外部と通信せずに使えるローカルAI「LM Studio」に、外部に送信したくない資料を読み込ませて回答できるようにした。
良い感じで動くようになったが、コマンドプロンプト上で動くので目に優しくない。
それで、LM Studio + RAGの今の環境に、さらにOpenWebUI を加えてブラウザ上で使えるようにした。
使用イメージは以下。

基本方針(仕様)
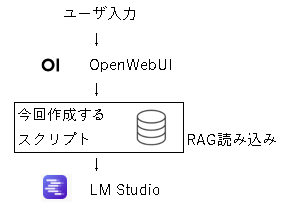
作成するスクリプトは生成AIサーバ(Webサーバ)として起動する。
OpenWebUIからのリクエストを受け取り、RAGと組み合わせてLM Studioに送信する。
前提
- インデックスが作成済み
以下の記事のスクリプトで資料をインデックス化(RAG生成)しておく。
- fastapi と ubicorn を使用するので未インストールであればインストールしておく。
pip install fastapi uvicorn
- OpenWebUIを使用するので未インストールであればインストールしておく。(以下の記事を参照)
作成したスクリプト
import os
import time
import json
from typing import List, Generator
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# =====================
# 設定
# =====================
CHROMA_ROOT = "./chroma"
LM_STUDIO_URL = "http://localhost:1234/v1"
CONFIDENCE_THRESHOLD = 1.3
MAX_CONTEXT_CHARS = 4096
# =====================
# FastAPI
# =====================
app = FastAPI(title="RAG API (Streaming)")
# =====================
# Embedding
# =====================
embeddings = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-base",
model_kwargs={"device": "cuda"}
)
# =====================
# キャッシュ
# =====================
_chroma_cache = {}
_mode_state = {}
_llm_cache = {}
def get_chroma(index: str) -> Chroma:
if index in _chroma_cache:
return _chroma_cache[index]
path = os.path.join(CHROMA_ROOT, index)
if not os.path.isdir(path):
raise ValueError(f"Chroma not found: {index}")
vs = Chroma(
persist_directory=path,
embedding_function=embeddings
)
_chroma_cache[index] = vs
return vs
def get_mode(index: str) -> str:
return _mode_state.get(index, "mode1")
def set_mode(index: str, mode: str):
_mode_state[index] = mode
def get_llm(mode: str) -> ChatOpenAI:
if mode in _llm_cache:
return _llm_cache[mode]
temperature = 0.1 if mode == "mode1" else 0.6
llm = ChatOpenAI(
base_url=LM_STUDIO_URL,
api_key="lm-studio",
temperature=temperature,
streaming=True
)
_llm_cache[mode] = llm
return llm
def build_prompt(mode: str):
if mode == "mode2":
system = (
"以下の資料を主な根拠として、日本語で回答してください。\n\n"
"【思考モード】\n"
"- 資料に書かれている事実を出発点にしてください\n"
"- 論理的な推論・整理・仮説を行って構いません\n"
"- 推論や仮説である場合は、その旨が分かる表現を使ってください\n\n"
"回答では、使用した資料の文を引用し、必ずファイル名と番号を明示してください。\n\n"
"{context}"
)
else:
system = (
"以下の資料を根拠として日本語で回答してください。\n\n"
"【厳密モード】\n"
"- 資料に書かれている内容のみを答えてください\n"
"- 推測、補完、一般論は禁止です\n"
"- 資料にない場合は必ず「分かりません」と答えてください\n\n"
"回答では、使用した資料の文をそのまま抜き出し、\n"
"**必ずファイル名**と番号を明示してください。\n\n"
"{context}"
)
return ChatPromptTemplate.from_messages([
("system", system),
("human", "{question}")
])
def retrieve_docs(vs: Chroma, query: str, k: int = 5):
results = vs.similarity_search_with_score(query, k=k)
if not results:
return [], None
best = results[0][1]
docs = [
doc for doc, score in results
if score <= best + 0.15
]
return docs, best
def docs_to_context(docs):
parts = []
for i, d in enumerate(docs, 1):
src = d.metadata.get("source", "unknown")
parts.append(f"[{i}] {src}")
text = d.page_content.strip()
if len(text) > MAX_CONTEXT_CHARS:
text = text[:MAX_CONTEXT_CHARS]
parts.append(text)
return "\n\n".join(parts)
# =====================
# OpenAI互換 Request
# =====================
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
model: str
messages: List[Message]
# =====================
# /v1/models
# =====================
@app.get("/v1/models")
def list_models():
data = []
if os.path.isdir(CHROMA_ROOT):
for name in os.listdir(CHROMA_ROOT):
if os.path.isdir(os.path.join(CHROMA_ROOT, name)):
data.append({"id": f"rag-{name}", "object": "model"})
return {"object": "list", "data": data}
# =====================
# /v1/chat/completions(Streaming)
# =====================
@app.post("/v1/chat/completions")
def chat(req: ChatRequest):
model_name = req.model
index = model_name.replace("rag-", "")
user_msg = next(m.content for m in reversed(req.messages) if m.role == "user").strip()
# ---- モード切替 ----
if user_msg == "mode1":
set_mode(index, "mode1")
return _single_response(req, "モード変更: 厳密モード")
if user_msg == "mode2":
set_mode(index, "mode2")
return _single_response(req, "モード変更: 思考モード")
# ---- ストリーミング応答 ----
return StreamingResponse(
stream_answer(req, index, user_msg),
media_type="text/event-stream"
)
def stream_answer(req: ChatRequest, index: str, question: str) -> Generator[str, None, None]:
mode = get_mode(index)
vs = get_chroma(index)
docs, best_score = retrieve_docs(vs, "query: " + question, k=5)
if not docs or best_score is None:
yield _sse_chunk("分かりません")
yield _sse_done()
return
context = docs_to_context(docs)
prompt = build_prompt(mode)
llm = get_llm(mode)
chain = prompt | llm
# ---- トークン逐次送信 ----
for chunk in chain.stream({
"context": context,
"question": question
}):
if chunk.content:
yield _sse_chunk(chunk.content)
# ---- 末尾情報 ----
confidence = max(0.0, min(1.0, 1.0 - best_score / CONFIDENCE_THRESHOLD))
confidence_pct = int(confidence * 100)
mode_label = "厳密" if mode == "mode1" else "思考"
sources = []
seen = set()
for d in docs:
src = d.metadata.get("source")
if src and src not in seen:
seen.add(src)
sources.append(src)
tail = (
f"\n\n信頼度: {confidence_pct}%\n"
f"回答モード: {mode_label}\n\n"
"参考資料:\n"
+ "\n".join(f"- {s}" for s in sources)
)
yield _sse_chunk(tail)
yield _sse_done()
# =====================
# SSE helpers
# =====================
def _sse_chunk(text: str) -> str:
payload = {
"choices": [
{
"delta": {
"content": text
}
}
]
}
return f"data: {json.dumps(payload, ensure_ascii=False)}\n\n"
def _sse_done() -> str:
payload = {
"choices": [
{
"delta": {},
"finish_reason": "stop"
}
]
}
return f"data: {json.dumps(payload)}\n\ndata: [DONE]\n\n"
def _single_response(req, content: str):
return {
"id": "rag-chat",
"object": "chat.completion",
"created": int(time.time()),
"model": req.model,
"choices": [{
"index": 0,
"message": {"role": "assistant", "content": content},
"finish_reason": "stop"
}]
}
スクリプトの使い方
以下のように呼び出すと、待機状態になる。
uvicorn rag_api:app --host <待ち受けるIPアドレス> --port <ポート番号>
例えば以下のような感じ。
uvicorn rag_api:app --host 0.0.0.0 --port 8000
引数は以下の2つ。
-
待ち受けるIPアドレス
特に制限をしないなら「0.0.0.0」で良い -
ポート番号
OpenWebUIからの通信を受け付けるポート番号を決める。
もちろん、OpenWebUIのポート番号、LM Studioのポート番号 とは異なるものにする。
起動すると以下のように「running」と表示されれば準備完了だ。

OpenWebUIの設定
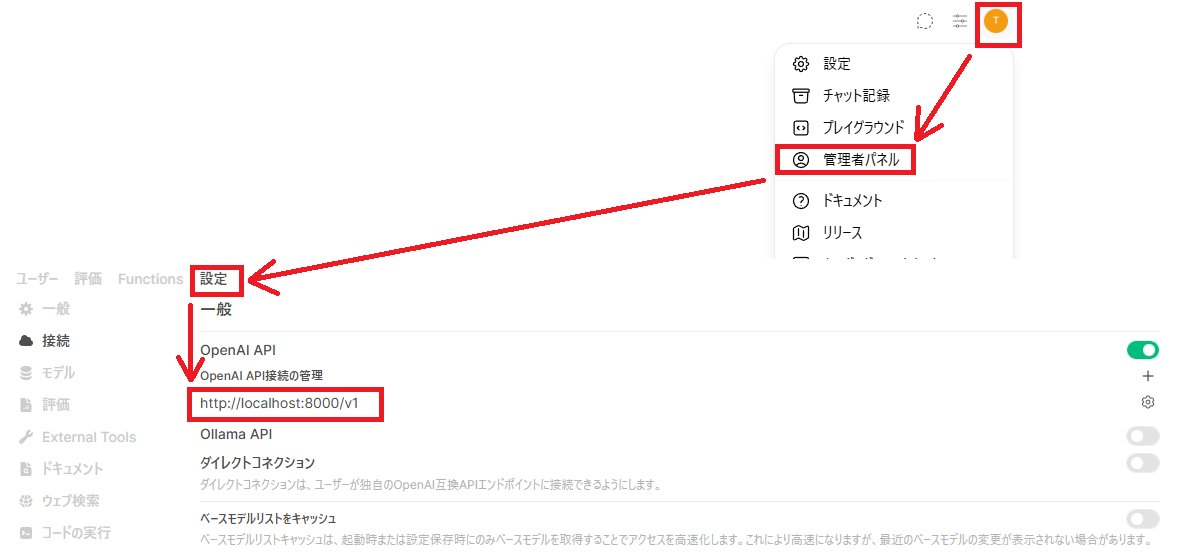
無事に起動ができたら、OpenWebUIの方の設定を変えて、作成したスクリプトに接続するよう設定する。
OpenWebUIを起動したら、右上のアイコンから「管理者パネル」を選ぶ。
「設定」の中に「OpenAI API接続の管理」があるので以下のように書き換える。
http://[IPアドレス]:[ポート番号]/v1
例えばスクリプトに 0.0.0.0 と 8000 を指定して起動するなら、以下のように設定する。
http://localhost:8000/v1
使い方
OpenWebUIから利用できる。
まず、新しい会話を開始したら、モデルを選ぶ。
ここに「rag-XXX」という名前で、自分が作成したchroma名が出てくるので使いたいデータベースを選べる。
初期状態は厳密モード(mode1)で起動するので、会話欄に「mode2」と入力してEnterを押すと思考モードに切り替えできる。

mode1やmode2の意味は前の記事で解説していますので、ご覧ください。
https://qiita.com/Qapla/items/6927220bad9e9e374046
スクリプトの調整
前の記事で作成した「ask_documents.py」の仕様を引き継いでいるので、前の記事をご覧ください。
動作させた様子
こんな感じで動く。
OpenWebUIにエラー表示が出たら
Response payload is not completed: <TransferEncodingError: 400, message='Not enough data to satisfy transfer length header.'> と表示されたら
- 原因1:LM Studioでモデルをロードしていない/2つ以上のモデルをロードしている。
LM Studioのログに以下が出ていれば、ロードしていない(0個)
No models loaded. Please load a model in the developer page or use the 'lms load' command.
LM Studioのログに以下が出ていれば、2つ以上のモデルをロードしている。
Invalid model identifier "gpt-3.5-turbo". Please specify a valid downloaded model
特定のモデルを常に読み込みたいなら、スクリプトの中に「llm = ChatOpenAI」で始まる行があるので、その引数に「model="openai/gpt-oss-20b",」という風にモデル名を追加しても良い。
- 原因2:回答が長すぎてあふれている
LM Studioに以下のログが出る。
Reached context length of 4096 tokens, but this model does not currently support mid-generation context overflow because
LM Studio側の設定で使用するモデルの「コンテキスト長」を増やす。設定を変えたら、モデルを再ロードすること
- 原因3:LM Studioを起動していない/サーバがONになっていない。
rag_api に以下のログが出る
httpcore.ConnectError: [WinError 10061] 対象のコンピューターによって拒否されたため、接続できませんでした。
openai.APIConnectionError: Connection error.
404: Model not found と表示されたら
- 原因:rag_api が起動していない/ポート番号が合っていない
OpenWebUIに以下のログが出る
ERROR | open_webui.routers.openai:send_get_request:83 - Connection error: Cannot connect to host localhost:8000