのデータストアアイテムの概要
Microsoft Fabric には 「Lakehouse」「Warehouse」「SQL Database」「Eventhouse」「Cosmos DB (プレビュー)」という 5 種類のデータストアが用意されており、ワークロードやデータの性質に合わせて最適なストアを選択できます。
本セクションでは、それぞれの特徴と役割を俯瞰し、後続の章で扱う Warehouse と Lakehouse の位置づけを整理します。
Lakehouse
Lakehouse は OneLake 上の Delta Parquet ファイルをテーブルとして公開し、構造化/半構造化データを一元的に保存・分析できる“レイク+ウェアハウス融合基盤”です。Spark エンジンを用いた PySpark/SQL による大規模 ETL が得意で、SQL エンドポイントを介した 読み取り専用 の T-SQL クエリも可能です。BI や ML 用のゴールドテーブルから未加工のブロンズファイルまで、多層データを同一アイテムで扱える柔軟性が最大の利点です。
Warehouse
Warehouse は “SQL Database に近い使用感” を目指した構造化データ専用ストアで、T-SQL の INSERT/UPDATE/DELETE やストアドプロシージャが利用できます。内部データは Lakehouse と同じく Delta Parquet 形式で OneLake に保存されますが、エンジンは高度に最適化された分散 SQL エンジン (Polaris) であり、マルチテーブル・トランザクションや細粒度の権限管理にも対応します。ファイルのまま置くことはできない反面、ACID 更新が SQL だけで完結する点が Lakehouse との決定的な違いです。
Eventhouse
Eventhouse は リアルタイム/時系列データ 専用のストアで、裏側には Azure Data Explorer (Kusto) エンジンが動いています。クエリ言語は KQL (Kusto Query Language) を使用し、秒単位で伸縮するスケーラブルなストリーム取り込みと高速集計が特徴です。IoT センサー、アプリケーションログ、クリックストリームなど、“高速に書き込まれ高速に読み取られる” データに最適化されています。
SQL Database
SQL Database in Fabric は Azure SQL Database エンジンをそのまま Fabric ワークスペースに持ち込んだ OLTP 向けトランザクション DB です。エンジンは従来の MDF/NDF/LDF ファイルで動きつつ、裏側で Delta Parquet へレプリケーションされるため OneLake との親和性も確保しています。完全な T-SQL 互換で identity 列やトリガーを含むフル機能を提供し、2 フェーズコミットなど厳格な整合性が求められるシステム・オブ・レコードに適しています(2025 年 2 月よりパブリックプレビュー)。
Cosmos DB (プレビュー)
2025 年 5 月のブログ発表で、スキーマレスかつグローバル分散可能な Azure Cosmos DB を Fabric アイテムとして利用できるプレビューが公開されました。これにより、Cosmos DB に格納されたドキュメント/グラフ/列指向データを OneLake 内に蓄積し、Lakehouse や Power BI と同一基盤で分析できます。スケールアウト自動化とマルチモデル API ( SQL ・ Mongo ・ Gremlin 等 ) がそのまま使えるため、IoT/モバイル/生成 AI のリアルタイムアプリを Fabric エコシステムに統合する選択肢が広がります。
まとめると
- データの“柔軟な貯蔵・加工”やAI開発用途なら → Lakehouse
- “構造化データによるBI分析”なら → Warehouse
- “ストリーミングデータや時系列ログの解析”なら → Eventhouse
- “トランザクション処理や業務アプリのDB”なら → SQL Database
- “リアルタイムアプリ/NoSQLの分析連携”なら → Cosmos DB ミラーリング
となります。
また、初心者向けにイメージで分けると、
SQL Database、Cosmos DB、Eventhouseはリアルタイム性の高いデータ等を蓄積し(OLTP)、
それらに蓄積されたデータからより深い洞察を得たいときや機会学習に用いる場合はウェアハウスやレイクハウスに蓄積し可視化する。(OLAP)
というイメージでしょうか。
※ この後の章では、特に利用シーンが多い Warehouse と Lakehouse の違いに絞って詳細を解説していきます。
▽参考(英語ですが、とても分かりやすくまとまっています!)
ウェアハウスとレイクハウスの誕生の歴史
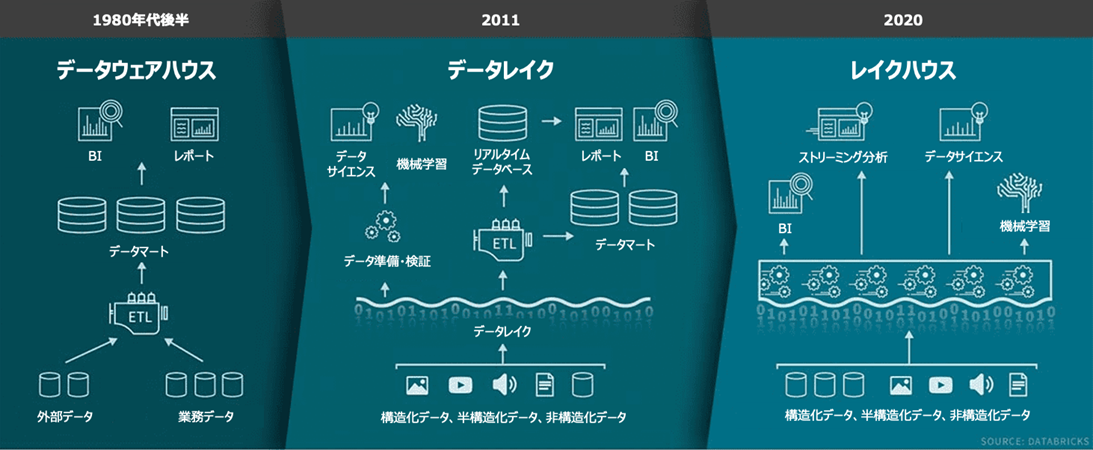
ここではデータ分析基盤の歴史的背景をざっくり振り返っておきましょう。
データウェアハウス(DWH) の起源は1980年代にあり、当時の研究者や企業が、企業内の構造化データを一元的に管理・分析するための仕組みとして提唱しました。
1990年代以降は Teradata や Oracle などの専用製品が登場し、「整理されたデータを高速に集計する倉庫」として普及。
スキーマが明確に定義され、信頼性の高いデータ分析が可能な基盤として、現在のSQL系BIの礎を築きました。
一方、データレイク は2010年頃から「生のデータをそのまま保存できる巨大な“湖”」として注目され始めました。
従来のDWHでは扱えなかった半構造化データや非構造化データ(JSONやログ、画像ファイルなど)も蓄積可能で、Hadoopやクラウドストレージ上に柔軟かつ安価に保存できる点が評価されました。
ただし、自由度の反面、ガバナンスやクエリ性能の低さなどが課題となり、「データの沼地」と揶揄されることもありました。
そして近年登場したのが レイクハウス(Lakehouse) というアーキテクチャです。
これは、データレイクの柔軟性とデータウェアハウスの信頼性・パフォーマンスを統合しようとする新しい考え方で、2019年に Databricks 社が発表した Delta Lake プロジェクトが大きな契機となりました。
Delta Lake は、Parquet ファイルにトランザクションログの概念を導入することで、ACIDトランザクションやスキーマのバージョン管理を可能にし、「レイクに置いたまま安全に書き換えられる」仕組みを実現しました。
これにより、分析基盤をシンプルに保ちながらも高信頼なETL処理や時系列の管理が可能となり、Snowflake や Microsoft Fabric も含め、多くのベンダーがレイクハウス志向へとシフトしています。
つまり、Warehouse=構造化データ特化の従来型分析基盤、Lakehouse=柔軟性と性能を両立した次世代アーキテクチャという位置づけです。
次のセクションでは、この2つのアーキテクチャの概念的な違いを、Fabric に依存しない形で整理していきます。
Fabricによらない概念的なWHとLHの違いをまとめる
データウェアハウスと レイクハウスの基本概念上の違いを、Fabric固有の話に入る前に押さえておきます。
簡単に言えば、
- ウェアハウス は構造化データ特化のリレーショナルデータベースであり、
- レイクハウス はデータレイクとデータウェアハウスの“いいとこ取り”を狙ったハイブリッドな仕組みです
ウェアハウス は従来からあるリレーショナルDBに近い存在で、事前に定義したスキーマ(構造)に沿ってデータを格納・管理します。
ETL等で綺麗に 整形されたデータ(構造化データ) を蓄積し、高速なSQLクエリやBIレポートに供することが主な用途です。
列指向ストレージや並列クエリ処理などにより、大量データの集計や複雑な結合も高速に処理できます。
一方で、取り込むデータは整合性の取れた構造化データに限られ、スキーマ外の生データや非構造データは直接扱えません。
言い換えると、 「整理されたデータの倉庫」 がデータウェアハウスの世界観です。
これに対し レイクハウス は、データレイクの柔軟性とデータウェアハウスのパフォーマンスを組み合わせたプラットフォームです。
データの保存先自体は低コストでスケーラブルなデータレイク(ファイルストレージ)に置きつつ、その上にテーブル形式のメタデータ層を設けることで、SQLによる高速クエリやスキーマ管理を可能にしています。
言うなれば「保存の仕方はデータレイク流、使い方はデータウェアハウス流」という折衷案がレイクハウスです。
レイクハウスでは非構造データや半構造データも一箇所に保存でき(データレイクの特性)、必要に応じてテーブルとして構造化・クエリ可能にすることができます。
また、データエンジニアリングや機械学習の処理も同じ基盤内で行えるため、データサイロを減らし効率的です。
Microsoft Fabricではまさに「レイクハウスだけで何でもできる!」という理想を掲げており、今後のデータプラットフォームの中心に据えようとしています。
もう少し技術的に言えば、レイクハウスの登場によりコンピュートとストレージの分離というクラウドの利点を活かしながら、データガバナンスとパフォーマンスを両立できるようになりました。
ウェアハウスが従来型の垂直統合DB(データも処理も一体化した専用システム)なのに対し、レイクハウスはオープンなデータファイル形式と汎用処理エンジンの組合せです。
そのキーワードとなる技術が Delta Lake です。
▽レイクハウスアーキテクチャ同士だから実現できるFabricとDatabricksの相互運用についてもまとめているのでご覧ください。
キーワード:delta Lakeとは
Delta Lake とは、先述の通り Databricks 社が開発したオープンソースのストレージフォーマット(およびその実装)です。
具体的には、データレイクでよく使われる Parquet 形式のファイルに対し、トランザクションログ(コミットログ)による管理レイヤーを追加したものです。
これにより、ファイルストレージ上でも ACID トランザクション(原子性・一貫性・独立性・永続性)を実現し、またデータのバージョン管理やタイムトラベル(過去時点のデータ参照)を可能にしています。
要するに、従来のデータレイクが不得意としていた「信頼性」「整合性」「高度なクエリ最適化」を、ファイルベースで提供する仕組みが Delta Lakeです。
これによって、データレイクの上で直接テーブル操作やSQLクエリを行えるようになり、データウェアハウス的な分析ができるようになりました。
Delta Lake の登場はまさに レイクハウスアーキテクチャ確立の決定打となり、現在多くのレイクハウス製品がその基盤技術として Delta Lake もしくは類似のオープンテーブルフォーマット(Apache Iceberg や Apache Hudi など)を採用しています。
参考までに、Delta Lake の概要を短時間で掴みたい方にはDatabricks社さんの以下の動画がおすすめです。
(日本語、3分程度でDelta Lakeのポイントを解説しています)
Fabric LHだけでなく WHでもDalta Lakeがベース
ここからMicrosoft Fabricのウェアハウスとレイクハウスの話に入ります。
おきたい重要ポイントとして、Microsoft Fabric上のウェアハウス も実は内部では Delta Lake 形式でデータが保存されているという点があります。
従来のオンプレミス型データウェアハウスやクラウドDWHサービスでは、データは各サービス専用のストレージ上に保存され、他のエンジンから直接アクセスできない形式でした。
しかし Fabric では、ウェアハウス も レイクハウス も共通のOneLake上にデータを持ち、オープンなDelta形式で格納しています。
つまり、「ウェアハウス」という名称でも、実体は レイクハウス と同様のオープンフォーマットに準拠しているのです。
Microsoft Learn の公式ドキュメントでも、Fabric ウェアハウス を “レイク中心に構築された次世代のデータウェアハウス” と説明されています。
このように、ウェアハウス と レイクハウス はデータの保存形式や基盤ストレージは共通であるものの、提供されるインターフェースやワークロードとの連携性には違いがあり、ユースケースに応じての使い分けが必要になります。
両者の構造が似ているがゆえに分かりづらく感じられる部分もありますが、この違いこそが Fabric 上での設計思想の反映とも言えるでしょう。
それでは次に、Fabric 上における ウェアハウス と レイクハウス の具体的な機能差について、さらに掘り下げて見ていきましょう。
Fabricのウェアハウスとレイクハウスの機能の共通点と違い一覧
見た目(UIやアイテム数)の違い
まず、ウェアハウスとレイクハウスではUI上の見た目や構成が若干異なります。
自動で作成されるアイテムの違い
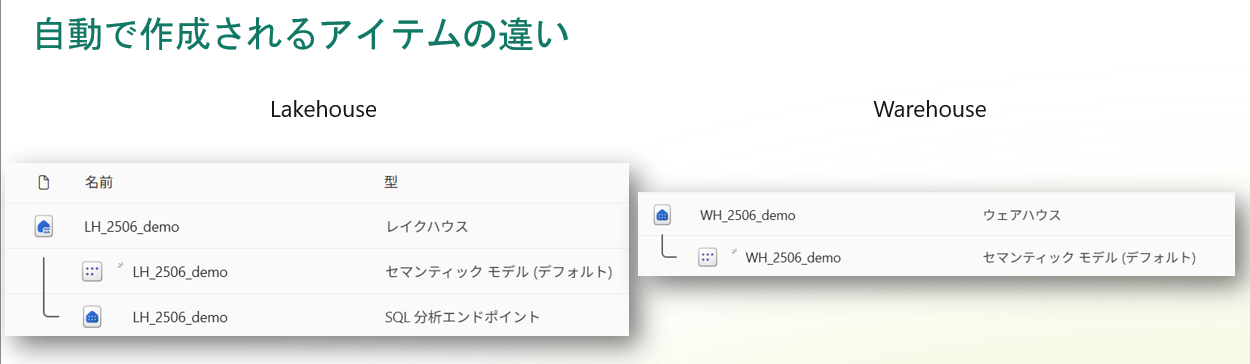
レイクハウスを作成すると自動的に SQL分析エンドポイント と 既定のセマンティックモデル(Power BI データセット) が生成されます。
レイクハウスアイテムの下位にこれらが紐づいており、レイクハウスのデータに対して直接SQLクエリを実行したり、Power BIでレポートを作成したりできる仕組みになっています。
またウェアハウスを作成した場合も自動でPower BI用のデータセット(既定のセマンティックモデル)が作られますが、レイクハウスのように別途「SQLエンドポイント」が生える概念はありません。
ウェアハウスそのものが完全なSQL実行エンジンを備えているため、追加のエンドポイント区分が不要だからです。
結果的に、Fabricワークスペース上では、
レイクハウスは3つのコンポーネント(Lakehouse本体 + SQLエンドポイント + データセット)で構成されるのに対し、
ウェアハウスは2つのコンポーネント(Warehouse本体 + データセット)に見える、といった違いがあります。
メイン機能やUIの違い
▽LHのメイン画面
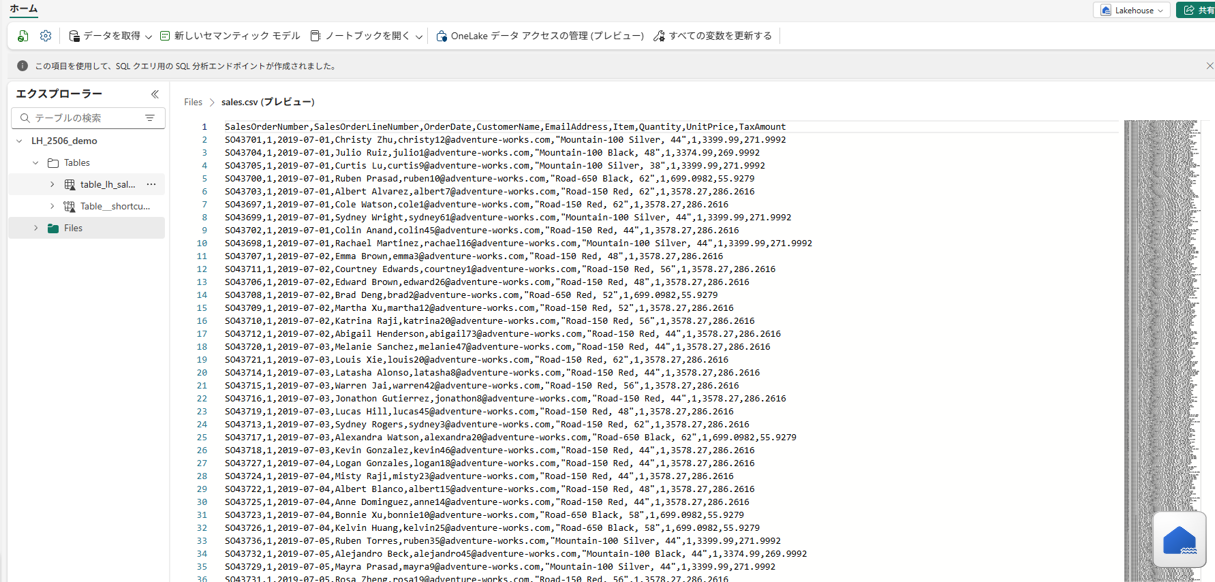
Fabricポータルでそれぞれを開いた際の画面構成を比較してみましょう。
上図は レイクハウス を開いた画面の例です。
左側のナビゲーションを見ると、「テーブル」 と 「ファイル」 という二つのセクションがあるのが分かります。
レイクハウスではこのように、OneLake上のファイルを直接参照できるファイルストレージ領域と、そこから登録されたテーブル一覧の両方がUI上に表示されます。
例えばCSVやJSON、画像ファイルなどを レイクハウス にアップロードすると「ファイル」配下に保存され、Parquet/Delta形式のテーブルとして取り込んだデータは「テーブル」配下に一覧されます。
つまり レイクハウス は構造化データと非構造化データを一箇所にまとめて管理できるよう、UI上でもファイルビューとテーブルビューの両方を備えているのです。
▽WHのメイン画面
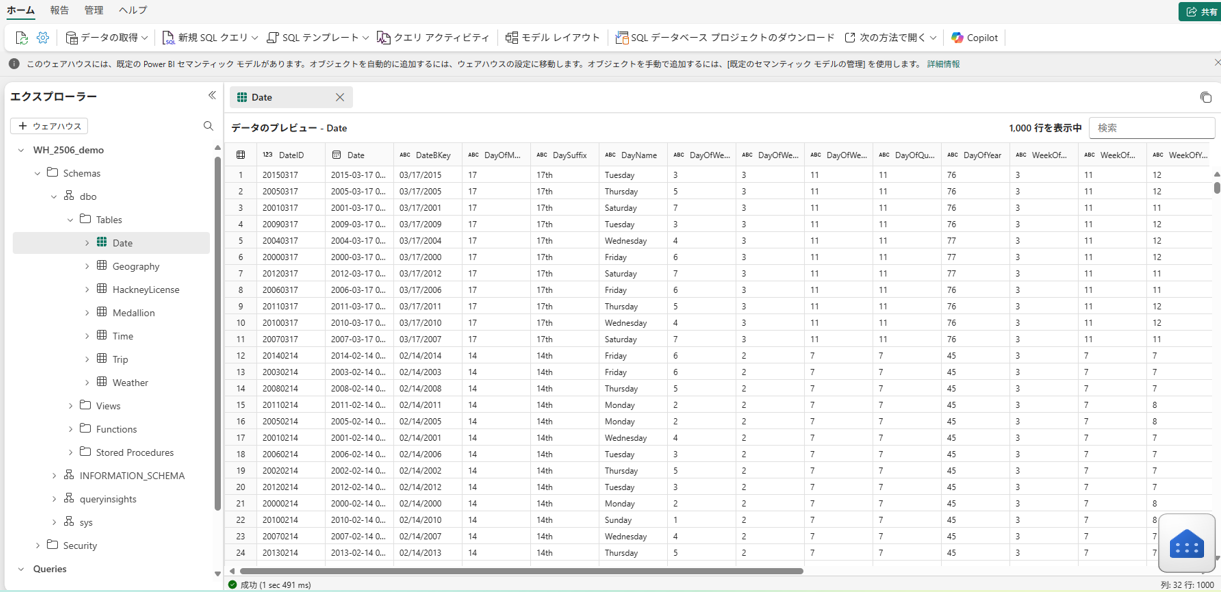
一方、こちらは ウェアハウス を開いた画面です。レイクハウスと比べてナビゲーションの構成が異なり、「スキーマ」(Schemas)や「SQLクエリ」といった項目が見えています。
ウェアハウスは純粋なデータベースのようにテーブルはスキーマで分類され、基本的にテーブル主体のビューになっています。
レイクハウスにあった「ファイル」セクションはウェアハウスにはありません。
ウェアハウスには非構造データを直接置くことはできず、すべてテーブル(行列形式の構造化データ)として管理されます。
このようにUIレベルでは、レイクハウスは「ファイルも扱えるデータレイク寄りの見た目」であり、ウェアハウスは「従来型データベース寄りの見た目」となっています。
レイクハウスのUIからはアップロードした生ファイルを直接参照・ダウンロードできるなど、データレイク的な操作も可能です。
一方ウェアハウスのUIでは、原則としてテーブル(とそれを含むスキーマ)の管理とクエリ実行が主体となります。
レイクハウスのSQLエンドポイントでできること-ウェアハウスとの違い
▽SQLエンドポイントの画面
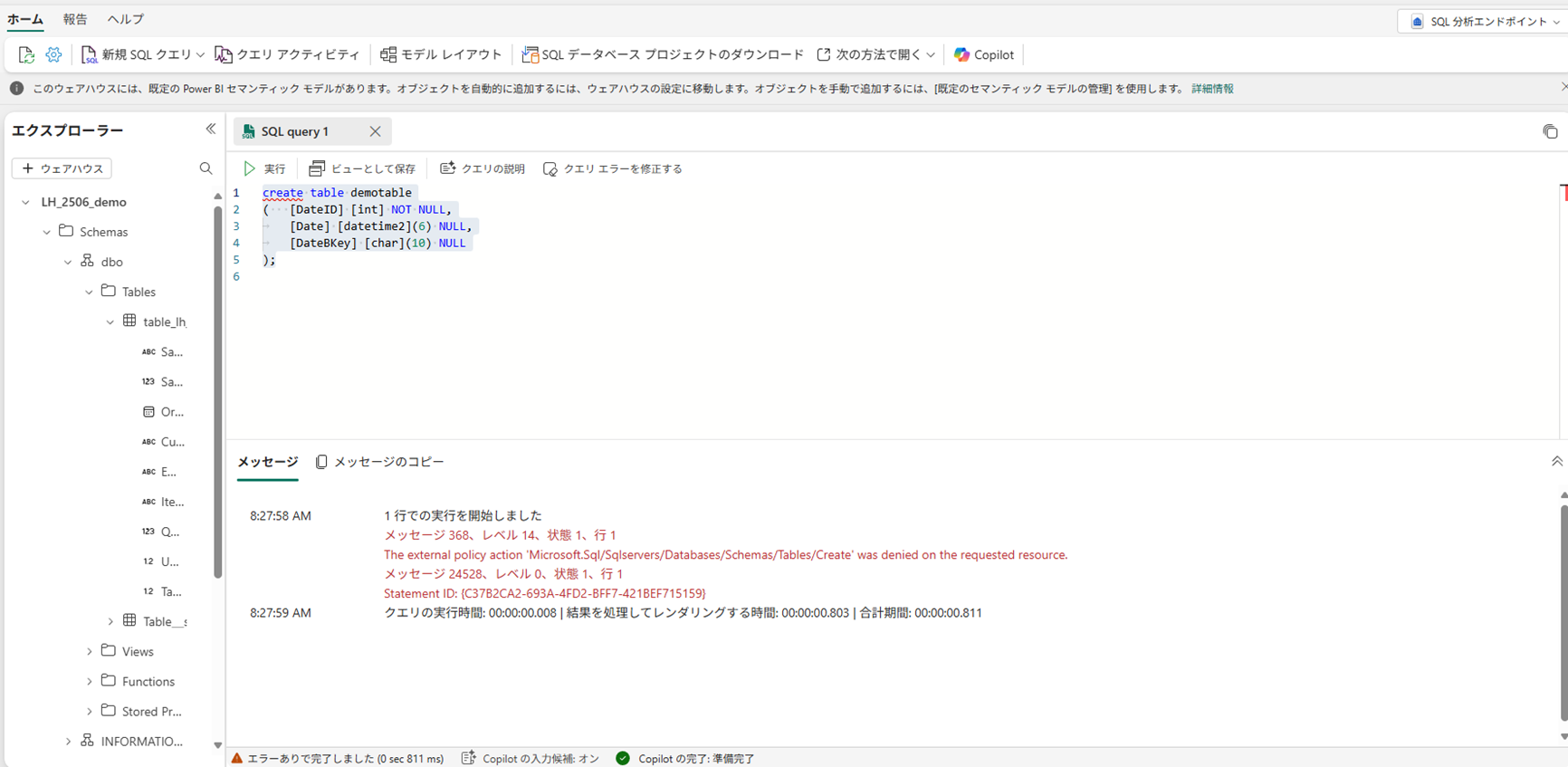
SQLエンドポイントは参照のみ テーブルを作成しようとするとエラーになる
The external policy action 'Microsoft.Sql/Sqlservers/Databases/Schemas/Tables/Create' was denied on the requested resource.
レイクハウス には「SQL分析エンドポイント」が自動的に生成され、Spark ノートブックを使わなくても Delta テーブルに対して SQL でデータを参照できるようになっています。
ウェアハウス に似た UI で SELECT クエリを実行できるため、
つい、 「ウェアハウス のようにデータ更新もできるのでは」 と思いがちですが、
実はこの SQL エンドポイントは 読み取り専用。
INSERT や UPDATE などの DML は一切サポートされていません。
レイクハウス のデータを更新・加工したい場合は、基本的に Spark ノートブック を用いて PySpark や Spark SQL を使う必要があります。
ただし、Notebook を立ち上げずとも、軽量なクエリ確認や BI レポート向けのスキーマ確認に SQL エンドポイントがすぐ使える点は大きな魅力です。
一方、ウェアハウス は SQL 実行エンジンそのものであり、データの参照・更新・構造変更まで T-SQL で完結します。
データの変換やロード(ETL)の違い
データ変換の違い
まず大きな違いとして、レイクハウス は Spark エンジンでデータ変換・処理を行い、ウェアハウス は SQL エンジンでETLを行う点が挙げられます。
これは、裏で動作するコンピューティングエンジンが異なることに起因しています。
具体的には、Fabric のデータウェアハウスは Microsoft 独自の分散SQLエンジン(Polaris)で動作し、レイクハウスはオープンソースの Apache Spark エンジンを採用しています。
そのため、前者では従来型のデータベースのように T-SQL で操作・変換を行い、後者ではコードベースの Spark 処理(PySparkやScala、sparkSQLなど)でETLを行う設計になっています。
WHとLHのデータロード(取り込み)の選択肢
各アイテムの UI における「データの取得 (Get Data)」オプションを見てみると、その違いは一目瞭然です。
▽WHの画面
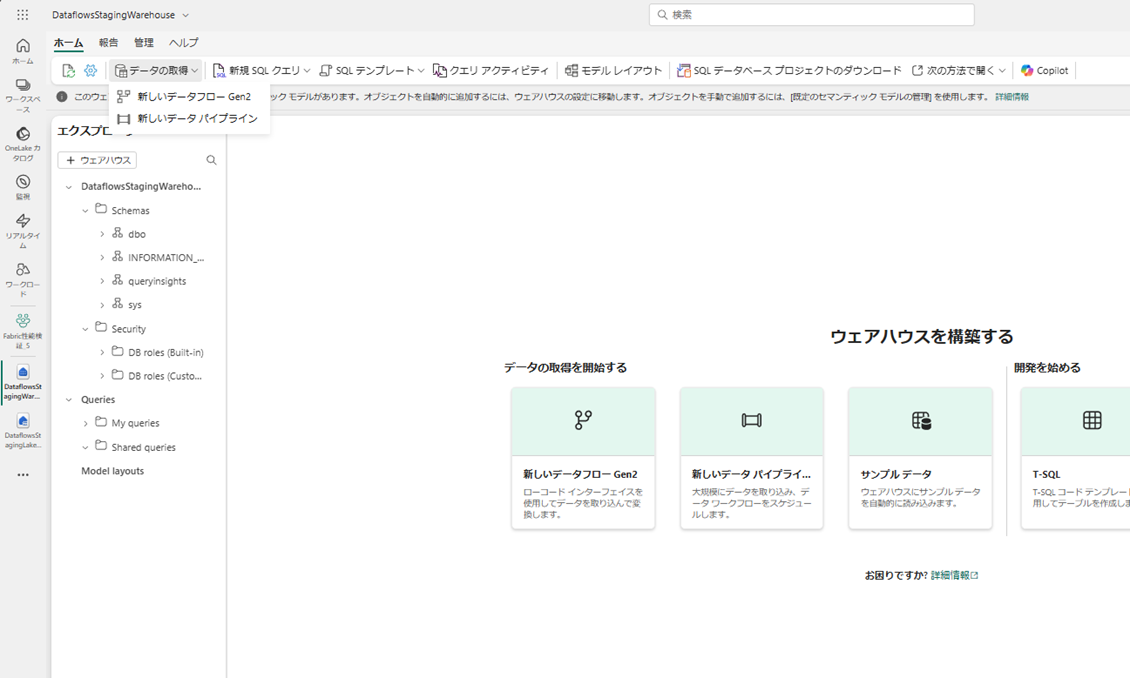
WH の「データの取得」オプション画面。WH の UI では、取り込み方法として 「データフロー Gen2」 や 「データパイプライン」がある
▽LHの画面
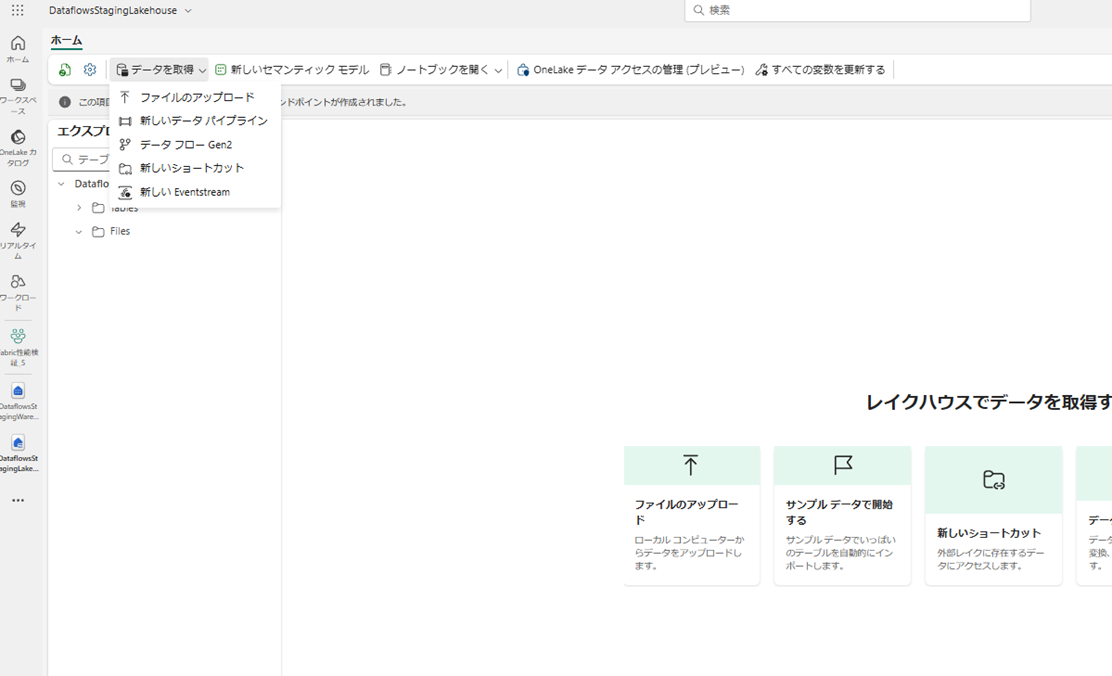
△LHの「データの取得」オプション画面。 パイプラインとデータフローに加えて様々な選択肢がある
以上の違いを表にまとめると次のようになります。
| ETL手段・データ取り込み方法 | アイテム名 |
|---|---|
| 共通 (両者で利用可能) | パイプライン、データフロー Gen2 |
| WHのみ | T-SQLクエリによる操作(CTAS、COPY INTO など) |
| LHのみ | ノートブック(Spark)、ファイルのアップロード、ショートカット、Eventstream |
ウェアハウスは基本的に従来のデータウェアハウス製品と同様に SQLベース で様々な操作が可能であり、T-SQL によるテーブル作成やデータロード(CTASや COPY INTO)、ビューやストアドプロシージャの活用など、リレーショナルDB的な手法でETLを実現できます。
一方で レイクハウス はどちらかというと データレイク寄り の使い方が想定されており、ファイルをそのままアップロードして生データを蓄積したり、Sparkノートブック上でコードを用いて高度な変換処理を行ったりすることができます。
また Eventstream によるリアルタイムデータの取り込みにも対応しており、ストリーミングデータの保存には レイクハウス が向いていると言えるでしょう。
これはレイクハウスが生データのファイル取り込みやビッグデータ処理、ストリーミングデータの蓄積に適した設計になっていることを示しています。
そして何より、データレイクや他のレイクハウス上のデータを ショートカット 機能で参照し、コピーせずにそのまま利用することも可能です。
この OneLake ショートカット により、ADLS Gen2 や AWS S3 上のファイル、他のワークスペースのデータなどを仮想的に統合し、ソースから重複コピーすることなくレイクハウス内で扱える点は非常に魅力的です。
(ウェアハウスにショートカット機能はありません。)
使用できるプログラミング言語の違い
ウェアハウスとレイクハウスでは、使える言語の種類とその活用方法に違いがあります。
これはそれぞれのアーキテクチャや実行エンジンの設計思想の違いにも起因しており、ユースケースや開発スタイルに与える影響も大きいポイントです。
ウェアハウスはT-SQLが中心
まず、ウェアハウスでは基本的に T‑SQL(Transact-SQL)を使用します。
T‑SQL は Microsoft SQL Server 系で長年使われてきた SQL 拡張言語であり、テーブルの作成、データの挿入・更新、クエリの最適化、ストアドプロシージャやビューの定義など、データウェアハウスとしての全ての処理が T‑SQL で完結します。
Fabric の ウェアハウス はこの T‑SQL 実行環境に最適化された分散クエリエンジン(Polaris)を採用しており、従来の SQL Server に慣れたユーザーにとって直感的な運用が可能です。
LHは多言語対応で柔軟
一方、レイクハウス は Spark ベースで構築されており、多様な言語に対応している点が大きな特長です。
Notebook では、PySpark(Python)、Spark(Scala)、Spark SQL、SparkR(R) など、データエンジニアやアナリストが馴染みのある言語を自由に選んで処理を記述できます。
また、Notebook内では %%sql のマジックコマンドで Spark SQL を使ったSQLライクな記述も可能です。
ただし、Spark SQL は T‑SQL と完全に互換というわけではなく、例えば列名をバッククォート column で囲む必要があるなど、細かな文法の違いがあります。
そのため、T‑SQL に慣れているユーザーが Spark SQL を使う際には若干の慣れが必要です。
さらに、レイクハウス の SQLエンドポイントを通じて T‑SQLのクエリでデータを参照することも可能です。
このように、ウェアハウス は SQL による構造化データ処理に特化し、データ管理・分析を一貫して T‑SQL で行う “データベース型” の体験を提供しています。
一方、レイクハウス は柔軟な Notebook 実行環境により、AI やデータサイエンス用途も視野に入れた “分析レイク型” の体験が可能です。
また文字列型がT-SQLだとCHAR型だけど、Spark SQLだとSTRING型。みたいな違いもあります。
T-SQLとSpark SQLの記事は以下にまとめたので、併せてご参照ください。
OPTIMIZE(パフォーマンス最適化)の違い
次に、データの最適化メンテナンス(OPTIMIZEやVACUUMなど)の違いについてです。
FabricではDelta Lake形式のデータを扱う以上、パフォーマンス維持のためのメンテナンス作業(小ファイルのコンパクションや不要ファイル削除等)が重要になりますが、ウェアハウスとレイクハウスでアプローチが異なります。
WHのOPTIMIZEは自動
ウェアハウス では、基本的に自動メンテナンス機能が有効になっています。
具体的には、データのコンパクション(小さいファイルの統合)やチェックポイント作成、統計情報の更新といったタスクがバックグラウンドで自動実行されるよう設計されています。
ユーザーが明示的にOPTIMIZEコマンド等を実行しなくても、Warehouse側で適切にデータファイルの整理や最適化が行われ、クエリ性能が維持される仕組みです。
これはウェアハウスがSaaS型のフルマネージドサービスであり、「ユーザーはメンテナンスを意識せず分析に集中できる」という利点を提供するためです。
LHのOPTIMIZEは手動が必要な場合あり
一方、レイクハウス では自動化できる部分もあるものの、より手動の介入が必要になるケースが多いです。
例えば、レイクハウス に継続的にデータを追記していくと、多数の小さなParquetファイルが蓄積してクエリ性能が低下する可能性があります。
この場合、データエンジニアが自ら OPTIMIZE コマンド(Delta Lakeのファイル統合機能)を実行し、ファイルをまとめて読み取り効率を向上させる必要があります。
また、古いバージョンのデータファイルを削除してストレージを掃除する VACUUM コマンドも、レイクハウスでは定期的に手動実行することが推奨されます。
これらのメンテナンス作業を怠ると、レイクハウス上のDeltaテーブルはバージョンが増えすぎたり、断片化した小ファイルが増えたりして、ストレージ容量の無駄遣いやクエリ性能の低下につながります。
▽LHはGUI操作でテーブルのメンテナンスが可能
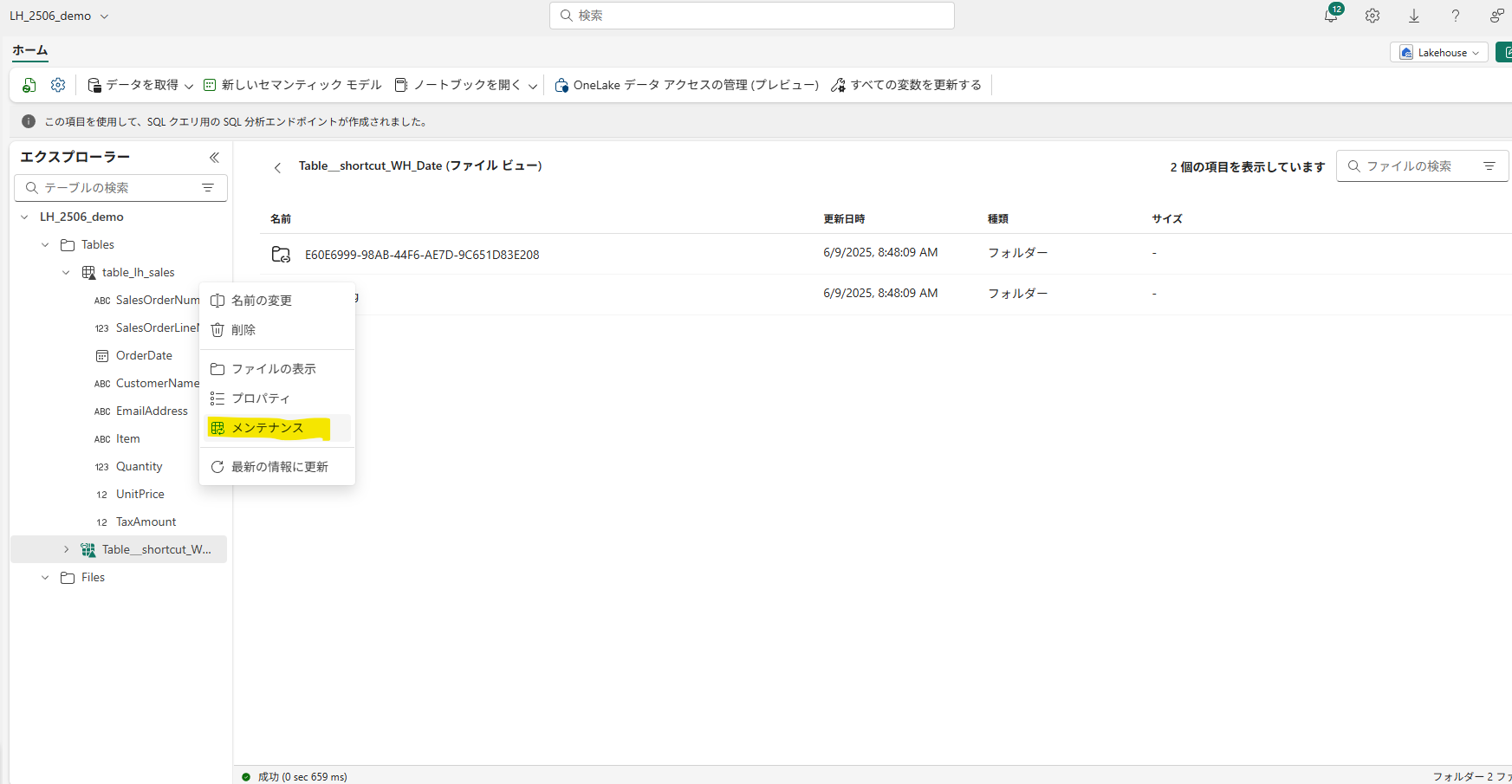
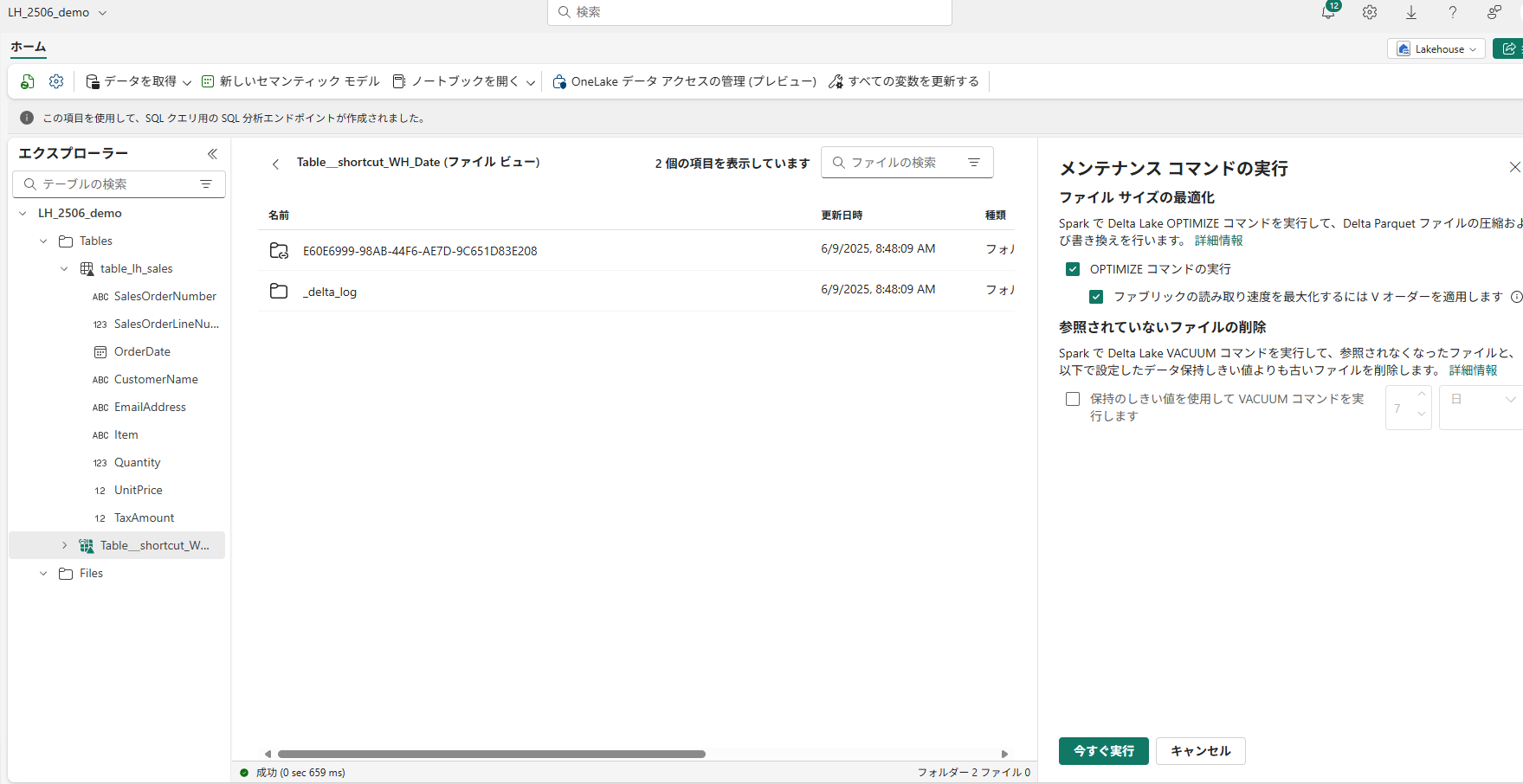
Fabricのレイクハウスでは、データを取り込む際にオプションで「自動でOPTIMIZEをかける」設定(例えばパイプラインのコピーアクティビティでOptimizeオプションON)がある程度で、長期的なメンテナンスは基本的に利用者の責任となっています。
一方ウェアハウスは、Fabric側が裏で適切にOPTIMIZE等を走らせてくれるため、利用者はあまりそこを意識しなくて済みます。
極端に言えば、ウェアハウスは “お任せ運用型”、レイクハウスは “セルフ運用型” とも言えるでしょう。
もしレイクハウスを長期運用する場合は、スケジュールされたノートブックジョブ等で定期メンテナンスする仕組みを入れることを考える必要があるかもしれません。
権限管理の違い
権限管理については、以下のQiita記事で非常にわかりやすくまとまっているのでお勧めです!
本記事では要点のみ簡潔に説明します。
前提として、両者ともにワークスペース、アイテム、エンジンといった粒度で権限設定を考えなければなりません。
ですが、すごくざっくり言ってしまうと、ウェアハウスの方がレイクハウスよりもきめ細かな権限設定が可能です。
例えばウェアハウスではオブジェクトや列単位でアクセス権を制御できます。
また、行レベルセキュリティ(RLS)や動的データマスクも使用できます。
一方、読み取り制御のみ OneLake データアクセスロール (プレビュー)にてレイクハウスの Files / Tables フォルダレベルでの制御 が可能です。
つまり、データアクセス制御の粒度という観点ではウェアハウスに軍配が上がると言えるでしょう。
レイクハウス の権限管理は進化中
レイクハウス上でも、ウェアハウス並みのきめ細かな権限管理が可能になりつつあります。
テーブル単位・フォルダー単位でのアクセス制御に加えて、列レベルセキュリティ(Column-Level Security)や行レベルセキュリティ(Row-Level Security)もサポート対象となってきています。
これらの高度な制御を使いたい場合は、OneLake セキュリティ機能のプライベートプレビューへの参加申請が必要です。
気になる方は、以下のリンクで詳細を確認してください。
FabCon Las Vegas 2025 and Microsoft Build 2025 - Microsoft Fabric What's new and what's next プラットフォームアップデート9: OneLake Security (プライベートプレビュー)
OneLake のセキュリティの概要
使われるパターン(運用方法)の違い-メダリオンアーキテクチャとの関係性-
※あくまで個人の見解です。
ここまでの比較を通して、ウェアハウスとレイクハウスどちらを使うべきか?と
考えたかもしれませんが、そもそもこれは
「どちらか一方を選ぶ」というより、「どう組み合わせて使うか」を考えるべきテーマ
かなと思います。
特にエンタープライズ規模のデータ基盤では、単一のストアで完結することは稀であり、アーキテクチャ全体を俯瞰する視点が重要になります。
そのうえで、ウェアハウスとレイクハウスはメダリオンアーキテクチャの各レイヤーに対して適した役割を持っています。
まずレイクハウスは、非構造データや半構造データを含む幅広い形式のデータを受け入れる柔軟な基盤です。
特にBronze層(生データの格納)においては、ファイル形式を問わずデータをそのまま蓄積することができ、さらにSparkベースの処理によってSilver層(加工・統合)へのステップにもスムーズに移行できます。
SQLベースで開発してきた人がSpark SQLに極端につまづくケースは少なく、OLTP前提のクエリ以外であれば実運用も問題ありません。
一方でウェアハウスは、構造化されたデータに対して高度なSQL分析や多テーブル間のトランザクション処理を効率的に行うための環境です。
これは主にGold層(分析・参照クエリ用途)を担う役割として使われることが多く、分析パフォーマンスやクエリ同時実行性の面で優れています。
Fabricではレイクハウスとウェアハウスの両方がT-SQLに対応しており、言語的には同条件ですが、運用面の最適化(バックアップ、クラスタリング、負荷制御など)がウェアハウス側に集約されていることが選定理由になる場面も増えています。
このように、典型的な組み合わせ方は以下のようなイメージになります:
- 生データの格納(≒Bronze):レイクハウス
- データ加工・統合(≒Silver):処理スタイル・制約に応じて選択
- 分析・参照クエリ(≒Gold):要件次第でどちらも選択肢
また、なぜGold層でウェアハウスが好まれる場合があるかというと、
前述のとおり Polaris SQLエンジンによるクエリ高速化 や 自動OPTIMIZEによるテーブル最適化 といった機能が、最終的な分析用途に非常にマッチしているためです。
特に、Power BI などからの高頻度かつ複雑な問い合わせに対し、並列クエリ処理性能が高く、同時接続にも強い アーキテクチャが組まれています。
実際、データマートとして多くのユーザーにデータを提供する OLAP 的な用途では、ウェアハウス の構造化特化の強みが活きます。
レイクハウスのような柔軟性や AI/ML ワークロードとの親和性は求められず、純粋にBI用途に特化した構成を目指す場合はウェアハウスが適任です。
最終的に、「品質保証された構造化データを、高速かつ安定して届けたい」という要件において、ウェアハウスは極めて優れた選択肢です。
一方で、レイクハウスはGold層まで一貫して担える柔軟性と性能を備えており、
「レイクハウスだけで Bronze〜Gold をまかなう」という構成も技術的には十分に成立します。
特に Power BI との Direct Lake 接続 を活用すれば、Delta テーブルを中間変換なしにそのまま高速に可視化でき、シンプルかつ高速な分析基盤を構築できます。
さらに、レイクハウス は Spark ベースであり、AI モデルの学習や推論処理との統合も容易で、データ基盤とAIワークロードを同じ土台で展開できるのが強みです。
現時点では BI 中心でも、「将来的に AI 活用を視野に入れておきたい」というニーズがあるなら、レイクハウス ベースの構成が有利でしょう。
またGold層に関していえば、レイクハウスにはもう一つ注目すべき強みがあります。ショートカット機能を使えば、他クラウドストレージ上のテーブル(他部門のデータマートや外部の分析済みテーブル)を自環境に簡単に統合できます。つまり相互運用性が上がります。
これにより、既存のS3やADLS上のデータ、他チームの成果物などを、コピーせずに参照・分析に取り込むことが可能になります。
▽ Fabric以外との相互運用性については、私が以前書いた以下のQiita記事もご参照ください
▽またこのトピックについては以下の公式ドキュメントも参考になります。
【おまけ】細かいけどその他の違い
このセクションについては、気づいたらどんどん追加したいと思います。
LHではUI上からテーブル名の変更が可能
レイクハウスの場合は、GUI操作で簡単にテーブル名を変えることができます。
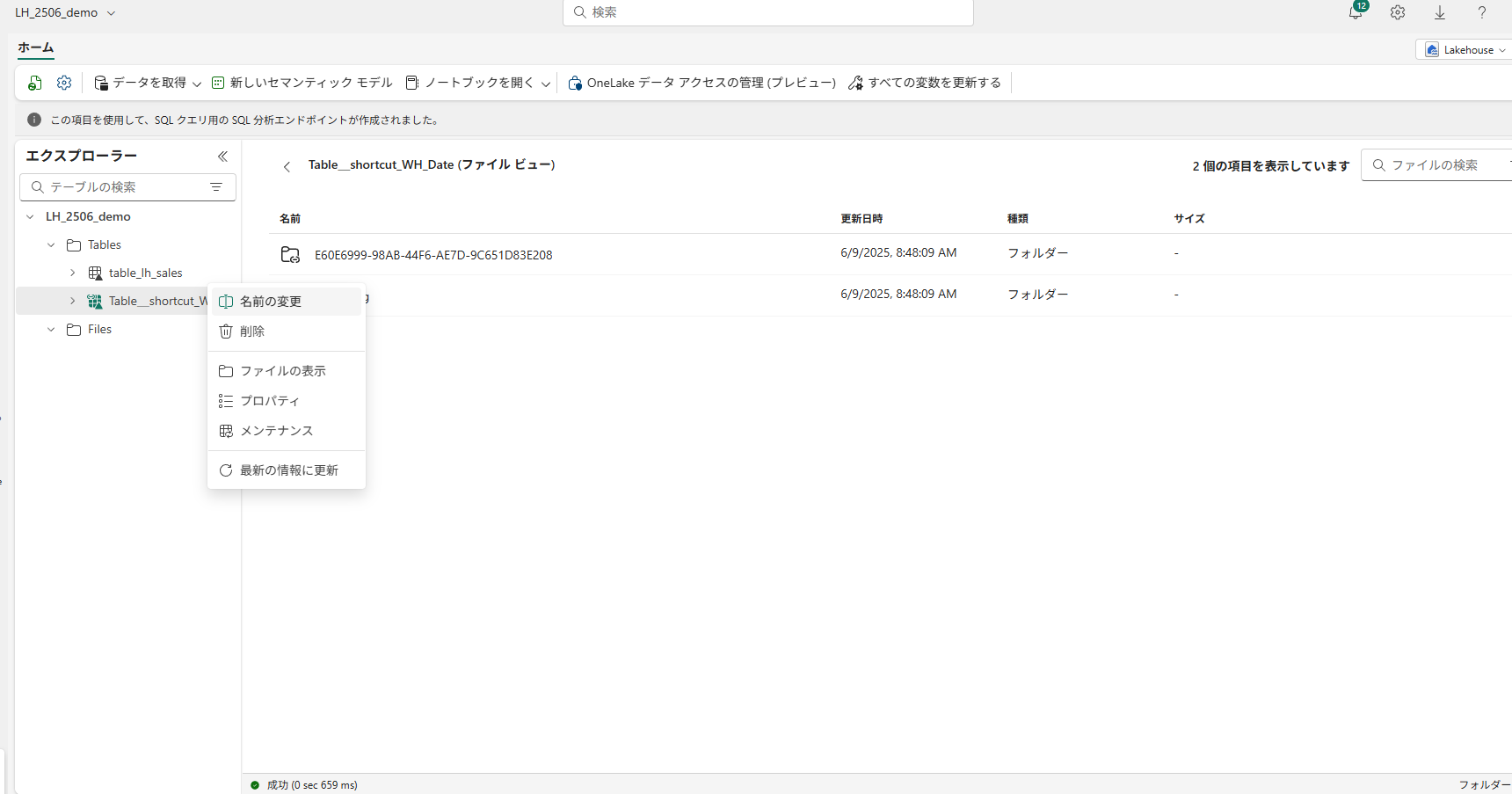
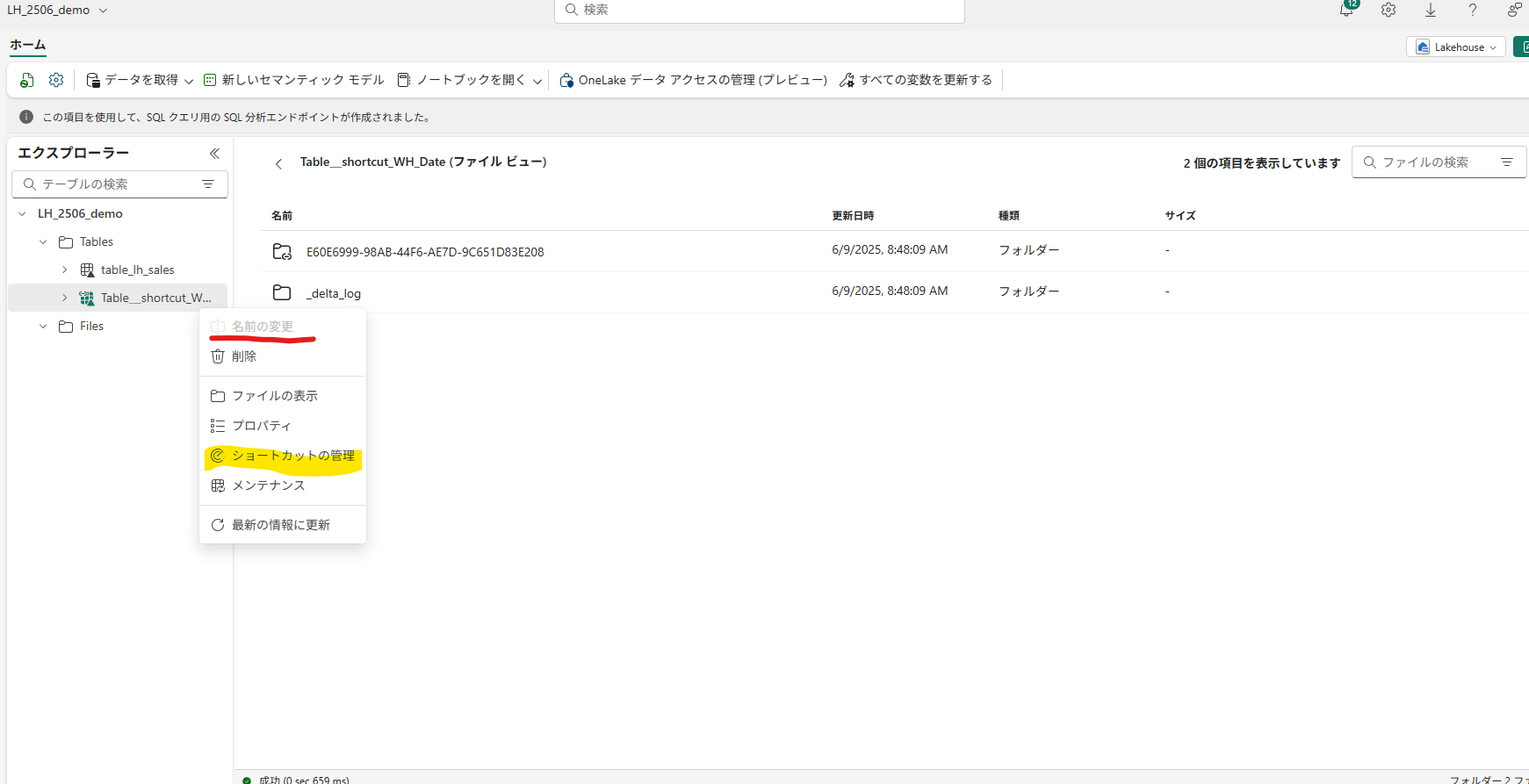
ただし、ショートカットテーブルは「名前の変更」がグレーアウトしており、
代わりに「ショートカットの管理」からショートカットの名前を変更することができます。
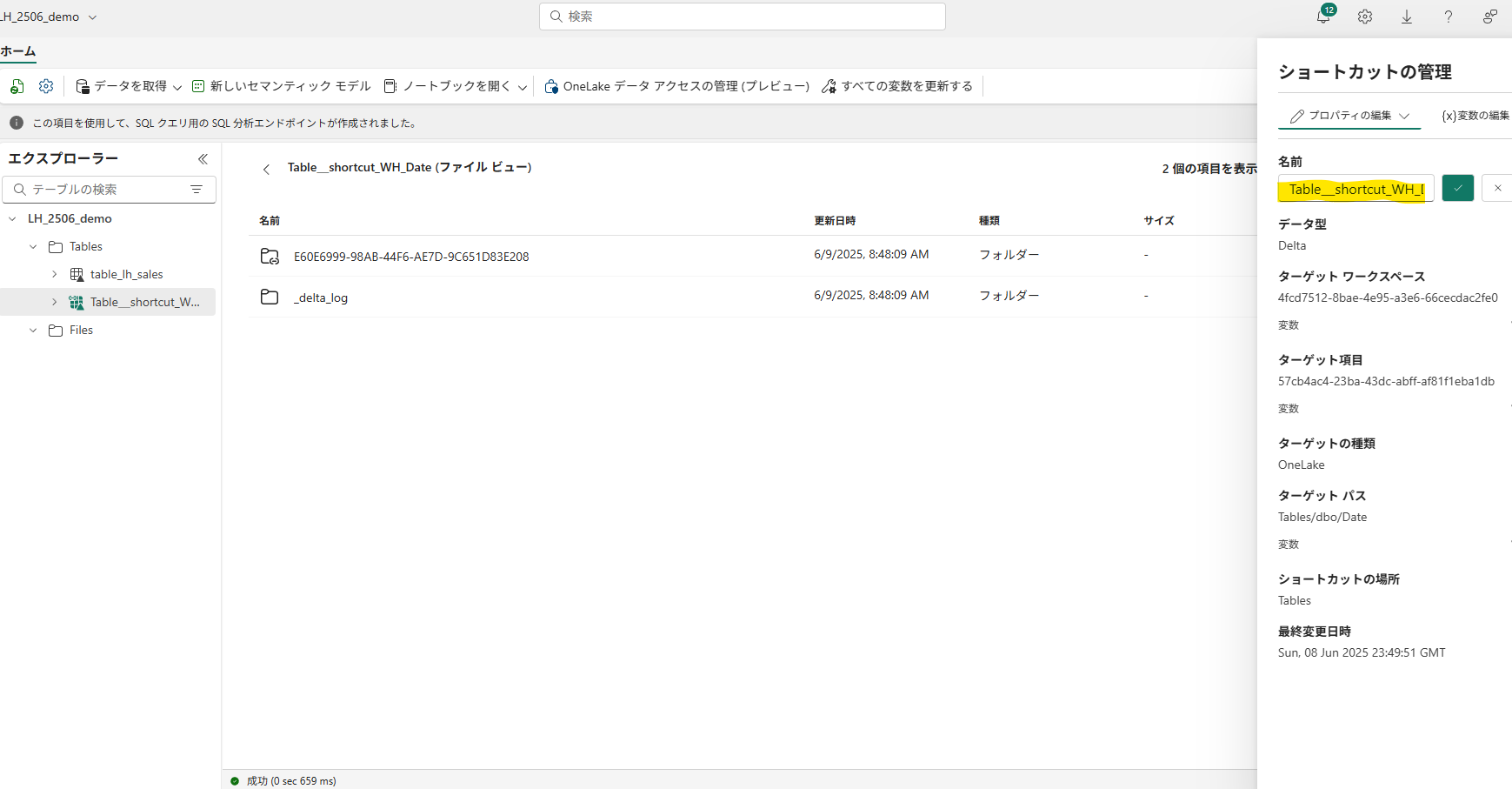
一方、ウェアハウスではGUIでテーブル名を変更することはできません。
WHでテーブルの名前を変更したい場合は、次のように sp_rename ストアドプロシージャを使います。
EXEC sp_rename '旧テーブル名', '新テーブル名';
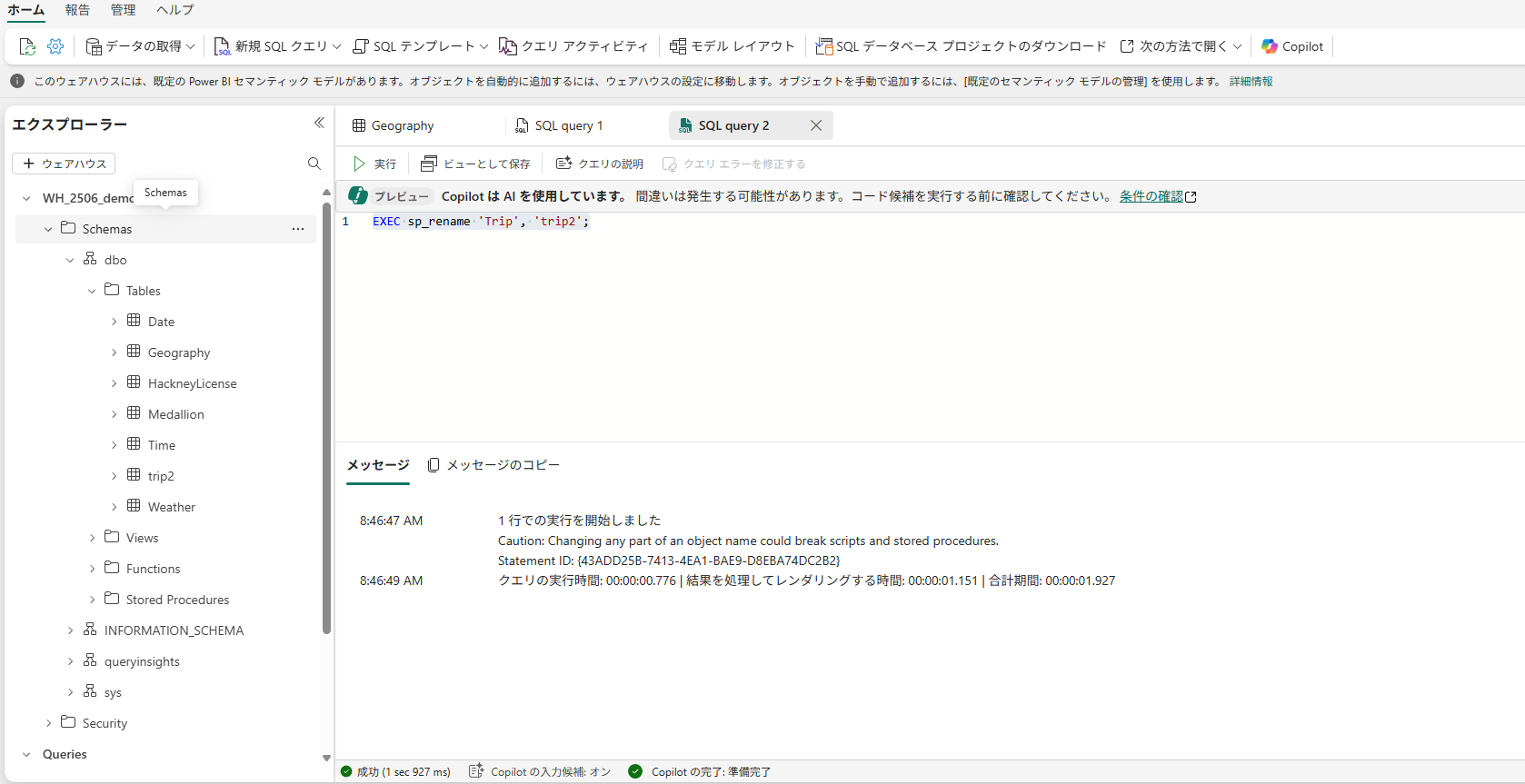
UI上でテーブル名をコピーできるかどうか
すごく地味な違いなのですが、
個人的に少し改善したらいいなと思っているポイントです。
SELECT文を投げるときにテーブル名をいちいち手入力したくないので、テーブル名をコピーしたいのですが、その操作性がLH、WHともに完全ではありません。
ウェアハウス(またはSQLエンドポイント)の場合は、GUIからテーブル名を選択することができ、Ctr+Cでコピーすることができます。
しかし、Ctr+Cを押す前にテーブルのプレビュー画面に遷移してしまい、少しもどかしいときがあります。
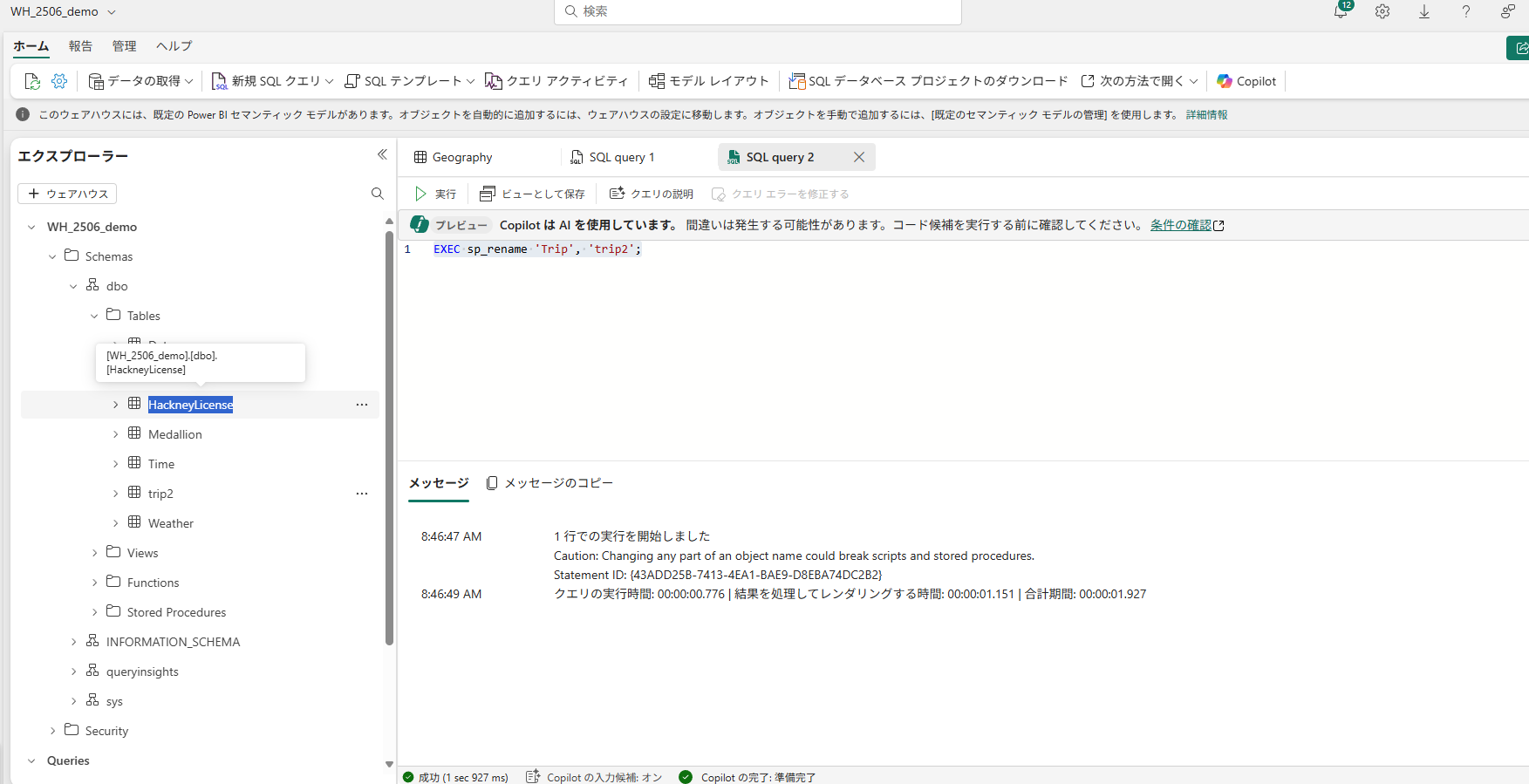
一方レイクハウスでは、テーブル名を選択しようとするとドラックアンドドロップ操作になってしまいコピーすることができません。
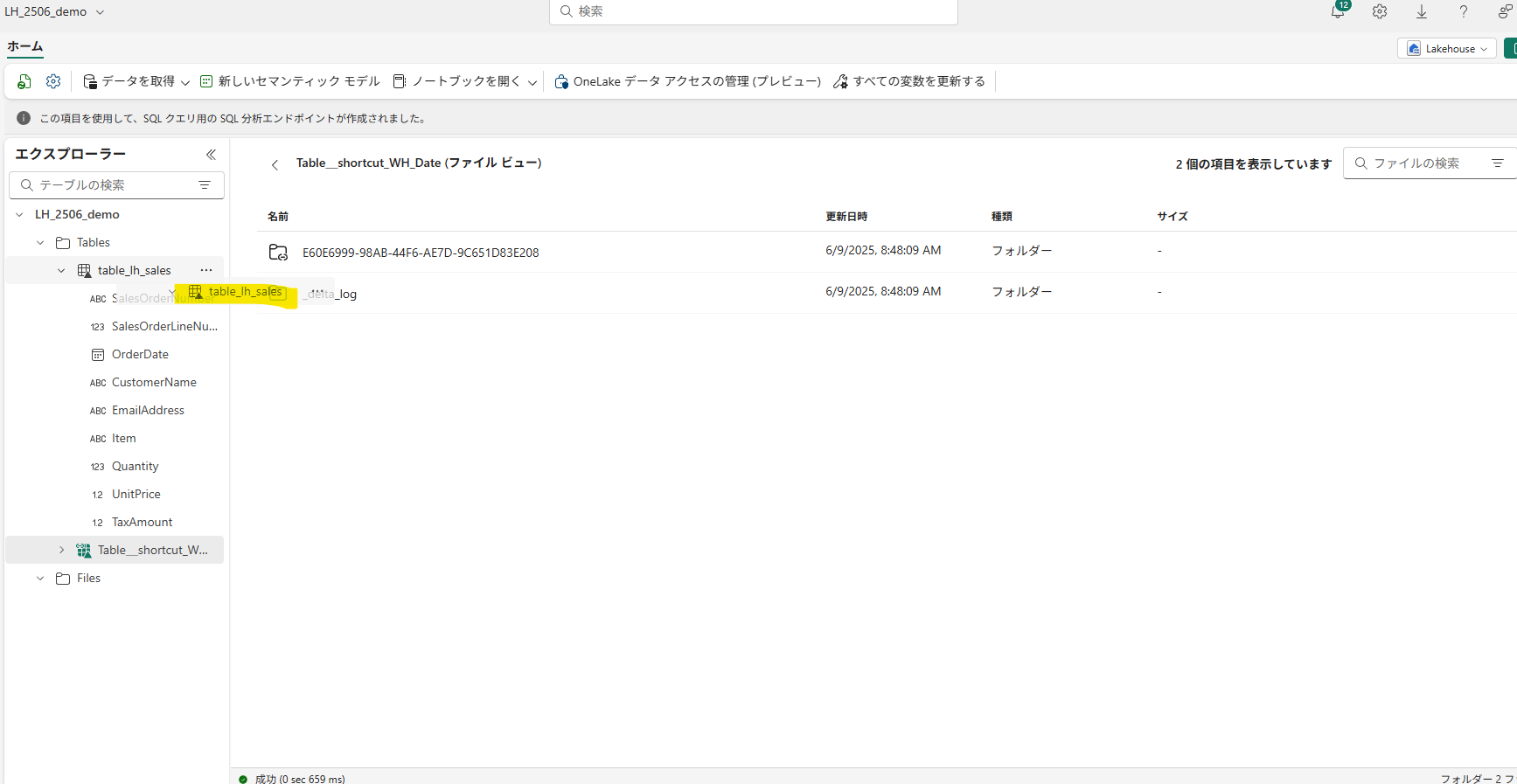
私の場合、LHのテーブル名コピーするときは、テーブルの「名前の変更」からテーブル名をコピーしています(笑)
少し手間なのが悩みです。

まとめ(感想)
以上長くなりましたが、Microsoft Fabricにおける ウェアハウス と レイクハウス の違いを見てきました。
振り返ってみると、内部のデータ形式は同じDelta Lakeに統一されているとはいえ、ユーザー体験や機能面では随所に違いがあり、それぞれ明確な役割があることが分かります。
筆者自身、新卒でFabricに触れ始めた当初は「どっちも似たようなものでは?」と思っていましたが、調べていくうちに
- ウェアハウスは従来のデータウェアハウスの流れをくむ分析特化DB
- レイクハウスはデータレイク文化を取り込んだオールマイティな基盤
と捉えると腹落ちしました。
実際のプロジェクトでも、要件に応じて両者を使い分けたり組み合わせたりすることで、非常に柔軟かつ強力なデータ分析基盤を構築できると感じています。
特に印象的なのは、Fabric ウェアハウスであってもオープンフォーマット採用に踏み切った点です。
これにより、データのロックインを避けつつSparkやPower BIなど様々なツールとシームレスに連携できるようになりました。
また、「自動最適化が効くウェアハウス」「セルフメンテナンスなレイクハウス」というように、運用上の考え方も異なるため最適な使い方を模索する必要はあります。
筆者個人としては、まずはレイクハウスで自由にデータを扱い、必要に応じて重要な部分だけウェアハウス化して堅牢性とパフォーマンスを高めるという併用パターンが現実的ではないかと感じています。
Fabricの良いところは、どちらか一方を選ぶのではなく両方のメリットを好きなように組み合わせられるところでしょう。
初学者の方には少々ややこしく映るウェアハウス vs レイクハウスですが、本記事がお役に立てば幸いです。
ぜひ皆さんもFabric上で両者を実際に触ってみて、自分なりの使い分け方針を見つけてみてください。
今後もアップデートで新機能が追加される可能性がありますので、引き続き最新情報をウォッチしつつ、Fabricでのデータ活用を楽しんでいきましょう!
もし誤りや見落とし等ありましたらご指摘ください。最後まで読んでいただきありがとうございました。
その他参考