はじめに
「クラウドサービスのGoogle Colab」と「ローカルPCのwebカメラ」を利用し、AIにより「モノの認識」が簡単にできたら楽しいと思いませんか?
公開されているモデルを利用することで簡単にそんなことができます。
では、早速やってみましょう!
※Google Colabの使用方法は『0からはじめる「Python AIプログラミング」 for Google Colab』を参照して、簡単に理解しておいてください。
具体的にどんなことをやるか
webカメラからクラウドに映像を取り込み、そこに映ったものは何か、AIに**リアルタイム認識させ、画面にTOP3までを表示します。今回は、学習済みモデル**を利用しますので、時間のかかるAI学習などはありませんので、サクッと遊べます。

※ローカルPC版の『【簡単】webカメラでAI自動認識! for PC』は、こちらです
開発環境準備
Google Colabが全部用意してくれるので、今回はインストールなどはありません。
「Google Colabサービス」を利用するのに「Googleアカウント」が必要なだけです。
| No. | 開発環境 | 説明 |
|---|---|---|
| 1 | Googleアカウント | Google Colab利用のためにGoogleアカウントを使用します。無料です。 |
| 2 | Google Colabサービス | Googleのクラウド仮想マシン上で動くPython実行環境。使用料は無料です。インストール等の作業などは不要です。GPUも無料で使用でき、AI学習も素早く計算が可能です。 |
| 3 | クラアントPC with webカメラ | クライアントPCのwebカメラを使用するため必要です。 |
DenseNet121
簡単って言うからやっているのに、
いきなりDenseNet121と言われて、ワケワカラン!
もうやめだ!
大丈夫です。落ち着いてください。これは学習済みモデルのことで、今回はDenseNet121という学習モデルを使用しますということです。細かいこと分からなくてもできます!

- なぜ
DenseNet121モデルに選定したのか?
kerasライブラリからVGG16、ResNet50など様々な画像分類モデルが簡単に使えるようになっていますが、その中から今回使用する画像分類モデルは、モデルサイズが33MBと比較的小さく認識率も良いためDenseNet121を選びました。「Keras Documentation」によると、DenseNet121でモノを認識させた場合、TOP5までの認識正解率が約92%となるそうです。(TOP1だけだと約75%です)
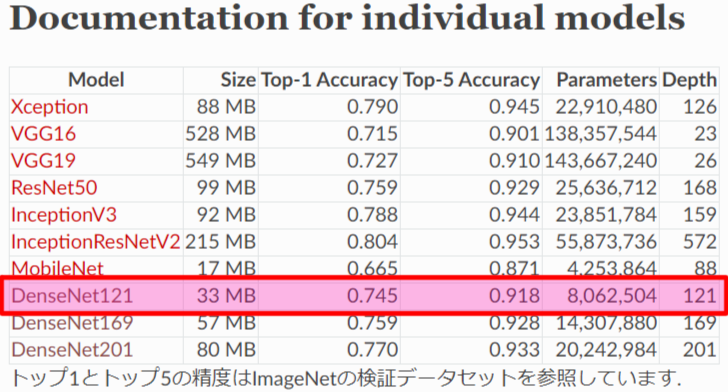
引用元:Keras Documentation
https://keras.io/ja/applications/#documentation-for-individual-models
AIプログラム
今回Google Colab上でローカルPCのwebカメラを扱うプログラムとして、@a2kitiさんの記事(Colab上でwebカメラをリアルタイムに処理)を参考にさせて頂きました😌
下記3つのプログラムを全てGoogle Colabのコード行にコピペし終わったら、[ランタイム]→[すべてのセルを実行]をクリックして、プログラムを実行してください。
●Program1
import IPython
from google.colab import output
from google.colab.patches import cv2_imshow # incompatible with Jupyter notebook
import cv2
import numpy as np
from PIL import Image, ImageDraw
from io import BytesIO
import base64
from keras.applications.densenet import DenseNet121
from keras.applications.densenet import preprocess_input, decode_predictions
from keras.preprocessing import image
model = DenseNet121(weights='imagenet')
def run(img_str):
#decode to image
decimg = base64.b64decode(img_str.split(',')[1], validate=True)
decimg = Image.open(BytesIO(decimg))
decimg = np.array(decimg, dtype=np.uint8);
decimg = cv2.cvtColor(decimg, cv2.COLOR_BGR2RGB)
#############your process###############
# DenseNet121画像判定
resize_frame = cv2.resize(decimg, (300, 224)) # 640x480 -> 300x224(4:3)に画像リサイズ
trim_x, trim_y = int((300-224)/2), 0 # 判定用に224x224へトリミング
trim_h, trim_w = 224, 224
trim_frame = resize_frame[trim_y : (trim_y + trim_h), trim_x : (trim_x + trim_w)]
x = image.img_to_array(trim_frame)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x) # 画像AI判定
# 認識物体名, 認識率 表示用
TXT1 = "[DenseNet121 predict]"
TXT2 = "TOP1 :" + decode_predictions(preds, top=3)[0][0][1] + " : " + str(int(decode_predictions(preds, top=3)[0][0][2] * 100)) + "%"
TXT3 = "TOP2 :" + decode_predictions(preds, top=3)[0][1][1] + " : " + str(int(decode_predictions(preds, top=3)[0][1][2] * 100)) + "%"
TXT4 = "TOP3 :" + decode_predictions(preds, top=3)[0][2][1] + " : " + str(int(decode_predictions(preds, top=3)[0][2][2] * 100)) + "%"
img = Image.fromarray(trim_frame)
draw = ImageDraw.Draw(img)
draw.text((15, 10), TXT1, fill=(255, 255, 255, 0))
draw.text((15, 30), TXT2, fill=(255, 255, 255, 0))
draw.text((15, 50), TXT3, fill=(255, 255, 255, 0))
draw.text((15, 70), TXT4, fill=(255, 255, 255, 0))
img = np.array(img)
# cv2_imshow(img)
out_img = cv2.resize(img, (224*3, 224*3)) # 拡大表示
#############your process###############
#encode to string
_, encimg = cv2.imencode(".jpg", out_img, [int(cv2.IMWRITE_JPEG_QUALITY), 80])
img_str = encimg.tostring()
img_str = "data:image/jpeg;base64," + base64.b64encode(img_str).decode('utf-8')
return IPython.display.JSON({'img_str': img_str})
output.register_callback('notebook.run', run)
●Program2
from IPython.display import display, Javascript
from google.colab.output import eval_js
def use_cam(quality=0.8):
js = Javascript('''
async function useCam(quality) {
const div = document.createElement('div');
document.body.appendChild(div);
//video element
const video = document.createElement('video');
video.style.display = 'None';
const stream = await navigator.mediaDevices.getUserMedia({video: true});
div.appendChild(video);
video.srcObject = stream;
await video.play();
//canvas for display. frame rate is depending on display size and jpeg quality.
display_size = 640
const src_canvas = document.createElement('canvas');
src_canvas.width = display_size;
src_canvas.height = display_size * video.videoHeight / video.videoWidth;
const src_canvasCtx = src_canvas.getContext('2d');
src_canvasCtx.translate(src_canvas.width, 0);
src_canvasCtx.scale(-1, 1);
div.appendChild(src_canvas);
const dst_canvas = document.createElement('canvas');
dst_canvas.width = src_canvas.width;
dst_canvas.height = src_canvas.height;
const dst_canvasCtx = dst_canvas.getContext('2d');
div.appendChild(dst_canvas);
//exit button
const btn_div = document.createElement('div');
document.body.appendChild(btn_div);
const exit_btn = document.createElement('button');
exit_btn.textContent = 'Exit';
var exit_flg = true
exit_btn.onclick = function() {exit_flg = false};
btn_div.appendChild(exit_btn);
// Resize the output to fit the video element.
google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true);
var send_num = 0
// loop
_canvasUpdate();
async function _canvasUpdate() {
src_canvasCtx.drawImage(video, 0, 0, video.videoWidth, video.videoHeight, 0, 0, src_canvas.width, src_canvas.height);
if (send_num<1){
send_num += 1
const img = src_canvas.toDataURL('image/jpeg', quality);
const result = google.colab.kernel.invokeFunction('notebook.run', [img], {});
result.then(function(value) {
parse = JSON.parse(JSON.stringify(value))["data"]
parse = JSON.parse(JSON.stringify(parse))["application/json"]
parse = JSON.parse(JSON.stringify(parse))["img_str"]
var image = new Image()
image.src = parse;
image.onload = function(){dst_canvasCtx.drawImage(image, 0, 0)}
send_num -= 1
})
}
if (exit_flg){
requestAnimationFrame(_canvasUpdate);
}else{
stream.getVideoTracks()[0].stop();
}
};
}
''')
display(js)
data = eval_js('useCam({})'.format(quality))
●Program3
use_cam()
AIプログラム実行

こんな感じにGoogle Colab上でクライアントPCのwebカメラで映した映像が出力され、AIが認識したTOP3の情報が画面に表示されれば成功です。ちなみにうちのワンコ(トイプードル)を映した結果は、下記の様にAIが96%の確率でプードルでしょうと言っている(トイ・プードルでは49%😅)ので、AIの認識はそれなりに正しいものになります😊
【結果の一例】AIの認識率TOP3
- toy_poodle : 49%
- miniature_poodle : 45%
- standard_poodle : 2%
※リアルタイムで認識率は変動します。
識別可能クラス
「imagenet_class_index.json」ファイルを参照すると、イメージデータが以下のNo.0~999の1000クラスに分類ができることが分かります。制限事項にもなりますが、ここに記載が無いものを認識させても、ここの中のどれかにクラス分類されてしまいます。ここに無いものを分類したい場合は、新たにモデルを作るか、転移学習、ファインチューニングなどを調べていただければと思います。
{
"0": ["n01440764", "tench"],
"1": ["n01443537", "goldfish"],
"2": ["n01484850", "great_white_shark"],
"3": ["n01491361", "tiger_shark"],
"4": ["n01494475", "hammerhead"],
"5": ["n01496331", "electric_ray"],
"6": ["n01498041", "stingray"],
"7": ["n01514668", "cock"],
"8": ["n01514859", "hen"],
"9": ["n01518878", "ostrich"],
~ 省略 ~
"990": ["n12768682", "buckeye"],
"991": ["n12985857", "coral_fungus"],
"992": ["n12998815", "agaric"],
"993": ["n13037406", "gyromitra"],
"994": ["n13040303", "stinkhorn"],
"995": ["n13044778", "earthstar"],
"996": ["n13052670", "hen-of-the-woods"],
"997": ["n13054560", "bolete"],
"998": ["n13133613", "ear"],
"999": ["n15075141", "toilet_tissue"]
}
以上
Google Colabだとcv2.imshow()など、cv2の特定メソッドを起動するとクラッシュしてしまうそうで、画像処理させるときには注意が必要です。cv2.imshow()については、Google Colabからパッチが出ている「from google.colab.patches import cv2_imshow」で代替できます。他のメソッドも実行してみてダメなら他の方法で代替するしかないみたいです。ちなみにcv2.resize()は大丈夫でしたが、cv2.putText()はダメでした😥そのためPIL(Pillow)で画像にテキストを描き込んでいます。
話は変わりますが、いまだとバウンディングボックスを表示してくれるyolo Ver5なども公開されていますね。こちらも試してみましたがとても凄いです。AIは発展目覚ましいですね😊
YOLO V5は、こちらの記事で、じゃんけん検出を行っていますので、よろしければご覧になってください。
お疲れ様でした!