I wrote it in English in the comment section.
◆はじめに
Intel公式ForumにてIntelのアーキテクトから当記事を取り上げて頂いたようでViewの伸びが凄まじいが、取り上げてもらえるほどクレバーな記事ではない気が…
さておき、前回、NCS(Neural Compute Stick) + Raspberry Pi 3 Model B + WebカメラでDeepLearning複数動体検知環境を構築したが、かなり動作スピードが改善したとはいえ、まだまだモッサリ感があってイライラしたため、マルチスティック(Multi Stick)環境をPythonで構築してみた。
NCSは1本¥9,900 もする高価なデバイスのため、良い子のみんなは絶対にマネしないように。

★【前回記事】環境構築
https://qiita.com/PINTO/items/b084fe3dc716c42e2867
★こちらを参考にさせていただいた、謝辞
https://qiita.com/PonDad/items/1a500c05a607a18f6384
◆前提
1.前回記事を参考にRaspberry Pi 3 + Stretch + Yolo + Python 環境を構築済みであること
2.セルフパワーのUSBハブ必須 (4 Port推奨)
3.NCS(Intel Movidius Neural Compute Stick)×3本
◆結果
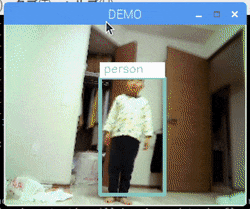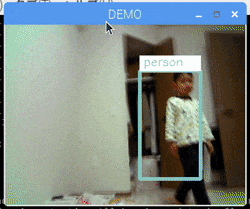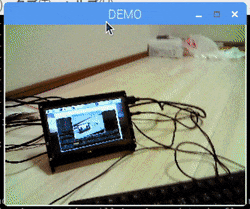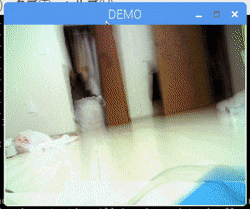
まずは下記GIF画像をご覧いただきたい。
NCSでの推論の遅さよりも、openCVによるRaspberry Pi画面へのレンダリングがボトルネックになり、多少のモッサリ感は残るが、かなりのサクサク感を体験できる。
あきらかに速い。。。
が、最終的に5本まで増設して試したが、3本、4本、5本と増やすたびに3倍速→4倍速→5倍速、とはならない。
Stick1本あたり12コアを持つが分散処理の仕組みを持たないため、2本にすれば24コア、という単純計算では認識されない。
あくまで12コアの別デバイスがn本、という計算になるため、1本あたり12コアの処理性能をn本分巡回しながら順次活用するメージとなる。
ロジックの組み方次第だとは思うが、複数のStickの推論結果をキューにため込み、取り出す順番はキューに排他を掛けて無理やり直列化しているため、画像1枚レンダリングあたり0.3秒弱のラグが発生してしまう。
むしろ、体感的にはStick1本のほうがスムーズに描写される。
効率的なロジックの組み方が分かる方は是非ご教示いただきたい。
サンプルのモデルデータがショボく、かなりの頻度で間違えた結果を表示する。
今回の検証では、かなり低確率でも検出されるように Threshold は 20% のままとしている。
大したことはしていないが、Intelのサンプルソースを改変して実現。
openCVのカメラ画像インプット および RaspberryPi へのレンダリング処理、NCSによる推論をマルチスレッド化して処理を非同期化し、即応性を極限まで高める工夫をしている。
前回のロジックに比べ、stick 1本でもこちらの実装のほうが応答性が遥かに優れている。
下記の画像は等倍速だが、MP4→GIF変換時にフレームレートが落ちて画質も劣化してしまっている。
★未編集の動画はこちら(Youtube)
https://youtu.be/GIpwdDnqHX4
ちなみに、Intelが公開している下記のYoutube動画は静止画をコマ送りしているところが味噌で、2本にすれば2倍速になっているように見える。
Intelの見せ方に若干の悪意を感じるが、注意しなければならないのは、静止画の紙芝居表示は動画とは違って画像処理の前後関係(時系列)を意識する必要が無く、非同期で順不問に処理されていても表面上はスムーズに順処理されているように見えてしまうことだ。
動画前半の談話時に後ろに見えている動画でのディテクションはしっかり見るとかなり遅い。
繰り返しになるが、処理能力が動画再生スピードに負け続けるため、かなり画期的なロジックを開発するか、性能が10倍以上にでもスペックアップしない限り、現状Stick仕様と動画の組み合わせでMultiStick構成により倍速以上のパフォーマンスを出すことは有り得ない。
◆IntelのNCS紹介動画
https://www.youtube.com/watch?v=jMcrbhIa9EA
2018/02/25追記
ロジック見直しでの限界を感じたため、Google Cloud Platform で NVIDIA Tesla K80 2本搭載 の環境を手に入れ、なんとかして10FPS以上の性能が出せないか、学習データへのパフォーマンスチューニングを試行中。
併せて Tesla K80 4本への増設もGoogle Supportへリクエスト中。
2018/03/03追記
入力解像度を落としたり、学習データをスモールにしたり、OpenGLに頼ったりして、次回記事の実装では精度は若干落ちるがStick1本で2倍近いパフォーマンスが出せた。
https://qiita.com/PINTO/items/db3ab44a3e2bcd87f2d8
2018/03/26追記
こちらが現時点の自分の力量で最速・最高精度の実装。
https://qiita.com/PINTO/items/b97b3334ed452cb555e2
◆実装
1.下記ソースを全コピペ(バックスラッシュは半角¥に読み替える)
import sys
graph_folder="./"
if sys.version_info.major < 3 or sys.version_info.minor < 4:
print("Please using python3.4 or greater!")
exit(1)
if len(sys.argv) > 1:
graph_folder = sys.argv[1]
from mvnc import mvncapi as mvnc
import numpy as np
import cv2
from os import system
import io, time
from os.path import isfile, join
from queue import Queue
from threading import Thread, Event, Lock
import re
from time import sleep
from Visualize import *
from libpydetector import YoloDetector
from skimage.transform import resize
mvnc.SetGlobalOption(mvnc.GlobalOption.LOG_LEVEL, 2)
devices = mvnc.EnumerateDevices()
if len(devices) == 0:
print("No devices found")
quit()
print(len(devices))
devHandle = []
graphHandle = []
with open(join(graph_folder, "graph"), mode="rb") as f:
graph = f.read()
for devnum in range(len(devices)):
devHandle.append(mvnc.Device(devices[devnum]))
devHandle[devnum].OpenDevice()
#opt = devHandle[devnum].GetDeviceOption(mvnc.DeviceOption.OPTIMISATION_LIST)
graphHandle.append(devHandle[devnum].AllocateGraph(graph))
graphHandle[devnum].SetGraphOption(mvnc.GraphOption.ITERATIONS, 1)
iterations = graphHandle[devnum].GetGraphOption(mvnc.GraphOption.ITERATIONS)
dim = (416,416)
#dim = (320,320)
blockwd = 12
#blockwd = 9
wh = blockwd*blockwd
targetBlockwd = 12
#targetBlockwd = 9
classes = 20
threshold = 0.2
nms = 0.4
print("\nLoaded Graphs!!!")
cam = cv2.VideoCapture(0)
# cam = cv2.VideoCapture('/home/pi/YoloV2NCS/detectionExample/xxxx.mp4')
if cam.isOpened() != True:
print("Camera/Movie Open Error!!!")
quit()
cam.set(cv2.CAP_PROP_FRAME_WIDTH, 416)
cam.set(cv2.CAP_PROP_FRAME_HEIGHT, 234)
# cam.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
# cam.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
# (WEBカメラのみ)
# 捨てるフレームが増えてカクつきが増える代わりに実像とプレディクション枠のズレを軽減
# cam.set(cv2.CAP_PROP_FPS, 100)
lock = Lock()
frameBuffer = []
results = Queue()
detector = YoloDetector(1)
def camThread(cam, lock, buff, resQ):
lastresults = None
print("press 'q' to quit!\n")
append = buff.append
get = resQ.get
while 1:
s, img = cam.read()
if not s:
print("Could not get frame")
continue
lock.acquire()
if len(buff)>10:
for i in range(10):
buff.pop()
append(img)
lock.release()
results = None
try:
results = get(False)
except:
pass
if results == None:
if lastresults == None:
pass
else:
imdraw = Visualize(img, lastresults)
cv2.imshow('DEMO', imdraw)
else:
imdraw = Visualize(img, results)
cv2.imshow('DEMO', imdraw)
lastresults = results
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
cv2.destroyAllWindows()
lock.acquire()
while len(buff) > 0:
del buff[0]
lock.release()
def inferencer(results, lock, frameBuffer, handle):
failure = 0
sleep(1)
while failure < 100:
lock.acquire()
if len(frameBuffer) == 0:
lock.release()
failure += 1
continue
img = frameBuffer[-1].copy()
del frameBuffer[-1]
failure = 0
lock.release()
imgw = img.shape[1]
imgh = img.shape[0]
im,offx,offy = PrepareImage(img, dim)
handle.LoadTensor(im.astype(np.float16), 'user object')
out, userobj = handle.GetResult()
out = Reshape(out, dim)
internalresults = detector.Detect(out.astype(np.float32), int(out.shape[0]/wh), blockwd, blockwd, classes, imgw, imgh, threshold, nms, targetBlockwd)
pyresults = [BBox(x) for x in internalresults]
results.put(pyresults)
def PrepareImage(img, dim):
imgw = img.shape[1]
imgh = img.shape[0]
imgb = np.empty((dim[0], dim[1], 3))
imgb.fill(0.5)
if imgh/imgw > dim[1]/dim[0]:
neww = int(imgw * dim[1] / imgh)
newh = dim[1]
else:
newh = int(imgh * dim[0] / imgw)
neww = dim[0]
offx = int((dim[0] - neww)/2)
offy = int((dim[1] - newh)/2)
imgb[offy:offy+newh,offx:offx+neww,:] = resize(img.copy()/255.0,(newh,neww),1)
im = imgb[:,:,(2,1,0)]
return im,offx,offy
def Reshape(out, dim):
shape = out.shape
out = np.transpose(out.reshape(wh, int(shape[0]/wh)))
out = out.reshape(shape)
return out
class BBox(object):
def __init__(self, bbox):
self.left = bbox.left
self.top = bbox.top
self.right = bbox.right
self.bottom = bbox.bottom
self.confidence = bbox.confidence
self.objType = bbox.objType
self.name = bbox.name
threads = []
camT = Thread(target=camThread, args=(cam, lock, frameBuffer, results))
camT.start()
threads.append(camT)
for devnum in range(len(devices)):
t = Thread(target=inferencer, args=(results, lock, frameBuffer, graphHandle[devnum]))
t.start()
threads.append(t)
for t in threads:
t.join()
for devnum in range(len(devices)):
graphHandle[devnum].DeallocateGraph()
devHandle[devnum].CloseDevice()
print("\n\nFinished\n\n")
2./home/pi/YoloV2NCS/detectionExample 直下に上記で作成した「MultiStick.py」を配置。
3.Webカメラ(UVC対応) を Raspberry Pi 本体のUSBポートへ接続
4.NCS(Neural Compute Stick)×3本をセルフパワーUSBハブへ接続、USBハブをRaspberryPiのUSBポートへ接続する
5.下記コマンドをRaspberryPiのコンソール上で実行
$ cd ~/YoloV2NCS
$ python3 ./detectionExample/MultiStick.py
◆注意点
バスパワーのUSBハブを意気揚々と購入して環境を仕立てたところ、見事に電圧不足となる洗礼を受けた。
セルフパワーのUSBハブが無いとまともに動かない。
ちなみに、Stick 2本でも電圧は不足し、実行時に正常にstickが認識されない。
記事内の画像にも映っているが、自分は下記を追加調達した。
★エレコム USBハブ 3.0 2.0対応 4ポート ACアダプタ付 ブラック U3H-A408SBK セルフパワー対応
https://www.amazon.co.jp/%E3%82%A8%E3%83%AC%E3%82%B3%E3%83%A0-USB%E3%83%8F%E3%83%96-2-0%E5%AF%BE%E5%BF%9C-AC%E3%82%A2%E3%83%80%E3%83%97%E3%82%BF%E4%BB%98-U3H-A408SBK/dp/B00KKJJCXC
◆おまけ
WEBカメラが手元に無い、などの理由で動画ファイルでお手軽に試したいときは、
# cam = cv2.VideoCapture(0)
cam = cv2.VideoCapture('/home/pi/YoloV2NCS/detectionExample/xxxx.mp4')
のようにコメント部を入れ替えたうえで、mp4ファイル名を宜しく変更いただければ動く。
その後試行を重ねることで、推論より画像のリサイズ加工のコストが極めて高いことが分かった。
あらかじめ動画の縦横サイズを416px以下の小ささへ加工しておくと、ラズパイにしてはかなりの爆速感を楽しめる。
もちろん、mp4ファイルを該当のパスへあらかじめコピーしておくことも忘れずに。