サンプルデータ作成
irisデータからDataFrameを作成
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)

辞書からDataFrameを作成
import pandas as pd
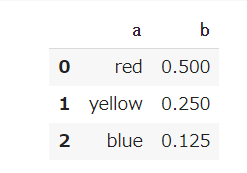
input = {'a': ['red', 'yellow', 'blue'], 'b': [0.5, 0.25, 0.125]}
df = pd.DataFrame(input)
2次元配列(matrix)から
df = pd.DataFrame(matrix, columns=['col1', 'col2'])
データ読み込み
import pandas as pd
# エクセル
df = pd.read_excel('ファイル名.xlsx')
# CSV
df = pd.read_csv('filename.csv', low_memory=False, sep=',', delim_whitespace=False, names=col_names, header=True)
データ確認
文字列操作
# 特定の文字列を含むレコードを抽出
df[df['対象列'].str.contains("文字列")]
統計量
train.describe(include='all')

ペアプロット
import seaborn as sns
sns.pairplot(df, vars=df.columns, hue="target")

nullチェック
df.isnull().sum()
各列のUnique数(Distinct)
df.nunique()

頻度
df.value_counts()

ヒストグラム
df3['列名'].plot.hist(bins=40)

ソート (Sort)
# Index順
df.sort_index()
# 列指定
df.sort_values(by='列名')
データ取得
# インデックスの値取得
df.index.get_level_values('INDEX名').unique()
データ加工
One Hot Encoding
import pandas as pd
import numpy as np
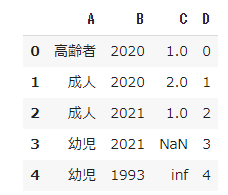
df = pd.DataFrame({'A': ['高齢者', '成人', '成人', "幼児", "幼児"], 'B': [2020,2020,2021,2021,1993],
'C': [1.0, 2.0, 1.0, np.nan, np.inf], "D":[0,1,2,3,4]})
pd.get_dummies(df, columns=["A", "B"])

# OneHot化
df = pd.get_dummies(df, columns=["列名"], drop_first=True) # drop_first=TrueはOneHot化した先頭列を削除
# 条件に当てはまる行のみ取得
df = df[df['列名'] == 値]
値の変更(置換)
# 全体置換
df.replace({'CA': 'California', 24: 100})
# 列指定置換
df.replace({{'列名': 'CA': 'California', 24: 100}})
# 「カレー」というワードを含むnameを1、含まないnameを0にラベルづけ
train['curry'] = train['name'].apply(lambda x : 1 if x.find("カレー") >=0 else 0)
DataFrameの扱い
# Dataframeを縦に結合
pd.concat([df1, df2, df3], axis=0, ignore_index=True)
# Dataframeを横に結合
pd.concat([df1, df2, df3], axis=1)
列の扱い
# 列名変更
df = df.rename(columns={'変更前':'変更後'})
# 列追加
df = df.assign('列名'='値')
# 列削除
df = df.drop('列名', axis=1)
# 列の順序入れ替え
df = df.reindex(columns=['col1', 'col2', ...])
NULL(NaN)の扱い
# 一つでもNULLを含む行を削除
df = df.dropna(how='any')
# NULLを置換
df = df.fillna({'列名': 値})
One Hot Decode
animals = pd.DataFrame({"monkey":[0,1,0,0,0],"rabbit":[1,0,0,0,0],"fox":[0,0,1,0,0]})

def get_animal(row):
for c in animals.columns:
if row[c]==1:
return c
animals.apply(get_animal, axis=1)

出力
# csv出力
df.to_csv('ファイル名.csv', index=False)
参考
- https://qiita.com/ao_log/items/fe9bd42fd249c2a7ee7a
- https://qiita.com/chusan/items/d7b210243f3b646375ba
- https://stackoverflow.com/questions/38334296/reversing-one-hot-encoding-in-pandas/38334528
- One-HotエンコーディングならPandasのget_dummiesを使おう | Shikoan's ML Blog
- https://www.renom.jp/ja/notebooks/tutorial/preprocessing/category_encoding/notebook.html
- https://qiita.com/uratatsu/items/8bedbf91e22f90b6e64b