以前、こんな動画を投稿しました。
【第三回ひじき祭】Unityでもいっぱいオブジェクトを動かしたい!
コメントで「性能比較がほしい」というようなものをいただきましたので、せっかくなのでコンピュートシェーダを使わない実装と実行時間の比較をとってみたいと思います。
環境
- CPU: Intel Core2Quad Q9450
- GPU: NVIDIA GeForce GTX 650
- OS: Microsoft Windows 10 Home
- Unity: Unity 2017.3.0f3
方法
動画内で実装した全GPUバージョンと、コンピュートシェーダを用いないCPUバージョン(描画のみGPU)との比較となります。
パーティクルのスポーンは、秒間のスポーン数をできるだけFPSによらず一定にしたいためFixedUpdate内で処理を行います。
結果
コードはこちら => https://github.com/Pctg-x8/ParticleBench
CPUの実装を急いで書き起こしたのでちょっとフェアな比較じゃないかもしれないですが、おおむね同じ実装のはずです(インスタンスデータの空き管理だけ最小バイナリヒープに変更しています)。
GPUパーティクルのスポーンは「ひとつずつ」と「まとめて(Batched)」の二つの方法が存在するので(念のため)両方計測しています1。
Preparing Timeは***LineParticleDriver.OnPreRender()とFixedUpdate.ScriptRunBehaviourFixedUpdateの合算(パーティクルの生成から更新まで)、Drawing Timeは
- CPUの場合は"
Graphics.DrawProcedural(CPULineParticleDriver.OnPostRender())"- 描画本体の時間と
SetPassなどを含めた時間
- 描画本体の時間と
- GPUの場合は
CommandBuffer.BeforeImageEffects- 描画コマンドの実行時間
をそれぞれ表示しています。数値はすべてProfilerウィンドウから、平均と思われる点をピックしています。
1 Particle/FixedUpdate(50 Particles/s)
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 0.09ms | 0.01ms(0.46ms) |
| GPU | 0.04ms | 0.01ms |
| GPU Batched | 0.04ms | 0.02ms |
10 Particles/FixedUpdate(500 Particles/s)
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 0.57ms | 0.13ms(4.27ms) |
| GPU | 0.04ms | 0.01ms |
| GPU Batched | 0.04ms | 0.02ms |
100 Particles/FixedUpdate(5,000 Particles/s)
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 11.39ms | 1.44ms(38.86ms) |
| GPU | 0.07ms | 0.02ms |
| GPU Batched | 0.09ms | 0.01ms |
1,000 Particles/FixedUpdate(50,000 Particles/s)
このあたりでCPUは限界です
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 559.57ms | 14.84ms(397.23ms) |
| GPU | 0.46ms | 0.02ms |
| GPU Batched | 0.41ms | 0.02ms |
5,000 Particles/FixedUpdate(250,000 Particles/s)
このあたりが性能限界というか妙なバグかなにかで思ってる通りにパーティクルが動かなくなります
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 2,415.69ms | 76.21ms(1,964.07ms) |
| GPU | 3.77ms | 0.12ms |
| GPU Batched | 3.07ms | 0.02ms |
10,000 Particles/FixedUpdate(500,000 Particles/s)
| Preparing Time | Drawing Time | |
|---|---|---|
| CPU | 5,018.98ms | 142.07ms(3,997.58ms) |
| GPU | 11.47ms | 0.03ms |
| GPU Batched | 8.78ms | 0.07ms |
グラフ
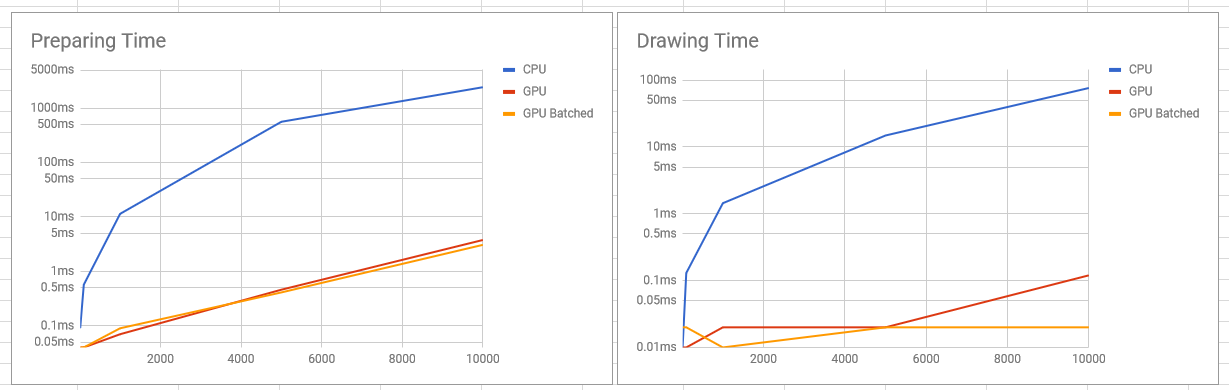
CPU実装のインフレがすごかったので縦軸を両方とも対数スケールにしています。
考察/所感
- GC Alloc: 0.77GBとか初めて見た(10,000Particles/FixedUpdateのCPU実装)
- 瞬間に大量に出す場合にGPU実装側では最適な実装をしているつもりだったけど、あんまり変わらないのでいらなかったかもしれない(でも便利なので使う)
- CPU実装のDrawing Timeが思っていた以上にパーティクル数と比例してくれていたのでうれしい(?
- GPU実装の場合はデータコピーがほとんど発生しないとかGPU/CPUの通信量が抑えられるとかでなんとなく高速化するだろうなと思っていたけど今回それなりに実証できたので安心
- というよりC#で配列のスライシングができないのがはげるほどつらすぎる2
- 意外にCPUは瞬間に大量に出すほど性能劣化がなくなっていくみたいなので(単に処理落ちして正しく計測できていない可能性)そういった用途では意外といけるかも?(とは
- コマンドバッファはやっぱり速い というよりインスタンシングが速い コマンド発行はやっぱり遅い
- CPU実装はもうちょっと早くできるかも
- DrawProceduralのインスタンシングがなんかうまくいかなかったので、今回のバージョンではパーティクル一つずつSetPassしてDrawしているので地獄
おまけ
実際に瞬間一万パーティクルも出す場面ないでしょとは思いつつ、GC Allocが0.77GBはちょっとさすがにおバカすぎるのでインスタンスデータをstructにして減らせないか試してみました。あとメモリアロケーションも抑えられるので予想ではちょっとくらい早くなるはず(たぶん)。
結果: 5,000 Particles/FixedUpdate
| Preparing Time | |
|---|---|
| CPU class | 2,415.69ms |
| CPU struct | 2,147.98ms |
思ったほど変わらなかった......
考察
InstanceDataを生成する部分だけプロファイルを限定して取ってみたところ、InstanceDataの生成の5倍くらいの回数メモリアロケーションがスポーン処理のどこかで発生しているみたいでした。まあスポーン処理でデータ生成以外ってなるとほぼ絶対にBinaryHeapの実装がマズっているのは確実なので、これが分かっただけでも今回の計測は収穫大でした。まあ、もっともこのBinaryHeapは現在どのプロジェクトでも使ってないんですが。