ファイルやデータソースからどのようにデータを読みこんでいるのか理解してる?ボタンポチポチの手順や関数の使い方っていう勉強していてもさ、ずっと気づかないままかも知れない。それはそれで素晴らしいことなんだけどね。
テーブルの行を選択するという処理は、処理できる行数に制限がない Power Query を使うときにはとても重要なこと。そのわりには、あまり理解しないまま使っていることが多いのではないだろうか。まぁ、普通に使っていれば大きな問題に遭遇することはないはずだけど。Power Query の本来の動作や仕組みを知らないまま、あれこれといじってしまい、とてもよくない状況を生み出していることもある。
Power Query の使い方や記述は自由だ。けれども Power Query はデータベースでも Excel でもない。特徴や仕組みを理解し、Power Query の強みを生かすロジックを考えるべきだ。
行を選択するときに理解しておくべきこと
行を選択することだけに限った話ではない。ただ、クエリ評価のうちできるだけ早い段階で行方向/列方向の絞り込みを適用することがベストプラクティスであるからだ。初っ端のミスチョイスを絶対に避けるべきということ。GUI での操作は簡単であるけれども、操作が簡単なだけだからね。
ソースデータにする CSV や Excel ファイル(xlsx) などファイルフォーマットや使用するデータソースの特徴や機能を十分に理解して、どのような処理(Power Query 関数)を選択するか、常に心掛けるとよいはずだ。
Power Query の重要な動作
データソースはデータベースじゃないし関係ないと思っているなら、お好きにどうぞ。
だが、クエリが評価されるとき、可能な限り上流(データソース方向)に向けて処理をプッシュする。
CSV ファイルを読み込むときを例にする。
let
Source = Csv.Document( File.Contents( Csv1GBToTable ) ),
SelectFirstN = Table.FirstN( Source, 10 )
in
SelectFirstN
このクエリが評価されるとき、CSV ファイルすべてを読み込まない。テーブルで 10 行到達した時点でファイルの読み込み動作(File.Contents)は終了する。先頭 10 行を選択するステップ(Table.FirstN)が後に記述されていてもだ。これは Power Query の評価システムの特徴であり、ファイルシステムがサポートしている機能を使っているということだ。
let
Source = Csv.Document( File.Contents( Csv1GBToTable ) ),
AddedIndexColumn = Table.AddIndexColumn( Source, "Index", 1 ),
SelectedRows = Table.SelectRows( AddedIndexColumn, each [Index] < 11)
RemovedIndexColumns = Table.RemoveColumns( SelectedRows, {"Index"} )
in
RemovedIndexColumns
このクエリでも同じ結果(テーブル)を得ることはできる。しかし、テーブルの行を選択する Table.SelectRows 関数はすべての行を評価するのだから、先頭 10 行という意図をクエリに込めることはできない。要はロジックのミスチョイスで、ファイル全体の読み込みを強制している。
File.Contents(…) を介してファイルシステムに問い合わせるときは、常にファイルの先頭から読み込み、必要あればファイル読込を途中で終了できるということを理解しておけばよいはずだ。
フォーマットが変われば処理も変わる
では、Json.Document( File.Contents(…) ) ならどうなるか。XML フォーマットでも同じなのだけど、ファイル全体を読み込んだ後、フォーマットに合わせてパースしてから初めてテーブルとして扱うことになる。なので、より効率的な行の選択という手段はない。
Excel ファイル(xlsx) をソースデータにするとき Excel.Workbook( File.Contents(…) )、ファイル全体を読み込むことはない。シートごとでデータは保存されアーカイブされているからだ。Excel アプリケーションからであれば特定の行や範囲を指定することはできるだろうけど、Power Query で xlsx ファイルを読み込むときは Excel アプリケーションに依存していない。より効率的な手段を考えるならば、CSV ファイル同等の効果的な行の選択を検討すればよい。
データソースが変われば処理も変わる
たとえば、OneDrive for Businessをデータソースにして、ソースデータを CSV フォーマットとする。このとき、Csv.Document( Web.Content(…) ) というクエリになるのだけど、ファイル全体をダウンロードすることになる。これはデータソースおよびコネクタがサポートしていないのだから仕方がない。動作はこんな感じ Csv.Document( File.Contents( Web.Content(…) ) ) とイメージすることはできる。ローカルにダウンロードしたファイルに対して効率的な行の選択とは?と考えればよい。
特徴のあるデータソースとファイルフォーマット組み合わせの例で、Azure Data Lake Storage + CSV や Parquet であるとき、行の選択を部分的にプッシュできることができる。よ~く確認するとよい。単なるオンライン ファイルストレージではないのである。
クエリフォールディングをサポートするデータソースについても常に確認しながらクエリの記述が必要。行を選択するという意図はデータソースへプッシュできるが、それは可能な限りだ。Table.SelectRows 関数 であっても、行を選択する条件式のすべてがサポートされているわけではない。だから、Power Query エディターで ネイティブ クエリを確認するか、データソースで利用できるプロファイラなどで調査が必須。そもそもクエリフォールディングがサポートされない行の選択もあるし、部分的にサポートされる行の選択もある。
適した関数を使ってる?
Table.SelectRows 関数は行を選択するとき多く使用される手段ではある。しかし、常に使うものではない。
いくつかの行を選択する手段で優先して使ういくつかを列挙するが、要件を満たすのであれば積極的に使うとよい。
ポイントはふたつ
- テーブルに含まれる値を評価する必要がない
- ソースデータがファイルであっても効率的に動作する
Table.FirstN 関数
Table.FirstN( table as table, countOrCondition as any ) as table
countOrCondition パラメータであることがポイント。
Table.FirstN( table , 10 )
Table.FirstN( table , each [Column1] <> null )
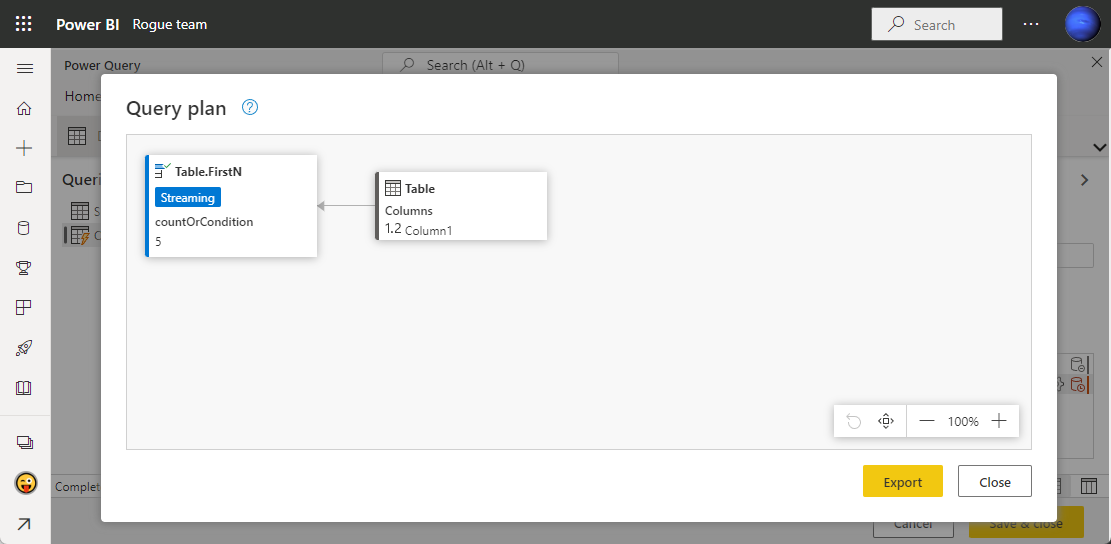
Table.LastN 関数はフルスキャン動作になる。
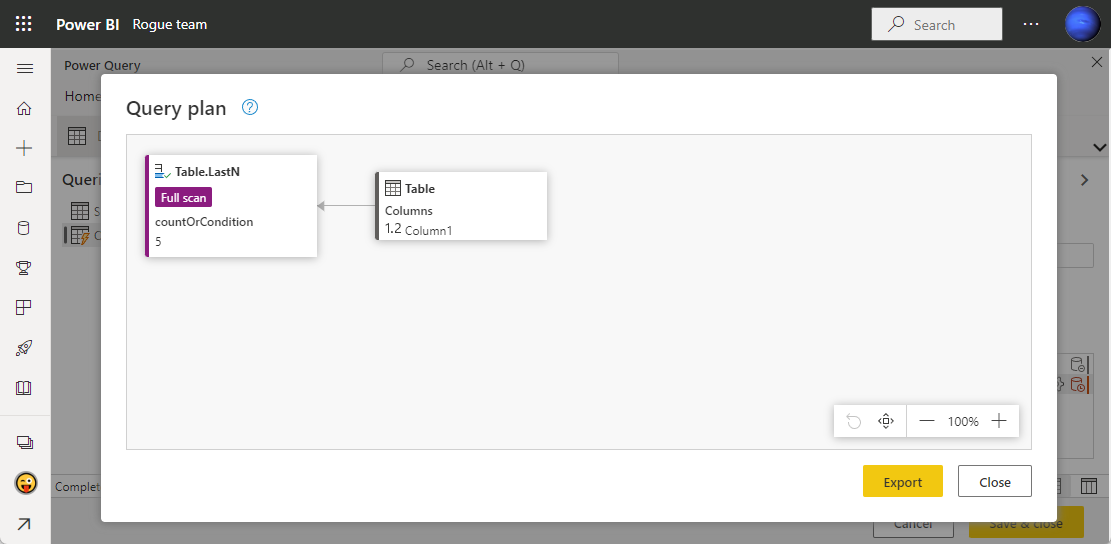
Table.Skip 関数 / Table.RemoveFirstN 関数
Table.Skip( table as table, optional countOrCondition as any ) as table
Table.RemoveFirstN( table as table, optional countOrCondition as any ) as table
Table.Skip( table )
Table.Skip( table, 10 )
Table.Skip( table, each [Column1] <> null )
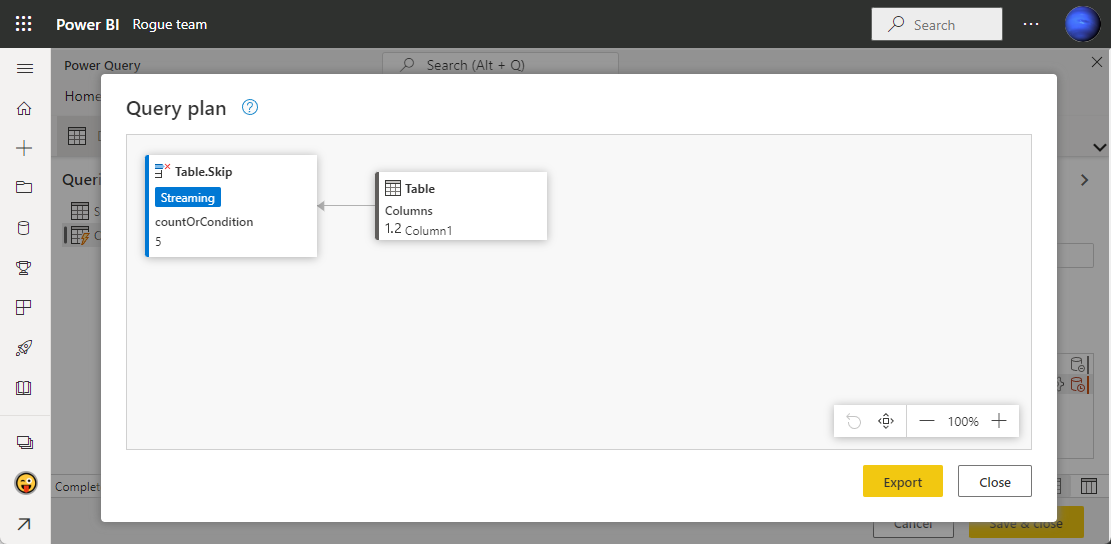
Table.RemoveLastN 関数は本質的に Table.ReverseRows( Table.RemoveFirstN( Table.ReverseRows( … ) ) )
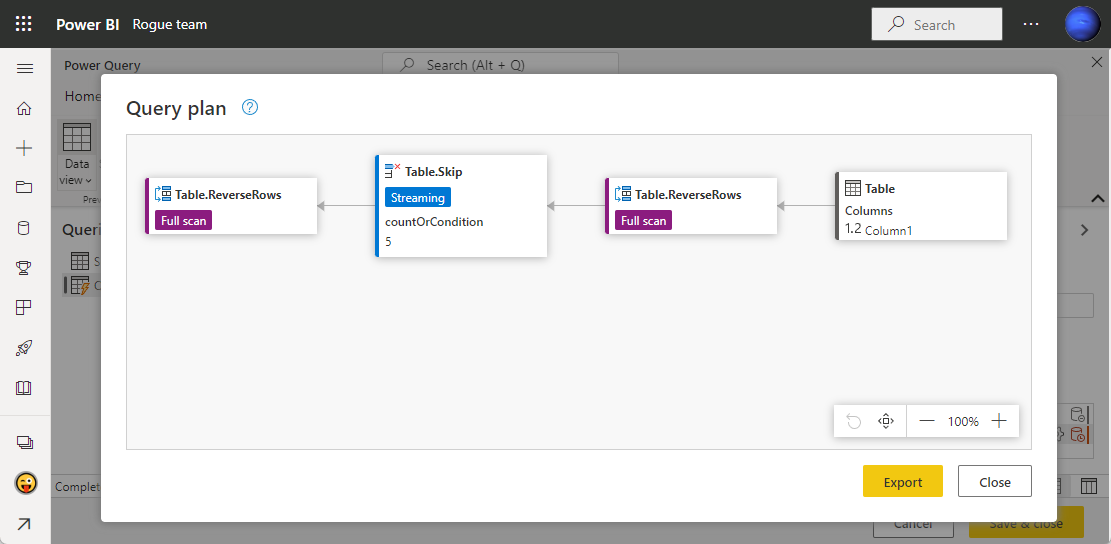
Table.Range 関数
Table.Range( table as table, offset as number, optional count as nullable number ) as table
Table.Range( table, 3, 5 )
本質的には、Table.FirstN( Table.Skip( … ) )
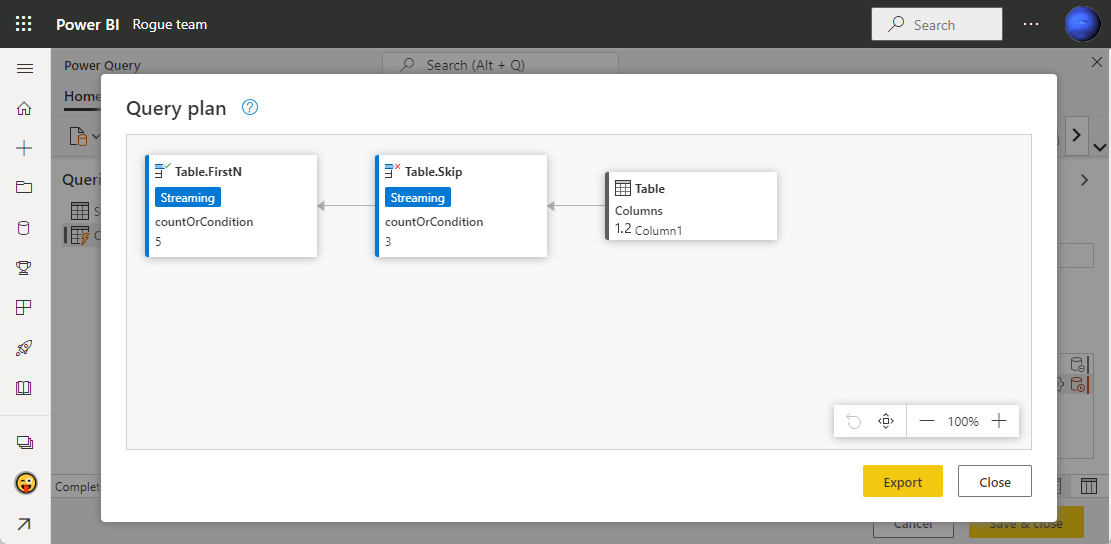
注意すべき行の選択
フルスキャン
フルスキャン動作が必要な行の選択については常に注意を払う必要がある。行の逆順(Reverse)で評価が必要だったり、行の並び替え(Sort)がセットになる関数は意外と多い。重複の削除もフルスキャンが必要になる行の選択だ。
これらの場合、テーブルのグループ化とセットでロジックを検討すると効率のよい行の選択ができることが多い。グループ化することでフルスキャンの範囲を程よく小さくするということだ。
アイテムアクセス
table{<n>} や table{[<record>]} で行にアクセスできるけれども、多くの場合で先頭行からのスキャンになるから注意が必要だ。
たとえば、table{5} は Table.First( Table.Skip( table, 5) ) と同じ動作をする。なので、テーブルのマージ代わりに使ったりすると驚くほどパフォーマンスが低下することがある。
思ったこと🙄
Power Query エディタの使い方/関数の使い方みたいな勉強は必要なんだろうけど、もっと大事なことがたくさんあるよな🤩。
テーブルで話を進めたけれども、リストでも同じ。
その他