Lambdaについて
AWS Lambda(以下Lambda)はサーバレスコンピューティングサービスです。 オペレーティングシステム(以下OS)などのインフラストラクチャの管理が不要で、利用者はプログラムコードを準備し、Lambdaにアップロードするだけで実行できます。
トリガーとは
トリガーはLambdaを実行するきっかけです、もちろん手動で実行できますが自動で実行も出来ます、それは色々の方法あります。
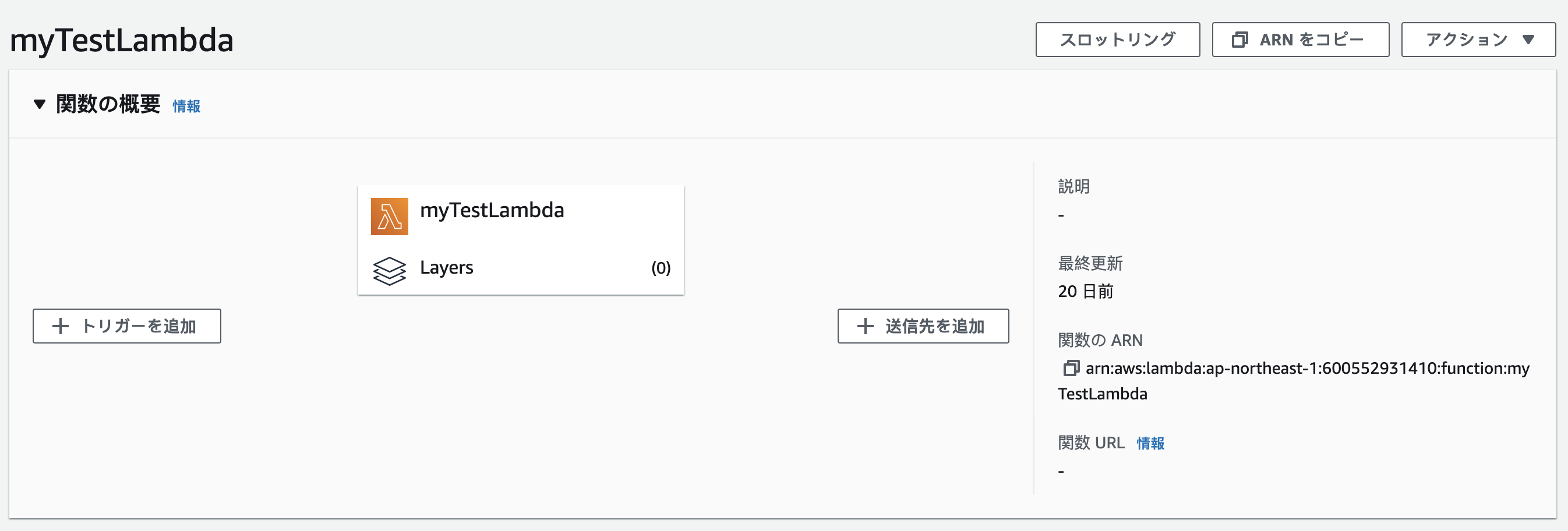
これは普通の作成したlambdaです、画面で左側は「トリガーを追加」オプションがあります、それをクリックすると色々選べます。選べるオプションの中にちょっと説明します。
s3
S3にファイルが置かれた時に自動でLambdaを実行できます。
設定画面はこちら:
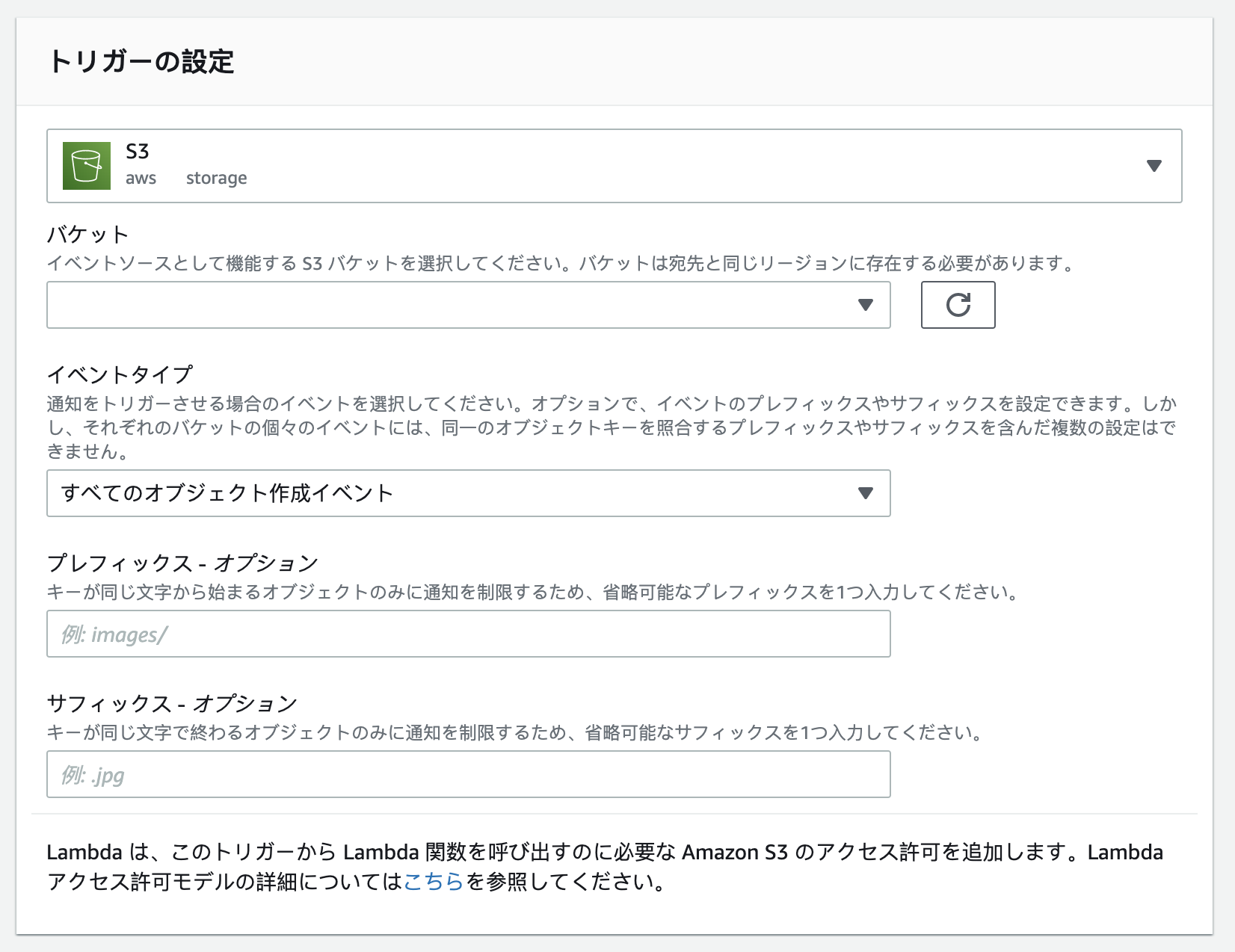
まずはどこのバケットのトリガーを設定します、アカウントの全体アクションは出来ませんので各バケットに設定が必要です。
次はどこのアクションで動かす、S3はファイルストーレージのサービスなので何が出来ますということファイルが作成された時にトリガーが出来ますし、ファイルのコピー、ファイルのストレージクラス変更もトリガーが出来ますなどなど:
後はキーで設定できます、例えばフォルダーを指定して、ファイル名が「test-」から始まるファイルを対象できます。それでも不満しましたらサフィックスも付けれます!ファイルの「.jpg」しか欲しく場合なら「.jpg」を使うもできます。
例えば:「export」のバケットに「my_files/export-*.csv」から始まるファイルが作成された時にutf8に変更して、別のアカウントのs3に送りたいです!と言う設定はこちら。
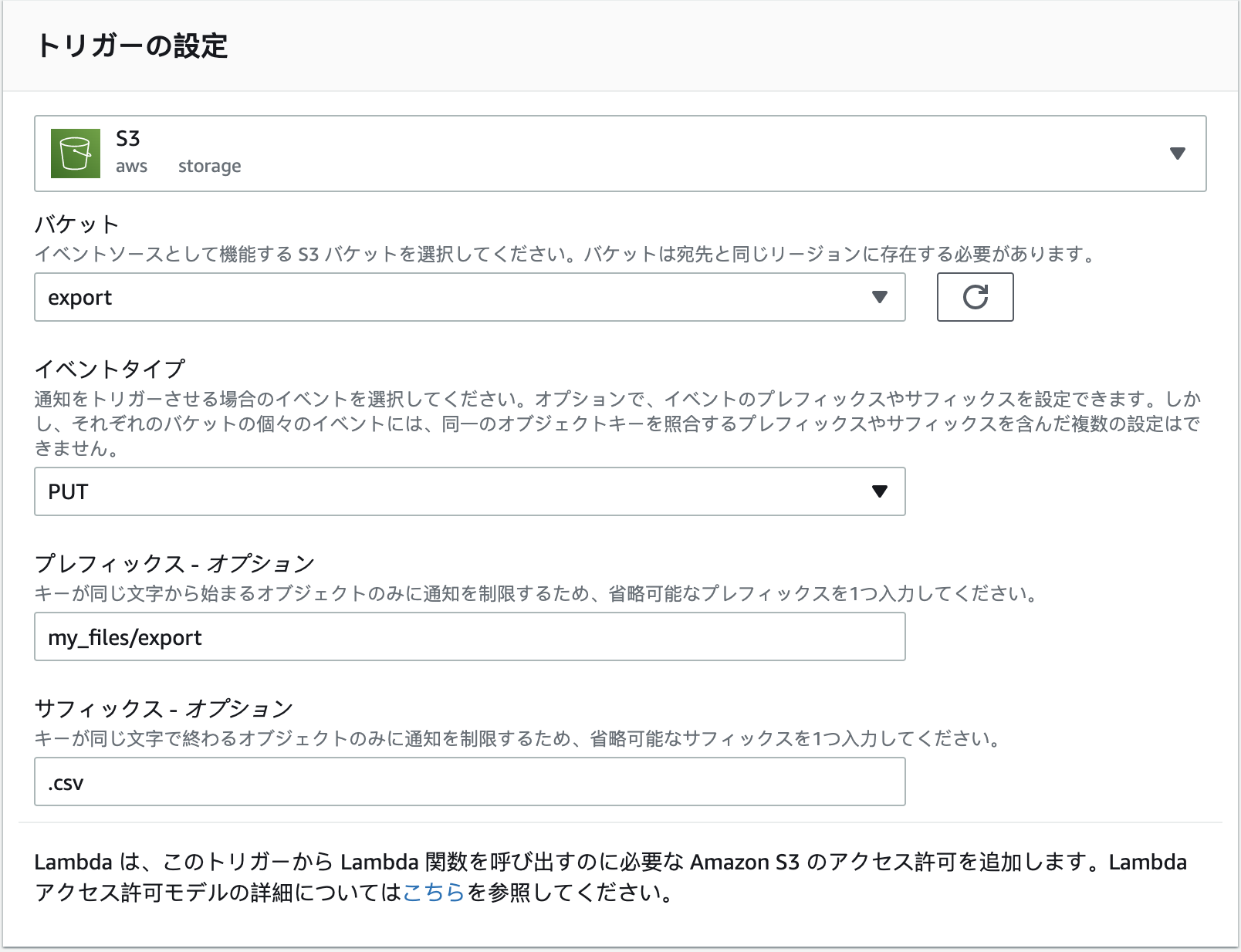
設定終わったらlambdaのコードで確認する。
S3のイベントはこんな感じです、普通のjsonです。
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "us-east-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "example-bucket",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::example-bucket"
},
"object": {
"key": "test%2Fkey",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}
jsonの形でファイルのバケットとパスが分かります。それで分かりやすいpythonコードにすると:
import json
import boto3
import os
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
s3 = boto3.resource('s3', aws_access_key_id=os.environ['ACCESS_KEY'], aws_secret_access_key=os.environ['SECRET_KEY'])
obj = s3.Object(bucket, key)
corpus = obj.get()['Body'].read().decode('utf-8')
client = boto3.client('s3', aws_access_key_id=os.environ['ACCESS_KEY_PRIVATE_USE'], aws_secret_access_key=os.environ['SECRET_PRIVATE_USE'])
client.put_object(Body=corpus, Bucket="private-csv", Key=key, ContentEncoding="utf-8")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
先にevent['Records']の中では腹痛のイベントがある可能性がありますのでループします、オブジェクトごとにゲットして、中身をutf-8してと別のアカウントに送ります。
os.environはlambdaの設定で登録したものです!
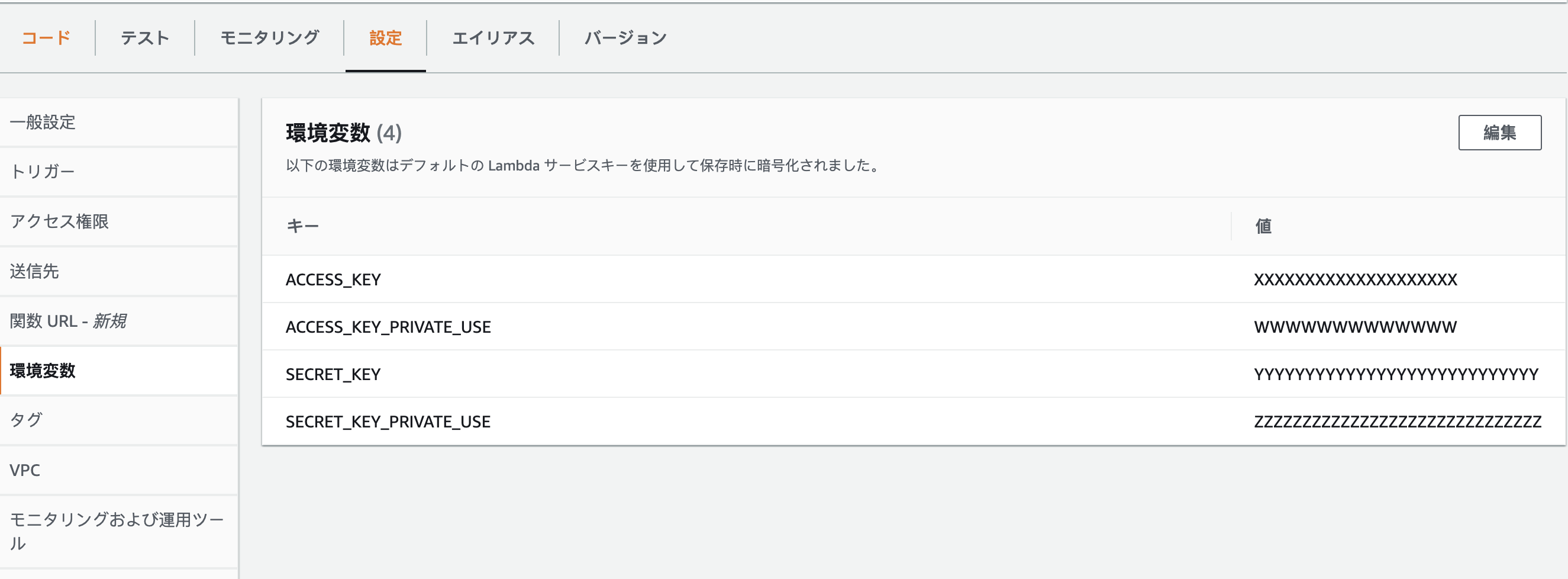
この設定でこのコードなら指定したファイルがS3のバケットに送られた瞬間にLambdaが実行して、そのファイルをutf-8変更して、別のs3アカウントに送る出来ます。
Cloudwatch
Cloudwatchは基本ログ管理とメトリクス管理を使いますが面白い使い方もあります、CloudwatchのイベントからLambdaを実行できます!
イベントってなに?スケジュールが出来るトリガーです!定期実行、特別の時間とかは設定できます。例えば毎時間のサーバーレス実行でサーバーをチェックしたいとか、特別のアクションをしたい場合は出来ます。
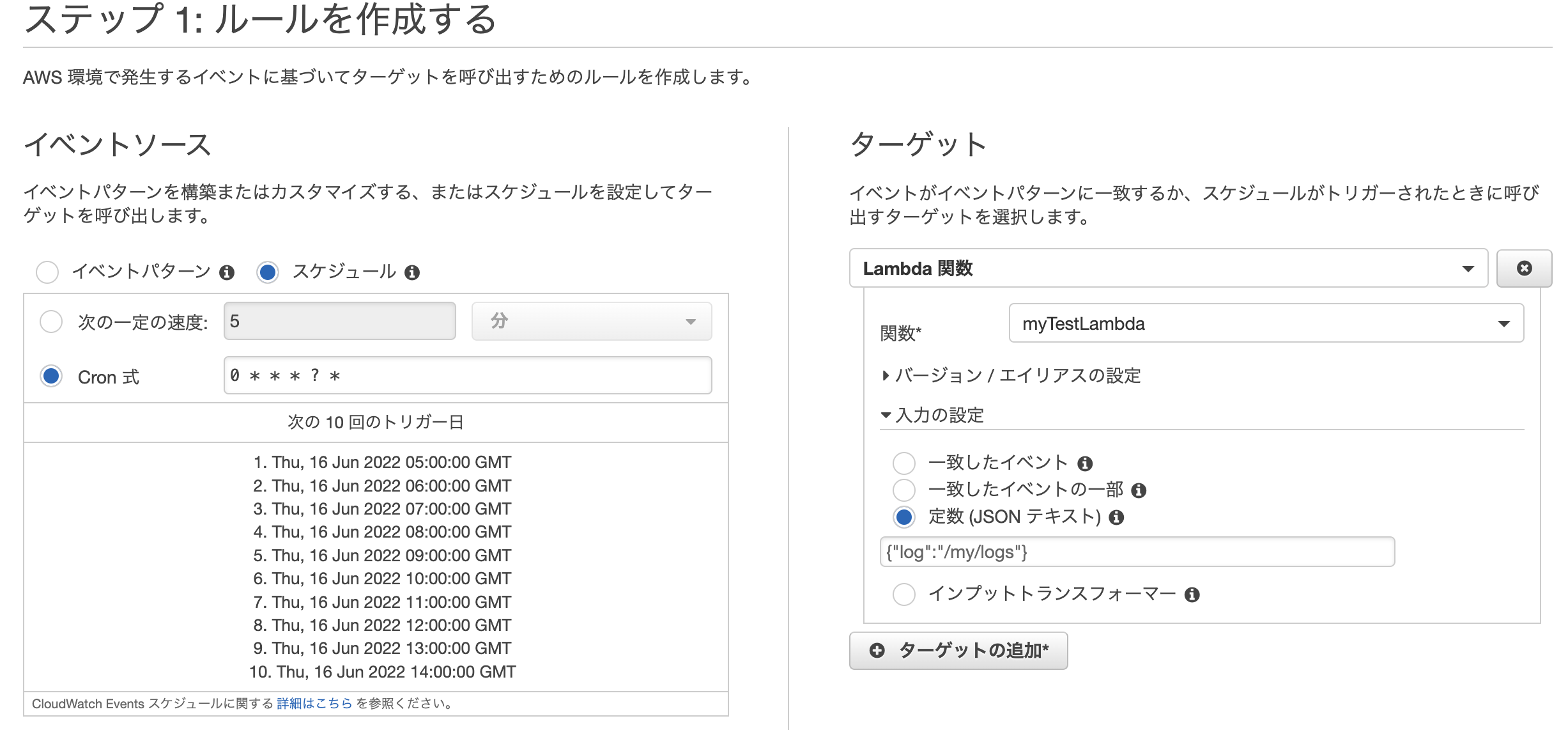
cronの設定して、次の10回の実行確認が出来ますので書き間違いを確認しやすいです。ターゲットをlambdaにすると設定するjsonsテキストとして入れて、そのままにlambdaが受け取れます!
lambdaのコードはこちらです:
def lambda_handler(event, context):
log_path = event['log']
print(log_path)
s3 = boto3.resource('s3', aws_access_key_id=os.environ['ACCESS_KEY'], aws_secret_access_key=os.environ['SECRET_KEY'])
obj = s3.Object(BUCKET, os_name+"/logs.txt")
log_check(obj)
def log_check(obj):
##log check function
SQS
SQSはキューのサービスです!それで色々ジョブとかを貯めて、ゆっくり実行してます。
例えば、エラーが発して、それをSQSのキューに入れて、キューに入ったらlambdaが実行されますのでlambdaからslackとかに送信したい・・!という事ができます。
これはSQSのトリガーイベントです:
{
"Records": [
{
"messageId": "19dd0b57-b21e-4ac1-bd88-01bbb068cb78",
"receiptHandle": "MessageReceiptHandle",
"body": "Hello from SQS!",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1523232000000",
"SenderId": "123456789012",
"ApproximateFirstReceiveTimestamp": "1523232000001"
},
"messageAttributes": {},
"md5OfBody": "{{{md5_of_body}}}",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-1:123456789012:MyQueue",
"awsRegion": "us-east-1"
}
]
}
そのイベントに対してのlambdaのコードはこちら:
import urllib3
import json
http = urllib3.PoolManager()
def lambda_handler(event, context):
for record in event['Records']:
url = "https://hooks.slack.com/services/XXXX/XXXX/XXXX"
msg = {
"channel": "#general",
"username": "",
"text": "Hello From Lambda",
"icon_emoji": ""
}
encoded_msg = json.dumps(msg).encode('utf-8')
resp = http.request('POST', url, body=encoded_msg)
print({
"message": "Hello From Lambda",
"status_code": resp.status,
"response": resp.data
})
他のlambda
もちろん、他のLambdaから呼べます、「なんでこれを使うの?」と言われたら色んな場合があります!
AWSのVPC内とVPC外は全然違います、同じlambdaをデータベースのデータを見たいと外部のサービスを使うは出来ません、それだと1 lambdaがVPC内でデータベース結果とって、VPC外のLambdaに送るが出来ます、設定しやすいし、セキュリティーとして安全です。
他の場合も、Lambdaの実行時間が決まってます、15分以上は出来ません、1ギガ以上のメモリが出来ませんので短いジョブに向いてます。多いユーザーリストに一件ずつを同じプロセスするより、同じプロセスが全部asyncに別のlambdaに送る方が効率良い、lambdaの同時実行がすごく良いのでそっちの方が安全です。
import json
import boto3
def lambda_handler(event, context):
log_path = event['logs']
print(log_path)
s3 = boto3.resource('s3', aws_access_key_id=os.environ['ACCESS_KEY'], aws_secret_access_key=os.environ['SECRET_KEY'])
obj = s3.Object(BUCKET, log_path+'users.txt')
corpus = obj.get()['Body'].read().decode('utf-8')
content = json.loads(corpus)
client = boto3.client('lambda', region_name='ap-northeast-1', aws_access_key_id=os.environ['ACCESS_KEY'], aws_secret_access_key=os.environ['SECRET_KEY'])
for user in content:
data = {"user": user, "log_path": log_path}
client.invoke(
FunctionName='arn:aws:lambda:ap-northeast-1:600552000000:function:check_users',
InvocationType='Event',
Payload=json.dumps(data)
)
InvocationTypeは一番面白いオプションです、asyncか返事待ちを選べます:
-
RequestResponse(デフォルト) - 関数を同期的に呼び出します。関数がレスポンスを返すかタイムアウトするまで、接続を開いたままにします。API レスポンスには、関数レスポンスと追加データが含まれます。 -
Event- 関数を非同期的に呼び出します。複数回失敗したイベントを、関数のデッドレターキューに送信します (設定されている場合)。API レスポンスには、ステータスコードのみが含まれます。 -
DryRun- パラメータ値を検証し、ユーザーまたはロールが、関数を呼び出すアクセス許可を持っていることを確認します。
Payloadは入力として Lambda 関数に提供される JSON。
以上。