最近、GraphQL APIをインターネット上に晒す上で何を考慮したらいいのだろうか、的なことを考える機会が多く、空いた時間でチマチマと素振りしています。
今日はGraphQLのクライアント - サーバー間に挟むリバプロ的な機能について書いてみようと思います。
やりたいこと
1. 想定しないクエリの排除
例えばECやメディアサイトのような、未ログインでも情報の閲覧が可能なサービスのWeb API層をGrahpQLで実装したとします。ECにしろメディアにしろ、詳細ページでの回遊率を上げるため、詳細同士を関連付けるようなスキーマ設計となるのは自然なことでしょう。
GrahpQLのスキーマ定義で書くと、下記のようなイメージです。
type Product {
id: ID!
name: String!
relatedProducts: [Product]
}
type Query {
product(id: ID!): Product
}
このスキーマが与えられると、GraphQLの文法上、クライアントは好きなだけネストを深くしたクエリを構築できてしまいます。
query {
product(id: "001") {
relatedProducts {
relatedProducts {
relatedProducts {
relatedProducts {
# ...
}
}
}
}
}
}
実際にサーバーサイド(Resolver)をどのように実装するかにもよりますが、そもそも実サービスにおいて、関連商品をこんなに深くネストして取得するシーンなど無いでしょう。
しかし、悪意のある誰かにこのようなクエリを実行されてしまうと、APIやDBのリソースを持っていかれてサービス全体がスローダウンするリスクがあります。
ネストのケースは「resolverでネストするカウントに閾値を設けてエラーにする」などの個別の対策でもよいのですが、より汎用的に考えると**「開発者が承認したクエリのみを処理するようにしたい」**としたいのです。
2. HTTPキャッシュ
例えば、人気商品や人気記事のランキングなどを考えてみましょう。通常、これらの順位はバッチで決定されるケースが多く、リアルタイムで変動するわけではないですし、個々の商品情報にしても同様です。
このような「誰が見ても(しばらくは)同じ内容のデータ」のクエリであれば、わざわざ実APIまで取得させずに、CDN(エッジサーバー)などにキャッシュさせたくなります。サーバーサイドのリソースを無駄に消費しないのもそうですが、CDNでリクエストを折り返すことができれば、その分エンドユーザーから見たパフォーマンスの向上にも繋がります。
GraphQLの文脈でキャッシュといった場合、グラフのノード1つ1つのデータのキャッシュの話もあるのですが(そしてそれはそれで重要なのですが)、今回の記事ではいわゆるHTTPキャッシュに話を絞って進めていきます。
解決案: Persisted Query
通常、GraphQLのクエリは以下のようなJSON bodyを単一のHTTPエンドポイントにPOSTする形式で実装します。
{
variables: {
id: "001",
},
query: `
query FindProduct($id: String!){
product(id: $id) {
name
}
}
`,
}
しかし、このままでは下記が課題となります。
- クライアントがクエリを自由に指定できてしまう。想定しないクエリを防げない
- POSTだとHTTPキャッシュに乗せられない
そこで、次のような方式を考えてみます。
- クライアントの開発完了時に、クエリ本文からhashを計算し、hash値と元となったクエリをサーバーに教えておく
- ランタイムでは計算したハッシュとvariablesを送信
- サーバーは送信されたハッシュからクエリを復元してGraphQLのAPIを実行する。送信されたhashが既知でなければリクエストを棄却する
hash値をもちいることで、第三者が好き勝手なクエリを実行させることを防げるようになります。
また、サーバー側で適切なCache-Controlヘッダを付与すれば、以下のようにHTTPメソッドをGETにすることによって、CDNやブラウザのキャッシュ機構に乗せることもできます。
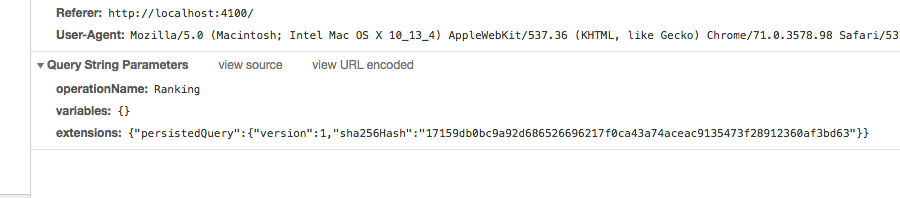
GET /graphql?variables=...&query_hash=17159db0bc
このような方式でGraphQLのクライアント - サーバー通信を行うことをPersisted Queryと呼ぶようなので、この投稿でもこの呼称をもちいることにします1。
実装例
ちょっと手を動かして実装してみました。ちなみに、Apollo EngineやRelay Compilerは使っていません。
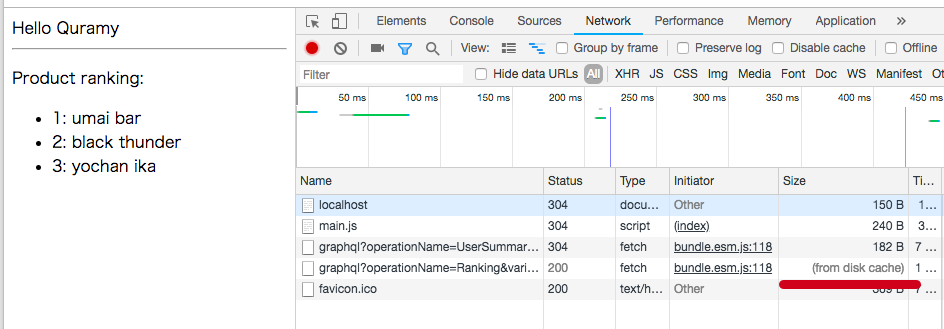
雑なサンプルですが、この画面では以下の2つのGraphQLクエリを投げています。
- 上段部分: ユーザー情報を含むヘッダー相当。no-cache
- 下段部分: 商品ランキング相当。cache-control max-ageあり
また、HTTPリクエストの詳細は以下のようになっており、GraphQLクエリ本体の代わりにsha256のhash値が送信されていることがわかります。
実際のソースコードは https://github.com/Quramy/apollo-sandbox/tree/for-persisted-query-entry にあるので、詳細が気になる方はこちらも参照してみてください。
Persisted Query関連のポイントを掻い摘んで説明すると、下記がポイントとなります。
- apollo-toolingの
apollo client:extractコマンドで、クエリごとにsha256とクエリ本文のペアとなるmanifestファイルを生成 - クライアント側のビルド時に、同様のロジックでクエリ本文からsha256を計算して、apollo-link-persisted-queriesへ引き渡す。またこのlinkの設定でfetchのメソッドをGETになるように変更
- ビルド時のsha256計算は、TypeScriptの
gqlタグに対して動作させるcustom TypeScript transformerをもちいている( https://github.com/Quramy/ts-transform-graphql-tag ) - .graphqlファイル派の人はwebpack loaderを作ればいいんじゃないかな
- 1で作成したmanifestファイルを読み込んで、hashから本文を復帰するリバースプロキシを実装
また、cache control関連でいうと、API本体であるapollo-server側の @cacheControl ディレクティブで、キャッシュコントロール用のextensionをレスポンスボディに付与させておき、リバプロ層でmax-ageのminをとって、HTTPのレスポンスヘッダに付与するようにしています。
export const typeDefs = gql`
type Product {
id: ID!
name: String!
description: String
price: Int!
}
type ProductConnection {
nodes: [Product!]! @cacheControl(maxAge: 300)
totalCount: Int!
}
type User {
id: ID!
name: String!
wishlist: ProductConnection!
}
type Query {
user: User!
ranking: ProductConnection! @cacheControl(maxAge: 300)
product(id: ID!): Product @cacheControl(maxAge: 3600)
}
`;
おわりに
cacheControl部分こそapolloの機能に頼りましたが、Apollo Engineなどのサービスも特に使わずにPersisted QueryによるHTTPキャッシュ機構とクエリのガード機構が実装できました2。
今回はリバプロをexpressで実装していますが、この部分はLambdaやCloud Functionsなど、サービスのインフラに合わせて好きな基盤を選ぶことができますし、CDNについてもURLとCache-Controlを見てくれさえすればよいだけなので、大概の製品と組み合わせられるはずです。
また、URL上にhashだけでなくクエリの名称も残しておくことができるため、nginxやALB層のロギング・モニタリングで、ある程度クエリごとの稼働統計を取ることもできそうです。
一方で、やはりというかなんというかで、ビルド周りに結構な複雑さを押し付けている感はあります。
実際、サンプルの実装中もcustom transformerの中でGraphQLのASTのvisitorを書いたりする羽目になったのですが、この辺の処理をミスるとリバプロがぶっ壊れます。
これはPersisted Queryに限った話では無いのですが、GraphQLに触っていると、どうしても静的解析関連ツールの品質がもたらす影響は大きそうです。
この点については、ツールの選定も含めてもうちょっと深く見ておきたいです。
-
https://blog.apollographql.com/caching-graphql-results-in-your-cdn-54299832b8e2 ↩
-
2019年2月現在、Apollo Engineのproxy関連機能がごっそりとDeprecated扱いにされているため、とてもじゃないですが利用する気にはなれませんでした。 https://www.apollographql.com/docs/references/engine-proxy.html ↩