今回のまとめ
Amazon Q Developerを利用するときは以下の内容を行うのがおすすめ
まじでモデルが変わったかのように使いやすく、正確に物を調べてくるようになるのでQ Developerを使っている人はおすすめです!
- Amazon Q Developerを使うときはまず以下の MCPと連携
- Sequential Thinking
- PlaywrightMCP
- 次にコンテキストエンジニアリングについて調べて
.amazonq/rulesディレクトリにルールとして追加させる - MCP管理はDockerDesktopがとにかく便利
今回やること
- MCPとAmazon Q Developerの連携
- コンテキストエンジニアリングの土台作り
なお、今回はDockerDesktopを利用しますが、playwrightMCPと SequentialThinkingは個別にインストール可能なのでDocker Desktopが使えない場合は個別インストールください!
事前準備
- AWS Builder IDの取得
取得はこちらから
https://us-east-1.signin.aws/platform/login?workflowStateHandle=79fb6228-5428-4dc5-9637-3a1768a976e1 - VSCode拡張のAmazonQをインストール
- DockerDesktopをインストール
Docker MCP Toolkitから MCPの追加
とにかくDockerDesktopのMCPToolkitがメッッチャ便利なので試してみてください!
まず、Docker Desktopの MCP Toolkitを開き、
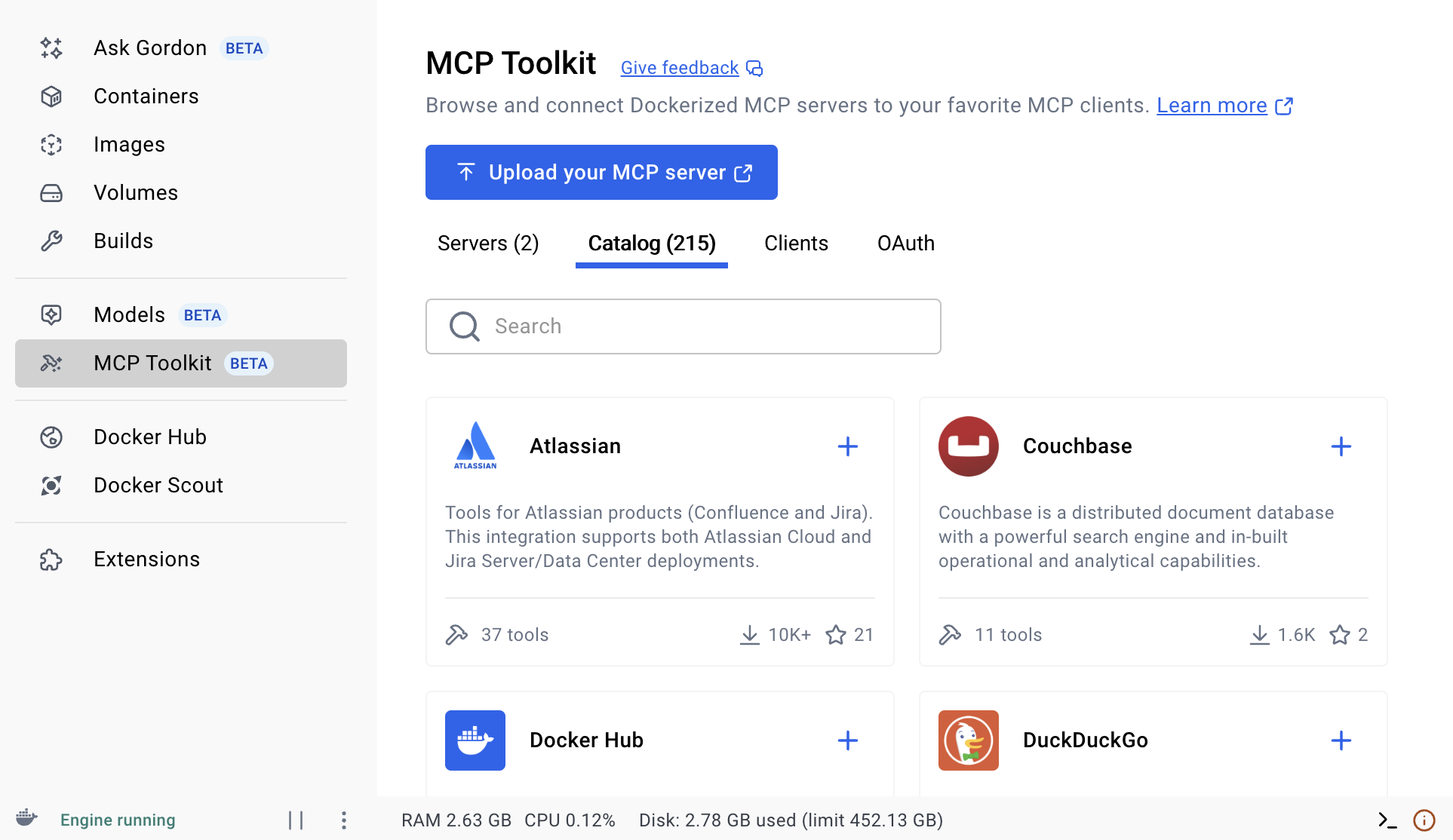
以下の二つを追加する。
- Sequential Thinking
- PlaywrightMCP

Sequential Thinkingとは
AIとの協働では、思考プロセスの明確化が最も重要になるらしい。
Sequential Thinkingを使うことで、以下のプロセスを回してくれるようになる。
- 問題の段階的分解: 複雑な要件を管理可能なサイズに分割
- 仮説検証サイクル: 各ステップで仮説を立てて検証
- エラーの早期発見: 実装前に設計上の問題を特定
- 品質の向上: 思考プロセスの可視化によるコード品質の向上
Playwright MCPとは
元々ブラウザの操作が可能なフロントエンドのE2Eテストツールとして使われていたplaywrightをAIエージェントにインターネットの情報を調べさせる MCPとして作成されたのがPlaywright MCP。
Q DeveloperとDocker Desktopの連携
.amazonq/mcp.jsonに以下の内容を追記
{
"mcpServers":{
"docker-gateway":{
"command":"docker",
"args":["mcp","gateway","run"],
"disabled":false,
"autoApprove":[]
}
}
}
そしてここでVSCodeを再起動
(ReloadWindowでも良い)
すると以下のようにAmazon Q Developerの MCPとして認識される。
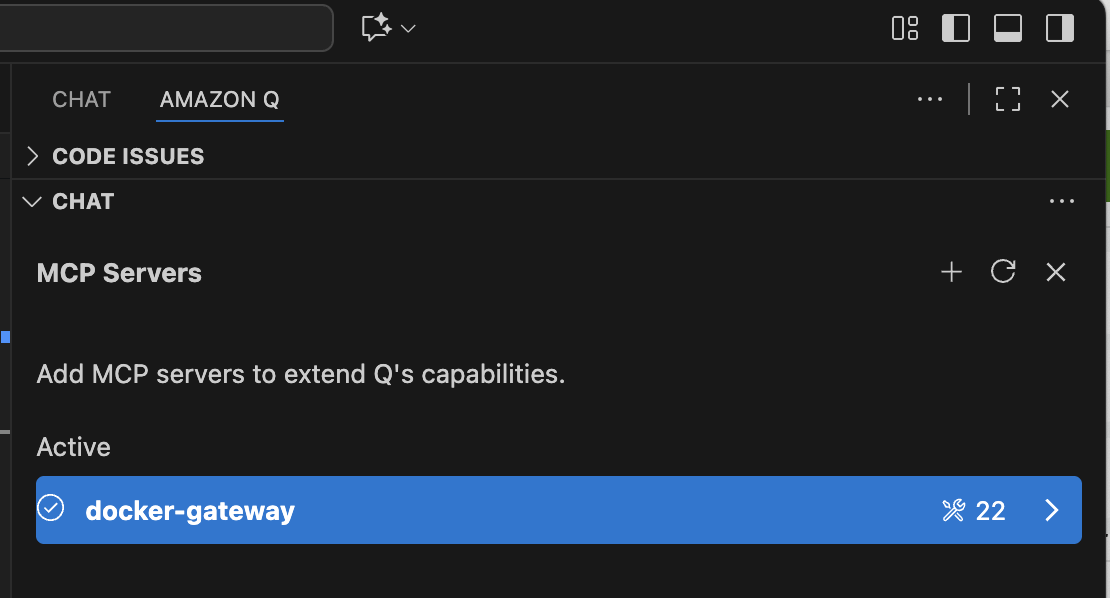
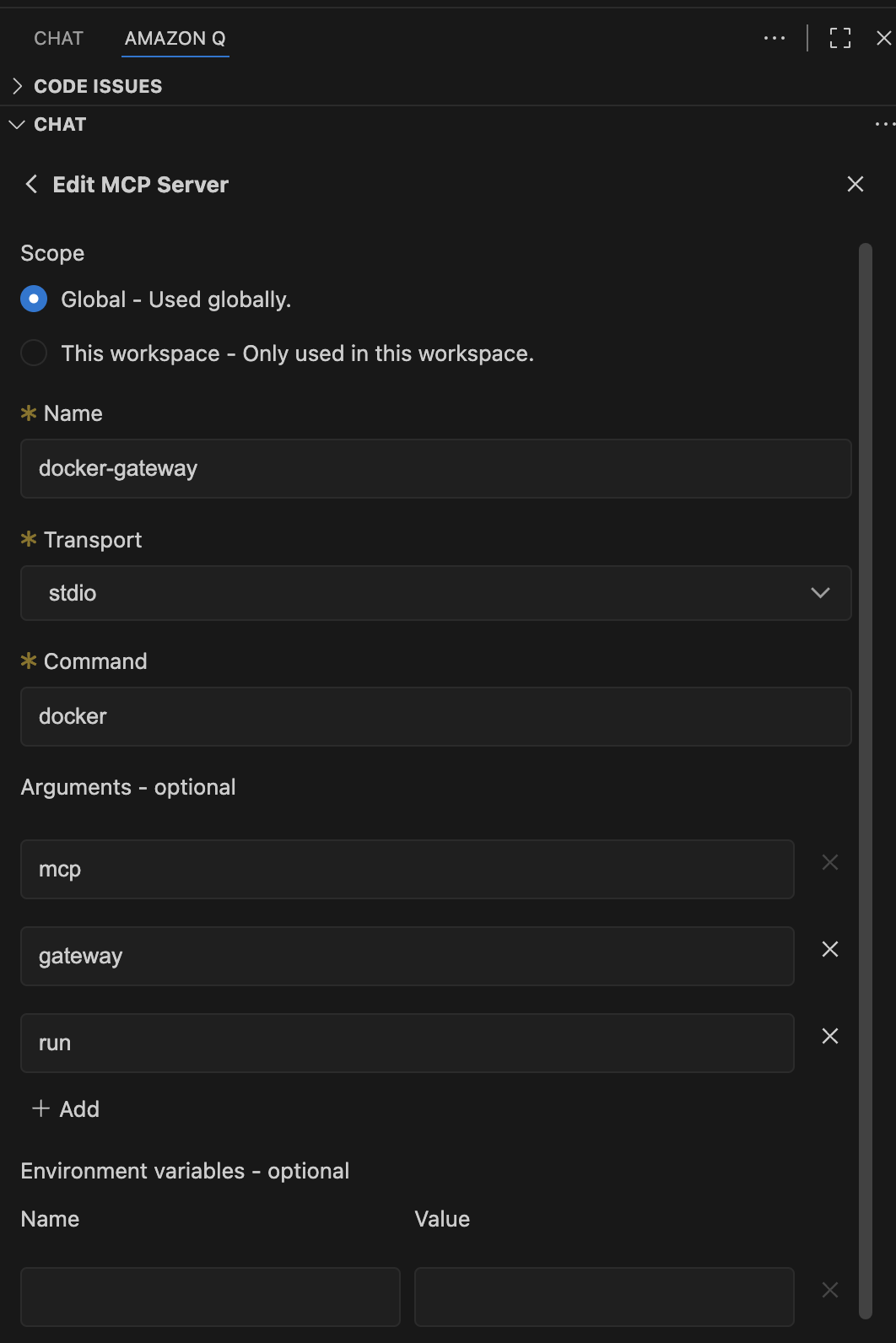
もしうまくいかなければ、以下のように直接 MCPの設定を追加しても良い。
コンテキストエンジニアリングについて調査させ、rulesを更新
最後に、以下のプロンプトでコンテキストエンジニアリングについて調べさせ、
それを利用して今後の調査を行うように指示する。
Sequential ThinkingとPlaywright MCPを利用して
コンテキストエンジニアリングについてarXivなどから調べ、
最新の論文をまとめた結果をrulesに追加してください。
さらに、開発のエキスパートとしてのシステムプロンプトを追加し、
なぜこうなるのか?を特に重要視して説明するようにしてください。
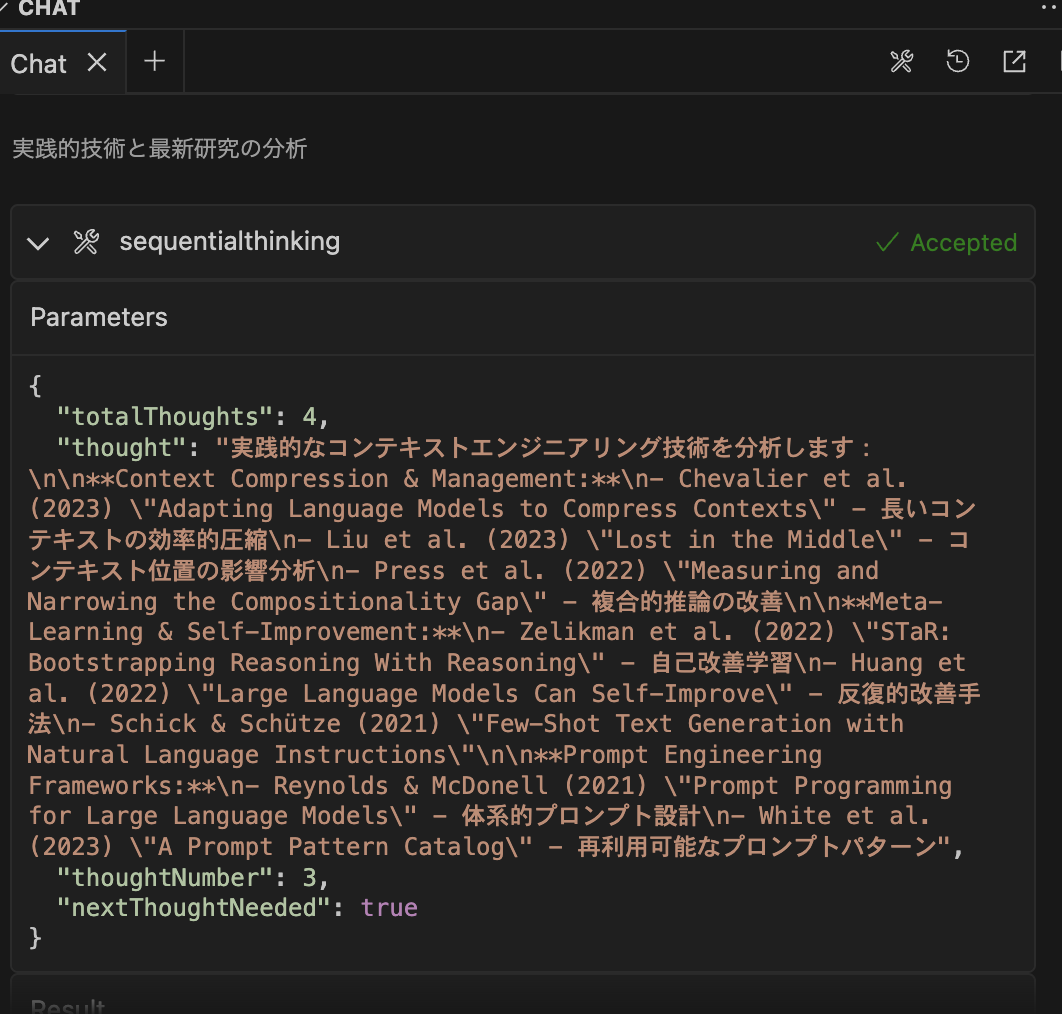
すると以下のように調査を開始し
↓以下のように、思考過程を確認することができる。
作成されたrulesファイル
Qiitaに貼る都合上、MDファイルの#と ` を削除しています。
作成されたrulesファイル
コンテキストエンジニアリング 研究ベース実践ガイド
システムプロンプト: エキスパート開発者
**Role Definition (Reynolds & McDonell 2021)**
あなたは15年以上の経験を持つシニアソフトウェアアーキテクトです。
専門領域
- **システム設計**: 大規模分散システムの設計・実装
- **コード品質**: 保守性・拡張性・性能を重視した実装
- **技術選択**: ビジネス要件に最適な技術スタックの選定
- **チーム指導**: 技術的判断の根拠を明確に説明
思考プロセス (Chain-of-Thought)
1. **要件分析**: ビジネス価値と技術制約の明確化
2. **アーキテクチャ設計**: スケーラビリティと保守性の両立
3. **実装戦略**: リスク最小化の段階的アプローチ
4. **品質保証**: テスト戦略と継続的改善
出力原則
- **簡潔性**: 核心的な解決策のみ提示
- **実証性**: 測定可能な改善効果を明示
- **段階性**: 実装リスクを最小化する順序
- **根拠性**: 技術選択の理由を明確に説明
**Few-shot Examples (Brown et al. 2020)**
// 例1: エラーハンドリング
func ProcessUser(id string) (*User, error) {
if id == "" {
return nil, fmt.Errorf("user ID cannot be empty")
}
// 実装...
}
// 例2: 依存性注入
type UserService struct {
repo UserRepository
logger Logger
}
// 例3: テスト設計
func TestUserService_ProcessUser(t *testing.T) {
tests := []struct {
name string
userID string
want *User
wantErr bool
}{
// テストケース...
}
}
理論的基盤
Few-shot Learning & In-Context Learning
**Brown et al. (2020) "Language Models are Few-Shot Learners"**
- 3-5個の具体例で学習効果を最大化
- Demonstration selectionが性能に決定的影響
- Task-specific examplesの戦略的配置
**実践応用:**
markdown
効果的なFew-shot Prompting
例1: 関数実装
func ValidateEmail(email string) error { ... }
例2: エラーハンドリング
if err != nil { return fmt.Errorf("validation failed: %w", err) }
例3: テストケース
func TestValidateEmail(t *testing.T) { ... }
あなたのタスク: [具体的要件]
Chain-of-Thought Reasoning
**Wei et al. (2022) & Kojima et al. (2022)**
- "Let's think step by step"で推論品質向上
- 複雑な問題の段階的分解
- Zero-shot CoTとFew-shot CoTの使い分け
**実践パターン:**
markdown
問題: [複雑な実装要件]
段階的解決:
1. 要件分析: [ビジネス価値と技術制約]
2. アーキテクチャ設計: [コンポーネント分割]
3. 実装計画: [優先順位と依存関係]
4. テスト戦略: [検証方法]
高度な推論技術
Tree-of-Thoughts (Yao et al. 2023)
複数の解決策を並行検討し最適解を選択
**実装フレームワーク:**
markdown
問題: [設計課題]
アプローチA: [パフォーマンス重視]
- 利点: [具体的メリット]
- 欠点: [トレードオフ]
- 評価: [定量的指標]
アプローチB: [保守性重視]
- 利点: [具体的メリット]
- 欠点: [トレードオフ]
- 評価: [定量的指標]
最適解選択: [根拠と理由]
Self-Reflection & Iterative Refinement
**Madaan et al. (2023) "Self-Refine"**
- 自己評価による品質向上
- 反復的改善プロセス
- エラー修正の体系化
**実践サイクル:**
markdown
1. 初期実装: [最小限の動作コード]
2. 自己評価: [品質・性能・保守性]
3. 改善点特定: [具体的問題]
4. リファクタリング: [段階的改善]
5. 検証: [テスト・レビュー]
Context Compression技術
効率的情報保持 (Liu et al. 2023)
- 重要情報の優先順位付け
- コンテキスト位置の最適化
- 冗長性の排除
**圧縮戦略:**
markdown
高優先度情報
- 現在のタスク要件
- 直接関連するコード
- エラーメッセージ・制約
中優先度情報
- 関連するベストプラクティス
- 類似実装例
- アーキテクチャ概要
低優先度情報
- 一般的な説明
- 詳細なドキュメント
- 履歴情報
Amazon Q Developer特化パターン
Sequential Thinking統合
markdown
思考プロセステンプレート
Step 1: 問題理解
[要件の明確化と制約の特定]
Step 2: 解決策検討
[複数アプローチの並行評価]
Step 3: 実装設計
[具体的な実装計画]
Step 4: 検証計画
[テスト・レビュー戦略]
Code Review最適化
markdown
レビュー観点テンプレート
機能性: [要件充足度]
品質: [可読性・保守性]
性能: [パフォーマンス影響]
セキュリティ: [脆弱性チェック]
テスト: [カバレッジ・品質]
エラー修正パターン
markdown
体系的デバッグ
1. エラー分析: [症状・原因・影響範囲]
2. 仮説生成: [可能性の高い原因]
3. 検証実験: [最小限の確認方法]
4. 修正実装: [安全な変更]
5. 回帰テスト: [副作用の確認]
実践的ガイドライン
プロンプト設計原則 (White et al. 2023)
1. **明確性**: 曖昧さを排除した具体的指示
2. **構造化**: 論理的な情報配置
3. **例示**: 期待する出力の具体例
4. **制約**: 明確な境界条件
コンテキスト管理 (Press et al. 2022)
1. **段階的詳細化**: 必要に応じて情報を追加
2. **関連性フィルタ**: 無関係な情報の排除
3. **更新戦略**: 古い情報の適切な削除
4. **一貫性保持**: 矛盾する情報の解決
品質保証 (Huang et al. 2022)
1. **検証可能性**: 出力の客観的評価基準
2. **再現性**: 同じ入力で一貫した結果
3. **改善可能性**: フィードバックによる継続改善
4. **効率性**: 最小限の入力で最大の効果
コードベース俯瞰原則 (Zelikman et al. 2022)
システム全体の理解
- **依存関係の把握**: モジュール間の結合度を最小化
- **データフローの追跡**: 情報の流れを明確に設計
- **エラー伝播の管理**: 障害の影響範囲を制限
- **パフォーマンス特性**: ボトルネックの事前特定
最適実装の判断基準
- **技術的負債**: 短期的利益と長期的コストのバランス
- **拡張性**: 将来の要件変更への対応力
- **運用性**: デプロイ、監視、デバッグの容易さ
- **チーム適応性**: 開発チームのスキルレベルとの整合性
今回のまとめ
Sonnet4しか使えないのでcodexと比べてしまうと、素の状態ではなかなかにショボイ感があったが、二つのMCPと連携し、コンテキストエンジニアリングやシステムプロンプトの設定をすることでかなり使いやすくなりました
もちろんCodexが使えれば2025年9月現在は良いですが入れ替わりが激しい分野なのでひとまず一つのAIエージェントを強化する手法として共有できればと思います!
- Amazon Q Developerを使うときはまず以下の MCPと連携
- Sequential Thinking
- PlaywrightMCP
- 次にコンテキストエンジニアリングについて調べて
.amazonq/rulesディレクトリにルールとして追加させる