概要
本記事では、普段 Docker をブラックボックスとして扱っている方々を対象として、コンテナが動く仕組みを低レイヤーから解説します。
そのために Go 言語を使って、ゼロからコンテナを実装し動かしながら学ぶアプローチを取ります。コンテナの基礎的な原理は意外にも簡単で、この記事の最後に出来上がるコードは僅か 60 行ほどです。
なお、完成したコードは GitHub レポジトリに置かれています。
コンテナとは何か
コンテナと仮想マシン (VM) の違いを説明する際に、よく次のような図が使われます。
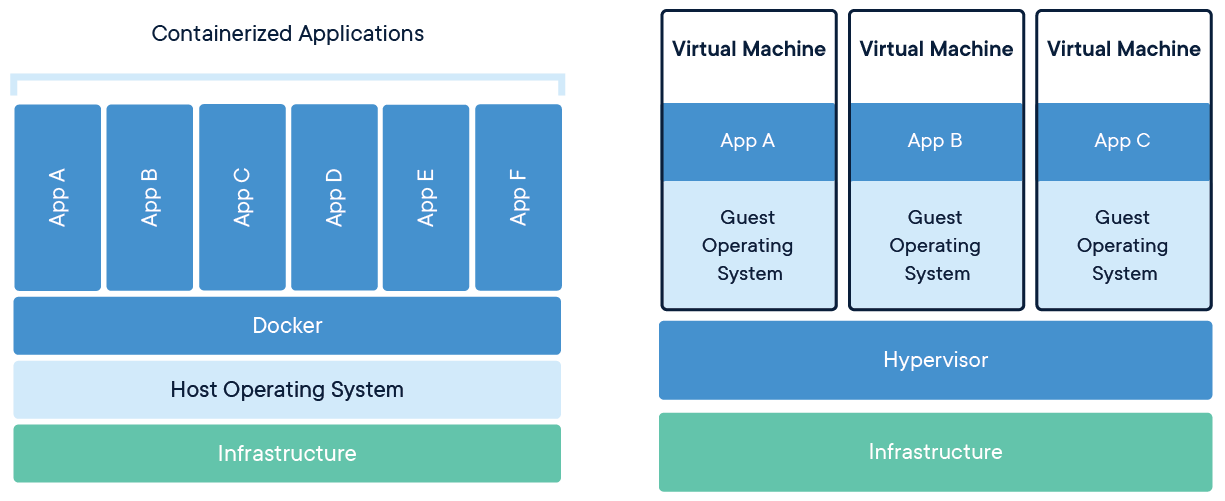
(Docker 公式サイトより引用)
VM とコンテナを比較した時の最大の特徴は、一つ一つのコンテナを作る際にゲスト OS を起動しないことです。
コンテナは全て、同じホスト OS の中で動くプロセスとして存在します。
しかし当然ながら、通常のプロセスはファイルなどのリソースを他のプロセスと共有しており、環境依存性を強く持ちます。
そこで、プロセスを論理的に隔離された状態で動かすために、 Linux カーネル の持つ chroot や namespace などの機能を利用します。これにより 隔離されたプロセス のことをコンテナと呼びます。
Linux カーネルとは何か
カーネルとは、文字通り OS の中核に当たる重要な部分です。
Linux マシンを次のような 3 層構造と捉えた時、カーネルはちょうど中間に位置します。
- ハードウェア : メモリや CPU などの物理デバイス
- Linux カーネル
- ユーザープロセス : シェルやエディターなど、ほぼ全てのプログラム
カーネルはハードウェアを直接操作できる特権を持ち、メモリーやプロセスの管理、デバイスドライバーなどの仕事を行います。
一方で、ユーザープロセスはハードウェアに対するアクセスが大きく制限されています。そのため、ファイル操作やプロセス作成などを実行するには、システムコールを通じてカーネルに依頼しなければなりません。
コンテナを作成するプログラムを実装する際にも、 chroot や namespace などを利用するためにシステムコールを多用します。
特に Go 言語のコードでシステムコールを行う場合には、公式パッケージ golang.org/x/sys を使うのが標準的です。
ゼロからのコンテナ実装
以降では Go 言語のプログラムで実際にコンテナを作成します。
コードを実行するためには、 Go コンパイラがインストールされた Linux 環境が必要です。 GitHub レポジトリに含まれている docker-compose.yml ファイルを使えば、環境構築の手間無しですぐに試すことができます。
$ git clone
$ cd minimum-container
$ docker-compose run app
root@linux-env:/work_dir# go run main.go run sh
chroot
chroot は、現在実行中のプロセス(と子プロセス)のルートディレクトリを変更します。そのディレクトリより上の階層にはアクセスできず存在を認識することもできない状態になるため、俗に chroot 監獄と呼ばれます。
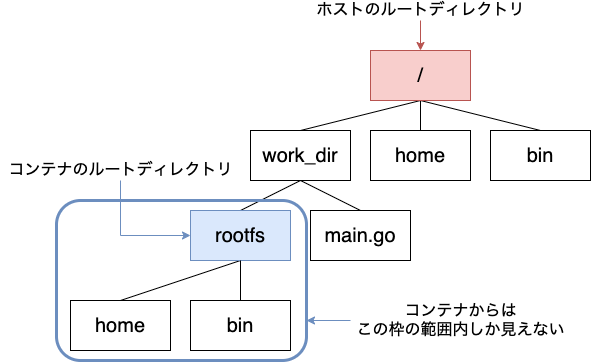
GitHub レポジトリの chroot ブランチ に、 chroot を使ったコンテナもどきのコード例があります。これはルートディレクトリを ./rootfs に変更した上で、与えられた引数をコマンドとして実行します。
// 隔離されたプロセスの中で cmd を引数 arg と共に実行
func execute(cmd string, args ...string) {
// ルートディレクトリとカレントディレクトリを ./rootfs に設定
unix.Chroot("./rootfs")
unix.Chdir("/")
command := exec.Command(cmd, args...)
command.Stdin = os.Stdin
command.Stdout = os.Stdout
command.Stderr = os.Stderr
command.Run()
}
早速この main.go を実行してみると、次のようなエラーが発生するはずです。
$ go run main.go run sh
panic: exec: "sh": executable file not found in $PATH
これは、まだ ./rootfs に何もファイルが入っていないために起きるエラーです。 chroot 実行後のコンテナ内では、ルートディレクトリが空の状態と同然のため、 sh のバイナリすら有りません。
そこで便利なのが docker export です。下記のコマンドを打ち込むと、任意の Docker イメージに含まれる全ファイルを ./rootfs の下に展開することができます。
$ docker export $(docker create <イメージ>) | tar -C rootfs -xvf -
.rootfs にファイルを用意した状態で、改めてコンテナを実行してみましょう。 ls コマンドを使ったり、ファイルを作成したりして、コンテナ内の / ディレクトリがホストの rootfs ディレクトリとリンクしていることを確かめてみてください。
root@linux-env:/work_dir# go run main.go run sh
/ # ls /
bin dev etc home proc root sys tmp usr var
/ # touch /tmp/hoge
/ # exit
root@linux-env:/work_dir# ls rootfs/tmp
hoge
namespace
Linux namespace は、マウントファイルシステムや PID など諸々のリソースを隔離できる機能です。
この機能の必要性を理解するために、前節で作成したコンテナもどきの中で ps コマンドを実行してみましょう。
root@linux-host:/work_dir# go run main.go run ps
PID USER TIME COMMAND
結果は何も表示されないはずです。その原因は ps コマンドが /proc ディレクトリを参照していることにあります。通常 /proc ディレクトリには、プロセス情報などを取得できる特殊な擬似ファイルシステムがマウントされていますが、コンテナもどきの中ではルートディレクトリを変更しているので /proc にはまだ何も有りません。
事前に /proc ディレクトリをマウントして ps を再度実行してみましょう。
root@linux-host:/work_dir# go run main.go run sh
/ # mount proc /proc -t proc
/ # ps
PID USER TIME COMMAND
1 root 0:00 bash
100 root 0:00 go run main.go run sh
154 root 0:00 /tmp/go-build474892034/b001/exe/main run sh
160 root 0:00 sh
163 root 0:00 ps
ここで問題が二つ生じます。一つはコンテナ外で動いているプロセス (PID 1, 100, 154) が見えている点、もう一つは、コンテナ内で設定したマウントがホストにも反映される点です。これでは外部環境からの隔離が充分とは言えません。
root@linux-host:/work_dir# cat /proc/mounts | grep proc
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
proc /work_dir/rootfs/proc proc rw,relatime 0 0 <- コンテナ内で追加した proc マウント
Linux namespace を使うと、リソースの名前空間をプロセス単位で別々に設定することができます。異なる名前空間に属するリソースは見ることも操作することもできないため、前述の問題が解決されます。
記事執筆時点で Linux namespace は 8 種類存在し、システムコールの clone, setns, unshare などでフラッグを指定します。
| 名前空間 | フラッグ | 隔離されるリソース |
|---|---|---|
| Mount | CLONE_NEWNS | ファイルシステムのマウントポイント |
| PID | CLONE_NEWPID | PID |
| UTS | CLONE_NEWUTS | ホスト名 |
| Network | CLONE_NEWNET | ネットワークデバイスやポートなど |
| Time | CLONE_NEWTIME | clock_gettime で取得できる時刻 (monotonic, boot) |
| IPC | CLONE_NEWIPC | プロセス間通信 |
| Cgroup | CLONE_NEWCGROUP | cgroup ルートディレクトリ |
| User | CLONE_NEWUSER | UID, GID |
Go 言語で Linux namespace を設定するには、 Cmd 構造体の SysProcAttr に Cloneflags をセットします。実際に Mount, PID, UTS namespace を使ってコンテナを作成する例が GitHub レポジトリの namespace ブランチ にあります。
func execute(cmd string, args ...string) {
unix.Chroot("./rootfs")
unix.Chdir("/")
command := exec.Command(cmd, args...)
command.Stdin = os.Stdin
command.Stdout = os.Stdout
command.Stderr = os.Stderr
// Linux namespace を設定
command.SysProcAttr = &unix.SysProcAttr{
Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS,
}
command.Run()
}
このコードで改めてコンテナを作成し、先程と同様に ps を実行すると、コンテナ内のプロセスだけが表示されることを確認できます。
root@linux-host:/work_dir# go run main.go run sh
/ # mount proc /proc -t proc
/ # ps
PID USER TIME COMMAND
1 root 0:00 sh
4 root 0:00 ps
また、 UTS namespace によって、コンテナ内でホスト名を変更しても外部に影響しなくなりました。
root@linux-host:/work_dir# go run main.go run sh
/ # hostname my-container
/ # hostname
my-container
/ # exit
root@linux-host:/work_dir# hostname
linux-host
コンテナの初期化
前節では、コンテナを立ち上げた後に手動で /proc のマウントやホスト名の設定をしていました。このままでは不便なので、コンテナ作成と同時にこれらの初期化処理も行うようにプログラムを変更しましょう。
ここで問題となるのが、初期化を実行するタイミングです。コンテナ作成は
- namespace を設定した子プロセスを作成
- 子プロセスを初期化 (
/procマウントなど) - ユーザー指定のコマンド (
shなど) を実行
という順序で行う必要がありますが、 1. と 3. の間に割り込めるフックなどは存在しません。そこで、 2. と 3. を両方とも実行するコードを書き、 namespace を設定したプロセス上でそのコードを実行します。
実装例は GitHub レポジトリの reexec ブランチ です。
// コマンドライン引数の処理
// go run main.go run <cmd> <args>
func main() {
switch os.Args[1] {
case "run":
initialize(os.Args[2:]...)
case "child":
execute(os.Args[2], os.Args[3:]...)
default:
panic("コマンドライン引数が正しくありません。")
}
}
// Linux namespace を設定した子プロセスで、execute 関数を実行する
func initialize(args ...string) {
// このプログラム自身に引数 child <cmd> <args> を渡す
arg := append([]string{"child"}, args...)
command := exec.Command("/proc/self/exe", arg...)
command.Stdin = os.Stdin
command.Stdout = os.Stdout
command.Stderr = os.Stderr
command.SysProcAttr = &unix.SysProcAttr{
Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS,
}
command.Run()
}
// namespace 設定後の初期化処理と、ユーザー指定のコマンドを実行する
func execute(cmd string, args ...string) {
// ルートディレクトリとカレントディレクトリを ./rootfs に設定
unix.Chroot("./rootfs")
unix.Chdir("/")
unix.Mount("proc", "proc", "proc", 0, "")
unix.Sethostname([]byte("my-container"))
command := exec.Command(cmd, args...)
command.Stdin = os.Stdin
command.Stdout = os.Stdout
command.Stderr = os.Stderr
command.Run()
}
一つの実行ファイルで完結させるために、少しトリッキーな方法を使っています。ポイントは initialize 関数の中で /proc/self/exe をコマンドとして実行している部分です。/proc/self/exe も proc ファイルシステムの一部で、現在のプロセスの実行ファイルのパスを返します。これを利用して、プログラムが自分自身を再帰的に実行することができます。
上記コード実行時の流れを順に追っていくと
- コマンド
go run main.go run <cmd> <args>を実行 - main.go が実行され
initialize関数に分岐 - namespace を設定したプロセスを作成
- コマンド
/proc/self/exe init <cmd> <args>を実行 - main.go が実行され
execute関数に分岐 -
/procマウントなどの初期化処理を実行 - プロセスを作成
- ユーザー指定のコマンドを実行
- コマンド
この時、ユーザーコマンド実行のために作られる孫プロセスにも ルートディレクトリと namespace の設定が継承され、コンテナとして機能します。
コンテナの標準仕様
以上でコンテナの基礎に当たる機能を実装できましたが、まだ欠けている部分がたくさんあります。この記事で全てを詳細に説明することはできませんが、大まかな全体像を伝えるために重要な標準仕様を 2 つ紹介します。
| 仕様 | 代表的な実装 |
|---|---|
| OCI Runtime Specification | runc |
| OCI Image Format Specification | containerd |
OCI Runtime Spec はコンテナのライフサイクルと filesystem bundle のフォーマットを規定します。filesystem bundle とは、コンテナの各種設定値を記載した config.json と、ルートファイルシステムとなる rootfs ディレクトリをまとめて tar アーカイブにしたものです。
一方で OCI Image Spec は、コンテナイメージのフォーマットと、イメージを filesystem bundle に変換する方法を規定します。イメージとは、 Dockerfile をビルドして得られるお馴染みのあのイメージのことです。

filesystem bundle に rootfs ディレクトリが含まれることから推測できるように、この記事で実装したのは OCI Runtime Spec の触りの部分に当たります。 OCI Image Spec やその他の要素にはノータッチなので、興味のある方はさらに詳しく調べてみることをお勧めします。
まとめ
- コンテナは Linux カーネルの機能によって隔離された特殊なプロセス
- chroot: ルートファイルシステムを隔離
- namespace: PID、ファイルマウント、ホスト名など様々なグローバルリソースを隔離
- コンテナに関する重要な標準仕様
- OCI Runtime Specification
- OCI Image Format Specification
- 本記事と関連が深いのは runtime spec