はじめに
最近、自然言語処理と画像処理の交流勉強会に参加したのもあり、これを機に前々から興味を持っていた画像処理系のニューラルに挑戦してみました。
せっかくやるので、自分の好きな音楽関係で何かできないかということで題目の通り、CDジャケット画像から音楽ジャンルを判別できるAIを作ってみようと思いました。
そこで、VGG16のfine-tuningを行うことで、CDジャケットの画像データを入力として、今回は{クラシック・ヒップホップ・ジャズ・メタル・ポップス・ロック}の6クラス分類を行うモデルを実装しました。
(細かく言えば、非常に複雑なカテゴリ分類になるかとは思いますが、今回はオンラインCDショップのカテゴリ分類を基に独断と偏見で大雑把に上記6クラスに分類しました。)
結果から言えば、分類精度は約60%となりました。そもそも人間が判断してみても難しいタスクであるため、精度向上にはひと工夫もふた工夫も必要な気がします。。
今回収集・使用したCDジャケット写真データセットについては、著作権等の関係が厳しそうなので公開予定はありませんが、自動収集に使用したスクリプトについては公開する予定です。
画像系ニューラルは超初心者で、至らないところが多々あると思います。
データ処理・モデル学習時の工夫など、ご意見・アドバイスいただければ励みになります!
VGG16の実装に当たってこちらの記事を参考にさせていただきました。ありがとうございます!
また、色々とアドバイスをくれた研究室の後輩くんにも感謝します!
今回やったこと
- WebスクレイピングによるCDジャケット画像の収集
- VGG16を基に全結合層を追加、fine-tuningによるモデルの学習
- 学習したモデルでCDジャケットからジャンルを推定
実装環境
OS : Ubuntu(16.04.1 LTS)
GPU : GeForce GTX 1080
Python : 3.6.5
tensorflow-gpu==1.4.0
Keras==2.1.3
CDジャケットで見る音楽ジャンル
まず、CDジャケットから本当にジャンル推定ができるのでしょうか?
今回、大まかに分類しているクラシック・ヒップホップ(+レゲェ)・ジャズ・メタル・ポップス・ロックの典型例?を紹介します。
クラシック

ヒップホップ/レゲェ

ジャズ

メタル

ポップス

ロック

もちろん見ただけではジャンルが想像付かなかったり、別のジャンルじゃね?と思うものもありますが、なんとなくジャンルごとのCDジャケットに特徴があるような気がしないでしょうか?
CDジャケット画像の収集
訓練およびテストに使用する画像データの収集を行います。
HMV&books -online-の「音楽CD・DVD」売れ筋ランキングページの各カテゴリから画像データのみをスクレイピングしました。こちらのサイトでは大きく9ジャンル(ジャパニーズポップス・韓国/アジア・ロック・ダンス&ソウル・ワールド・サウンドトラック・イージーリスニング・クラシック・ジャズ)についてそれぞれ最大14、最小3のサブジャンルに分類されています。今回はここから、各ジャンル売れ筋ベスト100の商品の画像データをスクレイピングの対象としています。
スクレイピングは予め用意したHMVの売り上げランキングページのURLリスト url_list.txt を元に、以下のスクリプトを用いて行いました。
import requests
import re
from bs4 import BeautifulSoup
import uuid
import os
def save_image(url_, genre_):
#画像スクレイピング
save_path = "./picture/"+str(genre_)+"/"
r = requests.get(url_)
# print(r.text)
soup = BeautifulSoup(r.text,'html5lib')
# print(soup)
imgs = soup.find_all('img',src=re.compile('^https://img.hmv.co.jp/image/jacket'))
for img in imgs:
print(img['src'])
r=requests.get(img['src'])
with open(str(save_path)+str(uuid.uuid4())+str('.jpg'),'wb') as file:
file.write(r.content)
print(genre,"save complete :-)")
def make_dir(dir_name):
# ジャンル別に画像保存用ディレクトリ作成
new_dir_path_recursive = "./picture/"+str(dir_name)
try:
os.makedirs(new_dir_path_recursive)
except FileExistsError:
#print("existed")
pass
if __name__ == "__main__":
with open("url_list.txt", 'r') as url_f:
for line in url_f:
url = line.split(',')[0]
genre =line.split(',')[1].strip('\n')
make_dir(genre)
trg_url2 = url + "pagenum/2/"
trg_url3 = url + "pagenum/3/"
trg_url4 = url + "pagenum/4/"
save_image(url,genre)
save_image(trg_url2,genre)
save_image(trg_url3,genre)
save_image(trg_url4,genre)
https://www.hmv.co.jp/bestsellers/21100900/,Jpops
https://www.hmv.co.jp/bestsellers/21102000/,Jrock
https://www.hmv.co.jp/bestsellers/21100200/,indies
・・・
それとは別に、メタルのCDジャケットについてはこちらの記事を参考にEncyclopaedia Metallumというサイトから収集しました。(本当はメタルの中のサブジャンル(デスメタル・スラッシュメタル・デスコア・メロスピetc...)に特化したモデルを作るためにこの企画を始めたものの、ジャンルの複雑さから挫折したのは内緒です。)
データ分割
今回は収集したジャンルのうち最も少なかった「ジャズ」のデータ数に合わせて、各ジャンル400枚の画像を使用しました。
収集した画像データをモデルの学習のためにtrain(70%), dev(15%), test(15%)に分割します。
収集・分割した画像データは /data/ ディレクトリ下にジャンル別に以下の用に配置します。また、/data/display/には評価時に推定ラベルを画像と共に一覧で表示するために使用する画像用ディレクトリとして、/test/と同じデータが入っています。
├── data
│ ├── train #各280枚
│ │ ├── Classic
│ │ ├── HipHop
│ │ ├── Jazz
│ │ ├── Metal
│ │ ├── Pops
│ │ └── Rock
│ ├── dev #各60枚
│ │ ├── Classic
│ │ ├── HipHop
│ │ ├── Jazz
│ │ ├── Metal
│ │ ├── Pops
│ │ └── Rock
│ ├── display #評価時の予測結果表示用
│ │ └── ~.jpg, ...
│ └── test #各60枚
│ ├── Classic
│ ├── HipHop
│ ├── Jazz
│ ├── Metal
│ ├── Pops
│ └── Rock
├── train.py
├── test.py
└── pred.py
モデルの訓練
訓練用スクリプトtrain.py では/train/ディレクトリにある画像データを用いてモデルの訓練を行います。
今回は学習済みモデルとしてimagenetを用いて、それをベースにVGG16のfine-tuningします。
fine-tuningのメリットとしては以下の点が挙げられます。
- 少ない画像でも学習できる
- 学習時間が比較的短く済む
こちらの記事を参考に、VGG16のfine-tuning用スクリプトを自分なりに少しだけ変更しました。
Dense(units, activation)によって全結合層を自由に追加することができます。
以下の部分ではVGG16の15層以降に全結合層をさらに2層追加しています。VGG16に全結合層を何層か加えることで精度も良くなったり、悪くなったりすることがわかりました。
今回は精度向上に繋がらなかったため加えていませんが、Dropout(rate)を用いてドロップアウトも行うことができます。 (参照:公式ドキュメント)
# add new layers instead of FC networks
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(1024,activation='relu')(x)
x=Dense(512,activation='relu')(x) #add FC1
x=Dense(216,activation='relu')(x) #add FC2
prediction=Dense(n_categories,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=prediction)
そのほか、optimizerやactivation、batch_sizeなどのハイパーパラメータを色々と変えてモデルの訓練を行いました。
さらに、学習済みの重みも更新することで少しだけ精度が上がったため、以下の部分もコメントアウトしています。
# fix weights before VGG16 14layers
# for layer in base_model.layers[:15]:
# layer.trainable=False
最終的には、以下の訓練用スクリプトtrain.pyを使用しました。
VGG16を基に、全結合層をさらに2層加えた構造としています。また、オプティマイザーをAdam、活性化関数をrelu、batch size=64と設定したときが最も良い精度となったため、これらを採用しています。
from keras.models import Model, Sequential
from keras.layers import Dense, GlobalAveragePooling2D,Input
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD, Adam
from keras.callbacks import CSVLogger
from keras.layers import Activation, Dropout, Flatten
n_categories=6
batch_size=64 #default 32
train_dir='data/train'
validation_dir='data/dev'
file_name='vgg16_music_fine'
base_model=VGG16(weights='imagenet',include_top=False,
input_tensor=Input(shape=(224,224,3)))
# add new layers instead of FC networks
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(1024,activation='relu')(x)
x=Dense(512,activation='relu')(x) #add FC1
x=Dense(216,activation='relu')(x) #add FC2
prediction=Dense(n_categories,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=prediction)
# fix weights before VGG16 14layers
# for layer in base_model.layers[:15]:
# layer.trainable=False
# model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),
model.compile(optimizer=Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
# save model
json_string=model.to_json()
open(file_name+'.json','w').write(json_string)
train_datagen=ImageDataGenerator(
rescale=1.0/255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen=ImageDataGenerator(rescale=1.0/255)
train_generator=train_datagen.flow_from_directory(
train_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
validation_generator=validation_datagen.flow_from_directory(
validation_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
hist=model.fit_generator(train_generator,
epochs=100,
verbose=1,
validation_data=validation_generator,
callbacks=[CSVLogger(file_name+'.csv')])
# save weights
model.save(file_name+'.h5')
自分の環境では100エポックの訓練に約1時間半程度かかりました。
学習経過
学習経過をグラフ描画しました。青が訓練時、オレンジが検証時の精度を表しています。
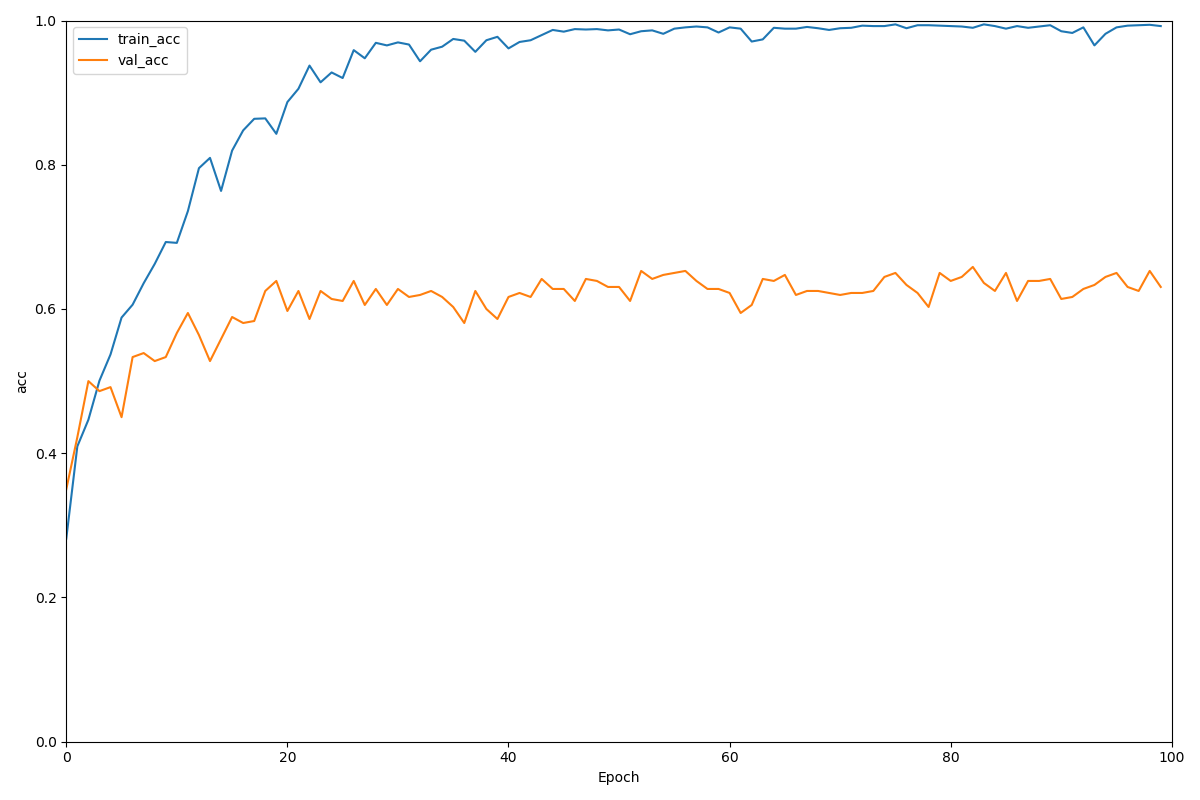
訓練セットではいい感じに学習が進んでいるのに対して、検証セットでは6割前後で頭打ちとなってしまっています(過学習?)。
モデルの評価
test.pyではテストセットを用いて訓練したモデルの評価を行います。それに加えて、テストセットの画像をモデルの予測ラベルとともにランダムで一覧表示します。
from keras.models import model_from_json
import matplotlib.pyplot as plt
import numpy as np
import os,random
from keras.preprocessing.image import img_to_array, load_img
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD, Adam
batch_size=64
file_name='vgg16_music_fine'
test_dir='data/test'
display_dir='data/display'
label=['Classic','HipHop','Jazz','Metal','Pops','Rock']
# load model and weights
json_string=open(file_name+'.json').read()
model=model_from_json(json_string)
model.load_weights(file_name+'.h5')
# model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),
model.compile(optimizer=Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# data generate
test_datagen=ImageDataGenerator(rescale=1.0/255)
test_generator=test_datagen.flow_from_directory(
test_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
# evaluate model
score=model.evaluate_generator(test_generator)
print('\n test loss:',score[0])
print('\n test_acc:',score[1])
# predict model and display images
files=os.listdir(display_dir)
#print(files)
img=random.sample(files,25)
plt.figure(figsize=(10,10))
for i in range(25):
temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224))
plt.subplot(5,5,i+1)
plt.imshow(temp_img)
# Images normalization
temp_img_array=img_to_array(temp_img)
temp_img_array=temp_img_array.astype('float32')/255.0
temp_img_array=temp_img_array.reshape((1,224,224,3))
#predict image
img_pred=model.predict(temp_img_array)
plt.title(label[np.argmax(img_pred)])
#eliminate xticks,yticks
plt.xticks([]),plt.yticks([])
plt.savefig('./figure.png')
# plt.show()
('\n test loss:', 2.0910739554299247)
('\n test_acc:', 0.6111111084620158)
モデル構造やハイパーパラメータを色々と試行錯誤してみても、61.1%が限界でした。
6クラス分類で61%なのでランダムで分類するよりかは確かに良い精度ですが、やはりタスク自体が難しいためか、同じVGG16のfine-tuningで他の方がやっていらっしゃるキャラクター識別や動物、花の種類識別に比べると精度が劣ります。。
テストセットがどのようにラベル付けされているのかを見てみましょう。

「メタル」のジャケット写真に関してはわかりやすいためか、予想通り高い精度で正解しているようです!(上の画像だと5枚中5枚正解!!)メタル好きの私にとってはとても嬉しいです。
そのほか、「クラシック」や「ジャズ」、「ポップス」は多少間違いがあるものの、割とうまく識別できているような気がします。
一方でThe Beatlesの名盤「abbey road」(2行5列目)は本来「ロック」と分類してほしいところを「ヒップホップ」に、逆に湘南乃風のアルバム(3行5列目)は本来「ヒップホップ」と分類してほしいところを「ロック」と予測されています。Queenのアルバム(4行1列目)も間違えて分類されています。
この辺りはジャンル特有の特徴が似ているせいか、人間と同様に識別困難のようです。
個別画像の予測
pred.pyでは第1引数に画像データを指定することで、個別画像の予測結果を見ることができます。
import os, sys
import numpy as np
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras.preprocessing import image
from keras.models import model_from_json
from keras.optimizers import SGD, Adam
from keras import optimizers
import argparse
classes = ['Classic','HipHop','Jazz','Metal','Pops','Rock']
nb_classes = len(classes)
img_width, img_height = 224, 224
file_name='vgg16_music_fine'
def get_args():
parser = argparse.ArgumentParser(description = 'python .py image.jpg')
parser.add_argument('file', type=str, help='specify the image')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
data = args.file
# model_load
json_string=open(file_name+'.json').read()
model=model_from_json(json_string)
model.load_weights(file_name+'.h5')
model.compile(optimizer=Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# get image
img = image.load_img(data, target_size=(img_width, img_height))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = x / 255
pred = model.predict(x)[0]
# predict label
top = 6
top_indices = pred.argsort()[-top:][::-1]
result = [(classes[i], pred[i]) for i in top_indices]
# print('file name is', test_image)
print(result)
python pred.py '予測したい画像.jpg'
テストデータにも存在していないジャケット写真のジャンルを色々と予測させてみました。(選んだジャケ写は筆者の好みのせいでジャンルに偏りがあります。)
Panteraの「俗悪」。メタルの名盤です。

[('Metal', 0.999918), ('Rock', 5.2051124e-05), ('Jazz', 1.7351162e-05), ('Pops', 5.5816536e-06), ('HipHop', 5.096015e-06), ('Classic', 1.8767064e-06)]
正解です。非常に高い確率でMetalと予測されていますね。
Protest the Heroの「Fortress」。とてもかっこいいプログレッシブメタルバンドです。

[('Metal', 0.9999982), ('Rock', 1.4321332e-06), ('Jazz', 2.0357638e-07), ('Pops', 8.214208e-08), ('Classic', 1.5169535e-08), ('HipHop', 6.500487e-09)]
こちらも非常に高い確率でMetalと予測されています。
Red Hot Chili Peppersの「By The Way」。日本でも人気の高いロックバンドの名盤です。

[('Rock', 0.6043729), ('HipHop', 0.3316904), ('Pops', 0.061973047), ('Jazz', 0.0013085871), ('Metal', 0.00040159596), ('Classic', 0.00025346255)]
正解です。60%の確率でRockと予測していますが、次点に33%と割と高い確率でHipHopが来ています。
ZARDの「永遠」。

[('Pops', 0.9347754), ('HipHop', 0.05901419), ('Jazz', 0.0056681125), ('Rock', 0.00035684672), ('Metal', 0.00013803164), ('Classic', 4.746155e-05)]
私も「Pops」だと思います。
私がよく聴くドビュッシーのアルバムです。 クラシックのアルバムは作曲家や演奏者の写真、名画などがジャケット写真中に入っていることが多い気がします。

[('Metal', 0.99534094), ('Rock', 0.0034454286), ('Classic', 0.00068164495), ('Jazz', 0.0005175881), ('Pops', 1.281737e-05), ('HipHop', 1.563463e-06)]
ドビュッシーはメタルミュージシャンだそうです。
こちらは名画が含まれているため典型的なクラシックのジャケット写真だと思っていましたが、Metalと予測されました。全体的に黒っぽいことが影響しているのでしょうか。
Ed Sheeranの「X」。今年初来日するそうです。

[('HipHop', 0.9996439), ('Pops', 0.00031218753), ('Metal', 2.7120488e-05), ('Jazz', 1.44978885e-05), ('Rock', 1.732426e-06), ('Classic', 3.6677994e-07)]
HipHopと予測されました。私はPopsだと思います。
最後にX Japanのベストアルバムです。ジャパニーズメタルの金字塔ですね。色以外はEd Sheeranの「X」と似ています。

[('Metal', 0.9984549), ('Pops', 0.0009312704), ('Rock', 0.00041957456), ('Jazz', 0.00012828718), ('HipHop', 5.0926585e-05), ('Classic', 1.5063462e-05)]
こちらはうまくMetalと予測してくれました!やはり、全体的に黒っぽいとMetalと予測しているのでしょうか。
おわりに
今回は、VGG16のfine-tuningを行うことでCDジャケット写真の音楽ジャンル判別を試みました。
画像処理の入門として実際にVGG16のモデルをいじってみましたが予想以上に簡単に実装することができました。
結果としてはあまり良い精度とは言えませんでしたが、fine-tuningによって少ない画像でも特定ドメインの画像をある程度は分類することができる事が確認できました。
ジャンルの区別が曖昧なもの、ジャケット写真だけでは人間でも区別が付かないものなど多いため、そもそものタスク設定を考え直す必要がありそうです。。