前編(以下の記事)の続きです
基本方針(仕様)

1.読み込める資料はテキストファイルかPDFファイルとする。
2.事前にテキストファイルやPDFを読み込んで、データベースを作っておく(前の記事:前編)
3.LM Studioに問い合わせてデータベースから回答させる(この記事:後編)
作成したスクリプト
import os
import sys
import time
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# =====================
# 設定
# =====================
CHROMA_ROOT = "./chroma"
LM_STUDIO_URL = "http://localhost:1234/v1"
CONFIDENCE_THRESHOLD = 1.3
# =====================
# Embedding
# =====================
def get_embeddings():
return HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-base",
model_kwargs={"device": "cuda"}
)
# =====================
# LLM(mode別)
# =====================
def get_llm(mode: str):
temperature = 0.1 if mode == "mode1" else 0.6
return ChatOpenAI(
base_url=LM_STUDIO_URL,
api_key="lm-studio",
temperature=temperature
)
# =====================
# 検索
# =====================
def retrieve_docs(vs: Chroma, query: str, k: int = 5):
results = vs.similarity_search_with_score(query, k=k)
if not results:
return [], None
best_score = results[0][1]
docs = [
doc for doc, score in results
if score <= best_score + 0.15
]
return docs, best_score
# =====================
# context 整形
# =====================
def docs_to_context(docs):
blocks = []
for i, d in enumerate(docs, 1):
src = d.metadata.get("source", "unknown")
page = d.metadata.get("page")
header = f"[{i}] {src}"
if page:
header += f" p.{page}"
blocks.append(header)
blocks.append(d.page_content.strip())
return "\n\n".join(blocks)
# =====================
# プロンプト生成
# =====================
def build_prompt(mode: str):
if mode == "mode2":
system_prompt = (
"以下の資料を主な根拠として、日本語で回答してください。\n\n"
"【思考モード】\n"
"- 資料に書かれている事実を出発点にしてください\n"
"- 論理的な推論・整理・仮説を行って構いません\n"
"- 推論や仮説である場合は、その旨が分かる表現を使ってください\n\n"
"回答では、使用した資料の文を引用し、必ずファイル名と番号を明示してください。\n\n"
"{context}"
)
else:
system_prompt = (
"以下の資料を根拠として日本語で回答してください。\n\n"
"【厳密モード】\n"
"- 資料に書かれている内容のみを答えてください\n"
"- 推測、補完、一般論は禁止です\n"
"- 資料にない場合は必ず「分かりません」と答えてください\n\n"
"回答では、使用した資料の文をそのまま抜き出し、\n"
"必ずファイル名と番号を明示してください。\n\n"
"{context}"
)
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{question}")
])
# =====================
# main
# =====================
def main():
if len(sys.argv) != 2:
print("使い方: python ask_documents.py <chroma名>")
print("例: python ask_documents.py work")
return
chroma_name = sys.argv[1]
chroma_dir = os.path.join(CHROMA_ROOT, chroma_name)
if not os.path.isdir(chroma_dir):
print(f"Chroma が見つかりません: {chroma_dir}")
return
start_time = time.time()
embeddings = get_embeddings()
vs = Chroma(
persist_directory=chroma_dir,
embedding_function=embeddings
)
# 初期モード
mode = "mode1"
elapsed = time.time() - start_time
print(f"準備完了(起動時間: {elapsed:.2f} 秒)")
print(f"使用中のインデックス: {chroma_name}")
print("現在のモード: 厳密モード(mode1)")
print("mode1 / mode2 を入力して切り替え。exit で終了")
while True:
user_input = input("\n入力: ").strip()
if user_input.lower() in ("exit", "quit"):
break
# ---- モード切替 ----
if user_input == "mode1":
mode = "mode1"
print("モード変更: 厳密モード")
continue
if user_input == "mode2":
mode = "mode2"
print("モード変更: 思考モード")
continue
# ---- 質問 ----
if not user_input:
continue
q = user_input
docs, best_score = retrieve_docs(
vs,
"query: " + q,
k=5
)
if not docs or best_score is None:
print("\n回答: 分かりません")
continue
confidence = max(
0.0,
min(1.0, 1.0 - best_score / CONFIDENCE_THRESHOLD)
)
confidence_pct = int(confidence * 100)
context_text = docs_to_context(docs)
prompt = build_prompt(mode)
llm = get_llm(mode)
chain = prompt | llm
answer = chain.invoke({
"context": context_text,
"question": q
})
print(f"\n回答({'厳密' if mode == 'mode1' else '思考'}モード):\n")
print(answer.content)
print(f"\n信頼度: {confidence_pct}%")
print("\n参考にした資料:")
seen = set()
for d in docs:
src = d.metadata.get("source")
if src and src not in seen:
seen.add(src)
print(f"- {src}")
if __name__ == "__main__":
main()
スクリプトの使い方
以下のように呼び出す
python ask_documents.py <chroma名>
- chroma名(任意の名称)
前の記事の範囲でデータベースを作る時に指定した名前。
例えば「仕事用」「趣味用」など、作成したデータベースに付けた名前を指定する。
例えば以下のように「work」と名前を付けて作成したデータベースを使うなら、
python index_documents.py C:\pdf_dir\ work
python ask_documents.py work
という風に名称を指定する。
スクリプトの実行結果
起動すると以下のような画面になる
準備完了(起動時間: X.XX 秒)
使用中のインデックス: 仕事用
現在のモード: 厳密モード(mode1)
mode1 / mode2 を入力して切り替え。exit で終了
入力:
ちょっと工夫したのが「mode1」と「mode2」の切り替え機能。
入力に「mode1」と入力してEnterを押すと、生成AIに「資料にないことは答えるな。わからないならそう言え」という指示を出す&temperatureを「0.1」にする。
つまり「mode1」を指定すると、生成AIに思考を禁止して厳密な回答を要求できる。
「mode2」と指定すると、生成AIに「資料に基づいて推論しろ。ただし、推論や仮説である場合はそう言え」という指示を出す&temperatureを「0.6」にする。
つまり「mode2」を指定すると、生成AIがある程度 思考して回答することが許可される。
生成AIを検索ツールとして使うなら「mode1」、資料を元に考えて欲しいなら「mode2」と指定することで切り替えできる。
スクリプトの調整
上記のスクリプトは無調整で動くはずだが、環境によっては以下を変える。
LM Studioのポート番号
15行目:LM_STUDIO_URL = "http://localhost:1234/v1"
信用度の計算
16行目:CONFIDENCE_THRESHOLD = 1.3
基本的に変えなくて良い(はず)
Chroma(embedding)の距離スコアは小さい方が良い。大きい方が関連性が低い。1.3くらいで計算することで、どのくらい信用できるか信用度を計算しています。
ちなみに、画面に表示される信用度とはLM Studioで動いている生成AIが考える信用度ではなく、multilingual-e5-base が検索したときの該当率(資料にどれほど基づいているか)の値です。
Text Embedding用のモデル指定
24行目:model_name="intfloat/multilingual-e5-base",
基本的に変えなくて大丈夫です。ただし、前の記事(以下)で使用しているスクリプトにも同じ記載があります。
もしモデルを変えたいのであれば、インデックス作成の方のスクリプトもそれに合わせて変えてください。
また、モデルを変えたら、インデックスも最初から作り直す必要があります。
CPU利用/GPU利用
25行目:model_kwargs={"device": "cuda"}
ここの「cuda」を「cpu」に変えると、GPUを使わなくなる。
前編と同じ内容なので、気になる方は前編の記事をご覧ください。
https://qiita.com/drafts/c66d5151eb14878dd2a9
プロンプト調整
77~104行目:プロンプト
この部分で「mode1」と「mode2」のプロンプトを定義しています。
必要に応じて変えることができます。
ここを変えるなら、33行目にある temperature も変えると良いかもしれません。
temperatureは値を大きくすると自由度が上がる(生成AIの発想、推論の割合が大きくなる)
0.1は厳しいので、同じ質問には同じ回答が出やすい
0.6はやや緩いので、同じ質問をしても回答に幅が出る。
ちなみにLM StudioをGUIで使う時のtemperatureは「0.8」が初期値になっている。
参考にする資料数
165行目:k=5
この数字が生成AIに参照させる資料の最大数です。
今は該当率が高いと思われる「上位5つのファイル」を参照するようになっています。
スクリプトを実行して生成AIの回答を見ると、回答の末尾に「参考にした資料」が出ますが、その数が5つになるのはこの設定が原因です。
小さい値にすると、生成AIに渡すファイル数が少なくなります。
つまり、信頼性の高い(multilingual-e5-base が検索したときに該当すると考えた距離が近い)少数のファイルだけを参照するようになります。
自分がした質問に対する回答の「参考にした資料」が適切かどうかを見て、調整できます。
もしmultilingual-e5-baseが、狙ったファイルを見つけられていない場合は値を大きく。
狙ったファイルを見つけているものの、無関係なファイルも見つけている場合は値を小さく。
と変更することで、自分の好みに合わせられます。
使用例
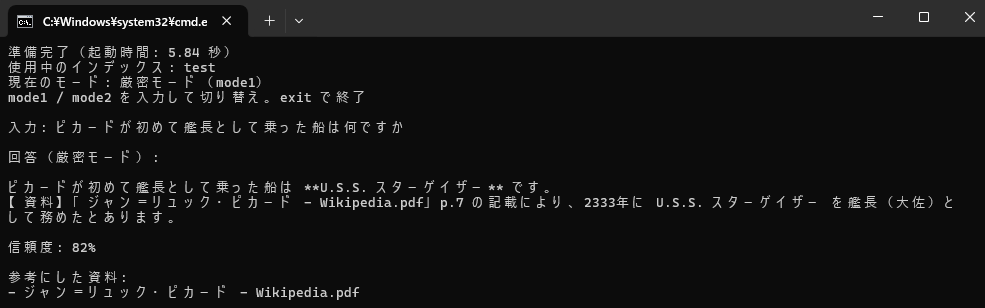
動作確認のためにWikipediaの1ページをPDFにして読み込ませてみた。
読み込ませたのは以下のページ
https://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A3%E3%83%B3%EF%BC%9D%E3%83%AA%E3%83%A5%E3%83%83%E3%82%AF%E3%83%BB%E3%83%94%E3%82%AB%E3%83%BC%E3%83%89
読み込ませたデータからちゃんと回答できている。
追記:GUI化しました
コマンドプロンプトでの動作では見辛いので、OpenWebUIでGUI化しました。
詳細は続く記事をご覧ください。