➊ はじめに
Power Automate Desktopは、RPA (Robotic Process Automation)です。win11に正式採用になるとのことで、win10のうちにPower Automate for Desktopがどんなものかちょっと使ってみました。
➋ どんな感じ
Power Automate for Desktopを使用して、Qiitaのwebページから、csvファイルのデータを作成してみたいと思います。取得するのは、TOPページにある①記事アドレス、②記事題名、③LGTM数にしました。

※Power Automate Desktop と Power Automate for Desktopでは、少々メニューや文言が変わっているようですが、初歩的なことしかやっていないので、似たような感じでできると思います。win11の方もトライしてみてください。
➌ インストール
以下のURLから、Power Automate for Desktopをインストールします。
ホームページの下方に「Download Power Automate for desktop free」となっているボタンを押下して、インストーラをダウンロードしてください。ダウンロード後、アプリをインストールしてください。

➍ アプリ準備
まずは、アプリの準備をします。
(1) アプリ起動
Power Automate for Desktopアプリを起動します。
起動したら、「+新しいフロー」を押下。

(2) フロー名
フローを作成します。まずはフロー名を付けます。
今回は、フロー名を適当に「qiita」としておきます。後でも変更できます。

「作成」を押下すると自動的にフロー編集画面になります。
(3) フロー編集
これがフロー編集画面です。ここにアクションを追加するなどして、自動実行の命令を入れフローを完成させます。ちなみに、フローとは処理の流れという意味です。
(4) ブラウザ拡張機能
ブラウザからデータを抽出する場合などは、拡張機能が必須になります。Chrome、Edge、Firefoxなど、ブラウザ種類毎に拡張機能をインストールする必要があります。
※IEは、ブラウザ拡張機能のインストールは不要です。
※既にブラウザ拡張機能を一度インストールしている場合は、この工程はスキップできます。
※拡張機能等の詳細は、👉「ここ」をご参照ください。
[ツール]-[ブラウザー拡張機能]-[Microsoft Edge]を押下。

ブラウザ拡張機能のホームページが開きます。
インストールボタンを押下。
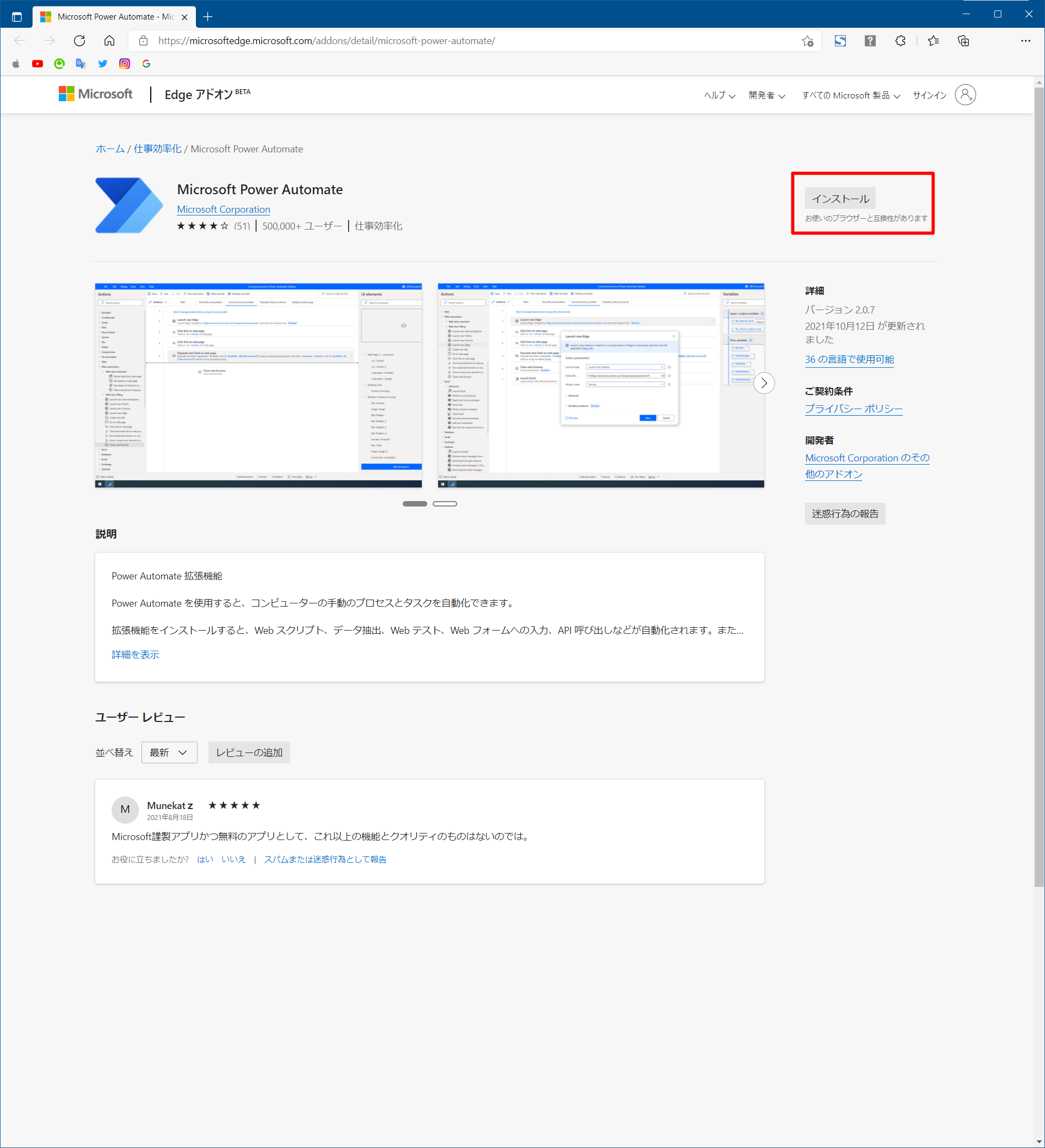
ブラウザ拡張機能がインストールできました。

➎ フロー作成
今回ブラウザはEdgeで実施します。Chrome、Firefox、IEを使っている場合は、適宜読み替えてください。
(1) 新しい Microsoft Edge を起動
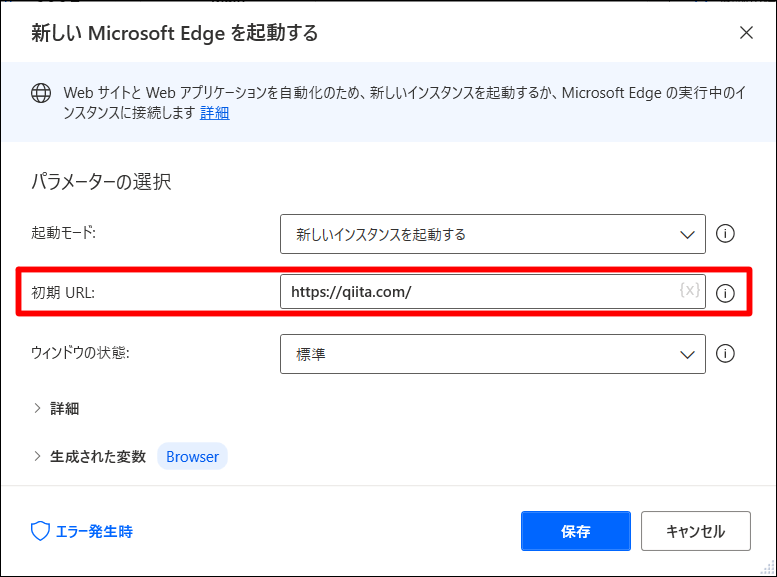
■ アクション
左上のアクションから、[ブラウザー自動化]-[新しい Microsoft Edge を起動する]をMain配下へドラッグアンドドロップします。

■ パラメータ設定
初期URLを「https://qiita.com/」と設定。
(2) Webページを開く
ここで、データ抽出したいホームページを対象のブラウザで開いておきます。
今回は「https://qiita.com/」を開いてください。
(3) Webページからデータを抽出
■ アクション
左上のアクションから、[ブラウザー自動化]-[webデータ抽出]-[Webページからデータを抽出する]をMain配下へドラッグアンドドロップします。

■ パラメータ設定
下記のようになったら、webページの方をクリックして、ブラウザをアクティブにします。

そうすると「ライブwebヘルパー」が自動で出てきます。
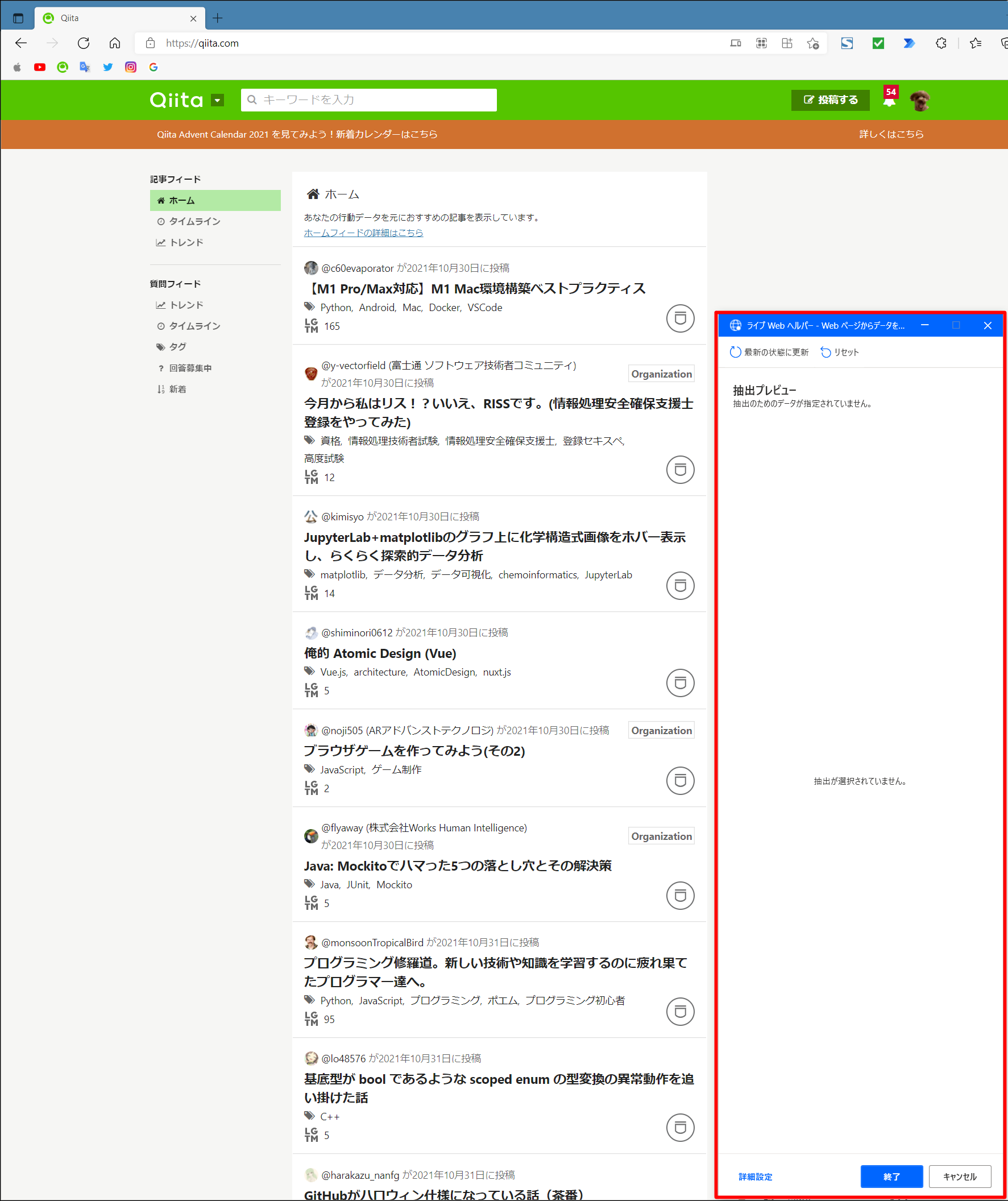
記事題名のところで「右クリック」すると、「要素の値を抽出」-「Href: (https://qita.com…)」というメニューが出るので、それをクリックし、記事のURLを取得します。

続いて、記事題名のところで「右クリック」し、「要素の値を抽出」-「テキスト: …」というメニューが出るので、それをクリックし、記事題名を取得します。

続いて、LGTMの数のところで「右クリック」し、「要素の値を抽出」-「テキスト: …」というメニューが出るので、それをクリックし、LGTM数を取得します。
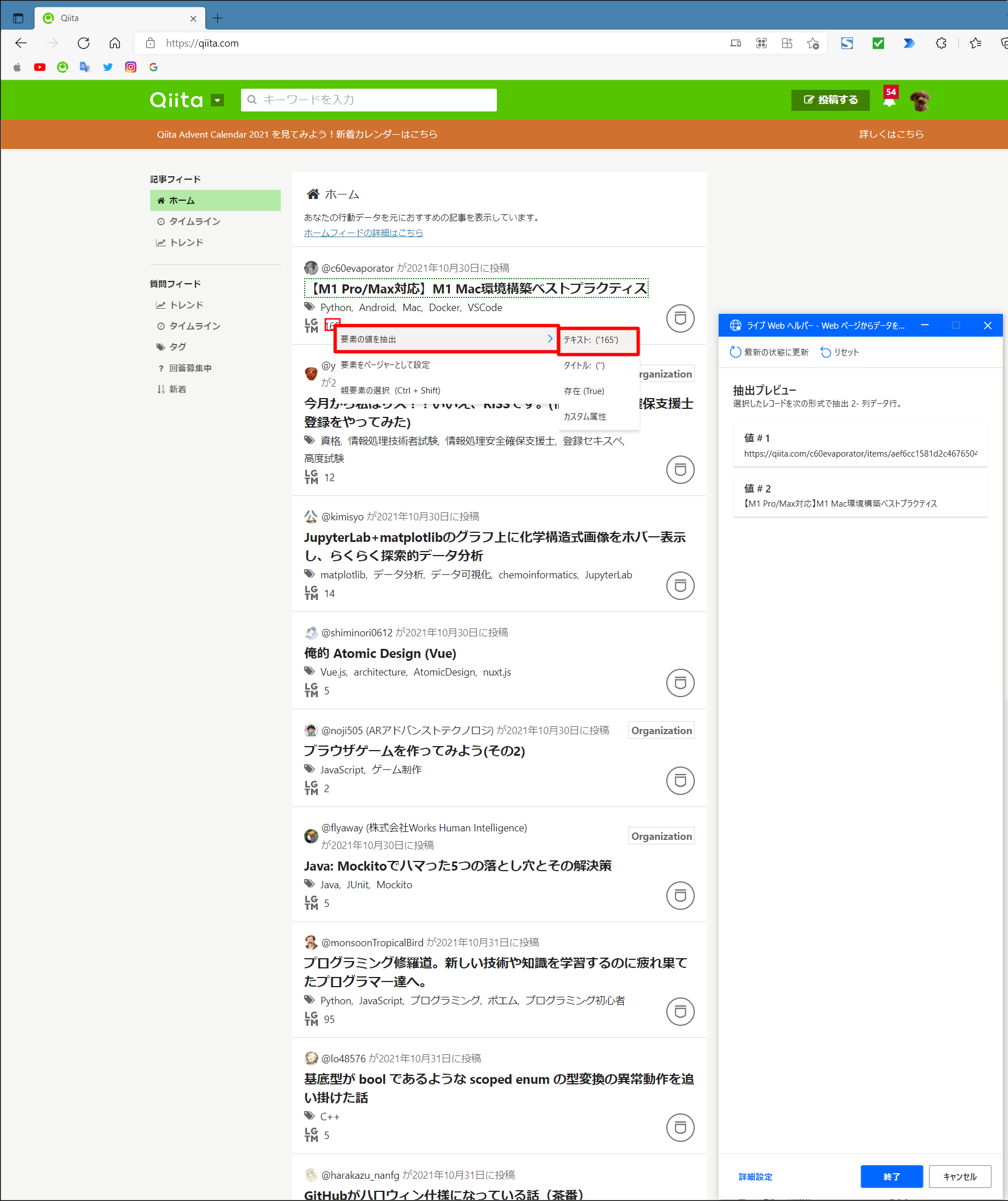
同様に、次の記事題名のところで「右クリック」し、「要素の値を抽出」-「Href: (https://qita.com…)」というメニューが出るので、それをクリックし、記事のURLを取得します。

そうすると表を自動認識し、テーブルが生成されます。

自動でついた"Value #1"などの列名を、"URL"などの正しい列名へ修正します。
※「ライブwebヘルパー」のウィンドウを大きく広げると見やすいです。

あとは、「ライブwebヘルパー」の「終了」を押下すると、「Webページからデータを抽出する」アクションのパラメータ設定画面に戻るので、「保存」を押下してください。
(4) CSV ファイルに書き込み
■ アクション
左上のアクションから、[ファイル]-[CSV ファイルに書き込みます]をMain配下へドラッグアンドドロップします。

■ パラメータ設定
書き込む変数として、Webページからデータを抽出際の変数名を選択します。
今回は、(3) Webページからデータを抽出で「DataFromWebPage」に格納していますので、この変数名を指定します。

出力先のファイル パスを設定します。

「詳細」をクリックして、オプションを確認します。オプションに「列名を含めます」があるので、スイッチ🔛を押して「OFF→ON」に変更します。

設定が終わったら「保存」を押下します。
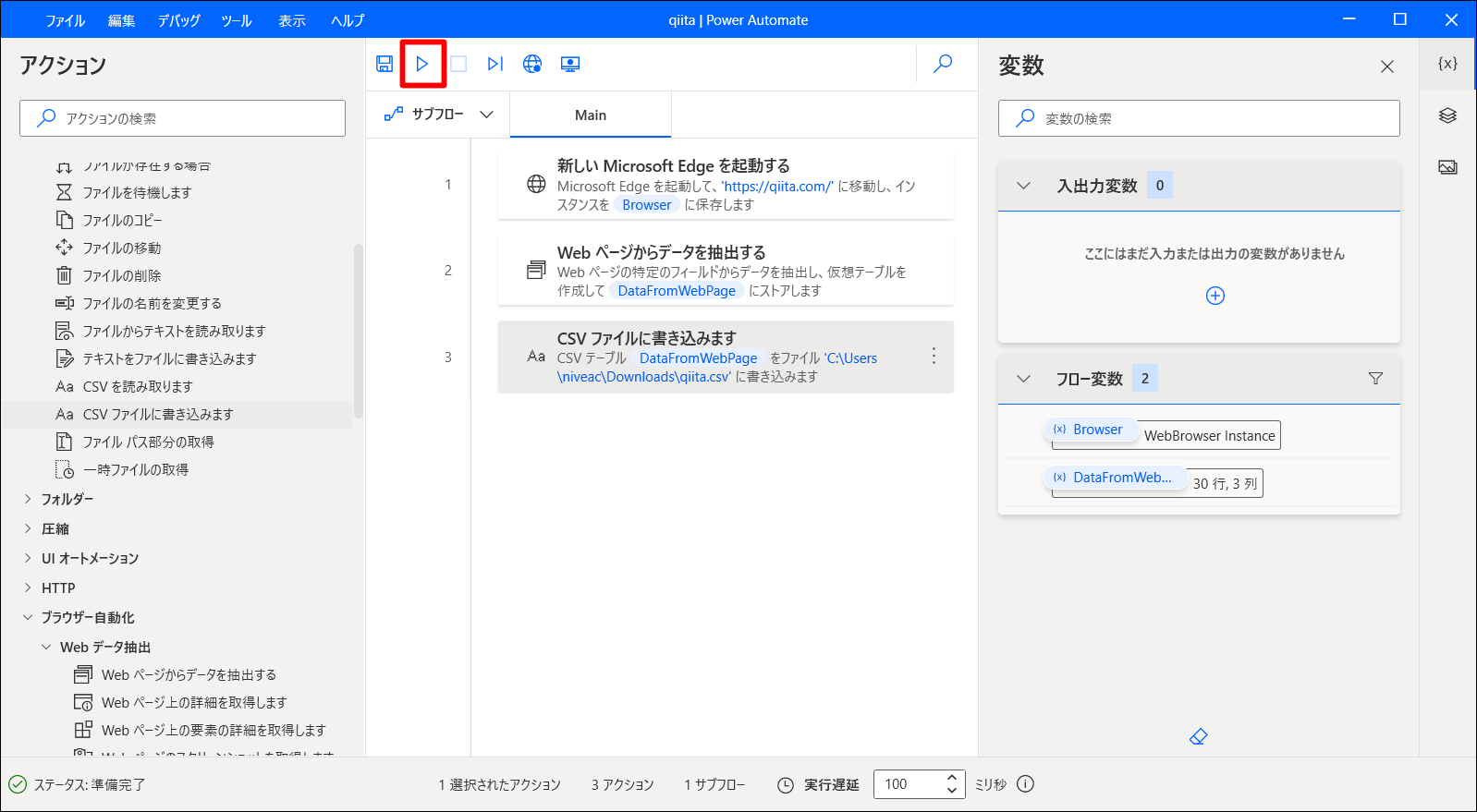
➏ 実行
ここまで完成したら、「▷実行」を押下してください。
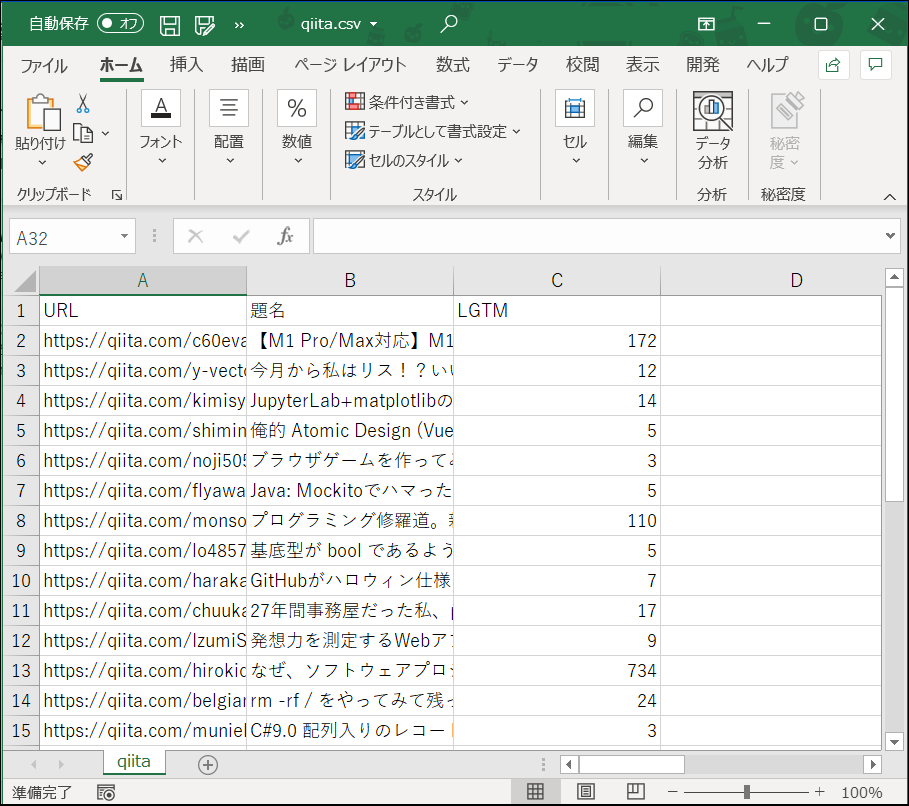
➐ 結果
保存したcsvを開いて確認してみてください。
こんな感じになっていれば、成功です!
➑ 注意
スクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のことです。今回実施した方法は、実際にブラウザを立ち上げてデータを抽出する手順をお試しで1回実施するくらいなのでサーバ側への負担はあまりないと思います。しかし、技術的には、プログラミングによりブラウザを立ち上げなくてもデータ抽出ができます。また、プログラミングなのでパラメータを変えてバンバン実行することができるようになりますが、こうなってくるとサーバ側の負担が大きくなってきます。そのため、スクレイピング禁止を明示しているサイトもあります。そのため、簡易にスクレイピングを行う際でも、注意が必要になります。
■ 禁止サイト例
Yahoo!ファイナンスでは、Yahoo!ファイナンスに掲載している株価やその他のデータを、プログラム等を用いて機械的に取得する行為(スクレイピング等)について、システムに過度の負荷がかかり、安定したサービス提供に支障をきたす恐れがあることから禁止しています。
➒ 以上
コマンド系は自動化しやすく、UI系は自動化しにくいなどありました。しかし、win11で強力なRPAアプリを標準装備することとなり、OFFICE系操作者など開発者以外の人も、簡単に自動化できる時代になってきました。以前はOFFICE作業などの自動化も開発業者へ発注していたけど、これからは事務作業の方もRPA操作を覚えることになりそうですね。大変そうですが、頑張ってください💪!
お疲れ様でした😊