お知らせ
Microsoft Data Analytics Day(Online) 勉強会 にて
この記事の内容で登壇しました!
この記事でわかること
目次
-
1章 Fabricミラーリングの概要
- Fabricミラーリングとは
- Fabric ミラーリングのコスト(実質無料!!)
- ストレージコスト
- コンピュートコスト
- Fabricミラーリングの種類
- ネイティブミラーリング(公式にサポートするデータソースに対して利用可能)
- オープンミラーリング
- どうやってランディングゾーンに置くのか?
- CDataがおすすめな理由
- ネイティブミラーリングのイメージ(キャプチャ)
-
2章 ミラーリング活用術
- なぜミラーリングするか?(よくある要件を4つに分類)
- 分析(運用システムに負荷をかけずに分析する)
- 統合(サイロ化したデータをOneLakeに集める)
- 共有(簡単に部門間のデータの共有ができる)
- 移行(移行中でも旧システムのテーブルを用いたレポート開発に先行着手可能)
- ミラーリングしたデータの活用ステップ(ミラーリングはまだ入り口でしかない)
- Lv.1 そのまま使う(SQLエンドポイントからクエリする)
- Lv.2 そのままBIにする(Power BIで可視化)
- Lv.3 ショートカットを駆使する
- Lv.4 加工する
- Lv.5 リバースETL
- なぜミラーリングするか?(よくある要件を4つに分類)
-
コラム:ショートカットとミラーリングの違い
-
3章 CData Syncで無限に広がるオープンミラーリングの可能性
- CData Syncとは
- CData Syncの料金
- まずはトライアルから
- 事例紹介(CDataでできるミラーリング)
- Salesforceのミラーリング
- kintoneのミラーリング
- YouTube Analyticsのミラーリング
- 関連記事
- CData Syncとは
-
コラム:ミラーリングを概念から理解する(DMBOKベース)
-
おわりに
はじめに
Microsoft Fabric の中でも注目度が高まっているのが「ミラーリング」です。
本記事では、その基本からコスト構造、ネイティブ/オープンミラーリングの違い、そして実際の活用事例までを整理しました。
Fabricを使ったデータ活用を一歩進めたい方に役立つ内容を目指しています。
1章 Fabric ミラーリングの概要
Fabricミラーリングとは

Microsoft Fabricにおける「ミラーリング」とは、外部システムのデータをOneLakeにほぼリアルタイムで同期し、そのまま利用できる仕組みです。
従来のように複雑なETL処理を組んでコピーする必要はなく、ソースのデータが自動的にFabric側へ同期される点が大きな特徴です。
これにより、システム移行や基盤統合といったシナリオでも、追加の開発を最小限にして最新データをFabricに取り込めます。
Fabricミラーリングの主なメリットは以下の通りです:
- ニアリアルタイムでのデータ連携:外部システムの最新データをそのままFabricに持ち込める
- 複雑なETL処理を回避:数クリックで同期が開始でき、導入がシンプル
- ストレージコストが実質無料・ミラーリングコストも無料:例としてF64容量では64TBまで無料で利用可能
- ソースデータベースに分析の負荷を与えることはない:OneLake上に作成されたレプリカは Fabric による全てのデータ分析に利用可能
- Direct Lakeモードに対応:Power BIから効率的かつ高速にデータ参照できる
このようにFabricミラーリングは、
「外部システムのデータを素早くFabricに取り込み、コストを抑えつつ即座に活用できる」
Fabricの中でも特に特徴的な機能として位置付けられています。
Fabric ミラーリングのコスト(実質無料!!)
Fabricのミラーリングは、実質的にほぼ無料で使えるのが大きな魅力です。
具体的には以下です。
- 同期そのものは無料(データを取り込むだけなら課金なし)
- 保存用ストレージも無料枠あり(SKUに応じてミラーリング専用のTB単位ストレージが付属)
このように、ほとんどコストを気にせず「まずは使い始められる」のがFabricミラーリングの強みです。
では、もう少し具体的にコスト構造を見ていきましょう。
ミラーリングのコストは大きく分けて以下の2種類に分類されます。
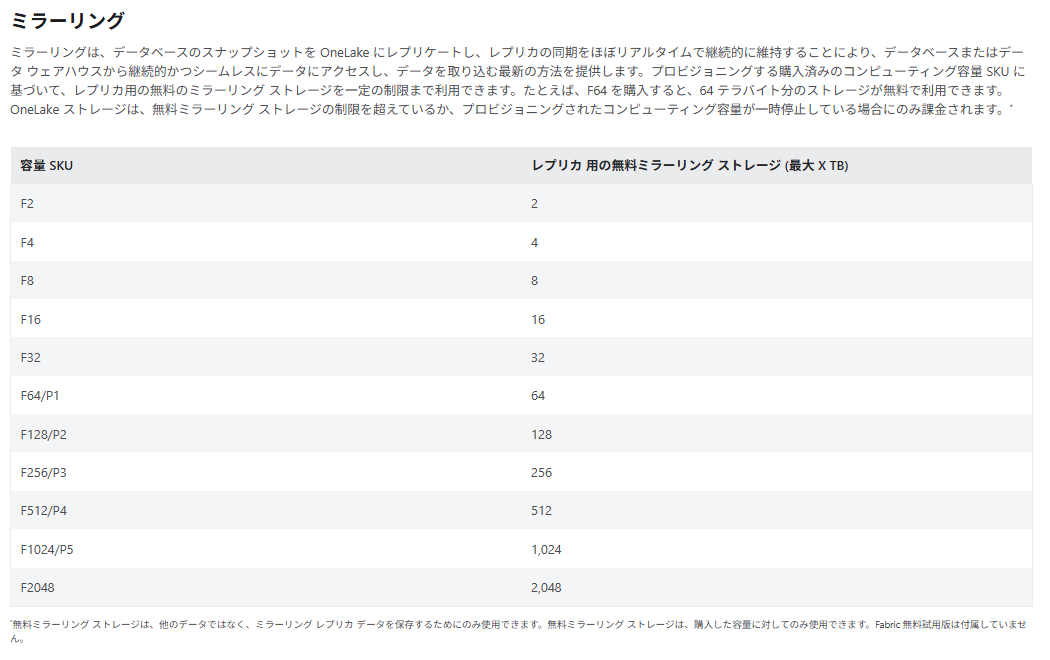
ストレージコスト
Fabricでは、SKUごとにミラーリング専用のストレージが無料枠として提供されます。
たとえばF64であれば、最大64TBまで追加コストなしでミラーリングレプリカを保存可能です。
64TBというのは相当な容量であり、多くのユースケースではまず使い切ることはないと思います。
つまり「ストレージコストは実質無料」と言っても過言ではないでしょう。
コンピュートコスト

一方で、クエリや分析を実行する際にはコンピュートリソース(CUが消費されます)。
- CU消費なし:データ同期(バックグラウンドレプリケーション)
- CU消費あり:ミラーされたデータを利用する場合(SQL / Power BI / Spark でのクエリ実行など)
💡 CU(Capacity Unit)とは?
Fabricで使える「処理能力の単位」を表します。データにクエリを投げたり分析をしたりすると、このCUが消費されます。
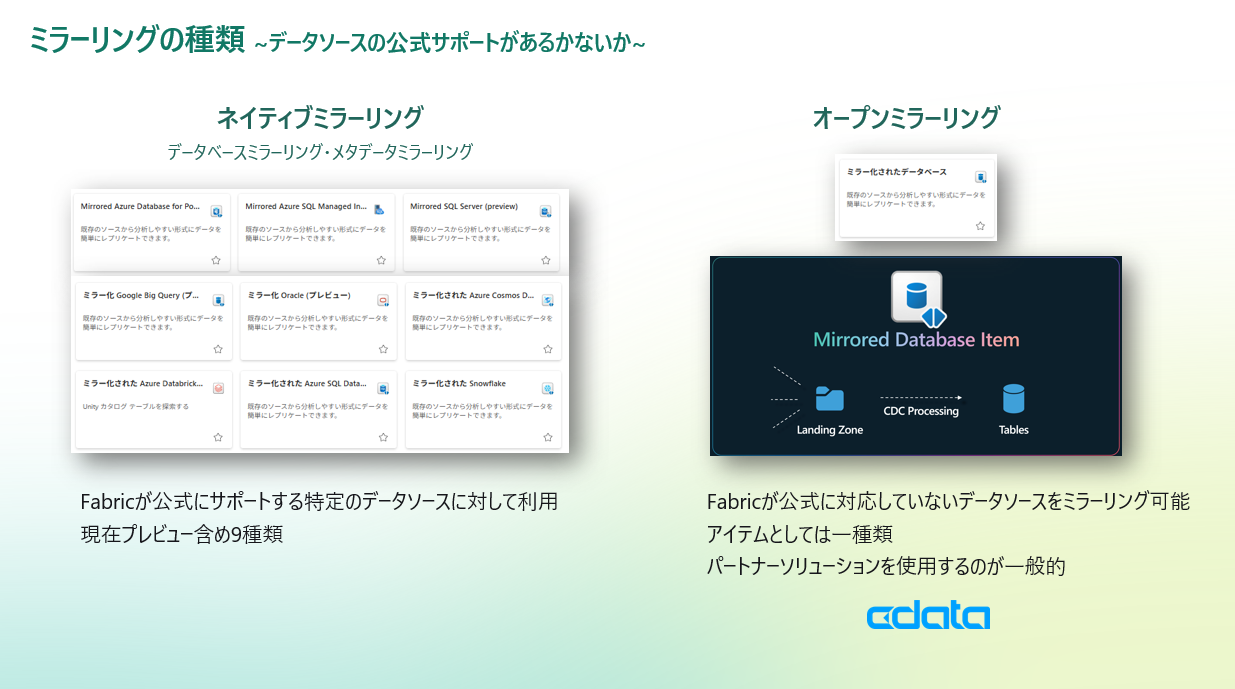
Fabric ミラーリングの種類
Fabricのミラーリングは、以下の3種類に分類できます
- データベースミラーリング
- メタデータミラーリング
- オープンミラーリング

ネイティブミラーリング(公式にサポートするデータソースに対して利用可能)
上記のうち 「データベースミラーリング」や「メタデータミラーリング」 は、
Fabricが公式にサポートする特定のデータソースに対して利用できるため、
ここではまとめて 「ネイティブミラーリング」 と呼びます。
ネイティブミラーリングは、
Fabricのアイテムとして提供されており、
数クリックの操作で簡単にミラーリングを開始できるのが大きな魅力です。
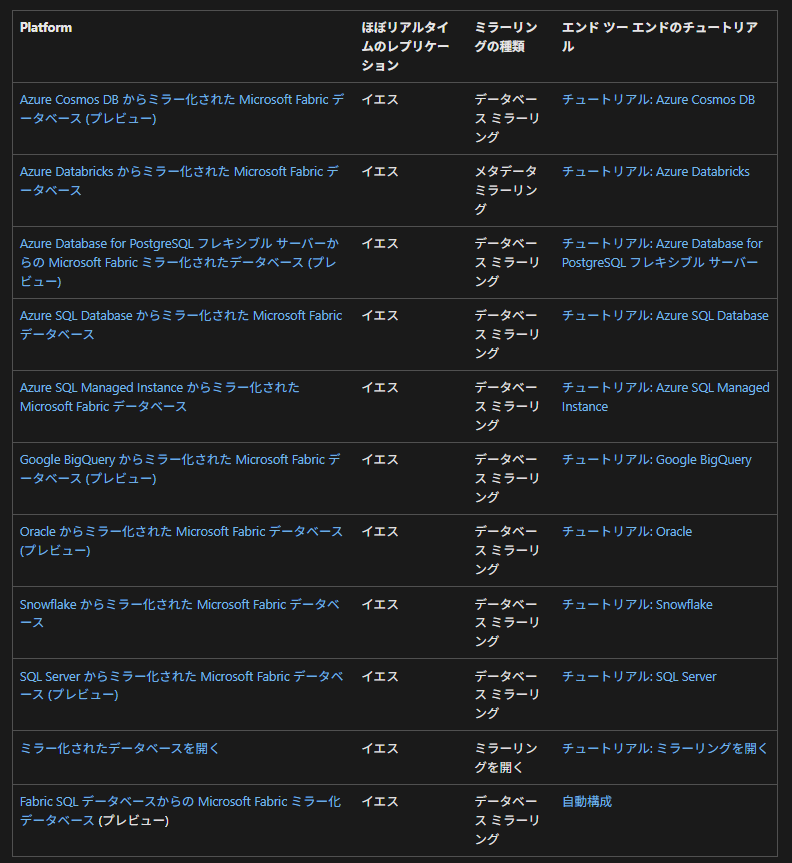
現状、プレビューも含めて9種類のネイティブミラーリングが存在しています。
Fabric初心者でもすぐに使い始められるので、公式に対応しているデータソースを扱う場合は、最初に検討すべき選択肢と言えるでしょう。
※OracleとBigQueryは先日パブリックプレビューになったようです!!
Unify your data estate for the era of AI with Fabric Data Factory
ただし、このネイティブミラーリングはとても便利である一方、
対応しているデータソースの種類はまだ限られています。
Azure SQLやCosmos DB、Snowflakeなど主要なサービスには対応していますが、
「自分が使っているSaaSやDBがサポートされていない!」 というケースも少なくありません。
そんなときに解決策となるのが次に紹介するオープンミラーリングです。
これを使えば、公式に未対応のデータソースでもFabricに持ち込むことができ、ミラーリングの可能性が大きく広がります。
オープンミラーリング
繰り返しになりますが、
オープンミラーリングは、Fabricが公式に対応していないデータソースを柔軟に取り込める仕組みです。
これにより、SalesforceやGoogle Analyticsなど、普段利用している多様なSaaSやオンプレDBをFabricにミラーリングすることができます。
仕組みとしては、外部システムから抽出した変更データ(変更データキャプチャ、CDCなど)を Parquet または 区切りテキスト形式 に変換し、必須の メタデータファイル(_metadata.json) とともに OneLake 上の「ランディングゾーン」と呼ばれる専用領域に配置することで実現されます。
Fabricはこのランディングゾーンを監視し、新しいファイルが到着すると自動的にミラーリングテーブルを更新します。
つまり流れとしては
「ソース → Parquet/CSV変換 + メタデータ付与 → ランディングゾーン配置 → Fabricが同期」
となります。

どうやってランディングゾーンに置くのか?
オープンミラーリングで重要になるのが パートナーソリューション です。
Fabric のオープンミラーリングはオープン仕様になっているため、
技術的には自前で CDC 処理を行い、Parquet や CSV ファイルと必須のメタデータファイルを生成してランディングゾーンに配置することも可能です。
ただし、変更データの抽出やファイル分割、メタデータ管理など複雑な要件をすべて自前で実装するのは負担が大きいのが現実です。
そのため、実際には ASAPIO、CData、Oracle GoldenGate などのパートナー製品が提供する ETL/レプリケーション機能を利用するのが一般的です。
これらのソリューションは、ソースからデータを抽出し、Fabric が期待する形式に変換したうえで自動的にランディングゾーンに配置してくれます。
CDataがおすすめな理由
パートナーの中でも特におすすめできるのが CData Sync です。私の視点では以下の点が魅力だと思います。
- GUIで設定できるので簡単:コードを書く必要がなく、画面操作だけで接続~ミラーリングまで完結
- 日本語サポートがある:国内ユーザーでも安心して問い合わせできる
- コネクタが非常に豊富:数百種類以上のSaaSやDBに対応(オンプレも)
- 日本独自サービスにも強い:kintoneやマネーフォワードなど、海外製品にはないコネクタが揃っている
特に「Salesforceなどの主流サービスだけでなく、日本メーカーのSaaSもまとめてFabricに持っていきたい」というケースでは、CDataがほぼ唯一の選択肢になる場面も多いはずです。
具体的なオープンミラーリングの例は3章へ
ネイティブミラーリングのイメージ(キャプチャ)
Fabricのワークスペースで、提供されているミラーリングを新規作成します。
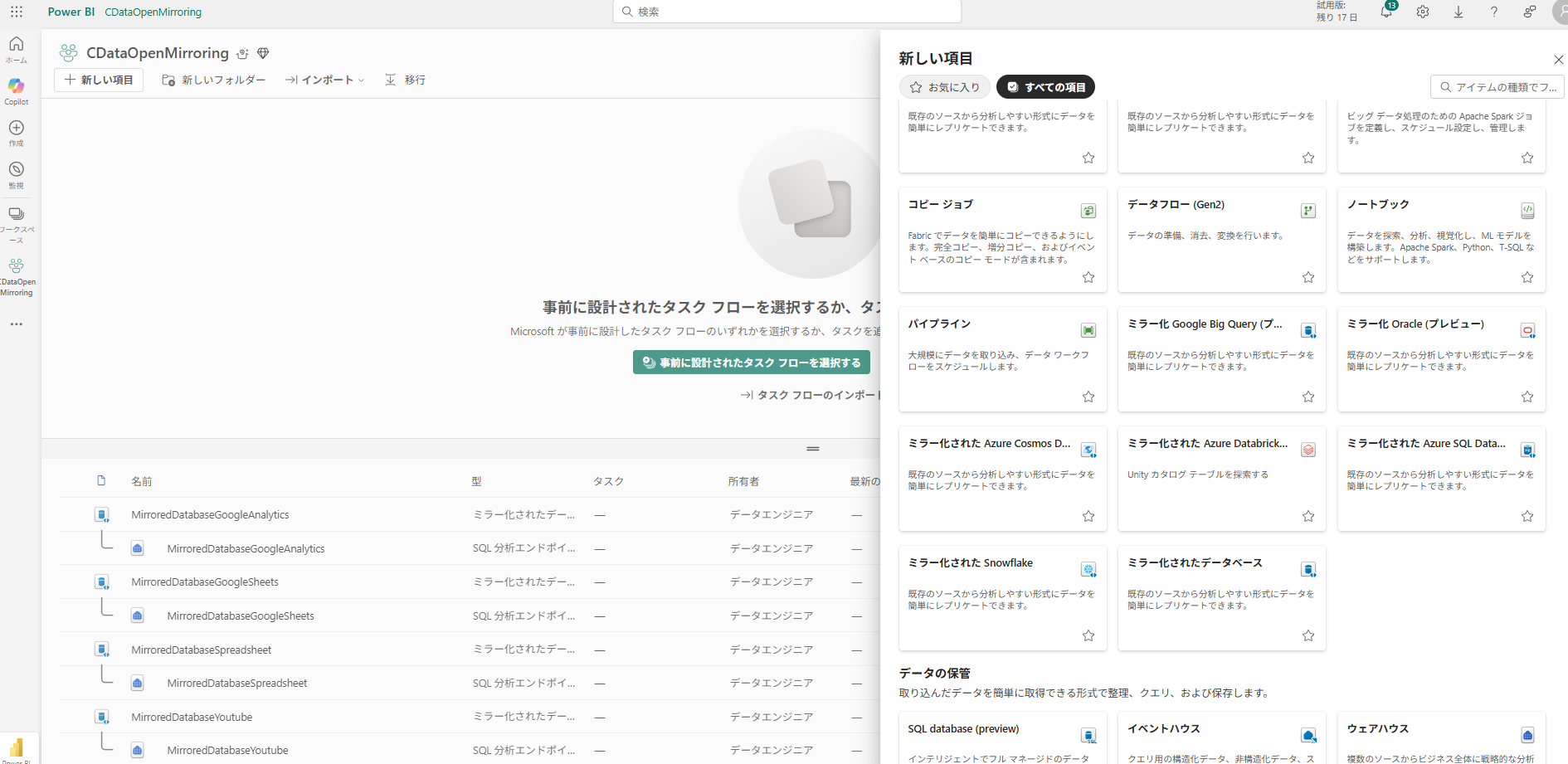
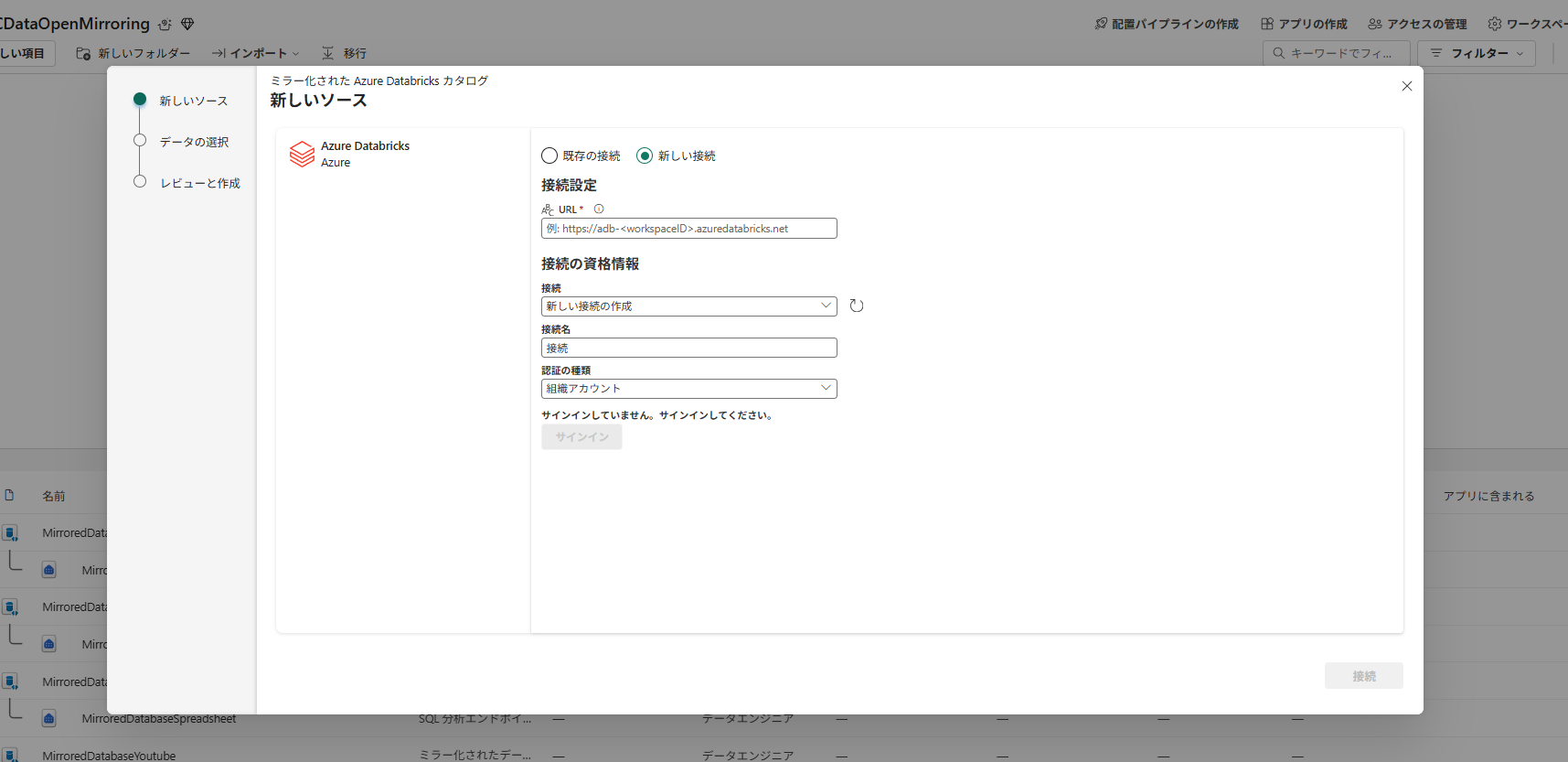
例えばミラー化されたAzure Databricksカタログを作成すると、以下のように入力画面がでてき、順に入力していきます
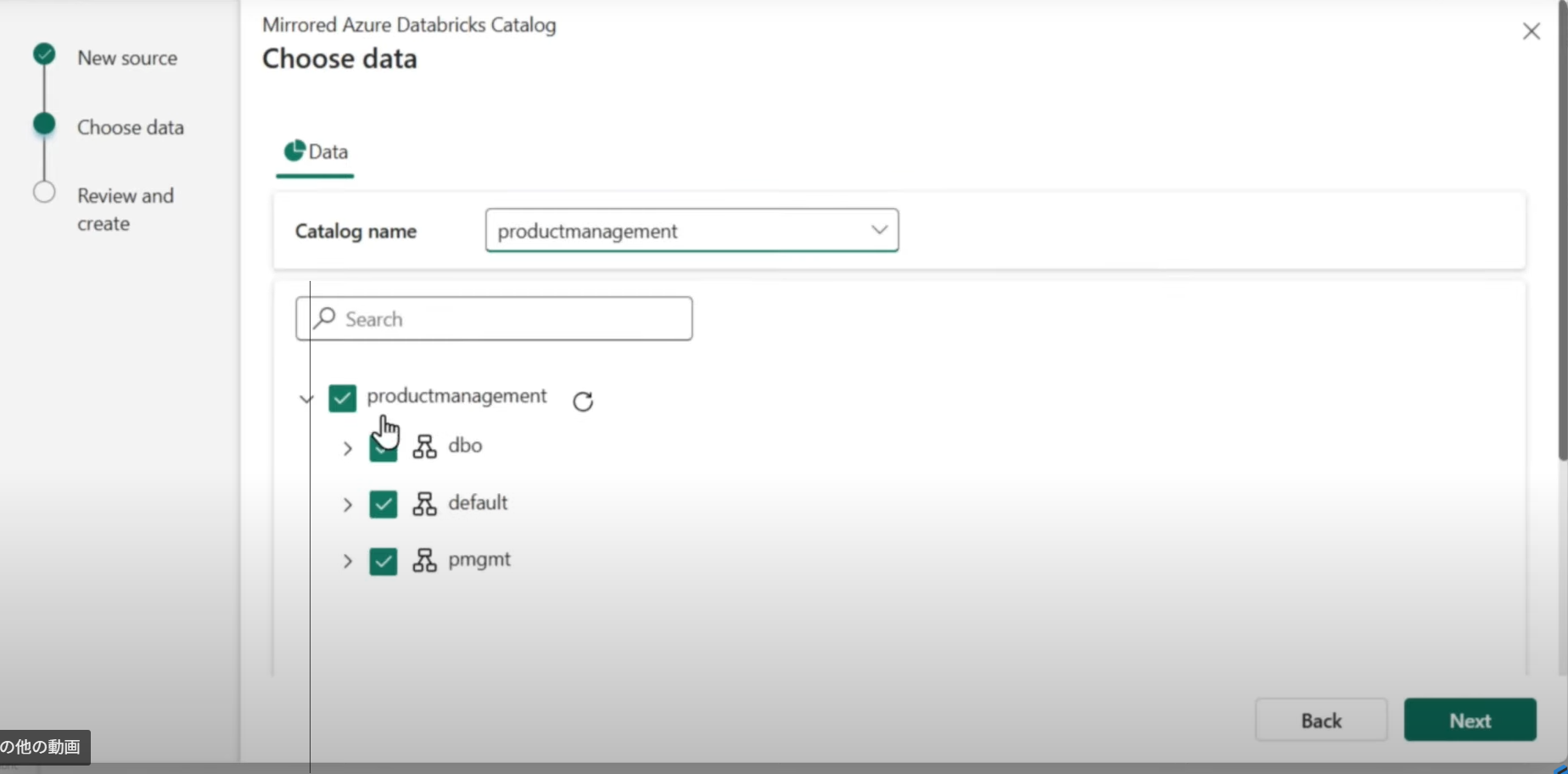
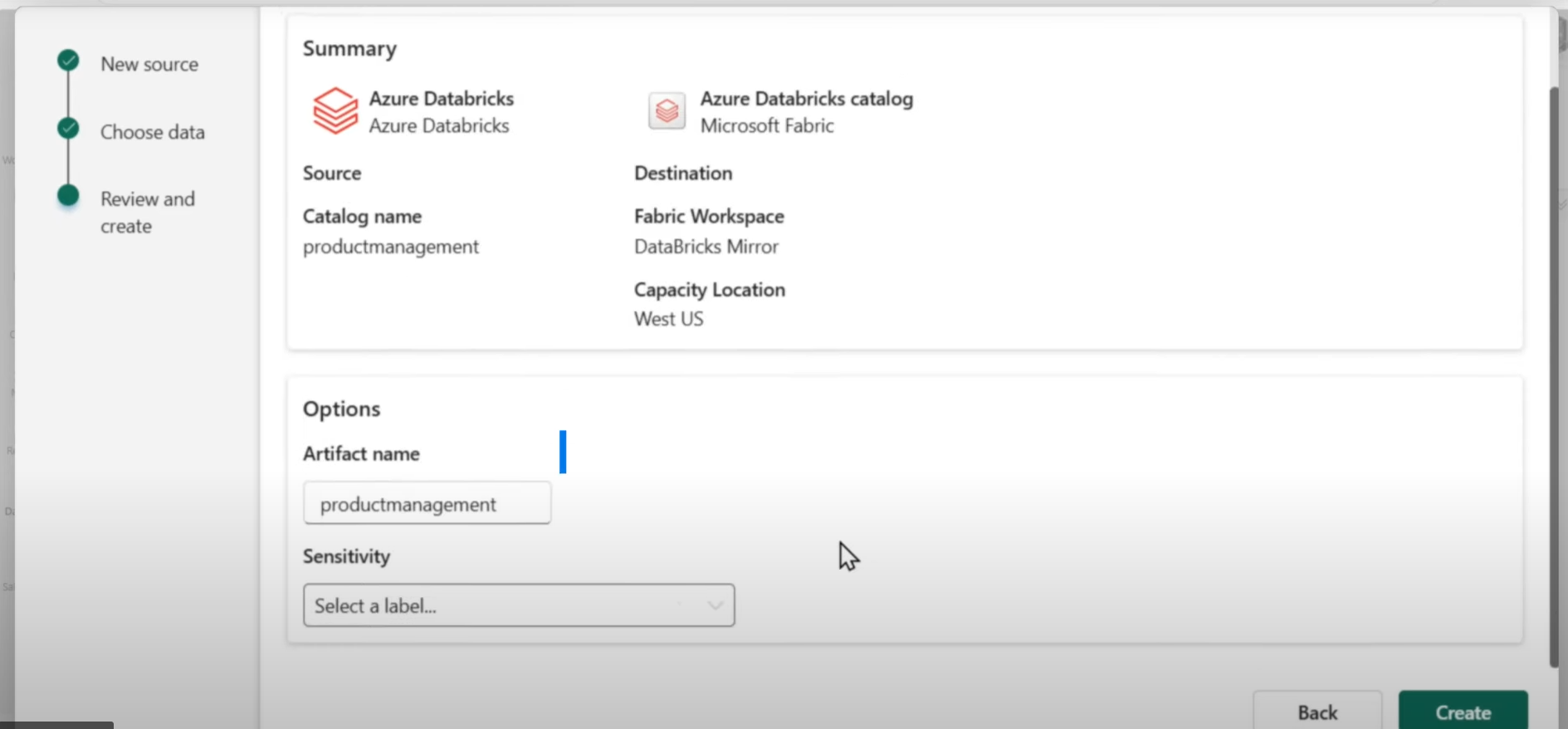
作成完了後、ミラー化データベースがアイテムとして作成されます
この時、分析用のSQLエンドポイントが付随してきます

ミラー化データベースを開いたときの画面
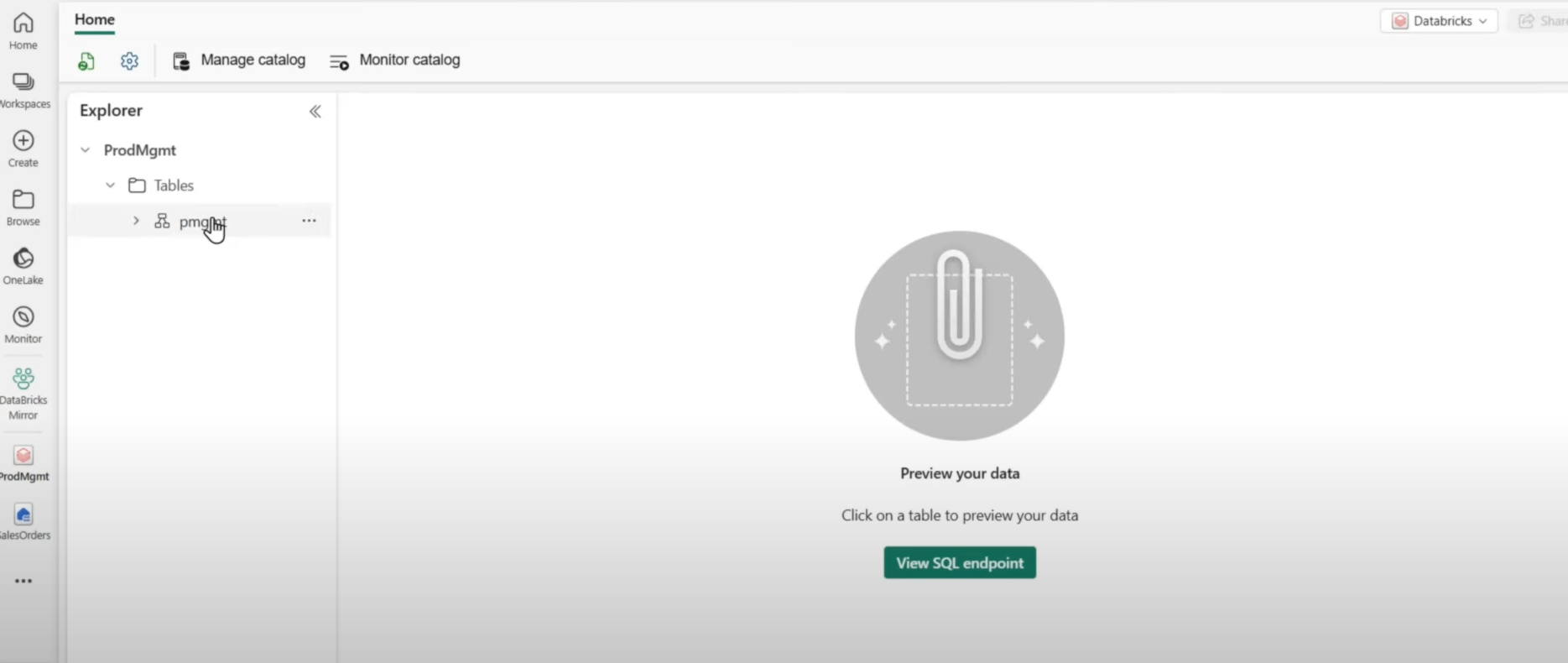
自動で作成されたSQLエンドポイントからSQLクエリを投げて分析することが可能になります
2章 ミラーリング活用術
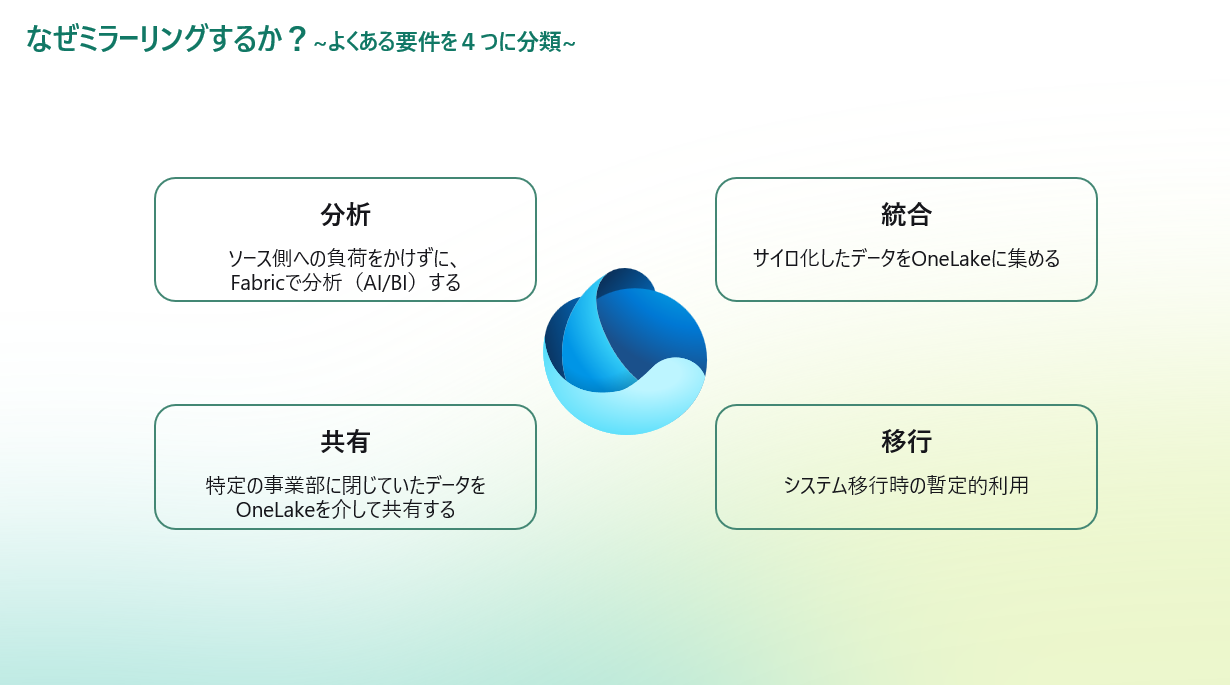
なぜミラーリングするか?(よくある要件を4つに分類)
Microsoft Fabric のミラーリングは、単なる「データをコピーする仕組み」ではありません。
まずは冒頭で触れたメリットをあらためて整理しておきましょう。
- 数クリックで同期が開始できるため 複雑なETL処理を回避できる
- ストレージコストがSKUに応じて一定量無料
- ニアリアルタイムで外部システムの最新データを取り込める
- ソースデータベースに 分析の負荷を与えることはない
つまり「いろんなデータを1つのFabricに集めて、すぐに分析できる」ことが大前提になります。
そのうえで、実際の現場でよく出てくる要件を 4つのパターン に整理してみました。
分析 (運用システムに負荷をかけずに分析する)
業務アプリケーションの本番データベースは、日々の取引処理や顧客対応といった リアルタイム処理(OLTP)に最適化 されています。
そのため「このデータを直接分析したい」と思っても、重いクエリを投げるとアプリの応答が遅くなり、最悪の場合は業務システム全体に影響を与えてしまいます。
ミラーリングを利用すれば、本番データを Fabric 側に複製し、安全に分析専用の環境へ切り離すことが可能 です。これにより運用システムは安定したまま、分析チームは自由にデータを活用できます。
具体的なユースケースとしては:
-
営業データの分析:Salesforce のデータを Fabric にミラーリングし、Power BI でダッシュボードを構築。
-
AI モデル学習:EC サイトの購入履歴やログデータを Fabric に取り込み、Azure ML やノートブックから直接呼び出して需要予測モデルを学習。学習の度に本番DBへアクセスしないので、アプリ側のパフォーマンスを阻害しない。
このように、ミラーリングは単に「データをコピーする仕組み」ではなく、運用システムを守りつつ分析の自由度を大幅に高めるための基盤 として機能します。
統合(サイロ化したデータをOneLakeに集める)
多くの企業では、営業、会計、人事、マーケティングなどのシステムが 部門ごとにサイロ化 しており、横断的な分析や全社共通の指標づくりが難しいのが現実です。
たとえば営業は Salesforce、人事は勤怠SaaS、会計はオンプレERP…といった具合にバラバラです。
ミラーリングを使えば、こうしたデータを ゼロETLでそのまま OneLake に集約 できます。また、ストレージコストはSKUに応じてほぼ無料(例:F64なら64TBまで) なので、大規模データも気兼ねなくため込めます。
具体的なユースケースとしては:
- 人事+業績:稼働時間と売上を組み合わせて生産性を可視化
- マーケ+顧客:リード情報と既存顧客を統合し、商談化率やキャンペーン効果を分析
このように「統合」は、システムごとの壁を超えてデータをまとめ、コストを抑えつつ全社最適の意思決定を可能にする Fabric ならではの仕組み です。
共有(簡単に部門間のデータの共有ができる)
従来のデータ共有は、CSVを出力してメールで渡す、別システムにコピーして持ち込む、といった 手間や重複 がつきものです。その結果、どのデータが最新か分からなくなるといった問題も起こりがちです。
Fabric の場合は、ミラーリングで集めたデータを ショートカット機能 を使ってそのまま共有できます。コピーを作る必要がなく、複雑な手順も不要。参照ベースで公開できるので、無駄にデータを重複させずにシンプルに共有・活用 できます。
具体的なユースケースとしては:
- 部門間共有:人事部の勤怠データを経営企画部にショートカットで提供し、即座に全社KPI分析に利用
- グループ会社間共有:親会社が持つ販売データを子会社に公開し、横断的な販売戦略を検討
このように「共有」は、ミラーリングとショートカットを組み合わせることで、簡単かつ効率的にデータを活用できる Fabric ならではの仕組み です。
移行(移行中でも旧システムのテーブルを用いたレポート開発に先行着手可能)
ここまでの3つ(分析・統合・共有)とは違い、「移行」におけるミラーリングはあくまで 暫定的な利用 を想定しています。
システム移行期には、既存システムに長年使われてきた データマートやゴールド層、BIで使うテーブル をすぐにFabricのETLに作り直すのは現実的に難しいケースが多いです。
そんなときでも、旧システムのデータを一旦ミラーリングでFabricに取り込み、レポート開発を先に進める ことが可能です。
たとえば、既存環境から新しい基盤へ移行を進める際に、まずはミラーリングでデータをFabricに取り込み、Power BIのダッシュボードなど分析基盤だけを先行して整備 すれば、業務部門への価値提供を早められます。
その後、Fabric内で新しいETLパイプラインによりゴールド層が整えば、ミラーリングのテーブルをFabricのゴールド層に差し替えるだけで、既存レポートを継続利用できる のも大きなメリットです。
このように「移行」におけるミラーリングは、移行期をつなぐ橋渡しであり、後工程にスムーズに接続できる現実的な戦略 です。
ミラーリングしたデータの活用ステップ(ミラーリングはまだ入り口でしかない)

ここまでさんざんミラーリングについて話してきましたが、
ミラーリングは「データをFabricに取り込む入口」でしかありません。
大事なのは、その後 どのように活用していくか です。
ここでは「簡単にできること」から「本格的な活用」まで、レベル順に整理してみました。
Lv.1 そのまま使う(SQLエンドポイントからクエリする)
ミラー化データベースには自動的にSQLエンドポイントが付与されます。
このSQLエンドポイントを使用することで、ミラーリングテーブルをプレビューしたり、SQLを投げてそのまま分析を行うことが可能です。

テーブルの中身をプレビューから直接確認できるだけでなく、簡単なSELECT文を実行してレコード件数を調べたり、集計を試してみるといったことがすぐにできます。
Fabricに正しくデータが取り込めているかどうかをチェックする最初のステップとしても便利です。
なお、このSQLエンドポイントは参照専用であり、データの更新や削除などの編集操作はできません。
そのため、最初の段階では「本当に取り込みが成功しているのか」「どんなカラム構造になっているのか」を確認したり、軽い集計を走らせる用途に最適です。
まずはFabricにデータがきちんと入っていることを確かめる、これがLv.1のステップと言えるでしょう。
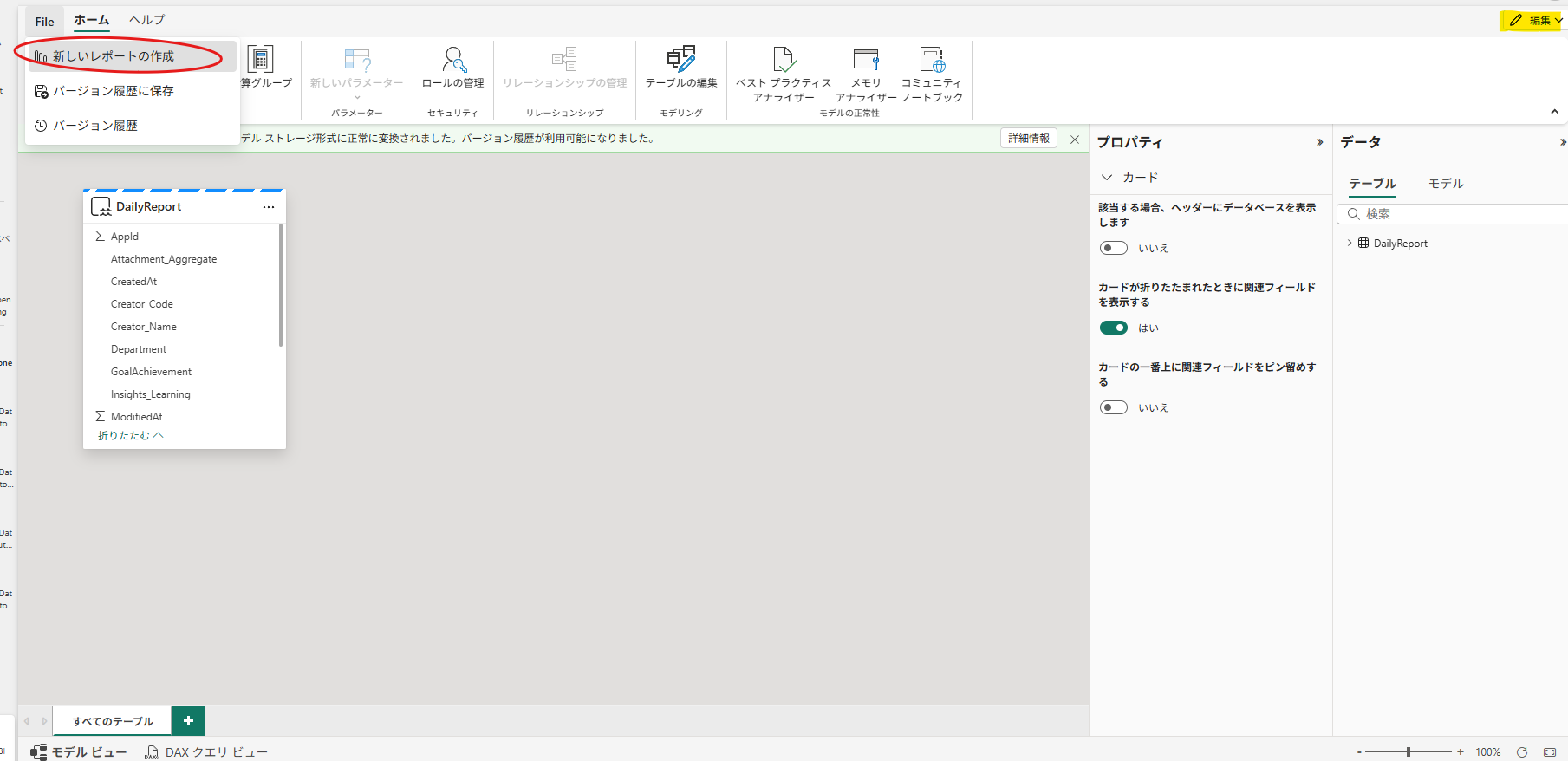
Lv.2 そのままBIにする(Power BIで可視化)
ミラー化データベースからは、そのままワンクリックでセマンティックモデルを作成できます。
作成したモデルからそのままレポートを作成できるため、
「とりあえず見える化したい」、「データマート(Gold)をミラーリングしてきた」場面では最短ルートです。
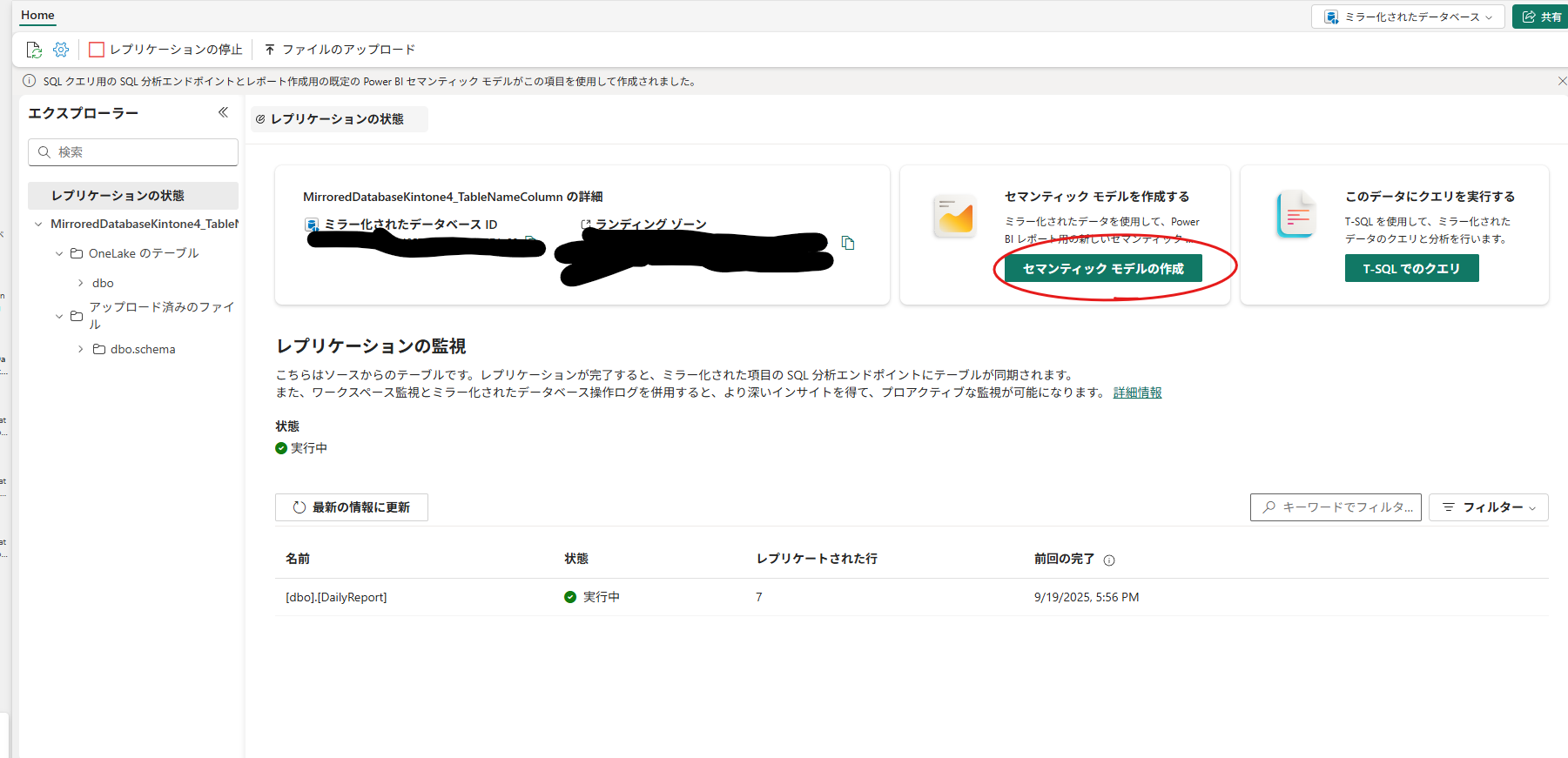
特に、ミラー化データベース内のテーブルだけで分析ニーズを満たせる場合は、追加のETLを挟まずにこのまま完結できます。
すぐにダッシュボードを公開できるので、スピード感が求められるPoCには非常に有効です。
さらに、ミラー化データベースもDeltaテーブルなので、Direct Lake モードに対応しています。
つまり、ソースデータをニアリアルタイムで効率的に可視化できます。
Lv.2は、Fabricに取り込んだデータを「すぐに見せたい・伝えたい」場面にぴったりのステップです。
Lv.3 ショートカットを駆使する
ここでFabricのもう一つの強みのショートカットが登場します。
ミラー化データベースのテーブルをレイクハウスのショートカット機能を使うことにより、データ共有が可能になります。
コピーを作ることなく、参照ベースで他部門や他ワークスペースに公開できるため、ストレージコストを増やさず(無駄な重複を増やさず)、最新データを全社で共通利用できます。
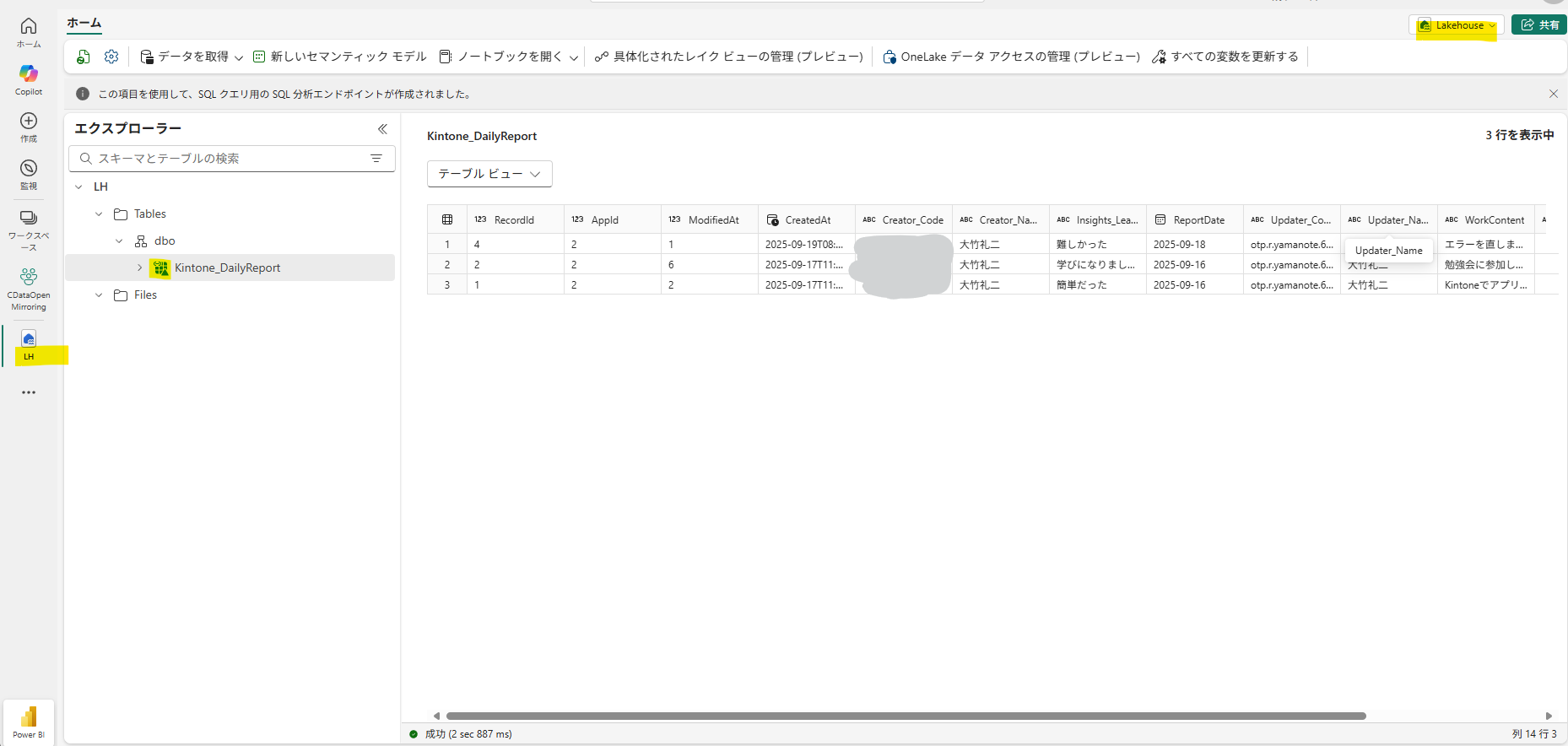
しかしショートカットは**「共有」のためだけではありません。**
ミラーリングで取り込んだテーブルをレイクハウス中に接続し、加工や変換を行いたい場合にも、このショートカットが必須になります。
つまり、単なる「閲覧用の参照」から一歩進んで、
ミラーリングテーブルをデータ統合や加工処理を進めたい
といった場面では、ショートカットを作成しておくことで初めて次のステップ(Lv.4)に進めます。
このように、Lv.3は「共有」と「移行・加工の入口」という2つの役割を担う重要なステップです。
Lv.4 加工する
ショートカットを通じてレイクハウスに取り込んだミラーリングテーブルは、通常のテーブルと同じようにFabric内で加工できます。
Notebook、Pipeline、Dataflow Gen2 といったETLアイテムを使えば、結合・集計・フィルタリングなど自由に処理を加え、新しい分析用のテーブルやデータマートを整備できます。
特に、ソースから取り込んだデータがそのままでは使いにくい「Bronzeレベル」の場合、ETLでクレンジングや変換を行い、SilverやGoldレベルへ昇格させるのがFabric活用の王道です。
▽ショートカットしたテーブルをノートブックで加工可能
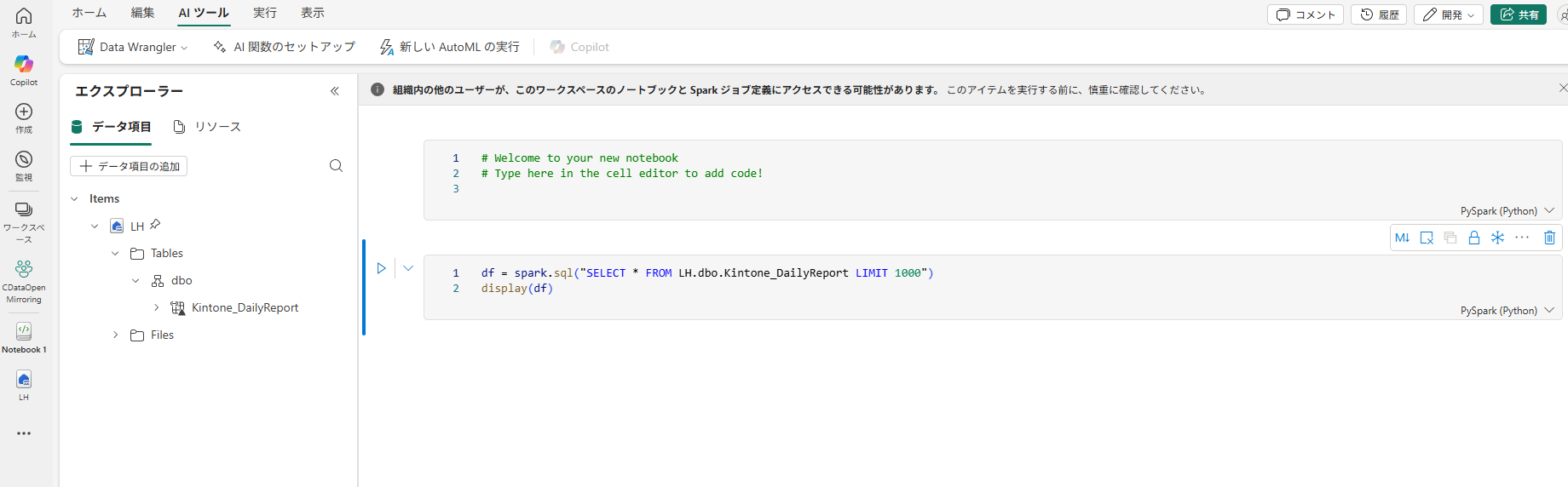
ただし、当たり前ではありますが、
ショートカット経由で参照している間はコストはかかりませんが、加工後に新しいテーブルとして保存すると、それは独立したテーブルとしてストレージを消費します。
ミラーリング=実質無料の世界から一歩進むと「普通のFabricテーブル」としてのコスト構造になる点は意識しておきましょう。
つまりLv.4は、「ただ持ってくる」から「使える形に整える」へと進むステップです。
Lv.5 リバースETL
Lv.4まで、つまりFabric内で分析・加工して可視化するだけでも十二分に価値があります。
しかし、さらに一歩進んだ活用方法が リバースETL です。
リバースETLとは、Fabric内で整形・加工したデータを再び外部システムやSaaSに書き戻す仕組みを指します。
これにより、分析結果や集計済みデータを業務現場のアプリケーションに直接返却できるようになり、Fabricは「見るだけの基盤」から「業務にデータを還元する基盤」へと進化します。
実現方法としては、Fabricのパイプラインを使い、豊富に用意されたコネクタを通じて外部システムにデータを送り出す方法があります。
これにより「取り込む」だけでなく「戻す」までを一気通貫でカバーでき、真の意味でのデータ活用ライフサイクルを完成させることができます。
コラム:ショートカットとミラーリングの違い
こちら読み飛ばしても構いません
Fabricを学ぶときに混乱しやすいのが「ショートカット」と「ミラーリング」の違いです。どちらも外部データをFabricから利用できるようにする仕組みですが、性質は大きく異なります。ここでは整理のためにいくつかの切り口から違いを見てみましょう。1. 物理的にデータを持つかどうか
ショートカットは外部のデータをそのまま参照する仕組みで、OneLake側にコピーを作りません。
対してミラーリングはデータベースの内容をOneLakeに同期して保持するため、実データがFabricに存在します。
2. 対象ソースの違い
ショートカットは主にデータレイク系のストレージ(S3やADLSなど)やFabric内の既存テーブルを対象としています。
一方ミラーリングはデータベース系のソースが中心で、Azure SQL、Cosmos DB、Snowflakeなどに対応しています。
またオープンミラーリングを使えば、SalesforceやGoogle Analyticsなど、公式に未対応のSaaSまで取り込めます。
▽ショートカットの対象
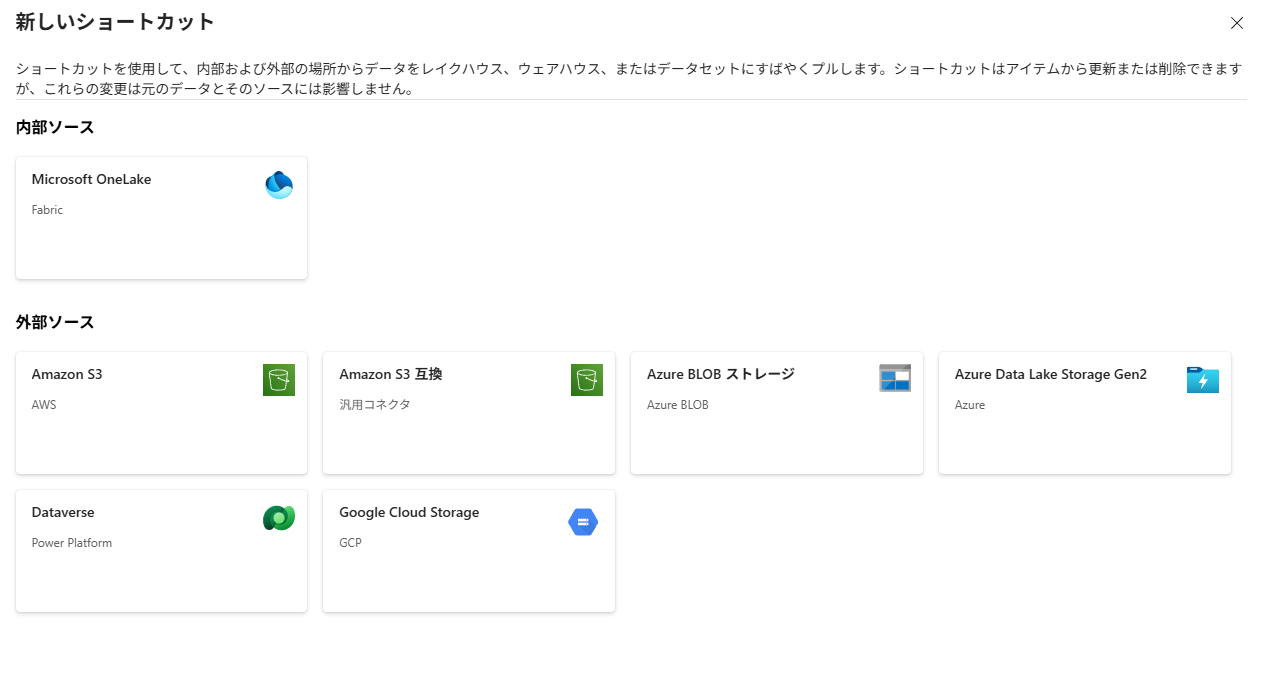
▽ミラーリングの対象
3. Fabric内での位置付け
ショートカットはレイクハウスの機能の一部として存在し、他のテーブルと並んで扱えるのが特徴です。
一方ミラーリングは独立したアイテムとしてFabricに用意されており、1つのデータベース単位で管理・操作できます。
ミラーリングテーブルを加工・ETL処理に使いたい場合は、先に紹介したようにレイクハウスへショートカットを作成しり必要があります。
4. 拡張性
ミラーリングには「オープンミラーリング」があり、外部ツールを使うことで対応ソースを大幅に拡張できます。
ショートカットにはそうした仕組みはなく、サポートされている対象に限られます。
3章 CData Syncで無限に広がるオープンミラーリングの可能性
Fabricのオープンミラーリングを使うなら、パートナーの中でも特におすすめなのが CData Sync です。
理由はシンプルで、Fabricがネイティブ対応していないサービスにも、驚くほど簡単にオープンミラーリングできてしまうからです。
CData Syncの魅力を挙げると:
- GUI操作で簡単
- 日本語サポートが可能
- 圧倒的なコネクタ数
- 日本独自サービスにも強い
つまり 「CDataさえあれば、Fabric未対応のどのサービスでもミラーリングできる」 と言えるほど、実用性の高いソリューションです。
CData syncとは
CData Sync は、数百種類以上の SaaS・DB・クラウドサービスと簡単に連携できるレプリケーションツールです。
GUIベースで操作できるため、専門的なコードを書かなくても接続からミラーリングまで数クリックで完了します。
コネクタの数は驚くほど多く、Salesforce や Snowflake といった定番から、kintone・マネーフォワードなど日本特有のサービスまでカバーしています。
「Fabricがまだネイティブ対応していないサービスもミラーリングできる」理由は、CData syncの豊富なコネクタにあります。

▽詳細は公式サイトをご覧ください。(念のため言っておきますが、私はCDataの回し者ではありません…!笑)
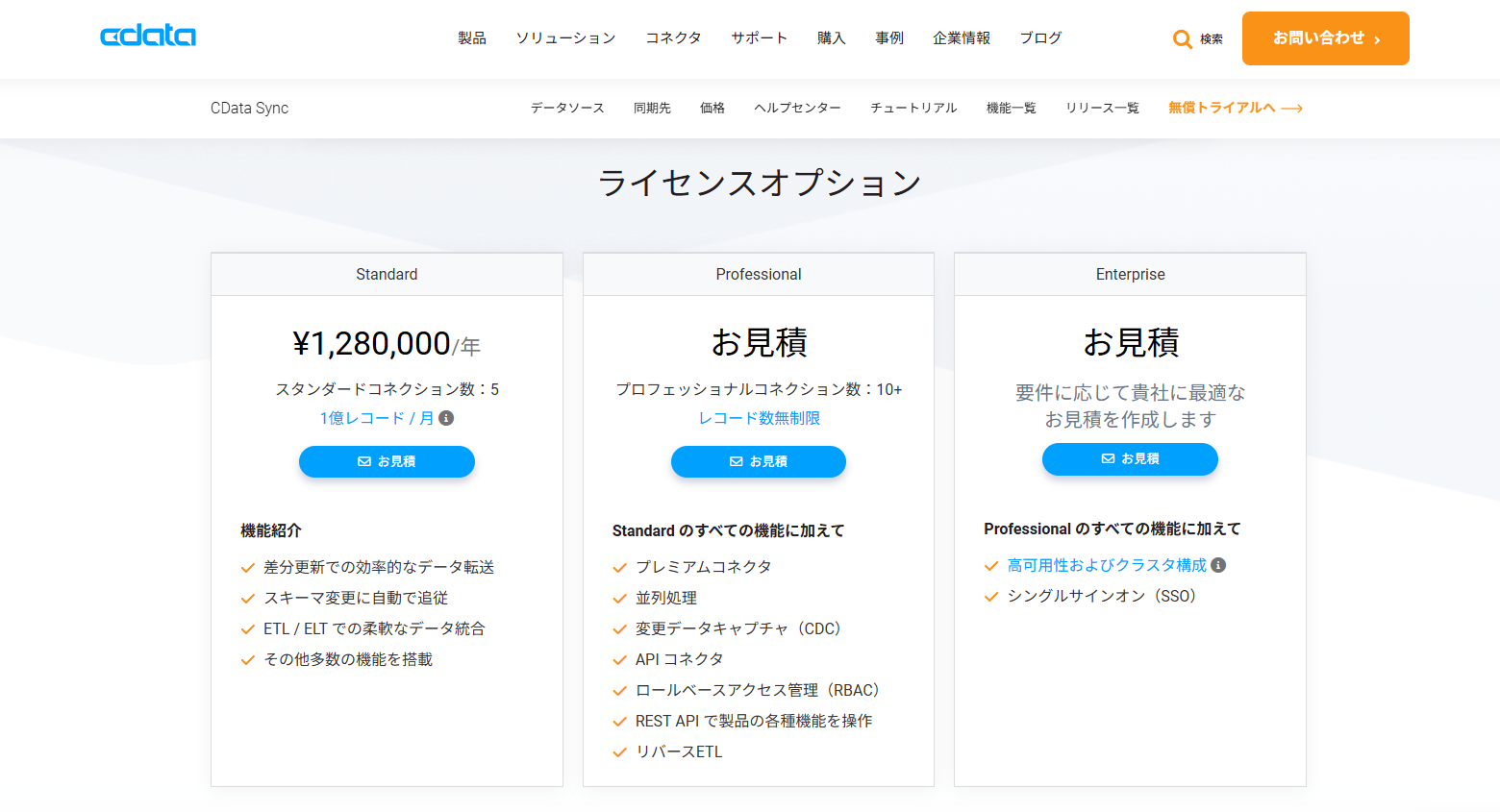
Cdata syncの料金
公式サイトによると、5コネクション・1億レコード/月 のプランで年間128万円ほどで導入可能とのことです。
一見すると高く見えるかもしれませんが、もし自前でAPI連携やETL基盤を構築するとなると、開発工数や運用保守に相応の人件費がかかります。
それを考えると「この金額で数百種類のサービスとFabricをつなげられる」というのは、十分コストパフォーマンスが高いと感じます。
まずはトライアルから
さらにありがたいことに、クラウド版には14日間の無料トライアル が用意されています。
興味がある方は、まずは実際に触って「Fabric未対応サービスをどれだけ簡単にミラーリングできるか」を体験してみるのがおすすめです。
実際に試してみた CData × オープンミラーリング 実践例
ここからは、私が CData Syncで実際に検証したオープンミラーリング事例 を紹介します。
Salesforceやkintoneといった業務アプリから、YouTube Analyticsのような外部サービスまで、Fabric標準では未対応のデータソースを実際にミラーリングしました。
手順や設定のポイントは各記事に詳細にまとめていますので、ぜひご覧ください。
Salesforceのミラーリング
Kintoneのミラーリング
IBM DB2のミラーリング
Youtubeアナリティクスのミラーリング
Coming sooon
関連記事
コラム:ミラーリングを概念から理解する(DMBOKベース)
こちら読み飛ばしても構いません(概念からしっかり理解したい人におすすめ!)
データマネジメントの国際標準である DMBOK(Data Management Body of Knowledge) では、データをどう扱い、どう届けるかについて様々な用語や概念が整理されています。ミラーリングを理解するうえでも、この枠組みを知っておくと腑に落ちやすいです。
まず前提となるのが 「複製(Replication)」 です。DMBOKの文脈では、複製とは「あるシステムのデータを別の環境にコピーして利用可能にすること」を指します(第6章 データストレージとオペレーション)。目的は可用性の確保や分析系の負荷分散など。シンプルに言えば「コピーを作ること」ですが、同じデータが複数存在するため、管理が煩雑になりがちです。
次に重要となるのが 「CDC(Change Data Capture)」 です。単純に全件コピーするのではなく、「ソース側で変更された部分だけを検出して転送する」仕組みとして定義されます(データ統合と相互運用性(第8章) )。CDCは、ネットワークやストレージの無駄を避けながら複製を効率化するアプローチで、DMBOKでもデータ統合や運用管理の一部として扱われています。
さらに一歩進んだ考え方が 「ミラーリング(Mirroring)」 です。DMBOKでは明確に「ミラーリング」という章立てがあるわけではありませんが、複製やCDCの仕組みを前提にしながら、利用者にとってほぼリアルタイムかつ一貫性のあるコピーを別の場所で扱えるようにする仕組み として理解できます。(データアーキテクチャ(第4章 や 第6章 データストレージとオペレーション(第6章))
つまり、複製 → CDC → ミラーリングという流れは、DMBOKにおける 「データアーキテクチャ(第4章)」「第6章 データストレージとオペレーション(第6章)」「データ統合と相互運用性(第8章)」 といった複数の領域が交差する部分に位置づけられます。
そして、この考え方をクラウド時代に具体的に体現しているのが Microsoft Fabric のミラーリング です。CDCをベースに外部データを取り込み、Parquet/Delta形式で標準化し、ショートカットで共有まで可能にする。DMBOKで整理されている概念が、そのままFabric上で実装されていると見ると理解しやすいでしょう。
※ここについてはAIと一緒に作成しています。間違いがありましたらご指摘ください。
おわりに
ここまで、Fabricのミラーリングの仕組みから活用方法、そしてオープンミラーリングを支えるCData Syncまで紹介してきました。
ミラーリングは「データをFabricに取り込む入口」でしかありませんが、その後の活用次第で分析・統合・共有・移行といった幅広いシナリオに応用できます。
特にオープンミラーリングを使えば、これまで扱えなかったSaaSや外部サービスもFabricに取り込めるようになり、利用シーンは大きく広がります。
まずは身近なシステムをミラーリングし、実際にFabricでの分析や可視化を体験してみてください。
きっと「ミラーリングの便利さ」を実感できるはずです。
💬 「これもミラーリングしてみて!」といったリクエストがあれば、ぜひコメントで教えてください!
Youtubeもやっているので見ていただけると嬉しいです!
FabricやDatabricksについて学べる勉強会を毎月開催しています!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページ移動後、申し込み可能です!