はじめに
開発業務で「情報収集」や「タスク自動化」をするときにスクレイピングやクローリングを用いる場合があると思います。一時期私もスクレイピング関連の本を読んでBeautifulSoup, Seleniumなどを使って自動化をしましたが、CSSセレクタを指定していくのが大変だったり、DOM構造が変わると動かなくなったりと、色々苦労した覚えがあります。
そんな時、browser-useという面白そうなライブラリを見つけたので、この記事では、browser-useを使ってみた内容を自分用のメモとして残そうと思います。
browser-useとは?
browser-useはAIを使ってブラウザ操作を自動化してくれるツールです。
このツールは、Pythonを使ってブラウザで実行する操作をテキストで渡してあげると、AIがそのテキストに基づき操作を行ってくれます。そのためスクレイピング/提携業務の自動化/Webアプリケーションの自動テストに利用することができます。
インストールとセットアップ
インストール手順
browser-useのreadmeにある通り, browser-use, playwrightをインストールします。
以下のコマンドでインストールします:
pip install browser-use
playwright install
初期設定
利用にはOPENAIのAPIキーが必要です。
ローカルプロジェクトの.envに記載してください。
OPENAI_API_KEY=foobar
基本的な使い方
まずはreadmeに載っているサンプルコードを試してみます。
引数はtaskに動作させる内容を、llmにモデルを指定するようです。
雑にQiitaでAIに関する人気のある記事のURLを10件取得してください。と指定してみます。
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
from dotenv import load_dotenv
load_dotenv()
async def main():
agent = Agent(
task="""
QiitaでAIに関する人気のある記事のURLを10件取得してください。
""",
llm=ChatOpenAI(model="gpt-4o"),
)
result = await agent.run()
print(result)
asyncio.run(main())
実行するとブラウザが起動して、Googleからうまいこと単語を分割して検索してくれています。
(当たり前ですが、流石にQiitaにアクセスして、そこから検索とかはしてくれませんでした。)
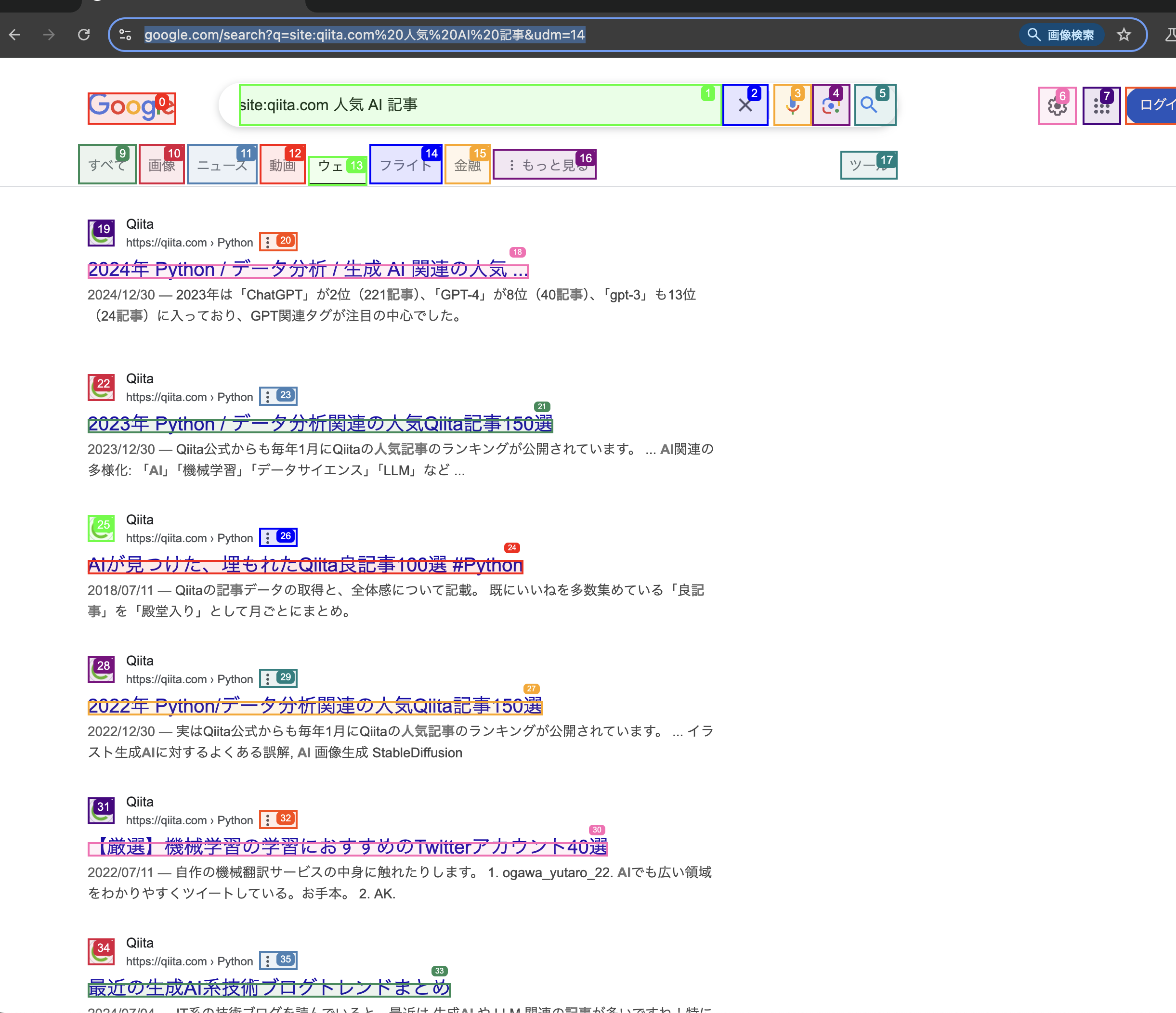
出力された結果は以下になります。

面白い、、、!
特定のサイトのURLを指定して検索もできるようです!
今回TMDBというサイトから情報を取得させてみます。
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
from dotenv import load_dotenv
load_dotenv()
async def main():
agent = Agent(
task="""
以下のリンク先にアクセスしてください。
- https://www.themoviedb.org/movie?language=ja
以下の条件に従って映画を検索てください。
- ジャンル: コメディ
- 公開日: 2000~2023年
- ユーザ評価: 6.0以上
検索にヒットした上位5つの映画の以下の情報を出力してください。。
- 概要
- ユーザスコア
- 出演者
""",
llm=ChatOpenAI(model="gpt-4o"),
)
result = await agent.run()
print(result)
asyncio.run(main())
指定したURLにアクセスしてくれています。
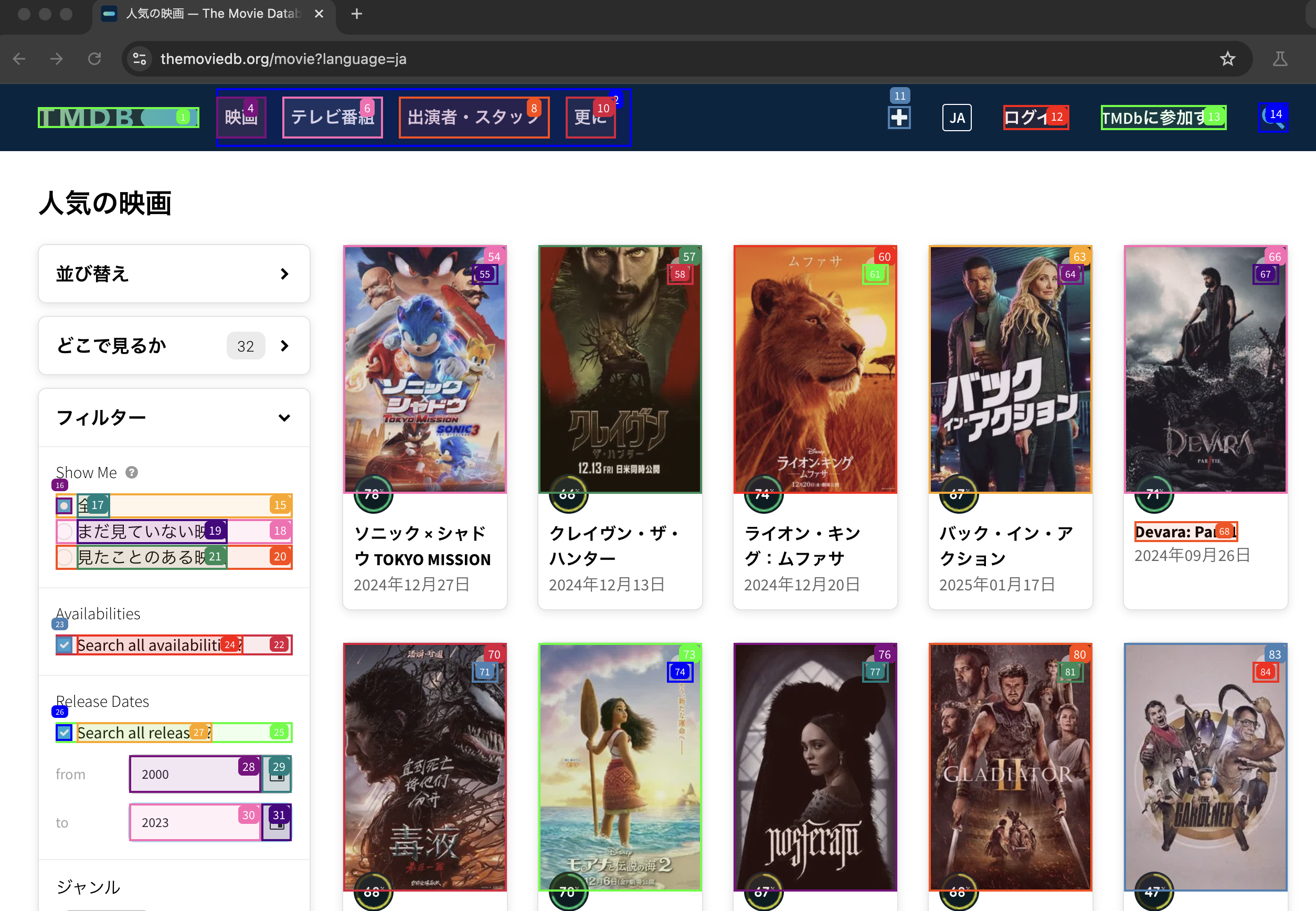
検索条件も入力してくれています。
(スライダーなどうまく動作しないUIもありそうでしたが。)
詳細画面にも遷移してくれています。
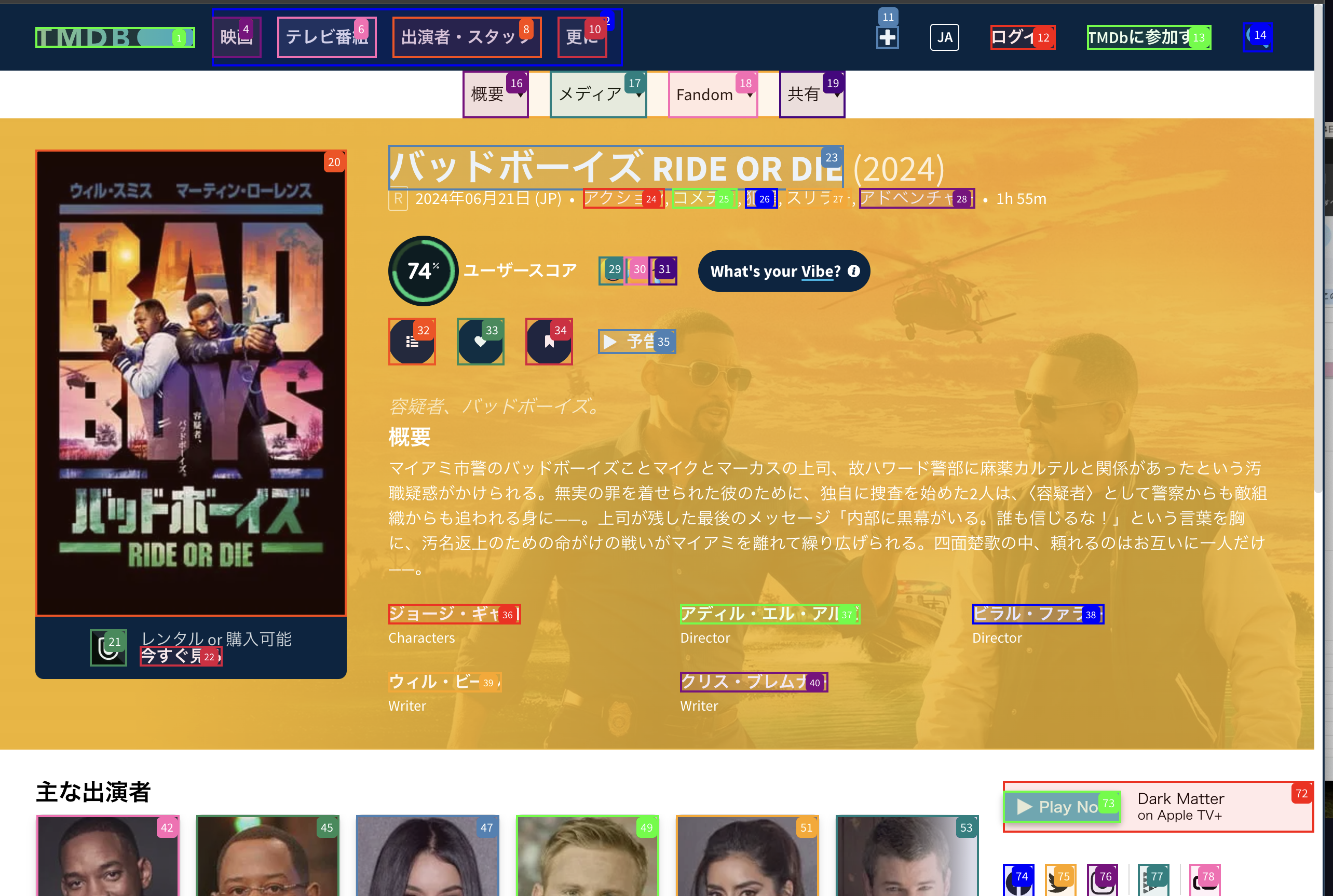
最後に出力です。

JSONを見てみると、「概要」「ユーザースコア」「主な出演者」も含まれていますね!
出力方法をtaskで指定してあげればデータ収集周りにも使えそうです!
{
"text": "Title: バッドボーイズ RIDE OR DIE (Bad Boys: Ride or Die)\n- ユーザースコア: 74%\n- 概要: マイアミ市警のバッドボーイズことマイクとマーカスの上司、故ハワード警部に麻薬カルテルと関係があったという汚職疑惑がかけられる。無実の罪を着せられた彼のために、独自に捜査を始めた2人は、〈容疑者〉として警察からも敵組織からも追われる身に――。上司が残した最後のメッセージ「内部に黒幕がいる。誰も信じるな!」という言葉を胸に、汚名返上のための命がけの戦いがマイアミを離れて繰り広げられる。\n- 主な出演者: ウィル・スミス (Mike Lowrey), マーティン・ローレンス (Marcus Burnett), ヴァネッサ・ハジェンズ (Kelly), アレクサンダー・ルドウィグ (Dorn), パオラ・ヌニェス (Rita)\n\nProcess needs to be repeated for four more movies to meet task parameters."
}
応用的な使い方
browser-useのリポジトリにいくつかexampleがあります。
https://github.com/browser-use/browser-use/tree/main/examples
などなど色々とできることがあるので、また時間のある時に触ってみようと思います!
おわりに
これまではSeleniumでブラウザ操作するのに、たくさんのCSSセレクタを指定してスクレイピングしていましたが、browser-useを使うと数行でブラウザ操作ができてしまいました。
またスクレイピング用に実装したコード上のセレクタに依存しないのである程度画面が変わっても動作しそうです!
今回はお試しに使ってみただけですが、色々と業務自動化もできそうなのでしっかり使い倒していこうと思います!