以前からやってみたかったRaspberry Piの物体認識を試してみました。今回はクラウドサービスを使わずに深層学習ライブラリと学習済みモデルを使ってみました。
環境

- Raspberry Pi3 (RASPBIAN JESSIE WITH PIXEL 4.4 / Python 3.4.2)
- LOGICOOL ウェブカム HD画質 120万画素 C270
- ミニロボットPC等用スピーカー小型かわいい白
- 7インチ(1024*600) IPS液晶パネル ディスプレイ
今までカメラモジュールを利用していたのですが、OpenCVでストリーミングをさせるためWebカメラを購入しました。ついでにちょっと可愛らしいロボット型のスピーカーも合わせて買ってみました。
ロボット型のスピーカーがWebカメラに映った物をしゃべってくれます(英語です)。
こんな感じ
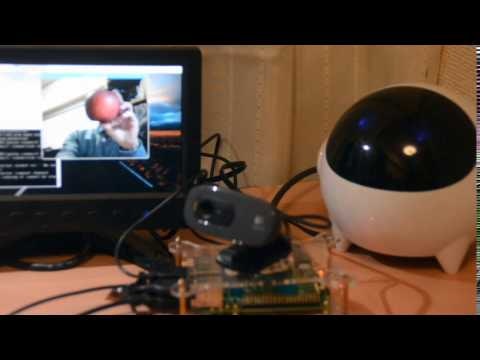
Deep Learning Object Recognition - YouTube
ちょっとレトロな機械音声で話します。

「Apple」と答えるかと思ったら、「Granny Smith(グラニースミス)」というりんごの品種を答えました。アメリカではメジャーな品種の様です。(これは「ふじりんご」です)

iPhoneを見せると「iPod」と認識しました。(学習データがちょっと古いかな?)
ライブラリのダウンロード
以下のサイトを参考にインストールしました。
OpenCV3インストール
Install guide: Raspberry Pi 3 + Raspbian Jessie + OpenCV 3
OpenCVはPython3系で使おうとすると、依存関係がややこしく苦労しました。上記サイトの手順に沿ってインストールするのが一番良いかと思います。
TensorFlowインストール
TensorFlowは標準ではラズパイに対応していませんが、GitHubに公開されているこちらのレポジトリを利用しました。
Keras インストール
Kerasは普通にpipを利用して簡単にインストール出来ます。依存関係のあるライブラリscipyやh5pyは時間がかかるのでsudo apt-getでインストールするのが良いかと思います。
学習済みモデルの利用
メイン開発者のFrançois Cholletさんがチュートリアルを公開してくれています。
fchollet/deep-learning-models - GitHub
こちらをクローンしてくれば、物体認識を試してみることが出来ます。今回は驚異の認識率96.6%を誇る学習モデルInceptionV3を利用しました。
サンプルでは学習済みモデルh5と、ラベル一覧jsonをダウンロードしてくる様になっていますので(ラベルが約1,000種類もある)、これはダウンロードしてしまい、同じ階層に設置します。
deep-learning-models
├── imagenet_class_index.json
├── imagenet_utils.py
├── inception_v3.py
├── inception_v3_weights_tf_dim_ordering_tf_kernels.h5
├── inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
├── inception_v3_weights_th_dim_ordering_th_kernels.h5
└──inception_v3_weights_th_dim_ordering_th_kernels_notop.h5
学習させるには膨大な時間がかかる様ですが(深層学習用のPCで1ヶ月位かかるとか)学習済みモデルをファイルで設置すれば、ラズパイでも1、2秒で画像認識してくれます。
少し改造する

$ cd deep-learning-models
$ python3 inception_v3.py
Using TensorFlow backend.
Predicted: [[('n02504013', 'Indian_elephant', 0.87686646), ('n01871265', 'tusker', 0.044712357), ('n02504458', 'African_elephant', 0.02874627), ('n02398521', 'hippopotamus', 0.0072720782), ('n02092339', 'Weimaraner', 0.0020943223)]]
画像を解析すると、「ラベル番号・ラベル名・予測値」が多次元配列で返ってくるので、326、327行目(最後の2行)を以下の様に置き換えます。
preds = model.predict(x)
recognize = decode_predictions(preds)
print('Label:', recognize[0][0][1])
これで一番予測値の高いラベルを取り出せます。
Label: Indian_elephant
OpenCVの画像を解析する
OpenCVの画像はBGRのNumPy配列となり、処理が面倒なので、今回は単純にsキー押下で画像を保存する様にしました。
316行目からのif __name__ == '__main__':以降を以下の様に書き換えます。
import cv2
if __name__ == '__main__':
model = InceptionV3(include_top=True, weights='imagenet')
cam = cv2.VideoCapture(0)
while(True):
ret, frame = cam.read()
cv2.imshow("Show FLAME Image", frame)
k = cv2.waitKey(1)
if k == ord('s'):
cv2.imwrite("output.png", frame)
img_path = "output.png"
img = image.load_img(img_path, target_size=(299, 299))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
recognize = decode_predictions(preds)
print('Label:', recognize[0][0][1])
elif k == ord('q'):
break
cam.release()
cv2.destroyAllWindows()
画像の変換はサンプルコードをそのまま利用しました。
音声発話させる
本当はラベルを日本語に変換したかったのですが、今回は断念し、英語ラベルをそのまま発話させます。ラズパイの英語での発話はlinuxのソフトeSpeak text to speechが簡単です。
$ sudo apt-get install espeak
$ espeak "This is a test"
これでラズパイに英語を喋らせることが出来ます。上記の22行目以降に以下を追記します。
# linuxコマンドを使うためにsubprocessをインポートしておく
import subprocess
# 22行目以降に以下を追記
speak = "This is a " + recognize[0][0][1]
subprocess.check_output(["espeak", "-k5", "-s150", speak])
print(speak)
まとめ
クラウドサービスのAPIを使わずにラズパイで物体認識が出来ました。ネット接続がないトイロボットなどにも組み込むことができると思います。
認識できるラベルがかなり豊富にあるので、これらの一部を日本語化するだけでも色んなものが認識が可能かなと思いました。(上記のGranny_Smithをりんごに変換したりとか)
今回は学習済みモデルを利用してみたので、自分で用意した画像の学習にも挑戦してみたいですね。では。
追記:2016/12/31
なんか気になってしまったので日本語化してみました(大晦日だというのに…)。
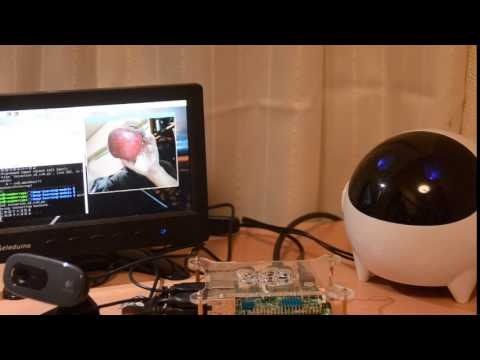
日本語で物体認識しました。
ラベルを日本語化
以前、Pokémon GOのモンスター名を日本語化したのと同じく、以下の様なjsonファイルを作りました。(利用したい方がいらっしゃったら、ご自由にお使いください)
サッとプログラミングを組んで翻訳出来れば格好良いのですが…。CSVファイルに落としたものを、Googleのスプレッドシートを使って翻訳して(GOOGLETRANSLATE)、翻訳がイマイチな部分をちまちまと手作業で直しました。
翻訳はこんな感じでいけるだろうと考えました。
import sys
import json
with open('imagenet_class_index.json', 'r') as f:
obj = json.load(f)
for i in obj:
if i['en'] == sys.argv[1]:
print(i['ja'])
実行してみます。
$ python3 app.py goldfish
金魚
うまくいきました。
日本語で音声発話させる
これはOpenJTalkを使えば良いと思い。こちらの記事(OpenJTalk + python で日本語テキストを発話 - Qiita)を参考にしてみました。
ただ、Python3だとエラーになっていまい、ひとしきり悩みました。
import sys
import subprocess
def jtalk(t):
open_jtalk=['open_jtalk']
mech=['-x','/var/lib/mecab/dic/open-jtalk/naist-jdic']
htsvoice=['-m','/usr/share/hts-voice/mei/mei_happy.htsvoice']
speed=['-r','1.0']
outwav=['-ow','open_jtalk.wav']
cmd=open_jtalk+mech+htsvoice+speed+outwav
c = subprocess.Popen(cmd,stdin=subprocess.PIPE)
c.stdin.write(t)
c.stdin.close()
c.wait()
aplay = ['aplay','-q','open_jtalk.wav']
wr = subprocess.Popen(aplay)
text = 'こんにちは'.encode('utf-8')
jtalk(text)
Python3系になってから文字列がstrになったので、この様にコマンドラインの引数として日本語を利用する際はエンコードが必要な様です。
テキストを.encode('utf-8')を使ってエンコードしたら上手くいきました。
こんな感じ

「リンゴ」と認識しました。これで子供も遊べるかな?

「iPhone」と認識しました。
プログラムはこんな感じです。316行目からのif __name__ == '__main__':以降を以下の様に書き換えます。
# 必要なモジュールはあらかじめインポートしておいてください
import cv2
import subprocess
import json
import sys
# 以下を316行目から書き換え
if __name__ == '__main__':
model = InceptionV3(include_top=True, weights='imagenet')
def jtalk(t):
open_jtalk=['open_jtalk']
mech=['-x','/var/lib/mecab/dic/open-jtalk/naist-jdic']
htsvoice=['-m','/usr/share/hts-voice/mei/mei_happy.htsvoice']
speed=['-r','1.0']
outwav=['-ow','open_jtalk.wav']
cmd=open_jtalk+mech+htsvoice+speed+outwav
c = subprocess.Popen(cmd,stdin=subprocess.PIPE)
c.stdin.write(t)
c.stdin.close()
c.wait()
aplay = ['aplay','-q','open_jtalk.wav']
wr = subprocess.Popen(aplay)
cam = cv2.VideoCapture(0)
while(True):
ret, frame = cam.read()
cv2.imshow("Show FLAME Image", frame)
k = cv2.waitKey(1)
if k == ord('s'):
cv2.imwrite("output.png", frame)
img_path = "output.png"
img = image.load_img(img_path, target_size=(299, 299))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
recognize = decode_predictions(preds)
recognize_rabel = recognize[0][0][1]
with open('imagenet_class_index.json', 'r') as f:
obj = json.load(f)
for i in obj:
if i['en'] == recognize_rabel:
print('これは' + i['ja'] + 'だよ')
text = 'これは' + i['ja'] + 'だよ'
text = text.encode('utf-8')
jtalk(text)
elif k == ord('q'):
break
cam.release()
cv2.destroyAllWindows()
もう一度まとめ
「人工知能を使って、こんなことできないかなあ。」って思ってたことが今年の内に出来たので、良しとします。それでは皆様、良いお年を。