概要
Webスクレイピングを行うには、Pythonなどのプログラミング言語を使う方法、Selenium等のWebアプリケーションオートメーションツール、UiPathやAutomation AnywhereなどのRPAツールなど、様々な方法があります。しかし、どのツールを使っても「スクレイピング」を行う方法は本質的に同じです。つまり、HTMLページ内のタグ構造を解析して、タグにはさまれたテキストや、タグの属性値、あるいは画像などのファイルをデータとして取得しているのです。使うツールによってどれくらいプログラミング言語の知識が必要か、HTMLの知識が必要か、といった難易度が異なってきます(^^♪
タグの構造解析をする際にはHTMLページの構造によってやりやすさ/やりにくさがあります。この記事では一般論としてスクレイピングしにくいページの特徴をメモします。
Webスレイピングがたやすいページ
スクレイピングはWebページ内の以下のようなHTMLタグの構造を解析してデータを取り出します。ページの中には同じタグが複数回出てきたり入れ子になっていたりしますが、一般的には「DOMXPath」と呼ばれる手法で、HTMLページの中の特定のタグの位置を表すことができるので、DOMXPathで指定された場所のタグや属性を抜き出すことでスクレイピングが成立します。
<div class="dress" id="table1" name="hogehoge">テキスト</div>
class、id、nameなどの属性は、特定のタグを指定するための一意の識別子、もしくは候補がだいぶ絞られる識別子となるため、これらの属性がタグにたくさんついていると、スクレイピングがしやすくなります。
また、以下のような表構造の場合はこの構造を認識して一括してCSVやExcelの形でファイルに抜き出す仕組みを持っているツールもあります。表は複数ページにわたっていてもよく、ページめくりのボタンを指定しておけば、ツールが自動的にページをめくって最後のページまでのデータを取得してくれます。
<tr>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
</tr>

表については<tr><td>のタグでなくてもよく<div>や<li>など他のタグでも「繰り返しパターン」のデータとして認識されます。
繰り返しパターンのデータでは、id/name属性がついていないと一意の場所が指定しにくいと思うかもしれませんが、特定の種類のタグの「XX個目の出現」というふうに何番目のデータを取得したいかをDOMXPathでは指定が可能です。
また、Webアプリケーション等では、利用にあたってサインインが求められる場合がありますが、そのような場合はサインインのロジックをあらかじめ組むか、スクレイピングに使うブラウザーの別タブであらかじめサインインしておけばOKです。サインインロジックはRPAなどの自動化ツールで簡単に作成できます。
HTMLページの先にある画像のダウンロードも、タグの属性からURLが取得できれば可能です。Automation Anywhere等、RPAでもファイルのダウンロード機能が標準であるものがあります。
このように、Webスクレイピングでは、タグの構造解析を行うことで様々なWebページのデータを自動的に取得できてしまいます。
Webスクレイピングがしにくいページの特徴
ところが、万能に思えるWebスクレイピングの手法にも解決が難しいことがあります。以下に代表的な例を挙げます( ;∀;)
タグ構造が細切れのページ
構造自体は表になっていても、表構造が細切れになったものの集合体になっている場合があります。
たとえば以下の構造
<tr>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
<td>テキスト</td><td>テキスト</td><td>テキスト</td><td>テキスト</td>
</tr>
を画像で

と書くとすると、たとえば
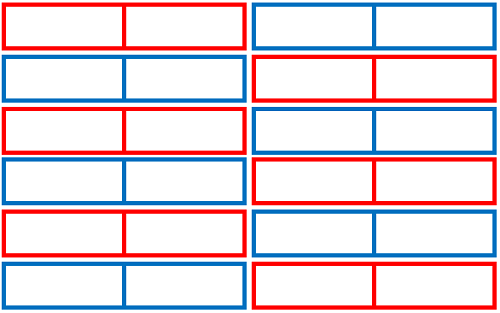
というような複数の小さな表の集合体の構造になっています。
ツールだとこのような表をスクレイピングしようとすると、一番小さな単位の表のみが取得可能で、きちんと全体を取得するにはPythonなどによるプログラミングによるスクレイピングが必要となります。
タグ構造が不規則なページ
一見、通常の繰り返しパターンの表のようにも見えるタグ構造なのですが、それぞれの繰り返しで微妙に違うタグが入ってきたり、途中で全然異なるパターンが挿入されたりする場合です。『ちょっとだけ規則正しくない繰り返しパターンのデータスクレイピングを試してみた』にいくつかパターンが記載されています。
この場合、ツールでどこまで対応できるかは、そのツールのパターン認識の柔軟性に依存していて、場合によってはデータが全く取れなかったり、取れても一部分が歯抜けになる場合があります。そのようなページでWebスクレイピングを行うには、ページの繰り返しパターンの癖をよく理解したうえでのプログラミングが必要になってきます。
例:
Qiitaトレンド

マイナビAgent

Google検索
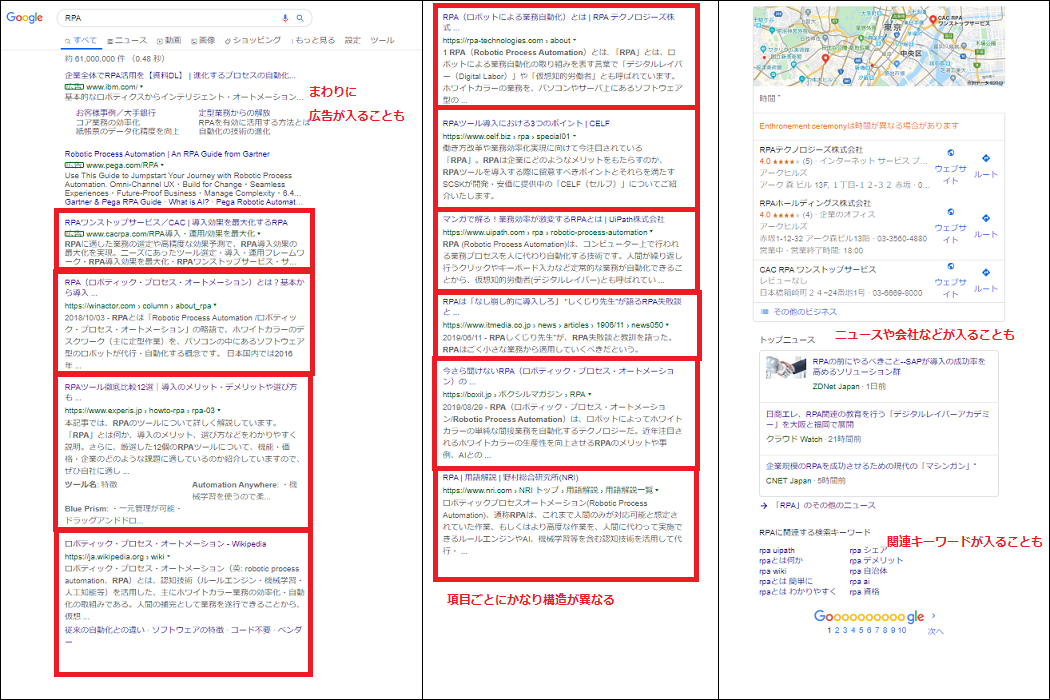
データ部分が画像になっている
表やデータの部分が画像として挿入されてしまっていると、画像認識エンジンを使って画像の分析をしないといけなくなるので、スクレイピングの手法が全く変わってしまいます。RPAでは画像内の文字を読み込める仕組みを持ったものがありますが、精度は悪くなります。Pythonなどのプログラミング言語でも、画像認識ライブラリを使えば不可能ではないですが、DOMXPathの手法とは全く異なる手法になるので難易度はかなり上がります。
Javascriptで動的に描画されるページ
最近のモダンなスタイルのWebページの中には、そのままソースを表示してもJavascriptのコードがたくさん書いてあるだけでHTMLタグがほとんどない場合があります (Reactなど様々なJavascriptライブラリがあります)。そのようなページではJavascriptで動的にページが描かれています。
単純にページ読み込み後にJavascriptで動的にHTMLタグを描画するだけであれば、SeleniumやRPAツールを使うことで簡単に描画済みのHTMLタグを取得できます(^^♪
しかし、さらに、最初のページ読み込み時の描画だけではなく、以下のような追加の描画を都度行っているパターンがあり、この場合は難易度が上がります( ;∀;)
- ページをスクロールしていくと表の続きが表示される (Salesforce.comのLightningページやEdgeのホームページのMicrosoft Newsなど)
- ドロップダウンリストで値を指定すると、ページの内容が動的に変わる
- ニュースサイトの記事一覧のように「続きを見る」をクリックするたびにパネルが10個表示され、表示数が増えていく
さらに、下の方が表示されると動的に上に隠れた要素をHTMLから消してしまうようなページもあります。
そのようなページでWebスクレイピングを行うには、ページの動的HTMLタグ描画の癖をよく理解したうえでの個別対応のプログラミングが必要になってきます。これは面倒くさい( ;∀;)
Pythonによる様々なプログラミングテクニックが『Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応』で紹介されているのでご参考まで(^_-)-☆ SeleniumはPythonからAPIとして呼ぶこともできるので、組み合わせで使われることも多いです。