目的
Unityで高速フーリエ変換(FFT)を使ったガウシアンブラーの記事がなさそうなのでかいてみることにしました。またComputeShaderを駆使してなるべく高速に仕上げることを目指しました。
最後にフラグメントシェーダーとの速度比較も行なっているのでComputeShaderFFTを使う目安など参考になるかと思います。
最終的にはこんな絵ができます。

強いぼかしも同じコストで計算できます。
また後のほうにも言及していますが、FFTを使ったこのポストエフェクトはブラー処理にとどまらずConvolution Bloom処理にも応用できます。いわゆるレンズフレア(lens flare)というやつですね。

完成形
リポジトリ
URP_FFTBlur_ConvolutionBloom
解説
サンプリング系ブラー
まずブラー処理について
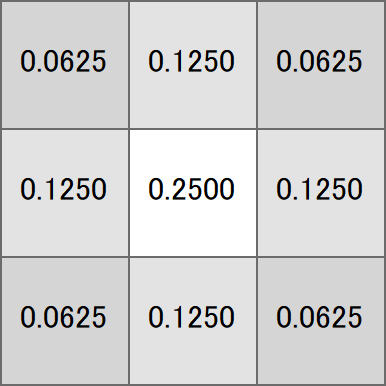
この図は近傍8+自分1=9ピクセルの色をどのくらいの重みでブレンドするかというのをあらわしています。
畳み込みカーネル(Convolution Kernel)ともよばれます。

↑この画像に1回この処理を実行すると↓

わずかに滲んでいるのがわかります。
もう1回この処理を実行すると
もう少し滲んできているのがわかります。
さらに4回この処理を実行すると
けっこう滲んできているのがわかります。
さて、合計6回の処理をまとめた重みを事前計算で求めておけば、1回の処理で6回分のブレンドが可能になります。

私が調べた限りサンプリング系ブラー実装のほとんどは「1つ隣までみるブラー×N段」か「Nつ隣までみるブラー×1段」の処理でかかれています。
とりあえずこれだけ知っていれば他人のコードでも何をしているか理解しやすいと思います。
(他にも2次元の処理を1次元×2回でやっている等工夫はありますが)
FFTブラー
次にFFTを使ったブラーの畳み込みの解説です。
畳み込みとはなんぞやというとこですが、ここでは多倍長整数乗算の例をだしてみます。以下のような14134141×62955312のかけ算を考えます。
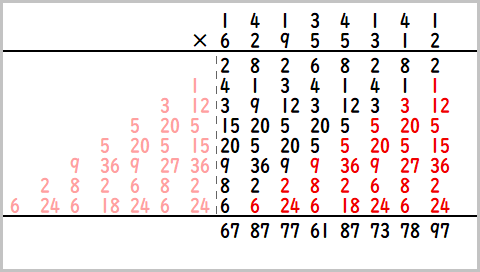
普通と違うところは赤文字のところで、赤文字を無視してみれば手で計算する筆算と同じですね。
図では左側のピンク文字が右にまわりこんでいるのがわかります。
これを正巡回の畳み込み乗算といい、FFT(NTT)を使うことで計算できます。
少し工夫すると負巡回の畳み込み乗算も可能です。

この正巡回と負巡回の結果を使うことで巡回部分とそうでない黒い部分を分離できるため、14134141×62955312の値が求まります。
(参考:FFTでの正巡回、負巡回畳み込みの話 離散荷重変換 https://qiita.com/peria/items/cf4c4b72ebbeec7728af#fnref1)
ここでさっきの「Nつ隣まで見てブラー×1段」の処理をおもいだしてください。
かけ算の2つの数のうち、上の数をぼかしたい画像に、下の数を重みとして計算したらどうなるでしょうか。
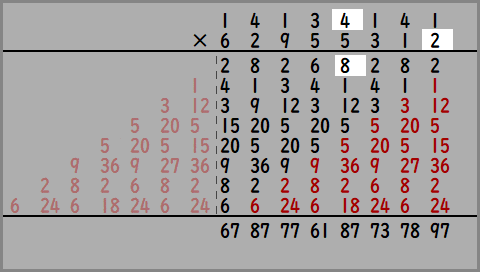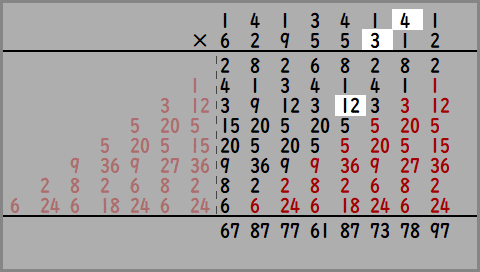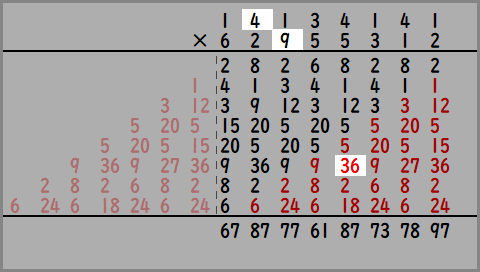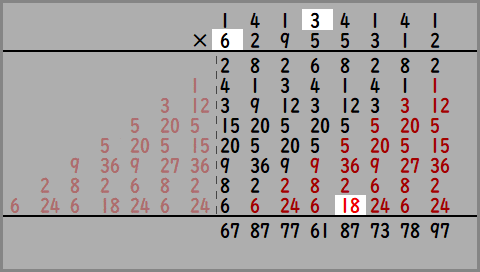
出力された数は、8ピクセルにわたって重みをかけて足した結果となっており、「Nつ隣まで見てブラー」と同じことをしているのがわかると思います。
実装
上記の畳み込み乗算は、かけたい数2つをFFTで変換し、変換後要素ごとにかけ算し、それをIFFTすれば得られます。
FFTの問題として画像サイズは2のべき乗が望ましいという制約があります。なのでぼかしたい画像も重み側も512×512など適切なサイズに拡縮する必要があります。
毎フレームぼかしをかけたい場合、フレームバッファは毎回FFTで変換します。ただ重みのほうはFFTの結果を使い回せます。
処理イメージ(可視化されたバッファはあくまでイメージです)

ここで
- フレームバッファのY方向のFFT
- 要素ごとの積
- Y方向のIFFT
の3つはまとめて計算することにします。つまりGPUメモリに戻さずレジスタとThread Group Shared Memory(共有メモリ)で一気に計算を進めてしまいます。そうすることでメモリアクセスを減らし、メモリバンド幅律速になりやすい計算を高速化するねらいがあります。
[参考]https://www.intel.com/content/dam/develop/external/us/en/documents/fast-fourier-transform-for-image-processing-in-directx-11-541444.pdf
これを実装したBuilt-inのコードを示します。(URPはもうちょっと複雑になるのでリポジトリ参照を)
FFTBlur.cs(空のゲームオブジェクトにアタッチ)
using UnityEngine;
public class FFTBlur : MonoBehaviour
{
//Bloom設定周り
const int M = 9;//ここをかえたらComputeShader側のMX,MYもかえるよう。最小4
const int fftSize = 1 << M;
private RenderTextureFormat bloomTexFormat = RenderTextureFormat.ARGBFloat;//or ARGBHalf
//compute shader周り
[SerializeField] ComputeShader cs;
[SerializeField] Texture2D convolutionKernel;
[SerializeField] float intensity;
float intensity_back;//重みの合計を1.0に正規化するため
int kernelFFTX, kernelIFFTX;
int kernelFFTY_HADAMARD_IFFTY;
int kernelFFTWY, kernelCopySlide;
RenderTexture rtexWeight = null;//convolutionKernelのFFT計算後の重みが入る
private void Awake()
{
kernelFFTX = cs.FindKernel("FFTX");
kernelIFFTX = cs.FindKernel("IFFTX");
kernelFFTY_HADAMARD_IFFTY = cs.FindKernel("FFTY_HADAMARD_IFFTY");
kernelFFTWY = cs.FindKernel("FFTWY");
kernelCopySlide = cs.FindKernel("CopySlide");
cs.SetFloat("_intensity", intensity);
CreateWeight();
}
//Convolution kernel画像を読み込んでリサイズして正規化して重みをFFTしてを計算しておく
//重みFFTはrtexWeightに保存
private void CreateWeight()
{
if (rtexWeight != null) rtexWeight.Release();
rtexWeight = new RenderTexture(fftSize, fftSize / 4 * 3 + 2, 0, bloomTexFormat);
rtexWeight.enableRandomWrite = true;
rtexWeight.Create();
RenderTexture rtex1 = RenderTexture.GetTemporary(fftSize, fftSize, 0, bloomTexFormat);
rtex1.enableRandomWrite = true;
rtex1.Create();
RenderTexture rtex2 = RenderTexture.GetTemporary(fftSize, fftSize, 0, bloomTexFormat);
rtex2.enableRandomWrite = true;
rtex2.Create();
RenderTexture rtex3 = RenderTexture.GetTemporary(fftSize / 4 * 3 + 2, fftSize, 0, bloomTexFormat);
rtex3.enableRandomWrite = true;
rtex3.Create();
uint[] res = new uint[4];
for (int i = 0; i < 4; i++) res[i] = 0;
ComputeBuffer SumBuf = new ComputeBuffer(4, 4);//R,G,Bそれぞれにおける全画面の値の総計。重みの合計を1.0に正規化するため
SumBuf.SetData(res);
//Convolution kernel読み込み→rtex2
Graphics.Blit(convolutionKernel, rtex2);//ComputeShaderはRenderTextureしか扱えないので
//テクスチャの中心を0,0に移動。ついでにSumBufに全画素値合計する
cs.SetBuffer(kernelCopySlide, "SumBuf", SumBuf);
cs.SetTexture(kernelCopySlide, "Tex_ro", rtex2);
cs.SetTexture(kernelCopySlide, "Tex", rtex1);
cs.SetInt("width", fftSize);
cs.SetInt("height", fftSize);
cs.Dispatch(kernelCopySlide, fftSize / 8, fftSize / 8, 1);
//1
cs.SetTexture(kernelFFTX, "Tex_ro", rtex1);
cs.SetTexture(kernelFFTX, "Tex", rtex3);
cs.Dispatch(kernelFFTX, fftSize, 1, 1);
//2
cs.SetTexture(kernelFFTWY, "Tex_ro", rtex3);
cs.SetTexture(kernelFFTWY, "Tex", rtexWeight);
cs.Dispatch(kernelFFTWY, fftSize / 4 * 3 + 2, 1, 1);//FFTY_HADAMARD_IFFTYでのTexture read高速化のため転置している
//intensity_backの計算
SumBuf.GetData(res);
intensity_back = 1.0f * res[0];
for (int i = 1; i < 3; i++)
intensity_back = Mathf.Max(intensity_back, res[i]);
if (intensity_back != 0.0f)
intensity_back = 255.0f / intensity_back;
//Release
RenderTexture.active = null;//これがないとrtex2の解放でReleasing render texture that is set to be RenderTexture.active!が発生する
RenderTexture.ReleaseTemporary(rtex3);
RenderTexture.ReleaseTemporary(rtex2);
RenderTexture.ReleaseTemporary(rtex1);
SumBuf.Release();
}
//sourceをリサイズして読み込みFFT計算
//計算後のデータが入ったfftSize×fftSizeサイズのRenderTextureが返る
public RenderTexture FFTConvolution(RenderTexture source)
{
RenderTexture rtex1 = RenderTexture.GetTemporary(fftSize / 4 * 3 + 2, fftSize, 0, bloomTexFormat);
rtex1.enableRandomWrite = true;
rtex1.Create();
RenderTexture returnRT = RenderTexture.GetTemporary(fftSize, fftSize, 0, bloomTexFormat);
returnRT.enableRandomWrite = true;
returnRT.Create();
cs.SetFloat("_intensity", intensity * intensity_back);//weightを計算したときのintensity_backも乗算
cs.SetInt("width", source.width);
cs.SetInt("height", source.height);
//1
cs.SetTexture(kernelFFTX, "Tex_ro", source);
cs.SetTexture(kernelFFTX, "Tex", rtex1);
cs.Dispatch(kernelFFTX, fftSize, 1, 1);
//2
cs.SetTexture(kernelFFTY_HADAMARD_IFFTY, "Tex", rtex1);
cs.SetTexture(kernelFFTY_HADAMARD_IFFTY, "Tex_ro", rtexWeight);
cs.Dispatch(kernelFFTY_HADAMARD_IFFTY, fftSize / 4 * 3 + 2, 1, 1);
//3
cs.SetTexture(kernelIFFTX, "Tex_ro", rtex1);
cs.SetTexture(kernelIFFTX, "Tex", returnRT);
cs.Dispatch(kernelIFFTX, fftSize, 1, 1);
RenderTexture.ReleaseTemporary(rtex1);
return returnRT;
}
private void OnDisable()
{
rtexWeight.Release();
}
}
CamerasOnRenderImage.cs(カメラにアタッチ)
using UnityEngine;
public class CamerasOnRenderImage : MonoBehaviour
{
[SerializeField] FFTBlur fFTBlur;
private void OnRenderImage(RenderTexture source, RenderTexture dest)
{
RenderTexture rt = fFTBlur.FFTConvolution(source);//rt = FFT_Convolution計算結果がはいる
Graphics.Blit(rt, dest);//ここでは拡大縮小コピーしかしてない
RenderTexture.ReleaseTemporary(rt);
}
}
FFTBlur.compute(FFTBlurのオブジェクトにアタッチ)
#pragma kernel FFTX
#pragma kernel FFTY_HADAMARD_IFFTY
#pragma kernel IFFTX
#pragma kernel FFTWY
#pragma kernel CopySlide
#define PI 3.14159265358979323846264338328
#define MX (9)
#define MY (9)
#define NX (1<<MX)
#define NY (1<<MY)
RWTexture2D<float4> Tex;
Texture2D<float4> Tex_ro;//read only
RWStructuredBuffer<uint> SumBuf;
groupshared float4 blockX[NX];
groupshared float4 blockY[NY];
float _intensity;
int width, height;//tex_ro's (width, height)
[numthreads(8, 8, 1)]
void CopySlide(uint2 id : SV_DispatchThreadID)
{
if ((id.x >= (uint)width) | (id.y >= (uint)height))return;
float2 idx = float2(id.x, id.y) + float2(width, height) * 0.5;
if (idx.x > width)idx.x -= width;
if (idx.y > height)idx.y -= height;
float4 f4 = Tex_ro[idx];
Tex[id] = f4;
InterlockedAdd(SumBuf[0], (uint)(f4.x * 255.0 + 0.5));
InterlockedAdd(SumBuf[1], (uint)(f4.y * 255.0 + 0.5));
InterlockedAdd(SumBuf[2], (uint)(f4.z * 255.0 + 0.5));
}
[numthreads(NY / 2, 1, 1)]
void FFTWY(uint id : SV_DispatchThreadID, uint grid : SV_GroupID, uint gi : SV_GroupIndex)
{
float4 reim0 = 0;
float4 reim1 = 0;
reim0 = Tex_ro[float2(grid, gi)];
reim1 = Tex_ro[float2(grid, gi + NY / 2)];
blockY[gi] = reim0;
blockY[gi + NY / 2] = reim1;
for (uint loopidx = 0; loopidx < MY; loopidx++)
{
uint dleng = 1 << (MY - loopidx - 1);
uint t = gi % dleng;
uint t0 = (gi / dleng) * dleng * 2 + t;
uint t1 = t0 + dleng;
GroupMemoryBarrierWithGroupSync();
float4 ri4t1, ri4t0;
ri4t1 = blockY[t1];
ri4t0 = blockY[t0];
float rad = -PI * t / dleng;
float fsin = sin(rad);
float fcos = cos(rad);
blockY[t0] = ri4t0 + ri4t1;
ri4t0 -= ri4t1;
ri4t1.x = ri4t0.x * fcos - ri4t0.y * fsin;
ri4t1.y = ri4t0.x * fsin + ri4t0.y * fcos;
ri4t1.z = ri4t0.z * fcos - ri4t0.w * fsin;
ri4t1.w = ri4t0.z * fsin + ri4t0.w * fcos;
blockY[t1] = ri4t1;
}
GroupMemoryBarrierWithGroupSync();
reim0 = blockY[gi];
reim1 = blockY[gi + NY / 2];
Tex[float2(gi, grid)] = reim0;
Tex[float2(gi + NY / 2, grid)] = reim1;
}
[numthreads(NX / 2, 1, 1)]
void FFTX(uint id : SV_DispatchThreadID, uint grid : SV_GroupID, uint gi : SV_GroupIndex)
{
float4 f4;
float4 g4;
f4 = Tex_ro[float2(1.0 * gi * width / NX, 1.0 * grid * height / NY)];
g4 = Tex_ro[float2(1.0 * (gi + NX / 2) * width / NX, 1.0 * grid * height / NY)];
blockX[gi] = f4;
blockX[gi + NX / 2] = g4;
for (uint loopidx = 0; loopidx < MX; loopidx++)
{
uint dleng = 1 << (MX - loopidx - 1);
uint t = gi % dleng;
uint t0 = (gi / dleng) * dleng * 2 + t;
uint t1 = t0 + dleng;
GroupMemoryBarrierWithGroupSync();
float4 ri4t1,ri4t0;
ri4t1 = blockX[t1];
ri4t0 = blockX[t0];
float rad = -PI * t / dleng;
float fsin, fcos;
sincos(rad, fsin, fcos);
blockX[t0] = ri4t0 + ri4t1;
ri4t0 -= ri4t1;
ri4t1.x = ri4t0.x * fcos - ri4t0.y * fsin;
ri4t1.y = ri4t0.x * fsin + ri4t0.y * fcos;
ri4t1.z = ri4t0.z * fcos - ri4t0.w * fsin;
ri4t1.w = ri4t0.z * fsin + ri4t0.w * fcos;
blockX[t1] = ri4t1;
}
GroupMemoryBarrierWithGroupSync();
uint idx1 = gi;
uint idx2 = NX - gi;
g4 = blockX[reversebits(idx2) >> (32 - MX)];//A~n-k
f4 = blockX[reversebits(idx1) >> (32 - MX)];//Ak
g4.y *= -1;
g4.w *= -1;
float4 h4 = (f4 + g4) * 0.5;//Rk(r,b) 0<=k<n/2
Tex[uint2(gi, grid)] = h4;
f4 = (f4 - g4) * 0.5;//iSk(g) 0<=k<n/2
g4.x = f4.y;
g4.y = -f4.x;
g4.z = f4.w;
g4.w = -f4.z;//Sk(g) 0<=k<n/2
GroupMemoryBarrierWithGroupSync();
blockX[NX / 2 + gi] = g4;
GroupMemoryBarrierWithGroupSync();
if (gi < NX / 4)
{
h4.xy = blockX[NX / 2 + gi * 2].xy;
h4.zw = blockX[NX / 2 + gi * 2 + 1].xy;
Tex[uint2(gi + NX / 2, grid)] = h4;
}
if (gi == NX / 2 - 1)
{
f4 = blockX[1];//Ak
h4 = 0;
h4.x = f4.x;
h4.z = f4.z;
g4 = 0;
g4.x = f4.y;
g4.z = f4.w;
Tex[uint2(NX / 4 * 3, grid)] = h4;
Tex[uint2(NX / 4 * 3 + 1, grid)] = g4;
}
}
[numthreads(NY / 2, 1, 1)]
void FFTY_HADAMARD_IFFTY(uint id : SV_DispatchThreadID, uint grid : SV_GroupID, uint gi : SV_GroupIndex)
{
blockY[gi] = Tex[uint2(grid, gi)];
blockY[gi + NY / 2] = Tex[uint2(grid, gi + NY / 2)];
for (uint loopidx = 0; loopidx < MY; loopidx++)
{
uint dleng = 1 << (MY - loopidx - 1);
uint t = gi % dleng;
uint t0 = (gi / dleng) * dleng * 2 + t;
uint t1 = t0 + dleng;
GroupMemoryBarrierWithGroupSync();
float4 ri4t1, ri4t0;
ri4t1 = blockY[t1];
ri4t0 = blockY[t0];
float rad = -PI * t / dleng;
float fsin, fcos;
sincos(rad, fsin, fcos);
blockY[t0] = ri4t0 + ri4t1;
ri4t0 -= ri4t1;
ri4t1.x = ri4t0.x * fcos - ri4t0.y * fsin;
ri4t1.y = ri4t0.x * fsin + ri4t0.y * fcos;
ri4t1.z = ri4t0.z * fcos - ri4t0.w * fsin;
ri4t1.w = ri4t0.z * fsin + ri4t0.w * fcos;
blockY[t1] = ri4t1;
}
GroupMemoryBarrierWithGroupSync();
float4 reim0 = blockY[gi];
float4 reim1 = blockY[gi + NY / 2];
float4 w = Tex_ro[uint2(gi, grid)];//weight
float4 tmp = reim0;
reim0.x = tmp.x * w.x - tmp.y * w.y;
reim0.y = tmp.y * w.x + tmp.x * w.y;
reim0.z = tmp.z * w.z - tmp.w * w.w;
reim0.w = tmp.w * w.z + tmp.z * w.w;
//
w = Tex_ro[uint2(gi + NY / 2, grid)];
tmp = reim1;
reim1.x = tmp.x * w.x - tmp.y * w.y;
reim1.y = tmp.y * w.x + tmp.x * w.y;
reim1.z = tmp.z * w.z - tmp.w * w.w;
reim1.w = tmp.w * w.z + tmp.z * w.w;
blockY[gi] = reim0;
blockY[gi + NY / 2] = reim1;
for (uint loopidx = 0; loopidx < MY; loopidx++)
{
uint dleng = 1 << (loopidx);
uint t = gi % dleng;
uint t0 = (gi / dleng) * dleng * 2 + t;
uint t1 = t0 + dleng;
GroupMemoryBarrierWithGroupSync();
float4 ri4t1, ri4t0;
ri4t1 = blockY[t1];
ri4t0 = blockY[t0];
float rad = PI * t / dleng;//inv -
float fsin = sin(rad);
float fcos = cos(rad);
float4 ri4t2;
ri4t2.x = ri4t1.x * fcos - ri4t1.y * fsin;
ri4t2.y = ri4t1.x * fsin + ri4t1.y * fcos;
ri4t2.z = ri4t1.z * fcos - ri4t1.w * fsin;
ri4t2.w = ri4t1.z * fsin + ri4t1.w * fcos;
blockY[t1] = ri4t0 - ri4t2;
blockY[t0] = ri4t0 + ri4t2;
}
GroupMemoryBarrierWithGroupSync();
w = blockY[gi] / NY;
Tex[uint2(grid, gi)] = w;
w = blockY[gi + NY / 2] / NY;
Tex[uint2(grid, gi + NY / 2)] = w;
}
[numthreads(NX / 2, 1, 1)]
void IFFTX(uint id : SV_DispatchThreadID, uint grid : SV_GroupID, uint gi : SV_GroupIndex)
{
float4 g4, h4, f4;
uint idx;
if (gi == 0)
{
h4 = Tex_ro[uint2(NX / 4 * 3 + 0, grid)];
g4 = Tex_ro[uint2(NX / 4 * 3 + 1, grid)];
f4.x = h4.x;
f4.z = h4.z;
f4.y = g4.x;
f4.w = g4.z;
blockX[NX / 2] = f4;
}
h4 = Tex_ro[uint2(gi, grid)];//Rk(r,b) 0<=k<n/2
g4 = Tex_ro[uint2(gi / 2 + NX / 2, grid)];//Sk(g) 0<=k<n/2
if (gi % 2 == 1)
{
g4.x = g4.z;
g4.y = g4.w;
}
g4.z = 0;
g4.w = 0;
f4.x = -g4.y;
f4.y = g4.x;
f4.z = -g4.w;
f4.w = g4.z;//iSk(g) 0<=k<n/2
blockX[gi] = (h4 + f4);
f4 = (h4 - f4);
f4.y *= -1;
f4.w *= -1;
if (gi != 0)
{
idx = NX - gi;
blockX[idx] = f4;
}
for (uint loopidx = 0; loopidx < MX; loopidx++)
{
uint dleng = 1 << (MX - loopidx - 1);
uint t = gi % dleng;
uint t0 = (gi / dleng) * dleng * 2 + t;
uint t1 = t0 + dleng;
GroupMemoryBarrierWithGroupSync();
float4 ri4t1, ri4t0;
ri4t1 = blockX[t1];
ri4t0 = blockX[t0];
float rad = PI * t / dleng;
float fsin, fcos;
sincos(rad, fsin, fcos);
blockX[t0] = ri4t0 + ri4t1;
ri4t0 -= ri4t1;
ri4t1.x = ri4t0.x * fcos - ri4t0.y * fsin;
ri4t1.y = ri4t0.x * fsin + ri4t0.y * fcos;
ri4t1.z = ri4t0.z * fcos - ri4t0.w * fsin;
ri4t1.w = ri4t0.z * fsin + ri4t0.w * fcos;
blockX[t1] = ri4t1;
}
GroupMemoryBarrierWithGroupSync();
f4 = blockX[reversebits(gi) >> (32 - MX)];
h4 = blockX[reversebits(gi + NX / 2) >> (32 - MX)];
f4 = f4 / NX * _intensity;
//f4.w = 1;
Tex[uint2(gi, grid)] = f4;
h4 = h4 / NX * _intensity;
//h4.w = 1;
Tex[uint2(gi + NX / 2, grid)] = h4;
}
画像(FFTBlurのオブジェクトにアタッチ)


結果

Convolution Bloom(レンズフレア)
明るいところで光条がチカチカしているのがそれです。
詳しくはUEのドキュメントをみるとわかりやすいかもしれません。
https://docs.unrealengine.com/4.27/ja/RenderingAndGraphics/PostProcessEffects/Bloom/
UEには標準で実装されているようですが、私が調べた限りUnityにConvolution Bloomは搭載されていません。
ないなら作ればいいじゃない、ということで今回のFFTブラーを少しいじって作ってみました。(リポジトリ参照)
最初の方でもふれましたが今回のコードはConvolution Bloomで真価を発揮すると考えています。
原理としては、FFTブラーのときに使っていたガウス分布画像のかわりにスターバースト↓の画像を使います。

画面全体でなくフレームバッファの明るい部分のみに適応したいので、それ用のテクスチャを用意して後はFFTブラーのときと同じです。
特筆すべきはこのスターバースト画像の自由度であり、左右非対称だろうが100方向にフレアが伸びてようが、その画像を用意さえすれば一発でできるため良いです。同じことをサンプリングベースの方法で実装するのは難しいでしょう。
(まぁあるにはあるんですけどね・・・ https://ics.media/entry/19728/)
Convolution Bloom実用例
以前私が作成したFFT Oceanに今回のConvolution Bloomを適応してみました。反射の明るい部分に注目するとレンズフレアの効果がついているのがわかります。

また明るさに応じてフレアの大きさも変わってきているのがわかります。ここはConvolution KernelにHDR画像を使っている恩恵がでていますね。実際表示している大きさは同じだけれどハイダイナミックレンジの色情報があるため、輝度を上げるとフレアが大きく見えるのです。
速度比較
FFTってすごいけど(計算コストが)お高いんでしょう?
と疑問もあると思うので速度比較を行ないました。
FFTブラー VS 複数点サンプリングブラー
公式サンプルでブラーをやっているコードをここから落としてきました。
https://docs.unity3d.com/ja/2018.4/Manual/GraphicsCommandBuffers.html

公式サンプルでは複数点のサンプリングブラーを7点×4段やっているようでした。
1回のフラグメントシェーダーで7回サンプリング。これがX方向2段+Y方向2段。
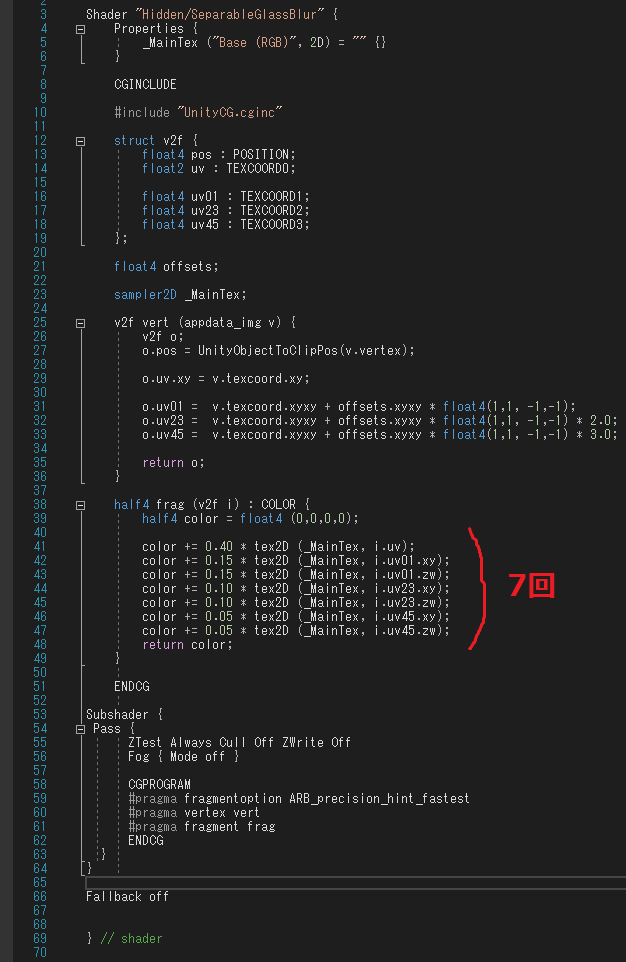
ちょっと中身をいじって画像サイズ512×512 R32G32B32A32として、PIXを使って速度を計測しました。
GPUはRadeon RX 6600を使いました。2021年発売のミドルレンジ帯GPUです。
[7回×4段サンプリングブラーの速度]
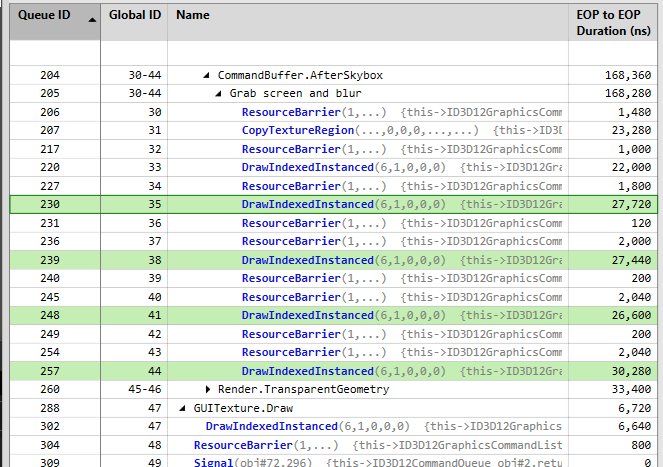
合計112,040 nsです。
これは約0.1msであり1フレーム16msですから、このままでも十分速いことがわかります。
次にFFTブラーです。
計算途中のバッファも含めサイズ512×512 R32G32B32A32で統一し
1,X方向FFT
2,Y方向FFT+要素積+Y方向IFFT
3,X方向IFFT
の速度を計測しました。
[FFTブラーの速度]
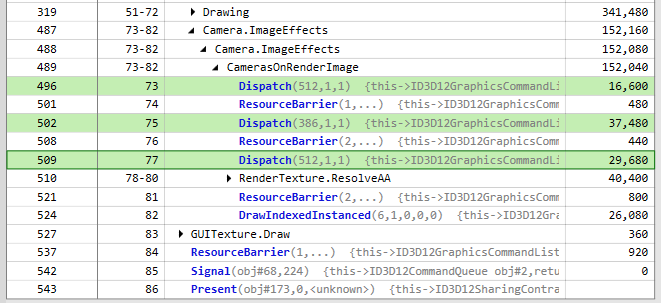
合計83,760 nsです。
なんとFFTブラーのほうがわずかに速いという結果になりました!
最適化した甲斐がありました。
次にローエンドGPUでも試してみました。ノートPCに搭載されているNVIDIA MX 450です。
モバイルでの動作を考えるならこっちの結果のほうが参考になるでしょう。
[7回×4段サンプリングブラーの速度]
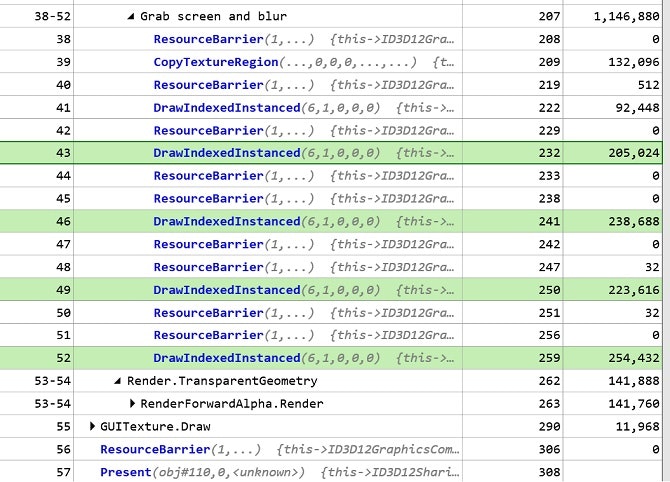
合計921,760 nsです。
[FFTブラーの速度]
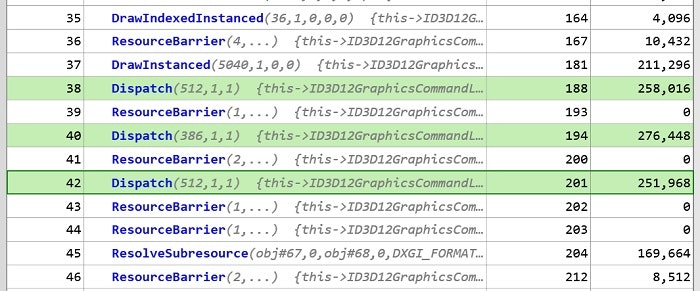
合計786,432 nsです。
やはりローエンドGPUでも7回×4段サンプリングにはギリ勝っているという感じです。
ただ結果の解釈で少し注意が必要なのは、本当にサンプリング方式ではR32G32B32A32も必要なのか、というとこです。
実際にやってみるとわかるのですがFFTブラーの計算ではFloat精度が必須なのに対し、サンプリングブラーではHalf精度で十分です。
つまり実用的なサンプリングブラーはこの2倍速いはずであり、そういう意味では高速化のために無理にFFTを使ったブラーを実装する必要性は薄そうです。
| FFTブラー | サンプリングブラーFloat | サンプリングブラーHalf(予測値) |
|---|---|---|
| 83,760 ns | 112,040 ns | 56,020 ns |
| 786,432 ns | 921,760 ns | 460,880 ns |
もちろんサンプリング点数が変わればその分負荷はかわってきます。そこらへんも含めて参考にしてみて下さい。
Unity FFTブラー VS Unreal EngineのConvolutionBloom
Unreal EngineにはConvolutionBloomが実装されています。今回Unityで実装したものを使ってUnity VS UEの夢の対決をしてみましょう。
UE5を自分のPCにインストールして時間計測できそうだったのでやってみました。
[UE5のConvolutionBloomの速度 RX 6600]
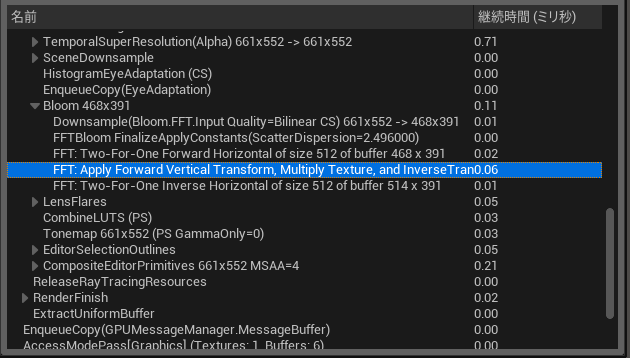
1,X方向FFT 0.02ms
2,Y方向FFT+要素積+Y方向IFFT 0.06ms
3,X方向IFFT 0.01ms
もう少し時間解像度がほしいところですが、まとめると
| Unity(RX 6600) | UE(RX 6600) | |
|---|---|---|
| 1 | 16,600 ns | 20,000 ns |
| 2 | 37,480 ns | 60,000 ns |
| 3 | 29,680 ns | 10,000 ns |
| 合計 | 83,760 ns | 90,000 ns |
勝ちました~!(ほんとか)
まぁ計算内容が同じかどうかわからないので単純に比較はできないですよね。
正巡回負巡回のところであったよう、私の実装したConvolutionBloomはフレアが画面端から画面端にまわりこんでしまうものになっています。しかしUEのほうはまわりこんでいなかったので、そこらへんの対策もなされた計算がされているのかもしれません。
参考文献
[下町のナポレオン] Compute Shader でFFTと畳み込み演算でブラー
https://hikita12312.hatenablog.com/entry/2017/11/11/180524
bloom-in-unreal-engine
https://docs.unrealengine.com/5.1/en-US/bloom-in-unreal-engine/
https://docs.unrealengine.com/4.27/ja/RenderingAndGraphics/PostProcessEffects/Bloom/
[Youtube] Unreal Engine - Image-Based (FFT) Convolution for Bloom
https://www.youtube.com/watch?v=SkJgopq-JQA&ab_channel=UnrealEngine
Fast Fourier Transform for Image Processing in DirectX* 11
https://www.intel.com/content/dam/develop/external/us/en/documents/fast-fourier-transform-for-image-processing-in-directx-11-541444.pdf
[e.blog] URPで背景をぼかしてuGUIの背景にする
https://edom18.hateblo.jp/entry/2020/11/02/080719
[ICS MEDIA]Unity Post Processing Stackで作る光芒エフェクト
https://ics.media/entry/19728/
Extending Unity 5 rendering pipeline: Command Buffers
https://blog.unity.com/technology/extending-unity-5-rendering-pipeline-command-buffers
[Unity] 海洋シミュレーションFFT Oceanを実装したい
https://qiita.com/Red_Black_GPGPU/items/2652f5bfd6d311d2034b
[Qiita] FFT を用いた多倍長整数の乗算の効率化 (2)
https://qiita.com/peria/items/cf4c4b72ebbeec7728af#fnref1
[Qiita] ポストエフェクトクエスト - 波動と回折とレンズと使われしシェーダ -
https://qiita.com/AngularSpectrumMTD/items/77f71b24b21cbc3d2a52
[Qiita] ポストエフェクトクエスト - スターバースト -
https://qiita.com/AngularSpectrumMTD/items/584e07052317a3dc8768