この記事は Microsoft Azure Tech Advent Calendar 2019 の 18 日目の記事です。
今日は、Azure の裏側の話、データーセンター (DC) を支える、Ananta1 と呼ばれる Software Load Balancer (SLB) アーキテクチャを紹介したいと思います。
はじめに
紹介の前に、まず最初に断っておかなければならないのは、Ananta が提案されたのは 2013 年であり、今から 6 年以上も前であるということです。当然、現在の Azure の DC で動いているロードバランサー (LB) は Ananta ではなく、以下のような多くの技術2を含む、改良を加えたバージョンのものです 。
- Duet [R. Gandhi, et al. 2014] 3 : Ananta の論文が公開された翌年 2014 年に提案。SLB である Ananta の一部を、汎用的なスイッチによってハードウェア処理とすることで、低レイテンシー・高帯域を実現。
- Rubik [R. Gandhi, et al. 2015] 4 : Duet のメリットを残したまま、DC 内のリンクの利用効率を 4 倍も向上し、結果としてネットワーク帯域量を大幅に削減した。
- VFP [D. Firestone 2017] 5 : ホスト OS の NIC で行っていた VIP/DIP 変換や SLB 関連の処理を、コントロール/データ プレーンに分離することでスケールを可能とした。OpenFlow (Open vSwitch) にインスパイアされた MAT モデルに基づき、Hypter-V の仮想スイッチの拡張機能として実装される。
- SmartNIC [D. Firestone, et al. 2018] 6 : NIC の帯域が増えるにつれボトルネックとなっていた、CPU による VFP 処理の一部をハードウェア処理に置換。ASIC の融通の効かなさをカバーする為に FPGA を活用 7。
- Azure accelerated networking: SmartNICs in the public cloud – the morning paper
- paper slide
- ASCII.jp:自社開発技術満載!Microsoft Azureの物理インフラを大解剖 (1/3)
- インフラ野郎 Azureチーム 博多夏祭り p.56
Ananta を学ぶメリット
じゃあ、なぜ 2020 年にもなろうというのに今更 Ananta を学ぶべきなの?という話なんですが、個人的には、Ananta の仕組みを知るメリットは大きく 4 つあると思っています。
1. Azure を使う時に Azure の気持ちになれるから
これはユーザー目線のメリットです。
Ananta は Azure の DC アーキテクチャの中心と言っても過言ではありません。というのも、Ananta に基づく SLB のアーキテクチャを利用している限り、データ プレーン (ネットワーク・トポロジー) はほぼほぼ固定されるからです。トポロジーが決まるということは、トラフィックのフローが決まるということですから、インターネットからやってきたトラフィックがどのように VM に流れ込むのか 理解することに繋がります。
さらに、Azure の (主にネットワーク関連の) 仕様が「アーキテクチャから自然と導かれる」ことを理解できれば、所謂 Azure でのお作法を丸暗記する必要もある程度なくなります。
例えば、記事のタイトルにもあるように、Ananta は ステートフル な L4 ロード バランサーを ソフトウェア実装 で実現するものです。ちょっと Azure の動作に関して踏み込んだ内容にはなりますが、この点を意識するだけでも以下のお作法を理解する助けになります。
- ステートフル
- Azure Load Balancer のバックエンド プールから実サーバー (VM) を切り離しても、確立している既存の TCP コネクションに関しては依然 VM に流れます。
- L4
- Azure Load Balancer では TCP/UDP のレイヤーまでしか考慮しないので、TLS 終端ができません (L7 ロードバランサーとしては、Application Gateway を使う必要があります)。また、HTTP のエラー (e.g. 403, 503 の HTTP status code) を Azure Load Balancer が吐くことはありません。
- ソフトウェア実装
- SLB が DC 内部に渡って極度に分散されている仕組みを知ることで、Azure Load Balancer がダウンすることと、リージョン全体がダウンする障害がほぼ等価であることもわかります。この公式ブログの記事 や宇田さんの記事にも書かれてあるように、こうした知識を知っていれば、トラブルシュートの際のアクションの順番を決定することにも役立ちます。
2. Microsoft の SDN 技術を学ぶ土台になるから
これは、Azure (Microsoft) でのデータセンター・インフラストラクチャ/ネットワーク技術を知りたい人向けのメリットです。
わかりやすい例で言えば、冒頭に示した Duet, VFP, SmartNIC など、Ananta の知識無しに学ぼうと思っても、正しく理解するのが難しい Microsoft の技術が多く存在します。他の例としては、Windows Server 2019 で実装されている SDN 技術 (e.g. SLB) も、詳細は公開されていませんが、アーキテクチャを見る限り Ananta (および VFP) がベースであるのは間違いないでしょう。
このように、Microsoft Research が発表しているネットワーク関係の論文8や技術には Ananta をベースとしているものが多く存在し、Microsoft として Ananta ライクな SLB に力を入れているのが分かります。今後 Microsoft が公開するであろうネットワーク技術をキャッチアップしていく土台を作る目的で Ananta を学ぶのは良い初手と言えます。
3. SLB のリファレンス アーキテクチャとなるから
SLB 技術に興味のある人へのメリットです。
Ananta 以外の データ センター向け L4 ロードバランサー としては、Facebook/Google の DC で動く Load Balancer が、それぞれ "SlikRoad", "Maglev" という名前で論文が公開されています。そして、驚くことに、両論文ともに Ananta を Related Wroks として引用しており、提案手法との違いを議論しています。
- SilkRoad: Making Stateful Layer-4 Load Balancing Fast and Cheap Using Switching ASICs - Facebook Research
- Maglev: A Fast and Reliable Software Network Load Balancer | USENIX
自分が Ananta の論文を読んだ時、Ananta は "off-the-shelf" な技術を活用しているので、本当の真新しさというのは一見するとわかりませんでした。しかし、その反面、アーキテクチャとしての美しさを感じました。
ここからはネットワーク素人の個人的な見解となってしまうのですが、上の論文を見ると、(細かい部分に違いはあるもののの) ベースになっているコントロール/データ プレーンの考え方は Ananta に似ています。Ananta が分散 SLB としてよいリファレンス アーキテクチャであるために、SilkRoad や Maglev でも参考にされているのではないかと思っています。
4. 知らないことを知るのは楽しいから
結局、これに尽きるんですよね。
仰々しくメリットを書いてみましたが、自分にとっては好奇心が一番大きなモチベーションです😝
背景
このセクションでは、Ananta が提供する機能 を背景を踏まえた上で説明します。
サービス/VIP/DIP
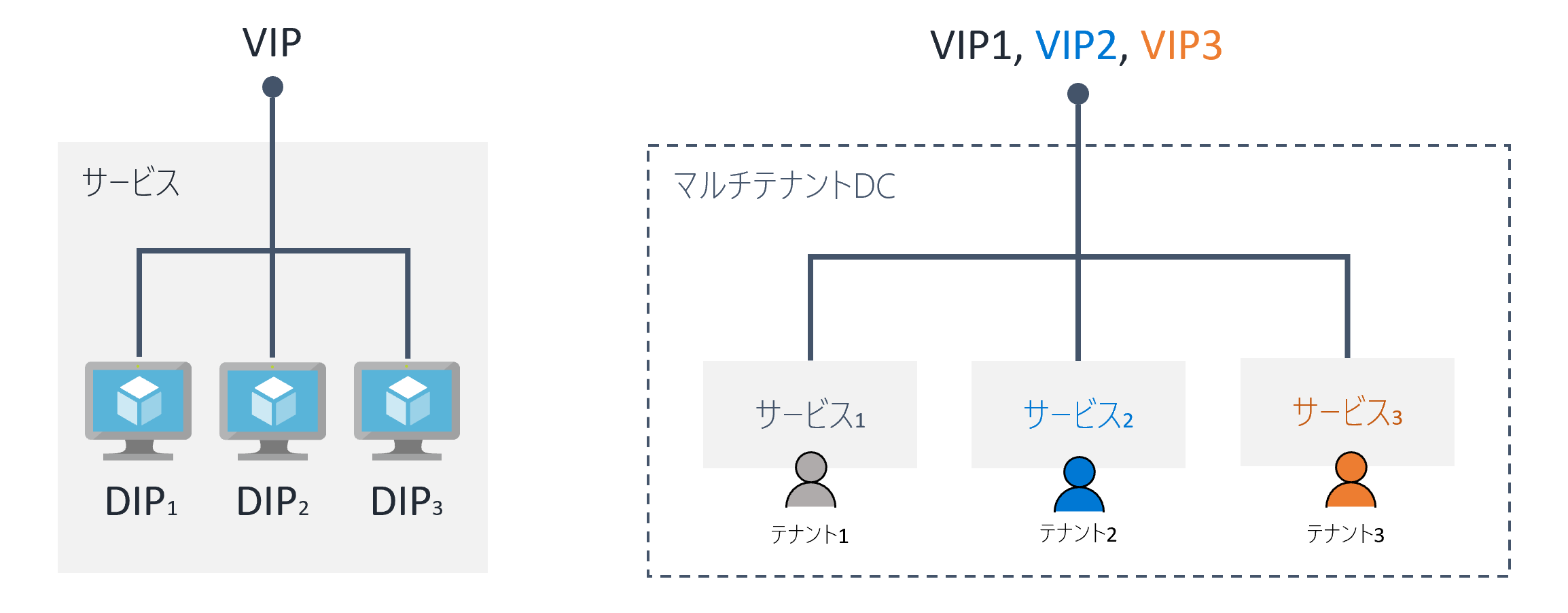
サービス
IT の世界では、人間/機械/システムにとってある程度意味をなす機能のまとまり (高レベルな概念での機能の単位) を**サービス (service)**と呼びます9。サービスは、一般に複数のコンピュータによって提供され、Web アプリケーション、VPN、データベースなど、多種多様です。例えば、ブラウザで YouTube にアクセスし、お気に入りのうさぎ🐰の動画が視聴できるのも、Google が youtube.com というエンドポイントで「動画サービス」を提供しているからです。
データ センターは多くのサービスをホストする場所です。また、Azure は、IaaS/PaaS という方法を通して多くの Azure ユーザーが自由にサービスをホスティングできる機能を提供しており、さらに Microsoft 自身も自社サービス (e.g. PaaS, Office 365, Dynamics 365) を Azure のデータ センターにデプロイしています。
このように、DC 内にサービスをホストする主体 (テナント) が複数存在することを、マルチテナント (multi-tenant) あるいは マルチテナンシー (multitenancy) といいます。一般に、サービスが違えばテナントも異なります (もちろん実際には、異なる二つのサービスを、同じテナントが所有するケースもかなり多いです)。
VIP/DIP
サービスの定義は状況に応じて変化する10ため曖昧ですが、LB の文脈でのサービスは「外部からサービスに アクセスできる 1 つの IP アドレスが関連付くもの」と定義されます。そして、その IP アドレスを 仮想 IP (virtual IP; VIP) といいます11。
一般的には VIP はグローバル IP アドレスとなるケースが多いです。例えば、WEB サイトの URL を名前解決したら出てくる IP アドレスは VIP です。
そして、VIP と対比する形で、サービス内部でのみ有効な IP アドレスを Direct IP (DIP) と呼びます。高可用性のサービスを提供するために、サービス内部では一般に複数のサーバー (バックエンド サーバー) 12が動いており、各サーバーにはそれぞれ一つの DIP が付与されます。
誤解を恐れずに言えば、VIP = グローバル IP アドレス、DIP = プライベート IP アドレスだと思ってください。
Azure
Azure は Microsoft の提供するパブリック クラウド サービスです。
54 のリージョンと、140 カ国以上の国で利用が可能、さらにリージョン内の帯域幅は最大で 1.6 Pbps !、なんてのが売りの一つです。
Azure は雲ではありません13 ので裏側では当然物理サーバーが動いているわけですが、クラウド サービスのデーターセンター (DC) と聞くと、「なんかトラフィック多そう🤔」「トラフィック捌くの大変そう…」のような漠然とした印象を受けるのではないでしょうか?
少なくとも、(ネットワークの勉強を始める) 半年前の自分はそう思っていました・・・。
DC の抱える問題
実際、Azure の DC にやってくるトラフィックをさばくのは大変です。
ただ、苦労しているのは Azure に限りません。これは、パブリック クラウドをホストする GCP, AWS はもちろん、世界中の DC での課題です。
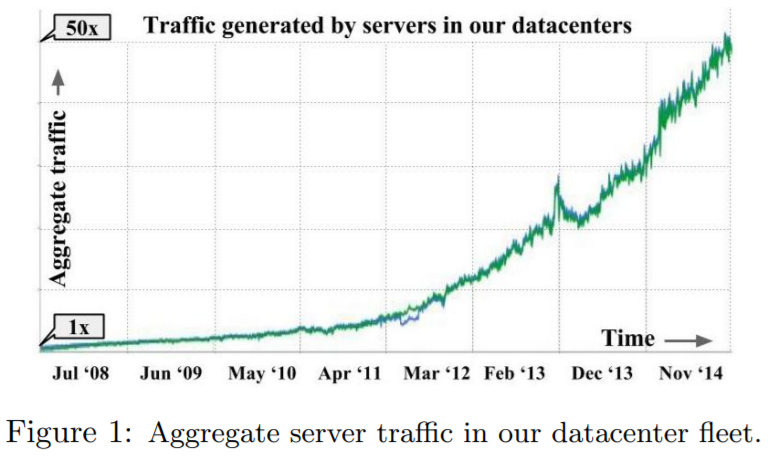
例えば、Facebook 社は、2014 年のブログ記事で自社サービスをホストする DC のネットワーク事情を語っていますが、サービス同士の「連携」が増えることによって、DC 内部のサーバー間通信量は 毎年 2 倍のペースで指数関数的増加している傾向がある と報告しています。(マイクロサービスアーキテクチャの影響?)
What happens inside the Facebook data centers – “machine to machine” traffic – is several orders of magnitude larger than what goes out to the Internet.
(中略)
We are constantly optimizing internal application efficiency, but nonetheless the rate of our machine-to-machine traffic growth remains exponential, and the volume has been doubling at an interval of less than a year.
Google のデータセンターでも、2008 年から 2014 年にかけて50 倍ものトラフィック増加を観測していて、概ね年に 2 倍のペースという点で Facebook の状況と類似しています14。
Azure の DC への要請
2013 年当時、Azure も引けず劣らず大変な状況でした。ユーザー数や計算機資源の投資額の数字としても、尋常じゃない量のトラフィックを捌く能力が必要とされていた (今もですが) ことがわかります。
また、パブリック クラウドの DC では、ストレージ、コンピューティング、あるいは Web/データ分析等を目的とした PaaS といった、多種多様なサービスをユーザーに提供できる必要があります。ビジネス的な要請として、ユーザー自身も IaaS/PaaS とよばれるサービス形態を通して自由にサービスを DC 内にデプロイできます。しかも、Azure では、仮想ネットワーク」という名前で知られる ”論理的なプライベート IP アドレス空間” 機能を提供しています。これまたネットワーク的には難しい話です。
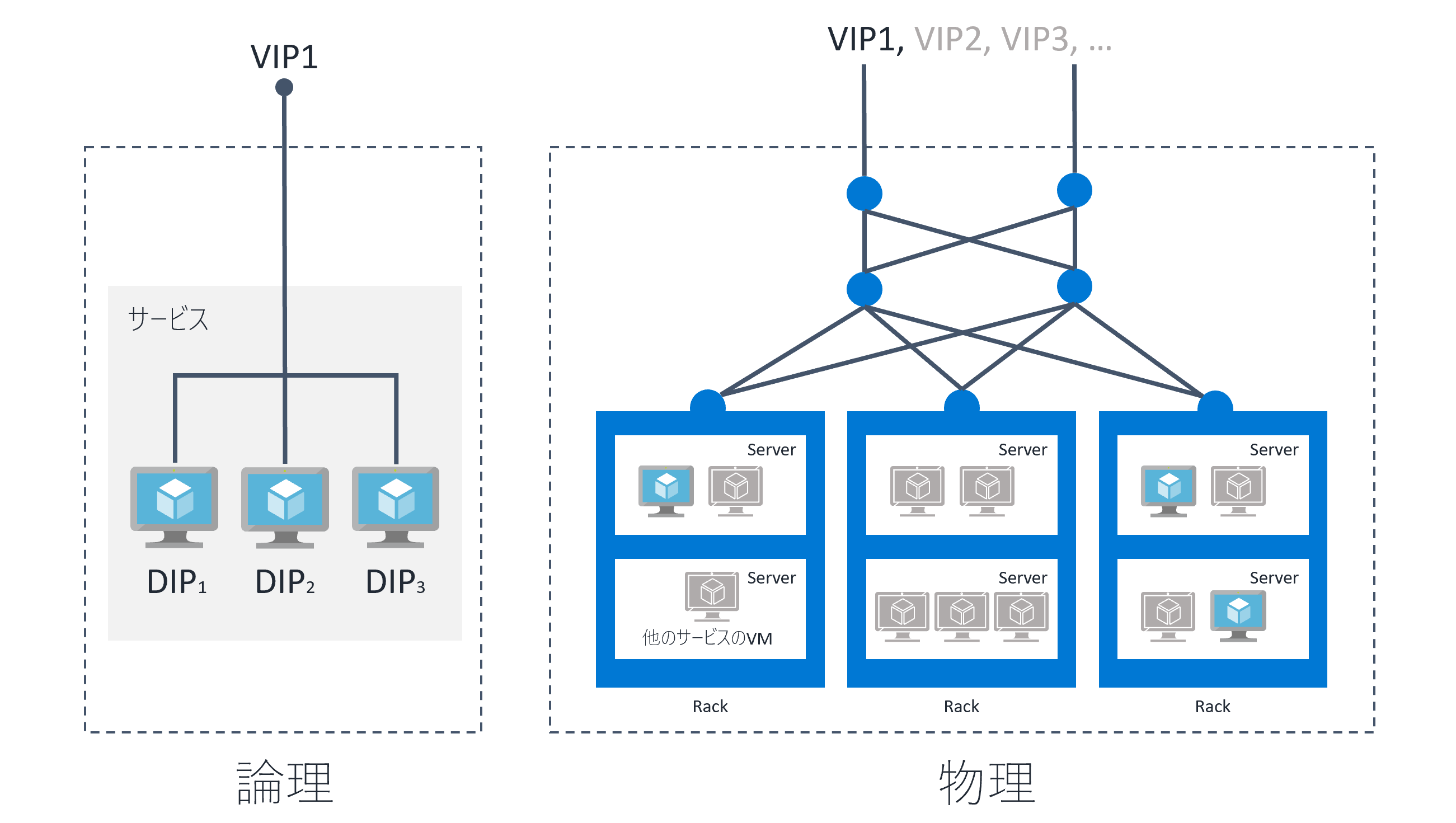
あとは、仮想化技術で Azure は支えられているということも忘れてはいけません。いままでの図では、物理的なことは一切書いていませんでしたが、実際は、サービスの VM はこんな感じでデーターセンター内のいろんな場所にサービス内部の VM が分散配置されています (かなり概略)。
物理的な計算機資源を最大限に利活用するためには、適切なリソースのアロケーション不可欠なので、サービスをホストする物理的な場所がころころ変わります 15。
負荷分散と NAT
さて、概念図に戻って、サービスの通信を DC としてどのように捌く必要があるのか見てみましょう。
実際にトラフィックを捌く仕組みは一旦置いといて、ここでは「なにかのしくみ」としておきます (後に見るように「なにかのしくみ」の新しい提案が Ananta であり、主に MUX とホスト エージェントによって実装されます)。
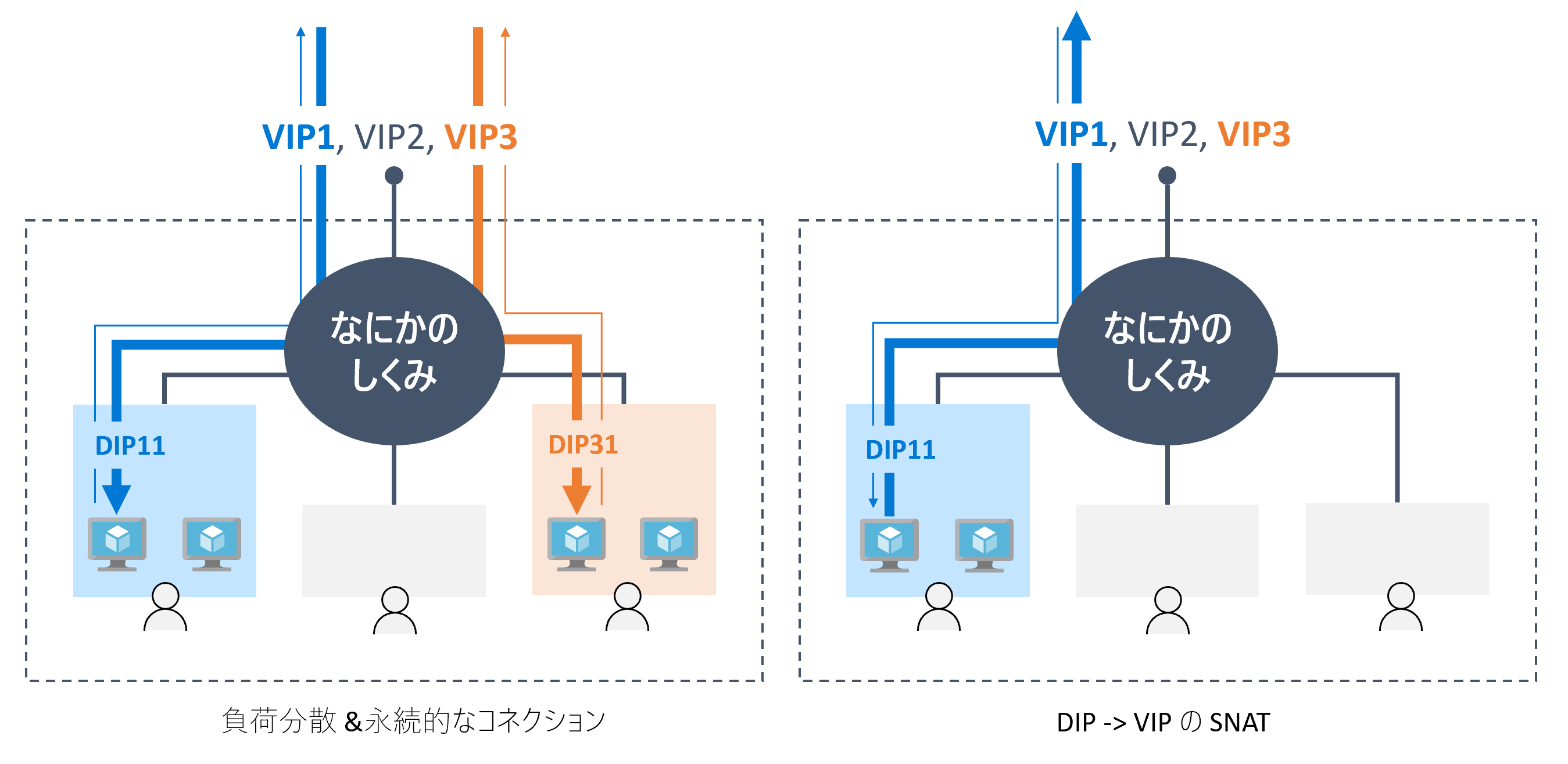
Inbound 通信
図の左側の話です。
任意の場所のクライアントから、サービスの VIP (e.g. VIP1) にアクセスしたときを考えましょう。例えば図の青色のサービスでは、バックエンド サーバーは 2 台なので、「なにかのしくみ」を通してどちらの VM にパケットを渡すか決めてあげる必要があります。これを 負荷分散 (load balancing、ロード バランシング) と言います 16。
また、一般にファイアウォールと呼ばれる機器で実装されるトラフィック制御も「なにかのしくみ」で出来れば嬉しいです。というより、Azure の DC では必須です。Azure では、ユーザーがステートフルな L3/L4 ファイアウォールのルールを柔軟に構成できる NSG と呼ばれる機能を提供しているので 17、「なにかのしくみ」で実現する必要があります。
さらに、TCP のようなコネクション志向のプロトコルでは、コネクションを確立 (e.g. 3-way handshaking) した後にも同じ VM に対してパケットを運んであげる必要があるので、L4 レベルでのパーシステンス (セッション維持) の機能も忘れてはいけません。
つまり「なにかのしくみ」は、Inbound 通信に対して次のような機能を提供します。
- 負荷分散アルゴリズムによる宛先 DIP の決定
- ステートフルな (L3/L4) ファイアウォール
- TCP コネクションのパーシステンス
Outbound 通信
右側の話です。
こちらは非常にシンプルで、「なにかのしくみ」がやることは一つだけです。つまり、DIP → VIP に変換する、ステートフルな Source NAT (SNAT) 機能です。
例えば サービス1 の DIP11 がインターネットと通信したい場合、「なにかのしくみ」はサービス 1 の VIP VIP1 を SNAT 用に使うことを考えます。次に、VIP1 で空いているエフェメラル ポートを検索し、最後にそのパケットを DC 外部に放出します。
また、Outbound 通信への戻り (図中の細い線) は、宛先 IP アドレス VIP 宛になっているので、適切に処理 (今度は DNAT) してあげる必要があります。したがって、SNAT 装置一般に言える話となりますが、「なにかのしくみ」ではどの VM がどの宛先に Outbound の送信をだしたか?という SNAT の履歴を保持しておく必要があります。
新しい「なにかのしくみ」へ
負荷分散、パーシステンス、ファイアウォール、SNAT という様々な機能を提供する「なにかのしくみ」ですが、さらに Azure DC の特性に合わせて、次の事項も満たすよう要請されます。
- スケールし、高い可用性を実現できる (N+1 冗長化できる)
- 安価に構成するため、専門的な HW (e.g. ASIC, FPGA) を使わずに一般的なサーバーでソフトウェア実装できる
- 任意の場所の物理サーバーに、任意のサービスのバックエンド サーバー (VM) をデプロイできる
- テナント (ユーザー) ごとに完全に分離された、論理的なネットワーク環境を提供する
なかなか難儀な話ですよね・・・。詳しくは論文を見てもらえばと思うのですが、既存の H/W ロードバランサーや SLB ではこのような要件を満たすことができませんでした。そこで Microsoft は Ananta の開発に取り組みました。

Ananta
前述の「なにかのしくみ」を実現するのが Ananta です。
負荷分散、パーシステンス、ファイアウォール、SNAT をやりたいんだなぁという気持ちを理解していたら、Ananta の論文も結構すんなり読めます。例えば論文 1 の Introduction をざっとみるとお気持ちを改めて知ることができます

アーキテクチャ
Ananta は、次の 3 つのコンポーネントで構成されています。
- Ananta Manager
- MUX (Multiplexer)
- Host Agent
SDN (Software Defined Network) の言葉を使って説明すると、Ananta Manager がコントロール プレーン、MUX と Host Agent がデータ プレーンです。ネットワークに明るくない自分にとっては、SDN に馴染みがなく、当初コントロル/データ プレーンを理解するのに少々時間がかかりました。なので、会社のアナロジーを導入して説明すると、次のようになります。
- Ananta Manager は非常に偉い役職なので、MUX と Host Agent に仕事のやり方について命令するだけで、自分は手を動かしません。
- MUX と Host Agent は下っ端なので、何も考えず、教えられた通りに仕事をします。
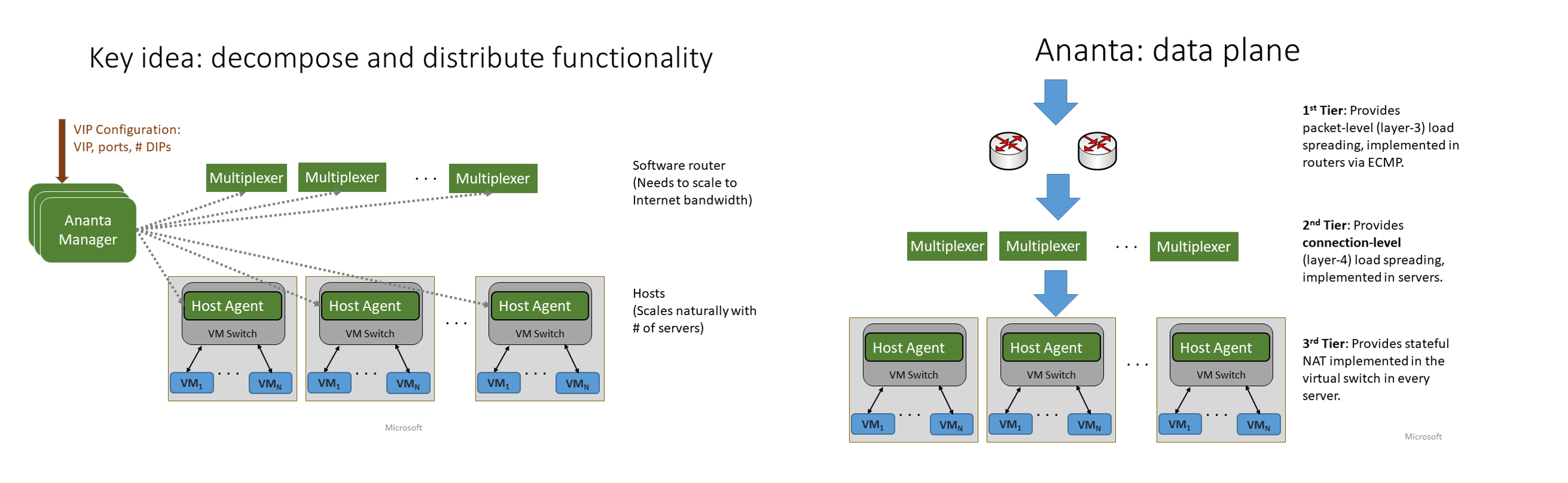
各コンポーネントがどのような役割を果たすか、詳しく見ていきます。
Ananta Manager (AM)
- コントロールプレーンを担うコンポーネント
- MUX と Host Agent の面倒を見る
- AM は DC 内のホスト (VM がデプロイされる物理サーバー) にデプロイされる
- AM ごとに 5 つのコピー (レプリカ, replica) を作成することで冗長化されている
- 提供する主な機能:
- MUX が管理すべきサービスのデータを、MUX に共有する
- SNAT で必要な諸々の管理

MUX (Multiplexer)
- データプレーンの真ん中のティアに存在
- 汎用的な x86 サーバー上でソフトウェア実装されている
- MUX も HA 同様 DC 内部のホスト (物理サーバー) 上にデプロイされている
- MUX はチームとして動く
- このチームを MUX プールと呼ぶ
- 典型的には一つの MUX プールに 8 個の MUX が存在 (レプリカではない)
- プール内のすべての MUX は同じ情報を共有する
- AM からチーム全体に対して、チームで担当すべきサービスの情報 (VIP と DIP の対応表、負荷分散の規則、SNAT の情報、...) が共有される
- MUX の主な役割:
- BGP を喋って、ティア 1 ルーターに自分が担当する VIP のリストを知らせる
- 実際にパケットがルーターから届いたときに、ハッシュ計算に基づいて負荷分散先を決める
- 負荷分散先を決めたら、HA に届けるために IP-in-IP によるカプセル化を行って送信する
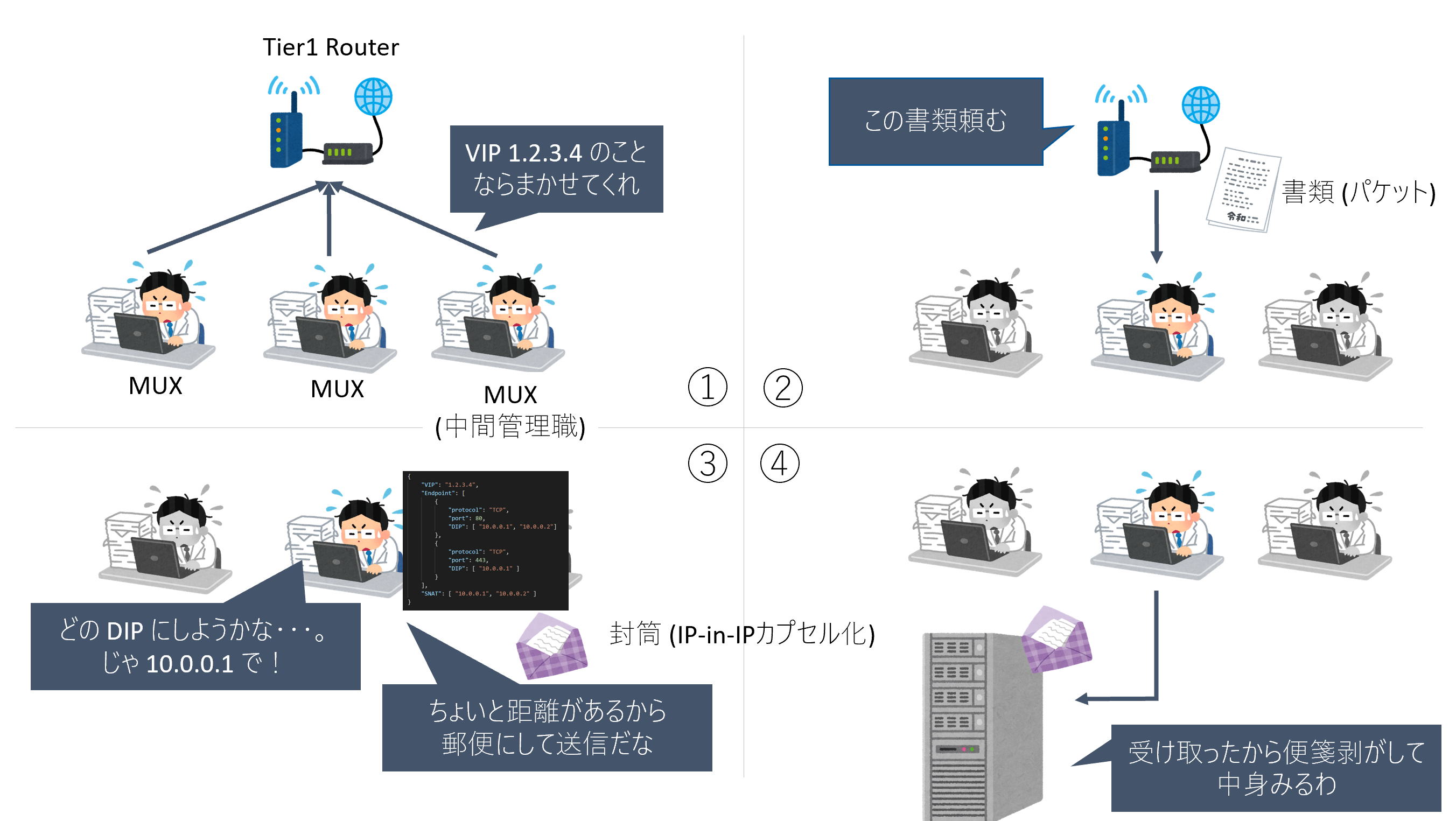
Host Agent (HA)
- データプレーンの一番下のティアに存在
- ハイパーバイザーで動く仮想スイッチ上のソフトウェア
- 主な機能:
- MUX がカプセル化をしたパケットを解く
- 宛先が VIP になっているのを DIP になおす (DNAT)
- ACL に基づいてアクセスを拒否するか受け入れるか決める (ファイアウォールとしての役割)
パケットの流れ
Ananta の SIGCOMM 発表スライドからまんま拝借したスライドを使って、Inbound 通信と Outbound 通信のそれぞれで、パケットがどのような度をするのか解説します。
Inbound 通信
インターネット等 DC 外のクライアントから、VIP に対してアクセスがあったときのパケット フローです。
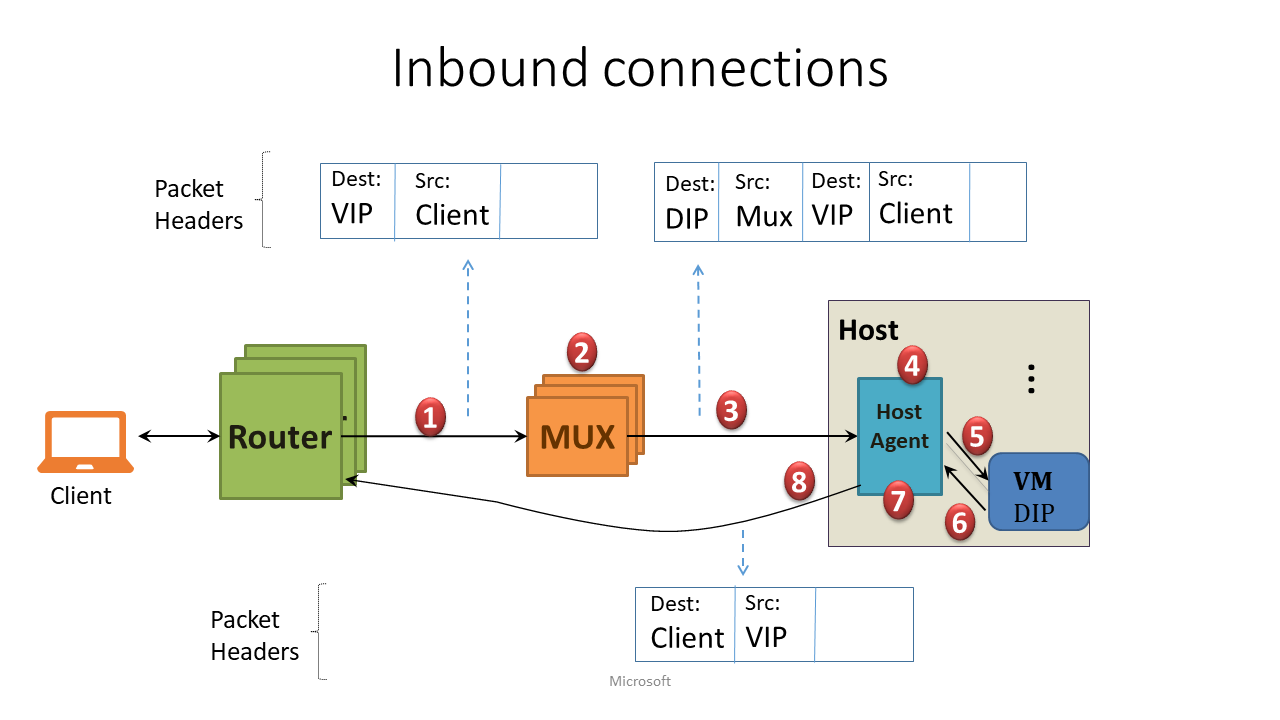
前提: MUX は、ルーターに対して、担当する VIP を経路広報している (ルーターは各 VIP のネクストホップを把握している)。
- パケットが外部から VIP 宛にやってきたとき、ECMP (Equal Cost Multi-Path) プロトコルによって、まず第 1 段階の負荷分散が行われる。つまり、(BGP ピアが張られている MUX のうち) ランダムに選択された MUX のどれかにパケットが転送される。
- MUX はある負荷分散アルゴリズムに基づいて DIP を一つ決定する
- IP-in-IP によってカプセル化されたパケットを、対象の DIP をホストしている物理サーバーの HA に送信する。
- HA はカプセル化を解き (i.e. 外側の IP ヘッダを外し)、DNAT (i.e. 宛先を VIP から DIP に書き換え) を実行。同時に NAT テーブルを更新する。
- HA は このパケット DIP に送信し、VM はパケットを受け取る。
- (ここからは戻りの話) VM が、クライアントの IP アドレス宛のパケットをゲートウェイに送信する
- HA はそれを横取りして、NAT テーブルに基づきリバース NAT を実行 (i.e. ソース IP を DIP から VIP に書き換え)。
- MUX 上で NAT していないことによって、DSR (direct server return) の効果が得られ、DC 内でパケットは MUX を介さずに直接ルーターに運ばれる。そしてクライアントに戻りのパケットが届く。
Outbound 通信
VM からインターネット宛の通信をする際のパケット フローです。
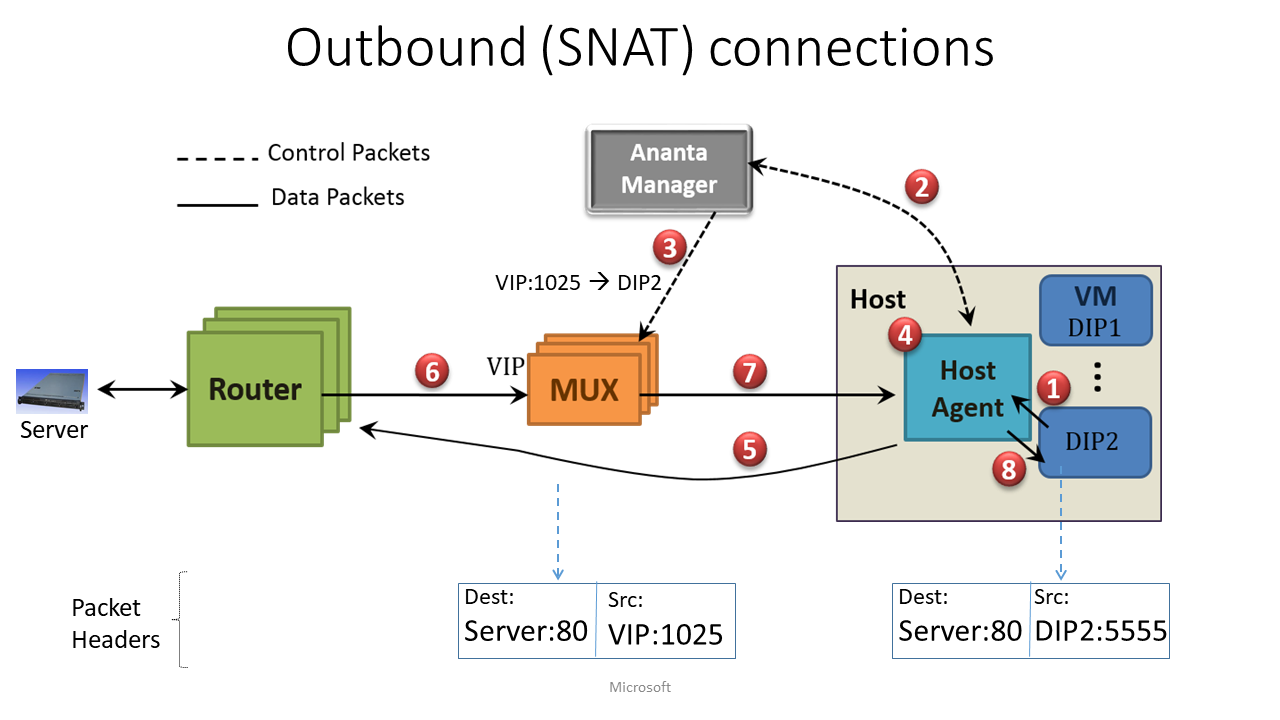
- VM が「ソース IP が DIP, 宛先が任意のグローバル IP アドレス」のパケットをデフォルトゲートウェイに向けて送信する
- HA はこれを検知して横取り。SNAT が必要なパケットであることを確認してから、「DIP 用の VIP と、空いているエフェメラルポートを教えてくれ~」と AM にお願いする
- AM は VIP とポートを用意し、この旨を DIP を担当する MUX のグループに知らせる
- HA もこの情報 (i.e. VIP とポートの組) を AM から受け取る
- HA が、IP ヘッダのソース IP:ポートを通知された "VIP:ポート" に変換 (SNAT) する。変換後のパケットは MUX を介さずルーターに直接渡す
- 戻りのパケットに関しては、Inbound と同様
ここがすごいぞ Ananta
ざっくり以上のような流れでパケットを処理するのですが、細かいところに素晴らしい技術が取り入れられています。ここでは、それらを掘り下げて取り上げます。
FastPath
Ananta では、同一 DC 内サービス間の通信を検知した時に無駄のない通信経路に切り替えます。この機能を FastPath と呼んでいます。FastPath
は、MUX の使用率を大幅に削減することに成功しました。
同じ DC 内にある 2 つのサービス (e.g. サービス 1, 2) があった時、同 DC 内とは言え、お互いはご近所であることを知りません。したがって、サービス間は VIP 同士でやりとりされます。ただ、最初の通信 (i.e. MUX の負荷分散による宛先 DIP の決定) が済んでしまえば、その後は DIP 同士でも通信が可能です 18。
「MUX 経由で送信する必要がない通信に対しては、MUX を介さず直接やり取しよう」というのが、FastPath の気持ちです。

-
DIP1上の VM から、宛先がVIP2の TCP SYN が送信される。VIP2はMUX2の担当なので、Host Agent は、パケットをMUX2に届ける。 -
MUX2はパケットをDIP2に転送する19。 - リプライのパケットは、まず
MUX1に返信される。 -
MUX1は返信パケットをDIP1に転送する。 - TCP コネクションが確立したら、
MUX2はMUX1にリダイレクトのメッセージを送信する。 -
MUX1はDIP2の IP/ポート を Host Agent に通知。 -
MUX1はDIP1の IP/ポート を Host Agent に通知。 - 最終的に、
DIP1とDIP2はMUX*を介さず直接やりとりするようになる。
Staged event-driven (SEDA)
Ananta Manager はたくさんの責務がありますが、タスクに優先度をつけて、ワークロードが増えた場合にでもミッションクリティカルなタスクは続行できるような工夫を実装していています。
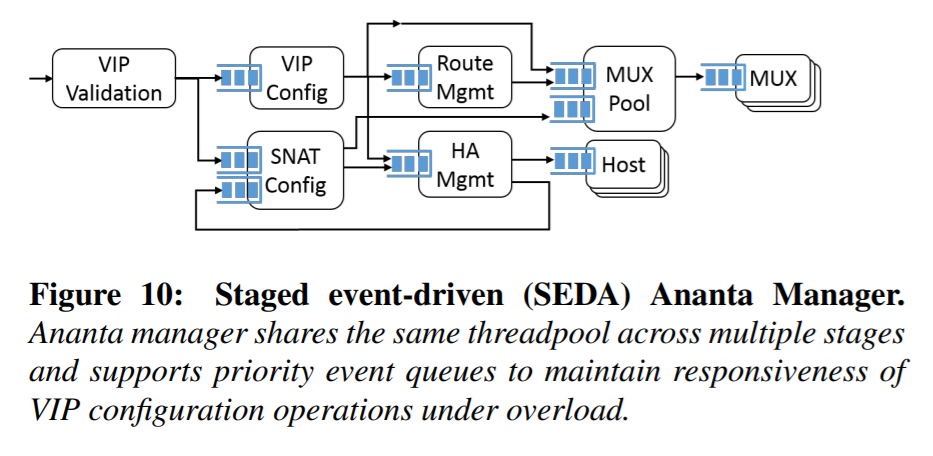
ベース技術は、SEDA (staged event-driven) 20 と呼ばれる、状態遷移を使ったスレッド プールの管理方法です。Ananta では加えて次の 2 点を改良しています。
- 異なる状態で同じスレッドプールを共有できる
- 各状態で複数の順位付きキューを付与できる
Paxos
Ananta Manager は冗長化を目的として 5 つの全く同じコピー(レプリカ)が存在しますが、整合性のためメインに選ばれた 1 台のみが実際に動作します。メインの AM を選ぶために、Ananta は分散システムでの合意形成アルゴリズムである Paxos 21 を利用します。
- Paxosアルゴリズム - Wikipedia
- 今度こそ絶対あなたに理解させるPaxos - Qiita
- ざっくり理解するPaxos - 小野マトペの納豆ペペロンチーノ日記
- Paxos - SlideShare
IP in IP トンネリング
MUX から Host Agent (HA) に送信する際、IP-in-IP (IPIP) トンネリングによって、IP パケットをカプセル化します。この結果、MUX と HA をネットワーク的に遠い場所に配置できるようになります。つまり、物理的ではなく、仮想的な同一 L2 セグメントに MUX と HA がいれば通信できる訳です。
この技術は HA 間の通信にも適用されます。Azure では、任意のホスト (物理サーバー)に VM がデプロイされるので、同一 L2 セグメントに配置しなくてはならないという制約は非常にボトルネックになってしまいます。
DSR (Direct Server Return)
Inbound 通信の戻りの際、Host Agent は MUX を介さず、直接ルーターにパケットを送信します ("Inbound" セクションのステップ 8 に相当する)。これは DSR (Direct Server Return) の一例となっています。MUX にいちいち戻り通信が帰ってこないので、MUX の負担を軽減することができるのですが、このテクニックを実現する鍵は「Host Agent 上での DNAT」です。
一般的な NAT の話として、NAT する場合はリバース NAT もしなければ通信が成り立たないため、NAT 装置を無視して戻り通信を送信することはできません。なので、もし MUX 上で DNAT (VIP -> DIP) してしまうと DSR は実現できません。Ananta では、ロードバランシングに不可欠な DNAT 機能を MUX から切り離し、HA に委任するアーキテクチャによって DSR が実現されています。
TCP コネクションの永続化
パーシステンスのために、MUX はコネクションと DIP の対応関係をフロー テーブルに記憶します。ただ、ティア 1 ルーターが選ぶ MUX は、BGP の ECMP を使っている限り、ランダムに決定されます。そのため、フロー テーブルを MUX プールで共有することで、どの MUX にトラフィックが来ても TCP コネクションを張っている DIP に割り振ることができます。
冒頭にも紹介したように、Azure Load Balancer はバックエンド プールに新しいサーバーを追加しても、既存のセッションに関しては新しいサーバーに振り分けられることはありません。この動作は、バックエンド プールからの VM の切り離しでは、MUX のフロー テーブルがリセットされないことに起因していますが、「バックエンド プールからの切り離し = Ananta Manager が MUX Pool に割り振る情報の変更」なので、これが MUX pool で共有している現在のフロー テーブルと関係ないことからも納得の動作とわかります。
ちなみに、フロー テーブルをリセットするには、VM の再配置が必要となります (再配置を伴う特別な VM の再起動)。
まとめ
この記事では、Ananta が Azure の特性の合わせて作られた L4 のロードバランサー & SNAT 装置であることをみてきました。
ロードバランサーとしての Ananta は、MUX と呼ばれる装置が主だって負荷分散しています。従来の H/W LB では 1+1 冗長化しか達成できませんでしたが、Ananta は MUX プールに存在する複数 MUX を Ananta Manager によってコントロールすることで N+1 冗長化を実現しました。MUX はデーターセンターの任意のホストにデプロイされるために、結果として、MUX の可用性と DC の可用性はほぼ等しくなります。そして、MUX をコントロールする Ananta Manager もまた、Paxos や SEDA といった技術でホットスタンバイのレプリカが作成できるため、データプレーン・コントロールプレーンともに高度な冗長化が実装されています。
また、Host Agent でも、多くのロードバランシング タスク (e.g. 負荷分散の DNAT, ステートフル L4 ファイアウォール) のオフロード、FastPath、DSR といった技術によって、MUX の負担を減らしていることを紹介しました。代わりに Host Agent での処理負担が増えてしまいますが、それは論文の Figure 11 の通り、MUX への負荷集中を考慮すればかなり限定的なものです。寧ろ、多くの処理を Host Agent 側にオフロードしたことによって、実装の最適化がしやすくなりました。実際に、2017 年に提案された VFP (virtual flitering platform) 5 では、Open vSwitch に着想を得てスイッチをコントロール/データ プレーンに分解し、処理の高速化・スケールを可能としました。また、VFP の処理の一部をハードウェア実装した SmartNIC6 が 2018 年にも提案されています。
2019 年 12 月現在、Ananta はもはや進化に進化を重ねてしまい、そのままの形では Azure の DC で使われていませんが、そのアーキテクチャの血は依然受け継がれています。冒頭で示したように、進化の一部は公開技術として提供されていますが、まだ非公開のものも多くあります。Azure のロードバランサー/データーセンターに関する新たな技術資料が公開され、そしてそれを皆さんに共有する機会が来ることを、いち Azure ファンとして楽しみにしています。
参考文献
- PPT - Ananta: Cloud Scale Load Balancing PowerPoint Presentation, free download - ID:1614411
- ロードバランサのアーキテクチャいろいろ - yunazuno.log
- サポート エンジニアが Azure Networking をじっくりたっぷり語りつくす会 (p.37--)
- 詳説 Azure IaaS ~私はインフラが好きだ~ | de:code 2016 | Channel 9 (50 分過ぎ~)
- ロードバランサ - 基本構成、IPアドレス割り当て、アドレス変換、用語説明
- Introduction to modern network load balancing and proxying
- Building a Billion User Load Balancer | USENIX
- 自作ロードバランサ開発 (pdf)
-
Patel, Parveen, et al. "Ananta: Cloud scale load balancing." ACM SIGCOMM Computer Communication Review. Vol. 43. No. 4. ACM, 2013. https://conferences.sigcomm.org/sigcomm/2013/papers/sigcomm/p207.pdf ↩ ↩2
-
今回紹介しきれなかったこれらの論文も大変興味深いので、いつか紹介したいと思っています。 ↩
-
Gandhi, Rohan, et al. "Duet: Cloud scale load balancing with hardware and software." ACM SIGCOMM Computer Communication Review. Vol. 44. No. 4. ACM, 2014. ↩
-
Gandhi, Rohan, et al. "Rubik: unlocking the power of locality and end-point flexibility in cloud scale load balancing." 2015 {USENIX} Annual Technical Conference ({USENIX}{ATC} 15). 2015. ↩
-
Firestone, Daniel. "VFP: A Virtual Switch Platform for Host SDN in the Public Cloud." 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). 2017. VFP: A Virtual Switch Platform for Host SDN in the Public Cloud - Microsoft Research ↩ ↩2
-
Firestone, Daniel, et al. "Azure accelerated networking: SmartNICs in the public cloud." 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18). 2018. ↩ ↩2
-
SmartNIC に関しては、次のような資料も理解の役に立ちます。 ↩
-
Systems & networking - Microsoft Research にネットワーク関連の技術が公開されています。 ↩
-
Docker に慣れている人は、
docker-compose.ymlで指定するservices:を想像するとわかりやすいかもしれません。Docker でのサービスの説明は "Part 3:サービス — Docker-docs-ja 17.06.Beta ドキュメント" にあります。 ↩ -
最近では、たくさんの小さなサービスで一つのアプリケーションを構成する設計思想 "マイクロサービス アーキテクチャ" が有名ですね。同じ Web アプリケーションでも、アプリケーション全体を一つのサービスで構成するのか、それとも複数のサービスを組み合わせるのかといったように、サービスの粒度は人間の裁量次第です。 ↩
-
なぜ VIP には「仮想」という名前がついているかと言うと、特定のネットワーク インターフェース (NIC) に関連付けられた "物理的な" IP アドレスではないからです。 ↩
-
LB のバックエンドに居るホストのことを 実サーバー (real server)、あるいはバックエンド サーバー等と言いますが、Azure では実サーバーは「仮想マシン」である点に注意してください (本記事では、ややこしいので実サーバーという呼称は使いません)。 ↩
-
Azure は雲ではありません… ↩
-
Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network – Google Research ↩
-
SLA を満たす最適な資源割り当てに関する手法. Dynamic Resource Allocation in the Cloud with Near-Optimal Efficiency - Microsoft Research ↩
-
また、受け取る VM (e.g. `DIP11) 側の気持ちになってみると、宛先 IP アドレス が VIP (e.g. VIP1) のままではパケットを受け取ったときにびっくりしてしまいます。なので負荷分散先の VM が決まったら、宛先を DIP に変換しなければなりません。Destination IP Address を NAT するので、この処理は DNAT と呼ばれます。 ↩
-
Azure ではネットワークセキュリティグループ (network security group; NSG)、AWS ではセキュリティーグループ、GCP ではファイアウォールルールと呼ばれる機能で提供される、L4 のステートフル ファイアウォールです。 ↩
-
DIP は VM 内部で有効な IP アドレス (いわゆる仮想ネットワークのアドレス) なので、DC 内部での物理 L3 ネットワークで有効ではありません。DIP 同士の通信でも、依然 IP-in-IP カプセル化によって L2 セグメントを越える必要があります。 ↩
-
ステップ 2. について、この時 Host Agent から送られたパケットの宛先 IP アドレスはあくまで
DIP2でありVIP2でははないので、インターネットからの通信とはちょっと動作が違う点に注意。 ↩ -
M. Welsh, D. Culler, and E. Brewer. SEDA: An Architecture for Well-Conditioned, Scalable Internet Services. In SOSP, 2001. ↩
-
L. Lamport. The Part-Time Parliament. ACM TOCS, 16(2):133–169, May 1998 ↩