はじめに
元論文:https://arxiv.org/pdf/1803.01534v4.pdf
論文名:’Path Aggregation Network for Instance Segmentation’
著者:Shu Liu,Lu Qi,Haifang Qin,Jianping Shi,Jiaya Jia
公開日:18 Sep 2018
PANetとは
Mask R-CNNを改良した、物体検出・セグメンテーションの新たな手法
モチベーション
Mask R-CNNの情報伝播の流れを改善→物体検出・セグメンテーションの精度向上
速習:物体検出
参考:
https://qiita.com/arutema47/items/8ff629a1516f7fd485f9(R-CNNについて)
https://qiita.com/tokkuman/items/3fabd04a1a524843bea5(モデルの比較あり)
物体検出とは
画像から、物体の位置と種類を特定(物体は複数存在する場合もある)
位置については、比較的ざっくり捉えるものとピクセルレベルで捉えるものがあります(下図参照)

https://www.pyimagesearch.com/2018/11/26/instance-segmentation-with-opencv/ より
ここでは
’Object Detection’→「物体検出」
’Instance Segmentation’→「セグメンテーション」と呼びます
セグメンテーションにはSemantic Segmentationというものもあります
Instance Segmentationはあらかじめ物体のありそうなところを検出してからその範囲をピクセル単位でラベルづけするのに対し
Semanticの方は画像全体に対してしらみつぶしにラベルづけします
Mask R-CNN
(元論文:https://arxiv.org/pdf/1703.06870.pdf)
参考:https://qiita.com/shtamura/items/4283c851bc3d9721ed96
https://qiita.com/yu4u/items/5cbe9db166a5d72f9eb8
そもそもMask R-CNNとは
物体検出機能に加えて、セグメンテーション機能が追加されたもの
Mask R-CNNの処理フロー
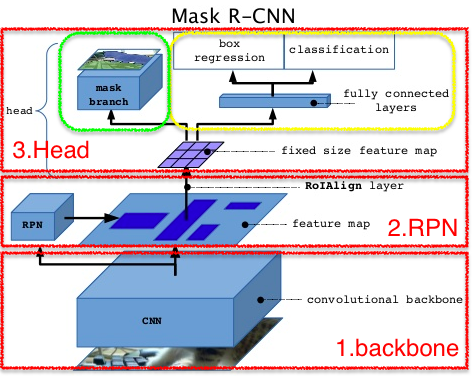
https://www.slideshare.net/windmdk/mask-rcnn より
1.Backbone
ResNetやVGGを転移学習する
入力された画像を畳み込み層で処理し、特徴マップを出力
2.RPN
1から特徴マップを受け取り物体がありそうな領域を探す
特徴マップから、その領域候補の固定サイズの特徴マップを抽出
3.Head
ーbox regression/classification(黄色枠)
上記の「物体検出」にあたる
box regressionで物体のある領域(四角)を判別
それぞれの物体についてclassificationでそれが何であるか分類
ーmask branch(緑枠)
上記の「セグメンテーション」にあたる
ピクセル単位でクラス検出をする
論旨
従来手法(Mask R-CNN)の問題点
1.候補領域抽出に下位層の情報を使いたいが、上の層まで距離があり正確に伝えるのが難しい
2.候補領域のサイズに合った層の特徴マップだけ使用しており、位置推定の精度がいまいち
3.セグメンテーションの予測が1つの視点だけで多様性がない
何をするのか?
以上3つの問題点それぞれへの対策を組み込んだモデルを作る
1下位層の情報を伝わりやすくする(Bottom-up Path Augmentation)
2.全ての特徴マップを合わせて使う(Adaptive feature pooling)
3.fcレイヤを追加し別の視点を入れる(Fully-connected Fusion)
提案手法
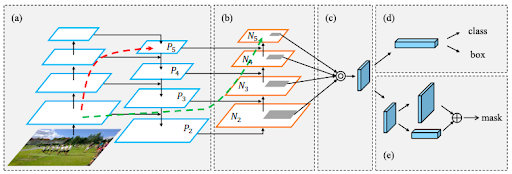
PANetの構造の全体図 (a),(b)ではチャンネル次元は図示されていない(見やすさのため)
(a)Backbone(ResNet-FPNを使用)
(b)RPN(①Bottom-up Path Augmentation)
以下Head
(c)候補領域ごとに特徴マップを抽出(②Adaptive feature pooling)
(d)物体検出
(e)セグメンテーション(③Fully-connected Fusion)
①Bottom-up Path Augmentation
モチベーション:候補領域の抽出の精度を上げたい
何をするのか:
エッジなどの局所的なパターンへの感度が高いと位置検出の精度向上に繋がる
→下位層の情報を伝播させやすくすることで、候補領域抽出をより正確にする
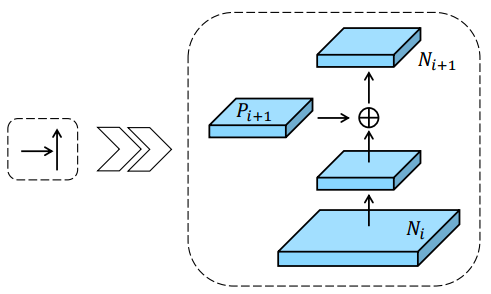
1.新しい特徴階層(N2,N3,N4,N5)を作る
Backboneで抽出された特徴量をP2,P3,P4,P5で表す
下図のように、空間サイズを合わせたNiとPi+1を足し合わせNi+1とすることで、特徴量を改善
2.FPNの既存のショートカット(赤点線)では距離がありすぎる(100層以上)
→下位層から上位層に情報の近道(緑点線)を作る(10層未満)
②Adaptive feature pooling
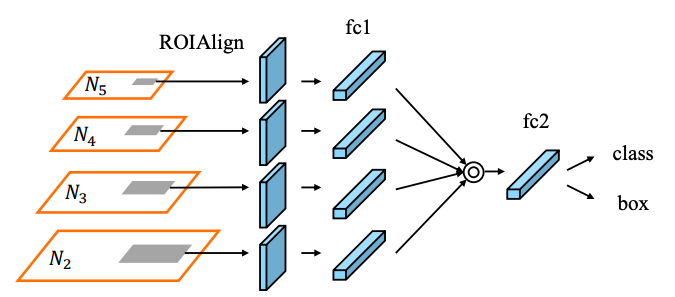
上図は物体検出の部分((b)-(d))を少し詳しく図示したもの
モチベーション
候補領域を抽出した後の位置推定を改善したい
何をするのか
今までは候補領域のサイズごとに処理していたが
(ex.小さい候補領域なら下位層の特徴マップ、大きいものなら上位層の特徴マップ)
下図の通り、使っていなかった特徴マップも位置推定に貢献することが分かる
→候補領域に当たる部分を抽出した特徴マップ(構造図のグレーの部分、図では4つ)について、
要素ごとの最大値または合計をとる形で融合する
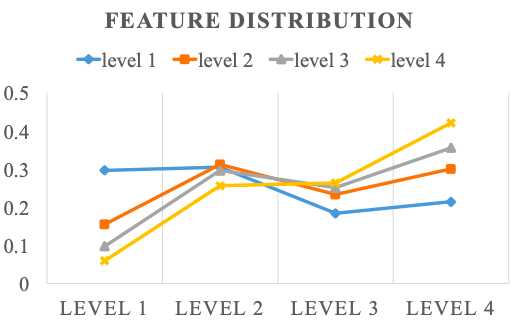
横軸は候補領域のサイズ、縦軸は特徴マップの貢献度
③A complementary path
モチベーション
違った視点を追加することで、セグメンテーションの精度を上げたい
何をするのか
元々使われていたFCNレイヤに加え、fcレイヤ(下図の赤枠部分)を追加
FCNは候補領域ごとにピクセル単位で物体の位置を予測するが、
fcレイヤは候補領域にとらわれず背景か物体かを予測
→情報の多様性が増加し精度向上に繋がる
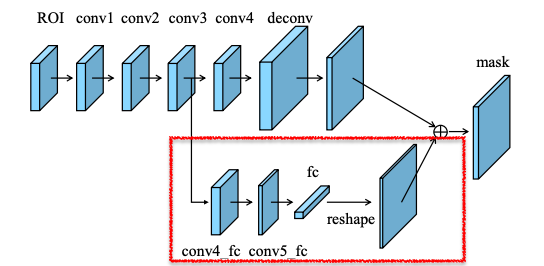
実験結果
評価指標について参考:https://note.mu/seishin55/n/n542b2b682721
要点
セグメンテーションと物体検出の両方で威力を発揮
COCO/Cityscapes/MVDの全てのデータセットにおいてもトップレベルの精度を得た
セグメンテーション

データセットはCOCO、APは適合率の平均を表す(右下の添字は閾値)
APS・APM・APLは物体のサイズ
Mask R-CNN(青枠)だけでなくこの年の1位の成績(緑枠)も上回っている
物体検出
物体検出のみを行いたい時は、セグメンテーション部分は切り離して使う

セグメンテーション同様、この年の1位の成績(緑枠)も上回っている
CityScapes(参考までに)

AP[val]は検証データ/APはテストデータについて
参考:精度計算について
IoU(Interseption over union)
予測領域と正解領域の重なりの割合を表す
物体の予測領域をP、正解領域をTとした時 IoU = (P and T) / (P or T) ※下図参照
IoUの値の範囲は0~1であり、その中で閾値を設ける
その閾値を超えた時に正解とする
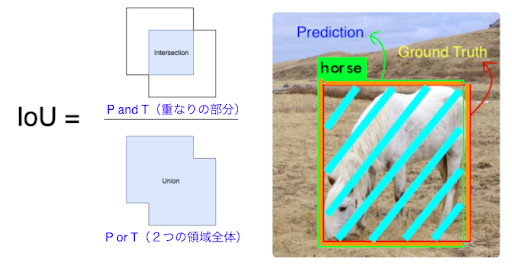
https://tarangshah.com/blog/2018-01-27 より
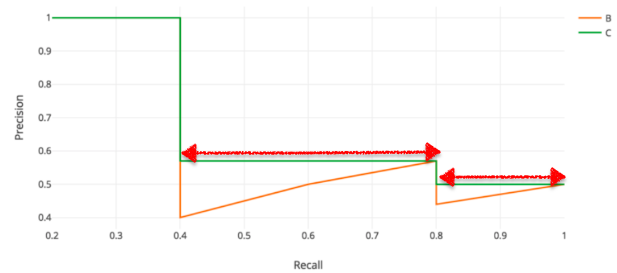
AP(Average Precision)
IoUの閾値を元に、recallを0~1の範囲で0.1刻みに変化させた時のPrecisionをプロット(オレンジ線)
ただしその時、赤矢印部分のようにrecallもprecisionも高いものがあればそれを採用(緑線)
緑線の下の部分の面積がその閾値でのAPとなる
最終的なAPは各閾値(0.5~0.95まで0.05刻み)に関して求めたAPの平均をとる