2018年末 Power Query についてお話しなどする機会があった。そこで話した内容とは、Power Query はほどほどに賢く想像しているような動作をしていないかもですよってこと。Excel ユーザーやこれからPower Query を使うのかなぁと考えられる層なので、Power Query エディターの使い方や Tips ではなかった。わりとそもそも的な内容。
"適用したステップ" の順番で処理されているのか?
速やかに処理が終えるような工夫がされていると考えておけば十分かもしれない。だけど、適用するステップの順番で処理されているとは限らない。
Power Query エディター でデータの変換や加工を進めていくとき、Power Query エディターはその処理を "適用したステップ" として残していく。UIでの操作をしていくと、都度、"適用したステップ" として追加や挿入をしてくれるので、人がそれらをみたとき理解しやすく作業しやすいわけだ。
では、中の人はどうしているかというと、Power Query エディター に並べられた "適用したステップ" の順番を気にすることはなくて、どのように"クエリ"を評価して行くべきかを判断しているのです。
let expression, in statement
Power Query エディター を利用し "クエリ" を作成していくとき、多くの場合で、let ~ in ~ が使われる。必ず使わなければならない構文ということではなく、見やすい/理解しやすい/編集しやすい という点で多用されているということでしょう。
Power Query は 関数型言語だから、Excel ワークシート関数のようにネストさせて複雑な計算などをさせることができる。必要であればだけど。
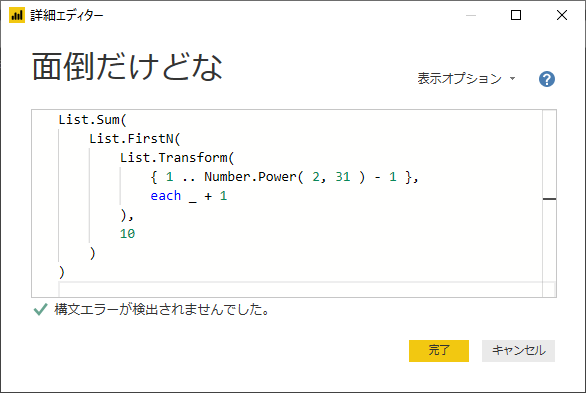
もうちょっとすると理解するのが面倒になるので、
let
Source = { 1 .. Number.Power( 2, 31 ) - 1 },
AddOneForEachItem = List.Transform( Source, each _ + 1 ),
SelectFirstItems = List.FirstN( AddOneForEachItem, 10 ),
SumOfItems = List.Sum(SelectFirstItems)
in
SumOfItems
という感じにしているのだ。これもまた Excel ワークシートでの作業と似ていて、複雑にネストするならば、いったん別のセルに途中の結果を置いといてさらに計算するような使い方みたいなもの。手続き型言語っぽくしていてUI操作がしやすいようにしている工夫でもあるのでしょう。
なにが収まっているのか
変数名と評価される式のセットひとつ以上を束ね、最終出力される式/値を指定しているだけ。"適用したステップ"の順番は定義されていない。中の人は 変数名 を頼りに式を評価していく順番を判断しているだけ。とはいえ、中の人が式の評価順を解釈しているということがとても重要なのです
"変数名" と "式" という表現をしたけれども、変数名は識別子であり、変数は不変/immutable なので、"名前付けされた値" という感じでもよいかもしれない。
順番が変わっても同じ結果が得られる
詳細エディターで行ごと上下など順番を入れ替えてみると何となく見えてくる。
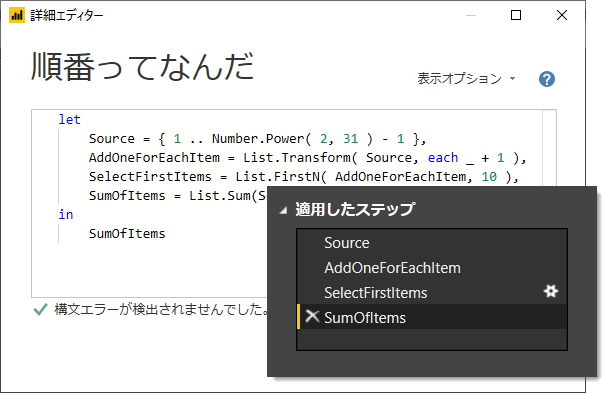
"適用したステップ" の順番とは別に期待する順序で評価されるのです。なので順番が入れ替わっていても同じ結果を得ることができる。
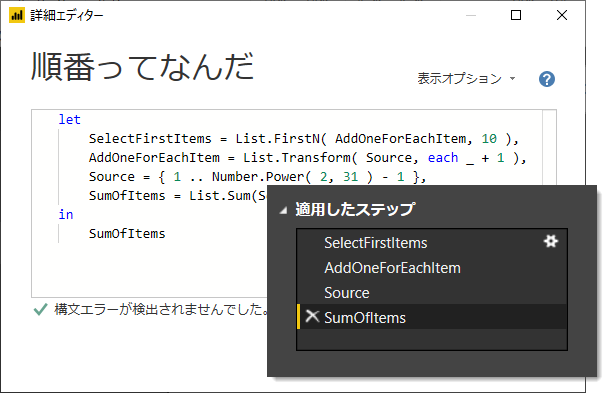
"適用したステップ"を上下に移動するという操作は、評価に用いる関数など式はそのままにして変数を入れ替える操作なので結果は変わってしましまう。
独自に順番を理解していてなにがよいのか
デモなどで実演する場合であれば、"適用したステップ"が連続する様は一本道でしょう。ですが、実装レベルで作業をするとき、もしかすると "ちょっと分岐させておいて" とか "ここで結合させて" とかフローが発生すると思うのです。これもまるっと面倒見てくれるのだから頼りになるかと。Power Query エディター でいうところの "クエリ" として分解するのでもありかな。"クエリ" が評価される順番も中の人がよきに管理してくれますので。
で、他にもイイ感じなことがあるのです。
遅延評価
前段とりあげた let 式 では 遅延評価 が機能することになっていて、求める結果を得るためには不要な評価をしない動作をする。
let
Source = { 1 .. Number.Power( 2, 31 ) - 1 },
ErrorStep = error "エラーですよ",
AddOneForEachItem = List.Transform( Source, each _ + 1 ),
SelectFirstItems = List.FirstN( AddOneForEachItem, 10 ),
SumOfItems = List.Sum(SelectFirstItems)
in
SumOfItems
と、なっているとき、
"SumOfItems" の評価には "SelectFirstItems" が必要
"SelectFirstItems" の評価には "AddOneForEachItem" が必要
"AddOneForEachItem" の評価には "Source" が必要
という具合に必要になるまで式を評価しない。エラーとなる "適用したステップ" が"クエリ"に存在したとしても、ここでは評価される対象には含まれないので "クエリ" の評価はエラーとならない。
評価順もこんな感じで決定していると考えればわかりやすいかなと。
let
Source = { "1".."4", "Five", "6".."9" },
NumberFromText = List.Transform( Source, Number.FromText )
in
NumberFromText
リストアイテムには評価できなかった意味の error が含まれるが、この"クエリ" がいきなりエラーで終了することはない。なぜなら error となる リストアイテムについての評価がまだされていないから。
let
Source = { "1".."4", "Five", "6".."9" },
NumberFromText = List.Transform( Source, Number.FromText ),
FifthListItem = NumberFromText{4}
in
FifthListItem
この"クエリ"は エラーで終了する。なぜなら、評価できず error となるリストアイテムを評価しているから。
let 式 のほか table / list / record を扱うときも 遅延評価 されることになっている。error が含まれていることで "クエリ" が終了してしまうと除外や置換ができなくなってしまうから必要な考え方なのでしょう。
可能であれば不要な評価をしない
評価順を理解していることで不要な評価をしないことがある。
let
Source = { 1 .. Number.Power( 2, 31 ) - 1 },
AddOneForEachItem = List.Transform( Source, each _ + 1 ),
SelectFirstItems = List.FirstN( AddOneForEachItem, 10 )
in
SelectFirstItems
(STEP1) 1 から 2^31 -1 の 整数値 のリストを作成
(STEP2) リストアイテムそれぞれに 1 を加算
(STEP3) リストの先頭 10 アイテムだけを選択
というクエリなのだけど、やたら早く完了するのです。
STEP3 の List.FirstN でリストアイテム先頭から10アイテムを選択するけど、少なくともリストアイテム個々の評価は必要としないので、STEP2 の評価に影響を与えていることが予想できていて、
let
Source = { 1 .. Number.Power( 2, 31 ) - 1 },
SelectFirstItems = List.FirstN( Source, 10 ),
AddOneForEachItem = List.Transform( SelectFirstItems, each _ + 1 )
in
AddOneForEachItem
特徴のある内容で明示しているので、実務上では できるだけ対象を絞り込んでから評価するようにした方がよいことにかわりはない。
クエリ フォールディング
データソースからすべてのデータを取得してから処理するというのはできるだけ避けたいところなのだけど、これについても評価順を知っている中の人は支援を試みる。
データソースに接続し得られたテーブルに対し、不要な行を除外したり、集計対象となる列のみを選択したり、Power Query エディター 上では 先の "適用したステップ" に移っているけれども、中の人は評価順とその意味を解釈し、データソースへの問い合わせをまとめてくれるのです。
リレーショナルデータベースから抽出をする際のクエリ フォールディングについては、以前ポストした。
Power Query エディター の クエリ フォールディング機能とは - Qiita
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
FilteredRows =
Table.SelectRows(
_商品,
each ([区分ID] = 1
)
),
RemovedOtherColumns =
Table.SelectColumns(
FilteredRows,
{"商品ID", "商品名"}
)
in
select [_].[商品ID],
[_].[商品名]
from [商品] as [_]
where [_].[区分ID] = 1 and [_].[区分ID] is not null
リレーショナルデータベース以外ではどうなんだ
リレーショナル データベースについては、Power Query エディター 上で どのような SQL が発行されるのか見るすべはあるのでよいのだけど。
OData.Feed コネクタを取り上げますよ
たまたま連続して周囲のトピックになったし、いろんなところで OData.Feed コネクタ が使われていることが多いから。
OData.org の Nothwind(v4) http://services.odata.org/v4/northwind/northwind.svc であれこれしてみる。
let
Source = OData.Feed(
"http://services.odata.org/v4/northwind/northwind.svc",
null, [Implementation="2.0"]
),
Products_table = Source{[Name="Products",Signature="table"]}[Data],
FilteredRows = Table.SelectRows(
Products_table,
each [UnitPrice] < 100
),
ExpandedCategoryName = Table.ExpandRecordColumn(
FilteredRows,
"Category", {"CategoryName"}, {"CategoryName"}
),
RemovedOtherColumns = Table.SelectColumns(
ExpandedCategoryName,
{"ProductID", "ProductName", "CategoryID", "UnitPrice", "CategoryName"}
),
SortedRows = Table.Sort(
RemovedOtherColumns,
{"CategoryID", Order.Ascending}
)
in
SortedRows
(STEP1,2) OData サービスに接続し、Products テーブルを参照
(STEP3) UnitPrice が 100 未満を条件に行の絞り込み
(STEP4) Cateogry テーブルの関連する行の CategoryNameを展開
(STEP5) 不要な列を除外
(STEP6) CategoryID で昇順
元のテーブルを参照してから 4ステップ進んでいるのだけど、データモデルにロードするときのリクエストは、
https://services.odata.org/V4/Northwind/Northwind.svc/Products?$filter=UnitPrice%20lt%20100&$expand=Category($select=CategoryID,CategoryName)&$orderby=CategoryID&$select=ProductID,ProductName,CategoryID,UnitPrice,Category&$skiptoken=8
skiptoken は 中の人がくっつけていて順次インクリメントしてリクエストしてくれる。
top とか 他にもサポートしてそうなパラメータありそうだけどこの辺で。
SharePoint リスト(online)はどうだ
だめだ。いろいろ試していて笑ってしまった。そして、あきらめた。だが、それも結果。
標準のコネクタではクエリフォールディングは効かない様相。その引き換えじゃないけど 5000件超えていても全行取得はできそうである。また、OData.Feed コネクタで filter パラメータを使う場合、インデックス付きの列を条件とすれば全件読み込むような動作はしなかった。
どうやったら確認できるのか
Fiddler を使ってキャプチャするっていうのが定番だとおもうんだけど、せっかくなので別の方法で。
・トレースログを参照する
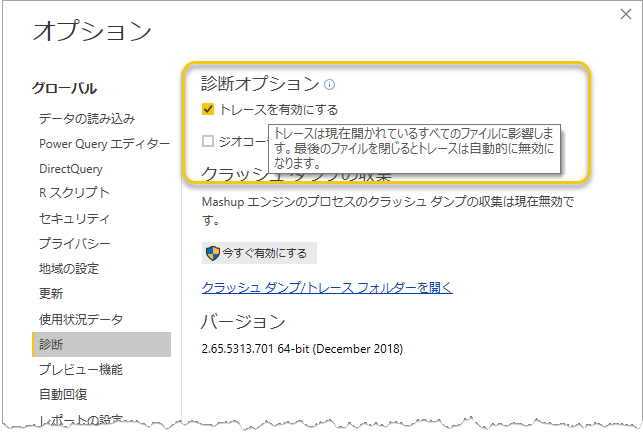
トレースを有効にして、[最新の情報に更新]。トレースフォルダにログが出力されるのでじっくり眺めればよいかと。ただ、Power Query のプロセスごとに出力されてしまってやたら多くなるかもだから、確認したいクエリと"適用したステップ"だけにしておいた方がよさそう。
Excel の場合は プロセスがひとつだけになるのでログもひとつのはず。と思っていたらそうでもなかったようだ。
Power BI Desktop に "クエリ診断" 機能が追加されました
Power Query エディターで診断開始から終了、パースされたファイル(JSON)からログなど参照できるようになりました ![]()
まとめ💥
ボタンポチポチでもそれなりに作業を進められる。ガッツリのめりこんで複雑な処理をすることもできる。使い方はどちらでも構わないけれども、問題ないはずだがなんだかうまくいかないなっていうときにどのような対処をするか/対処ができるか。知ってた/知らなかったで大きく違いが出てくるのではないかと。詳細エディターでスクリプトを凝視しても見えないことってあるのです。
その他
PowerBI PowerQuery Excel