みなさん、こんにちは!
Snowflake Open Catalog は、Apache Polaris をベースとしたフルマネージドのカタログサービスです。Iceberg REST互換の様々なクエリエンジンに対して、Iceberg形式のテーブルへの一元化された読み書きアクセスを提供します。
本記事では、S3を外部ボリュームとした Snowflake のテーブルを Open Catalog に登録し、Google Colaboratory から参照するまでの流れについて解説します。
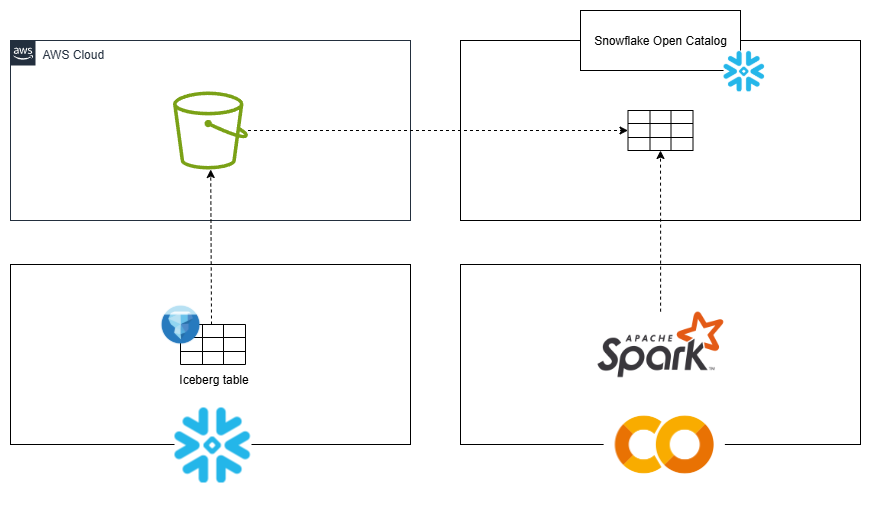
設定手順
オブジェクトストレージ、ロール作成
外部ボリュームとして登録するためのオブジェクトストレージとSnowflake用のロールを作成します。
今回はAWSを利用し、S3バケットとIAMロールを作成します。
IAMロールの信頼されたエンティティタイプは「AWSアカウント(このアカウント)」で、ポリシーは「AmazonS3FullAccess」をアタッチしておきます。
外部ボリューム作成
リソースを作成したら、外部ボリュームを作成します。
Snowflake のワークシートで以下のSQLを実行します。
CREATE OR REPLACE EXTERNAL VOLUME s3_iceberg_volume
STORAGE_LOCATIONS =
(
(
NAME = 's3_iceberg_volume'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://snowflake-external-volume-bucket-01/iceberg'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<ACCOUNT_ID>:role/snowflake-external-volume-bucket-role'
)
);
外部ボリューム作成後、以下のSQLを実行し外部ボリュームの詳細を確認します。
DESC EXTERNAL VOLUME s3_iceberg_volume;

以下の値を記録しておきます。
STORAGE_AWS_IAM_USER_ARNSTORAGE_AWS_EXTERNAL_ID
IAMロールの信頼ポリシーを以下のように修正します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<STORAGE_AWS_IAM_USER_ARN>"
},
"Action": "sts:AssumeRole",
"Condition": {"StringEquals": { "sts:ExternalId": "<STORAGE_AWS_EXTERNAL_ID>" }}
}
]
}
Icebergテーブル作成
外部ボリューム上にテーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE sample_data(
id INTEGER,
content STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 's3_iceberg_volume'
BASE_LOCATION = 'sample_data';
INSERT INTO sample_data VALUES (1, 'a'), (2, 'b'), (3, 'c');
BASE_LOCATIONはデータ格納先のディレクトリです。
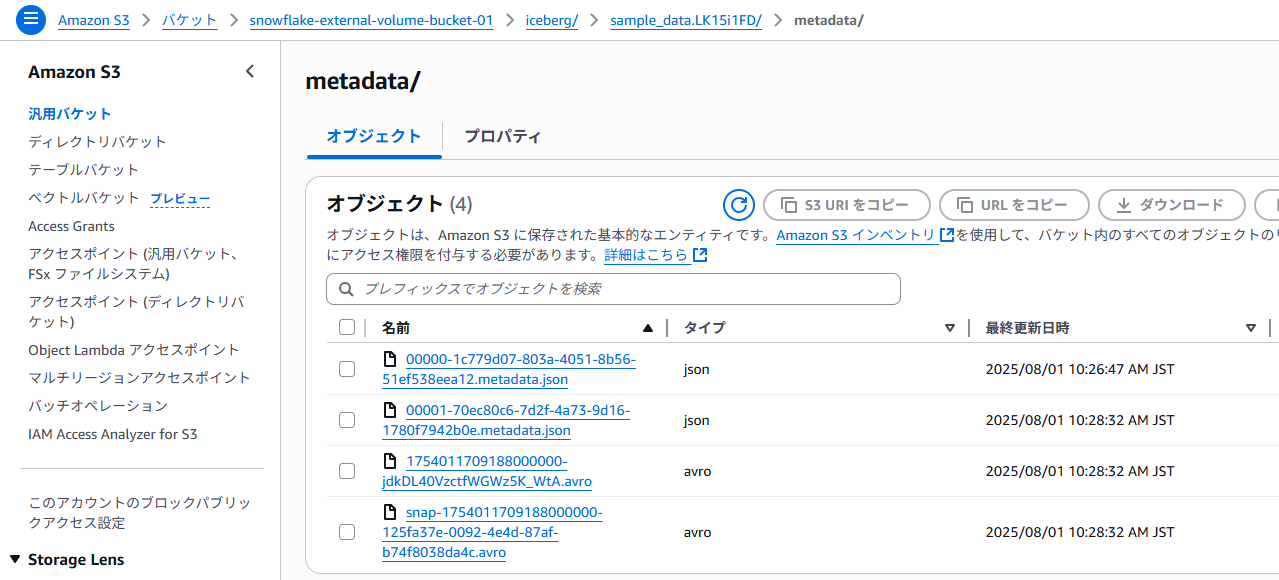
上記SQLを実行すると、S3バケット内に以下のようにデータが作成されます。
Open Catalog作成
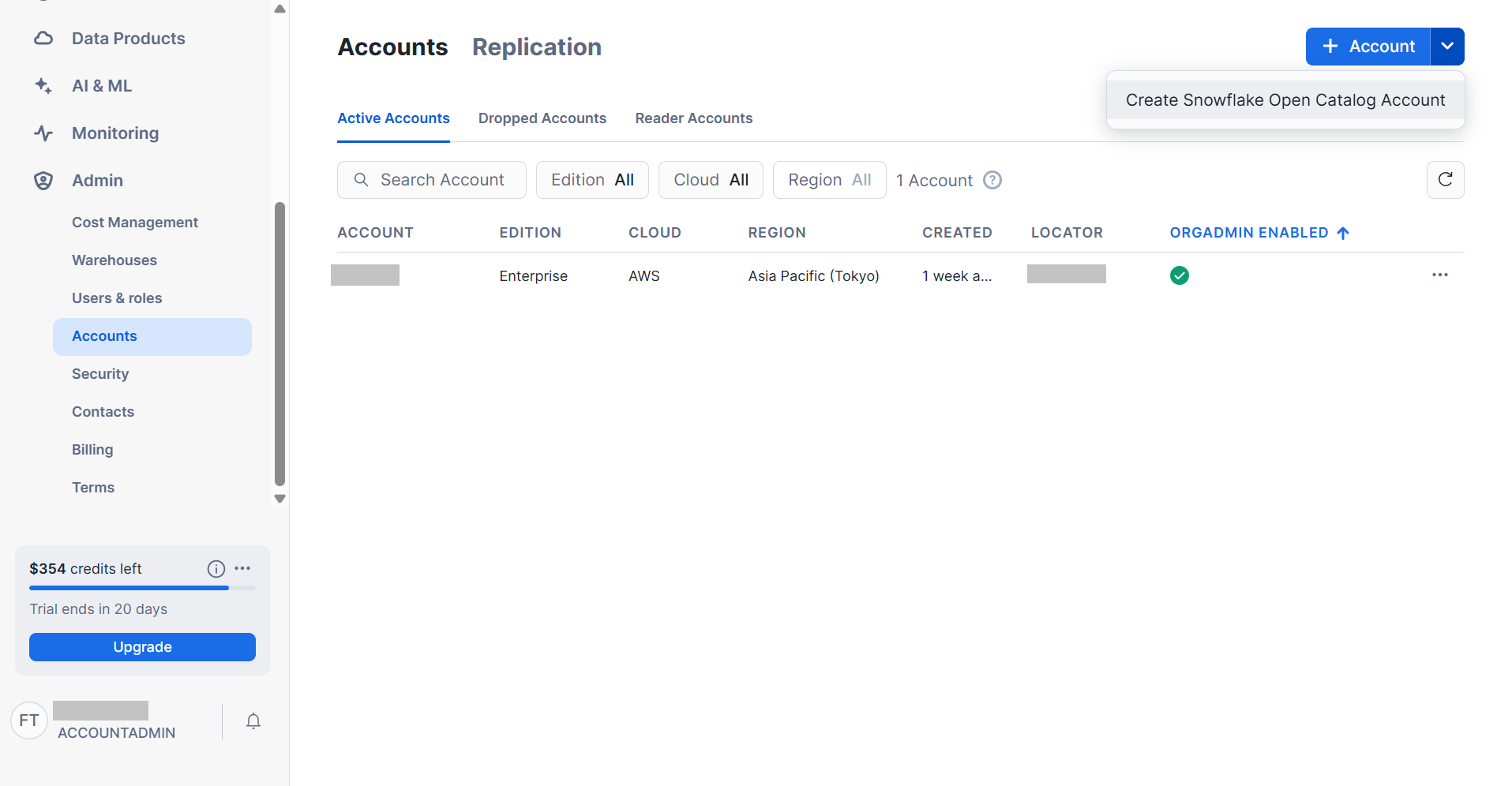
Snowsightで「Admin」→「Accounts」を開き、「Create Snowflake Open Catalog Account」をクリックします。
表示されたダイアログに従い、アカウントの設定を行います。
設定が完了すると、以下のような画面が表示されます。
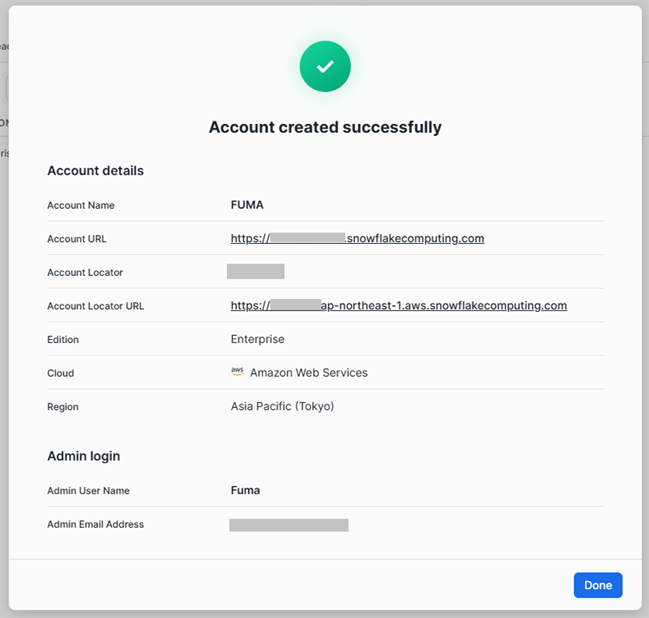
今後 Open Catalog を使用する際に必要となるため、「Account Locator URL」をブラウザにブックマーク登録しておきます。
ログインすると、以下のような画面が表示されます。
コネクション作成
メニューから「Connections」を開き、コネクションを作成します。
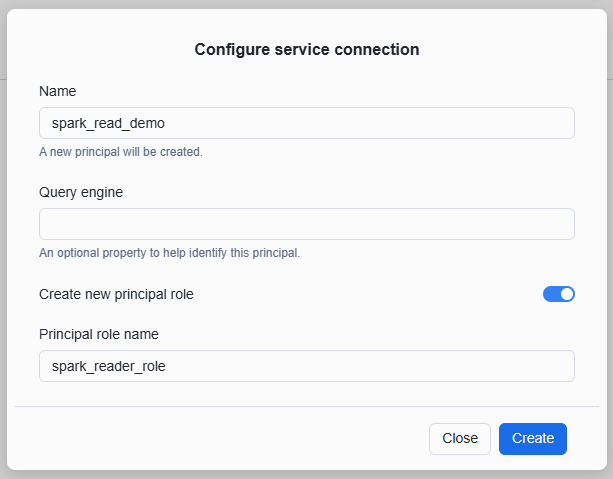
コネクションを作成するとクライアントIDとクライアントシークレットが発行されるため、コピーして控えておきます。
カタログ作成
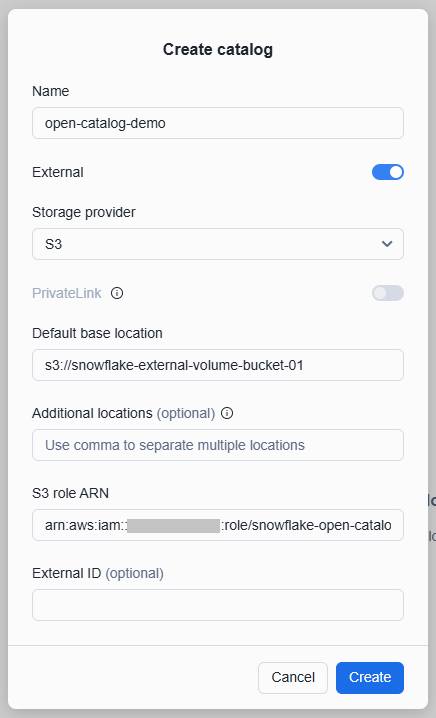
「Catalogs」を開き、カタログを作成します。
Open Catalog がS3にアクセスするためのIAMロールを作成しておき、そのロールARNを「S3 role ARN」に指定する。(ロールにはポリシー「AmazonS3FullAccess」をアタッチしています)
カタログが作成されたら、「Roles」タブでロール(open-catalog-role)を新規作成し、プリンシパルロール(spark-reader-role)に割り当てます。権限は「CATALOGMANAGECONTENT」を設定していますが、実際の環境では最小権限の原則に基づき適切な権限を付与してください。
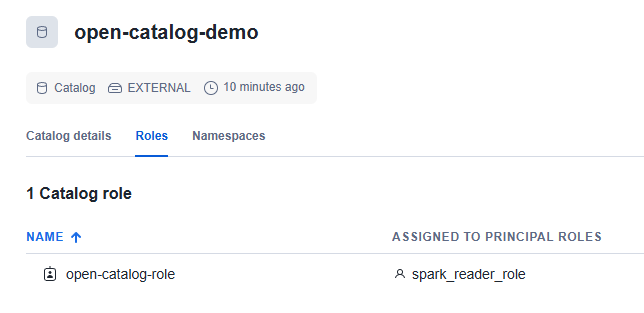
「Catalog details」を開き、「IAM user ARN」と「External ID」の値を記録します。
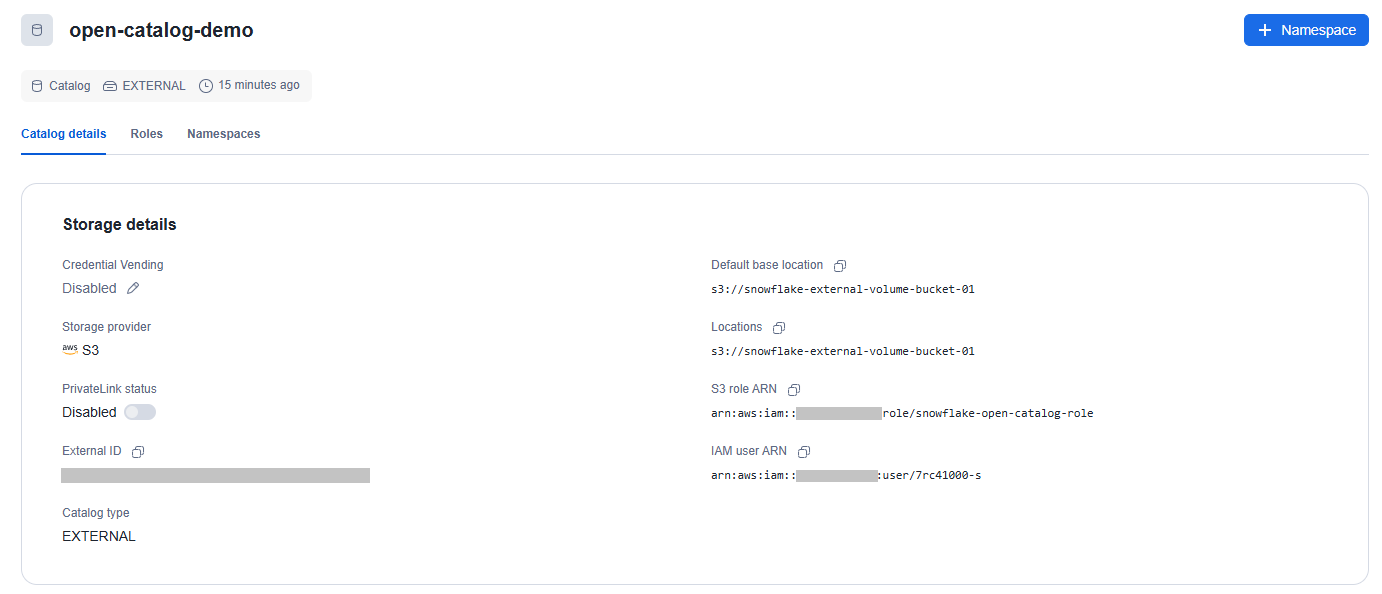
外部ボリューム作成のときと同じように、Open Catalog用IAMロールの信頼ポリシーを以下のように修正します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<IAM_USER_ARN>"
},
"Action": "sts:AssumeRole",
"Condition": {"StringEquals": { "sts:ExternalId": "<EXTERNAL_ID>" }}
}
]
}
カタログ統合作成
Snowflake から Open Catalog を参照するためのカタログ統合を作成します。
CREATE OR REPLACE CATALOG INTEGRATION open_catalog
CATALOG_SOURCE = POLARIS
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'default'
REST_CONFIG = (
CATALOG_URI = 'https://<ORG_NAME>-<OPEN_CATALOG_UESRNAME>.snowflakecomputing.com/polaris/api/catalog'
WAREHOUSE = 'open-catalog-demo'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<CONNECTION_CLIENT_ID>'
OAUTH_CLIENT_SECRET = '<CONNECTION_CLIENT_SECRET>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED = TRUE;
-
ORG_NAME:Snowflake の組織名 -
OPEN_CATALOG_UESRNAME:Open Catalog のユーザ名 -
CONNECTION_CLIENT_ID:「コネクション作成」で取得したクライアントID -
CONNECTION_CLIENT_SECRET:「コネクション作成」で取得したクライアントシークレット
テーブル作成
以下のSQLを実行し、カタログ統合と同期させた状態で再度テーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE sample_data(
id INTEGER,
content STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 's3_iceberg_volume'
BASE_LOCATION = 'sample_data'
CATALOG_SYNC = 'open_catalog';
INSERT INTO sample_data VALUES (1, 'a'), (2, 'b'), (3, 'c');
SQL実行後、Open Catalog にテーブルのデータが同期されていることが確認できます。
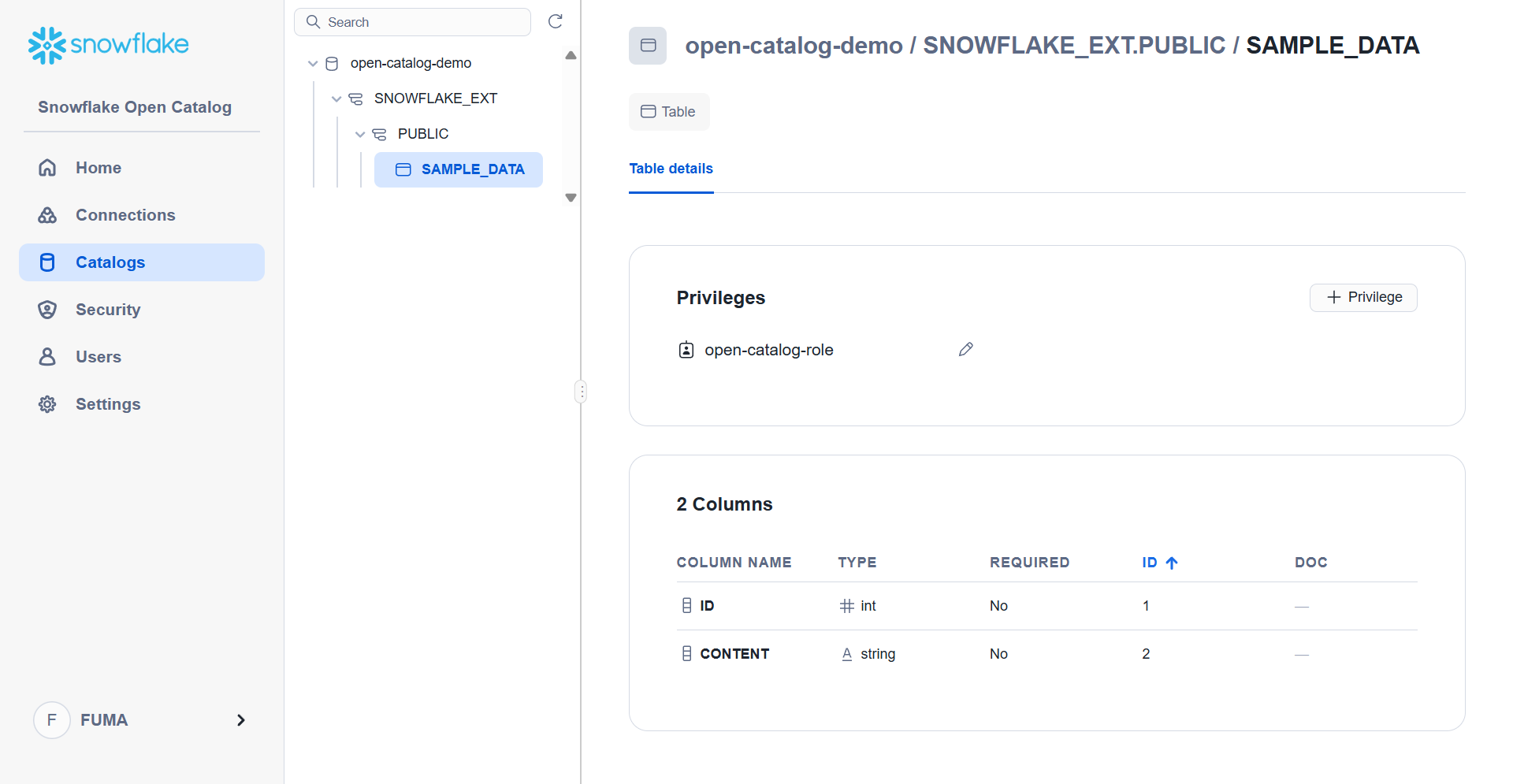
テーブル参照
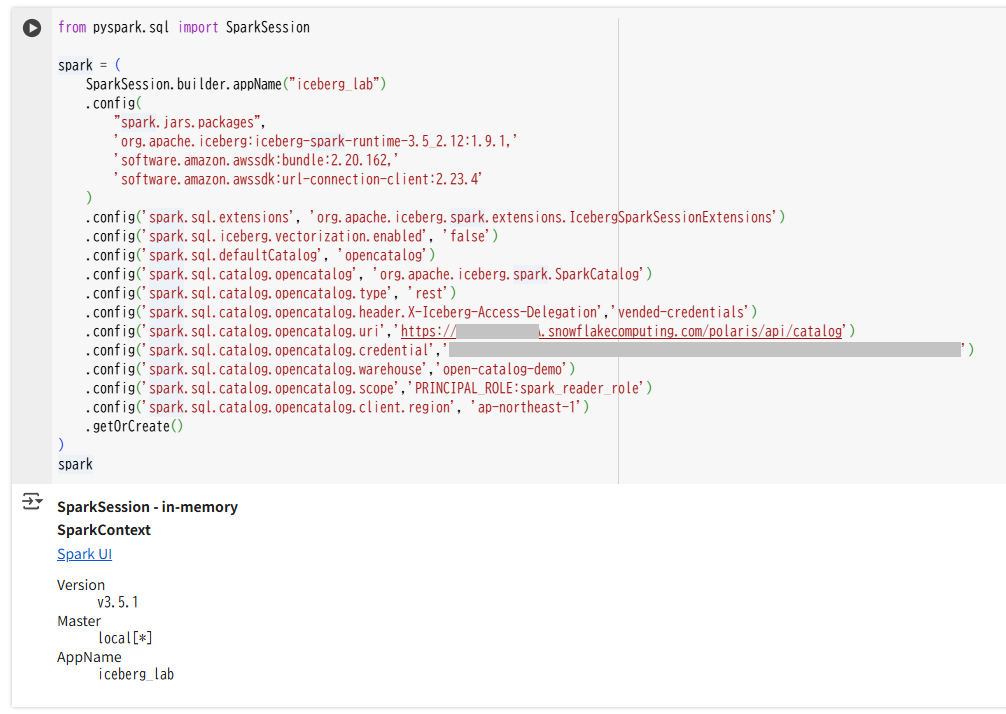
Google Colaboratory でノートブックを開き、以下のコマンドを実行します。
iceberg_labという名前でSparkセッションを作成します。
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("iceberg_lab")
.config(
"spark.jars.packages",
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.1,'
'software.amazon.awssdk:bundle:2.20.162,'
'software.amazon.awssdk:url-connection-client:2.23.4'
)
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
.config('spark.sql.iceberg.vectorization.enabled', 'false')
.config('spark.sql.defaultCatalog', 'opencatalog')
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog')
.config('spark.sql.catalog.opencatalog.type', 'rest')
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials')
.config('spark.sql.catalog.opencatalog.uri','https://<ORG_NAME>-<OPEN_CATALOG_UESRNAME>.snowflakecomputing.com/polaris/api/catalog')
.config('spark.sql.catalog.opencatalog.credential','<CONNECTION_CLIENT_ID>:<CONNECTION_CLIENT_SECRET>')
.config('spark.sql.catalog.opencatalog.warehouse','open-catalog-demo')
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:spark_reader_role')
.config('spark.sql.catalog.opencatalog.client.region', 'ap-northeast-1')
.getOrCreate()
)
spark
カタログの一覧を表示
spark.sql("show catalogs").show()

データベースとテーブルの一覧を表示
spark.sql("show namespaces").show()
spark.sql("use SNOWFLAKE_EXT.PUBLIC")
spark.sql("show tables").show()

テーブルデータ参照
spark.sql("SELECT * FROM SAMPLE_DATA").show()

課金について
Open Catalog の料金は、API呼び出し回数に基づいて計算されます。
※執筆時点で100万回につき0.5クレジット
Snowflake 外部に格納されているIcebergテーブルについては Open Catalog の課金対象とはならず、オブジェクトストレージを利用しているクラウドサービスから直接請求されます。
まとめ
Snowflake Open Catalog はフルマネージドのカタログサービスであり、Snowflake 上のテーブルをIceberg REST互換の様々なクエリエンジンから参照することができます。
本記事ではオブジェクトストレージとしてS3、クエリエンジンとしてSparkを利用しましたが、他の組み合わせでも同様の方法で利用することが可能です。ご利用の要件にあわせて、本記事の内容や公式ドキュメントを参考に設定を行ってみてください。