データスクレイピングとは
「Webサイトから情報を抽出するコンピュータソフトウェア技術」のことです。ページの特定の領域からひとつのフィールドの情報だけ取り出す場合もあれば、表や繰り返しパターンになっているページから、パターンになっているフィールドの情報をまとめて取り出す場合もあるんですよね。パターン情報の抽出はとても便利で、さまざまな情報集約サイトから情報の一覧を取ってくるのに役立ったりします。
Webページは、ブラウザーにページが読み込まれてから動的にタグが生成されるものもあるため、HTMLソースをダウンロードして解析するだけだとダメな場合があります。プログラミングをする場合は、ブラウザーのDOMを使ってXPathの解析を行っていく手法が必要です。
ただし、困るのはWebサイトによっては一覧の表示がちょっとだけ規則正しくないパターンになっている場合があるんです。そのような場合、完全にカスタムプログラミングをして想定されるパターンを実装すれば抜き出せるのですが、プログラミングが面倒くさかったりそこまで作れない場合は、RPAソフトウェアでお手軽にできると理想的です。
使用するRPAソフトウェアは、UiPathとAutomation Anywhereの2つです。これらはいずれもCommunity Editionが無料で取得でき、かつRPAソフトウェアの中では技術的に優秀な部類に入ります。この2つにどこまでできるかやらせてみましょう!
利用した環境
- UiPath Community Edition (2019.10.0-beta.227)
- Automation Anywhere Community Edition 11.0.0.0 (Build19922720)
※ Webサイトの作りも含め、いずれも2019年10月現在の情報です
RPAソフトウェアにおけるデータスクレイピング手順
繰り返しパターンの1項目目、2項目目で同じ要素を指定することで、RPAツールが繰り返しパターンを認識する仕組みになっています。
UiPath Community Edition
Internet Explorerで対象となるWebページを開いておきます。そしてUiPath Studioでまず新しいプロセスを作ります。
ツールバーの「データスクレイピング」を押します。
新しいレコーディングシーケンスを作成します。
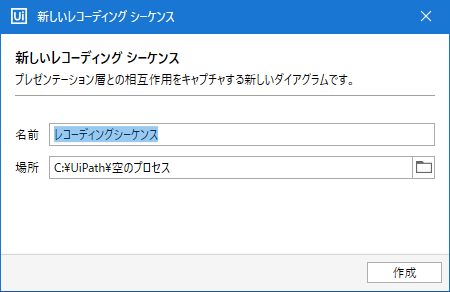
取得ウィザードを進めます。

マウスで繰り返しパターンの最初の項目の中の取り出したい要素をクリックして選択します。(マウスを動かすと、選択領域が四角で囲われます)

次に第2の要素の選択を同様に行います。(※選択モードの時は、なぜかマウスのホイールが効かないので、Internet Explorerのページ内で下の方のコントロールを選択するには、カーソルキーの上下で画面スクロールをすることになります)

正しく選択されると、Internet Explorer上で同じ要素のパターンがハイライトされます。列に名前を付けて先に進みます。

プレビューが表示されます。「相関するデータを抽出」でほかの列も必要に応じてデータを選択します。
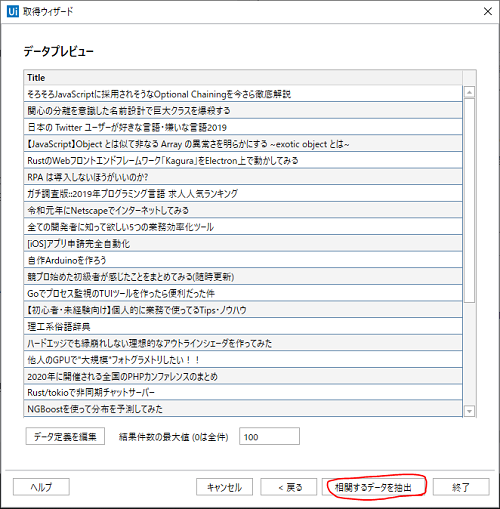
必要な回数だけ「相関するデータを抽出」と要素の選択を行い、列を追加します。追加が終わったら「終了」します。

最後に、複数ページにまたがるデータかどうかを聞いてくるので、必要に応じて次のページをめくるためのボタンを選択します。
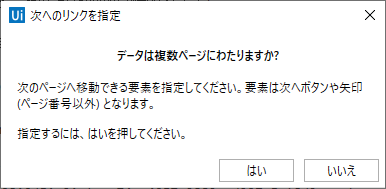
すると、以下のようなシーケンスが生成されます。

「構造化データの抽出」の直後に、「CSVに書き込み」アクティビティを最後に追加します。書き出すCSVファイル名と、「構造化データの抽出」のプロパティを見て「出力 > データテーブル」のところに記載がある変数名 ("ExtractDataTable")を記載します。

以上で、終了です。
Automation Anywhere Community Edition
AACEでは、Web Recorderを選択した状態で「Record」メニューで開始します。

URLには、対象とするWebページのURLを入力します。
その後、この画面が出る場合は「OK」を押します。
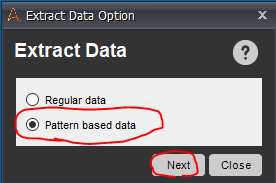
Web Recorderツールバーでは、「Extract Data」をクリックします。

オプションでは「Pattern based data」を選択。
指定したページがInternet Explorerで開くので、繰り返しパターンの最初の項目の中の取り出したい要素をクリックして選択します。(マウスを動かすと、選択領域が二重線の四角で表示されます)
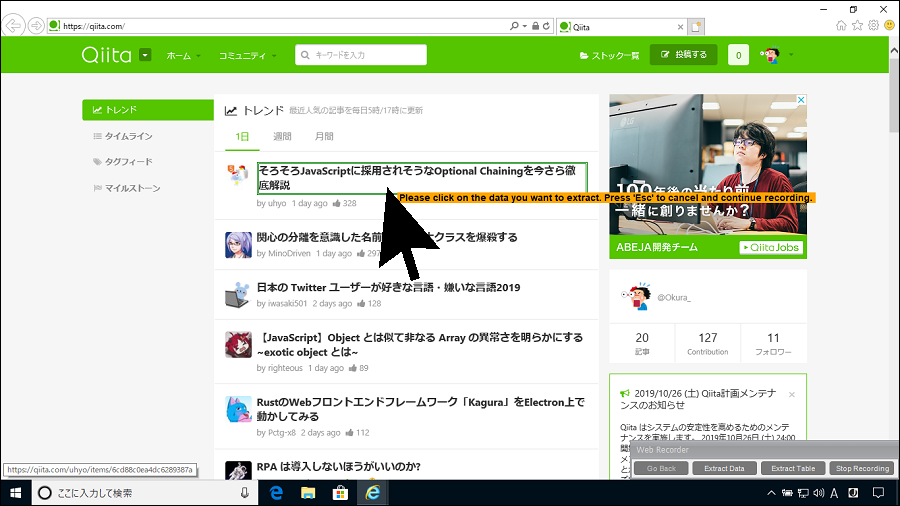
選択後、表示される要素が正しければ「Capture」します。
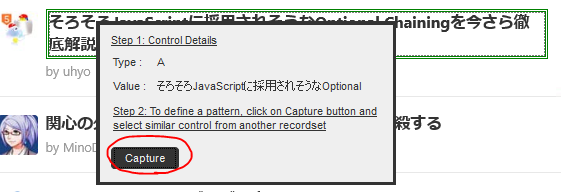
その後、2項目目の同じ要素をクリックして選択すると、列名を入力するダイアログがでるので、列名を適当に入れて「Save」します。
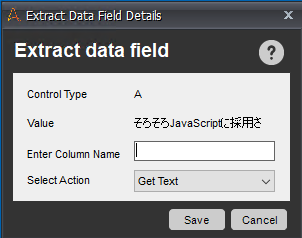
Extract Multiple Data Wizardダイアログボックスの中で、他にも必要な要素があれば「Add」で同様に1項目目と2項目目の要素をクリックで選択していきます。取り出す要素はText、URL、画像など選ぶことができます。終わったら「Next」を押します。
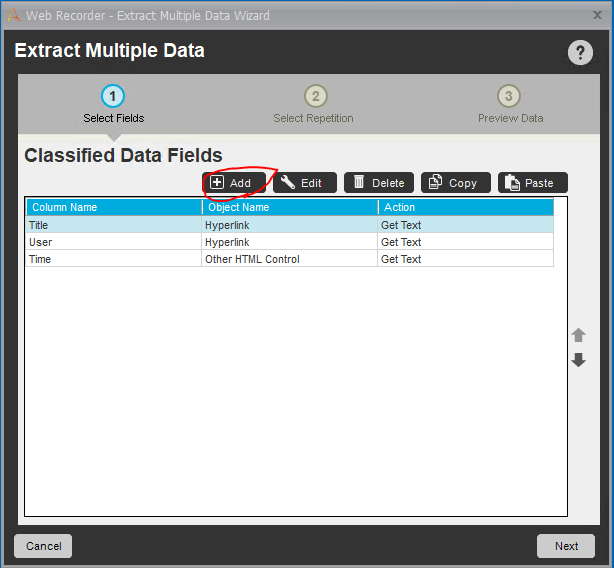
複数ページにわたるデータの場合は「The data spans across multiple pages」をチェックして、次のページに移動するボタンを「Capture」します。
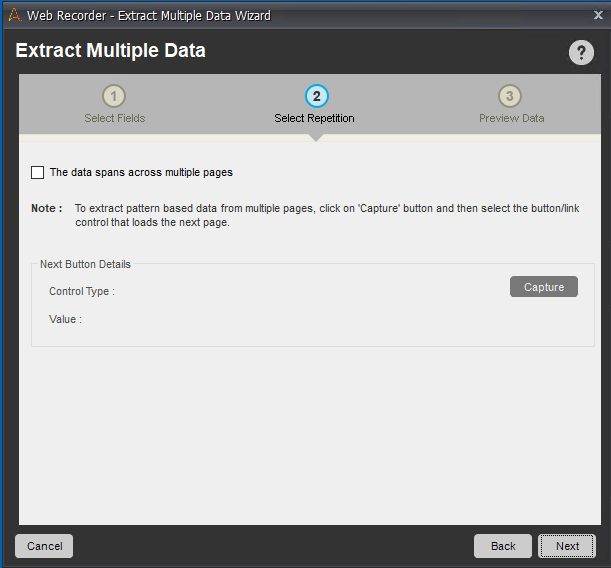
最後のページで「Preview」を見つつ、出力するCSVを指定すると終了し、コマンドが出力されます。Previewで正しく結果が表示されない場合は、実行時に正しくCaptureされません。

Web Recorderツールバーで「Stop Recording」を押して、TaskBotを保存する名前を指定したら終了です。

アクションリストが生成されました。

ちょっとだけ規則正しくないパターンを試してみた
いくつかのWebサイトで試してみました。
Qiita トレンド
Webページの特徴
- 単一ページ (30項目)
- 時々
newアイコンや、フォロワーのアイコンが出現

<div>
<div class="tr-Item">
<a class="tr-Item_userImage">
<img src="(プロファイル画像)" alt="(ユーザー名)"/>
</a>
<div class="tr-Item_body">
<a class="tr-Item_title" href="(記事URL)">(記事タイトル)</a>
<div class="tr-Item_meta">
<span class="tr-Item_new">new</span> 👈👈 このspanタグは現れたり現れなかったりする
<span>(ユーザー名)</span>
<time>(投稿日)</time>
<div class="tr-Item_likeCount tr-Item-liked"> 👈👈 このクラス名は場合により変わる
<span class="fa fa-thumbs-up mr-1of2">...</span>
(Like数)
</div>
<a class="tr-item_followingLikerImage">...</a> 👈👈 このaタグは現れたり現れなかったりする。現れるときは複数個の場合もある
</div>
</div>
</div>
取得するデータ
記事タイトル (Title)、ユーザー名 (User)、投稿日 (Time)
結果
UiPathの場合
UiPathの場合、正解と同じデータがきちんと取得できました。ちょっとくらいの不規則なパターンは無視してくれるようです。
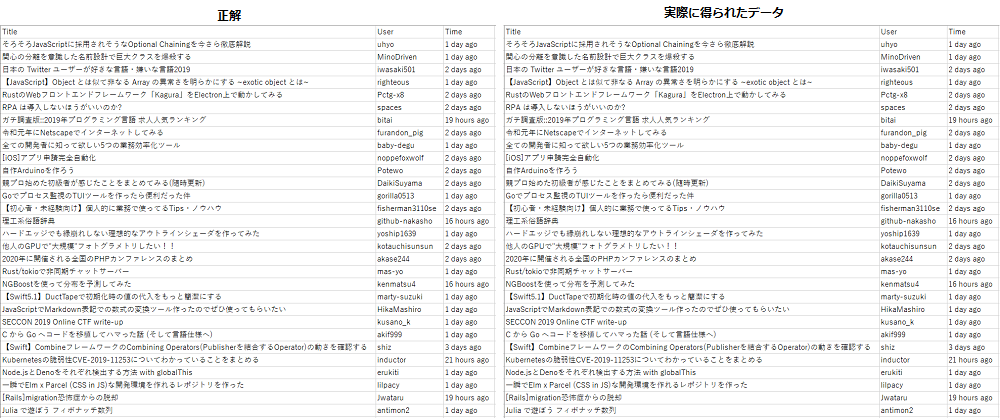
Automation Anywhereの場合
AAの場合、「new」アイコンが表示されている項目のところでユーザー名が取得できませんでした。なぜか、データが取得できなかった行が空欄になるのではなく、表全体で上に詰められるという不思議な動きになりました。一度全部メモリに読み込んでから成形したうえで出力しているのでしょうか??

【この勝負ではUiPathに軍配が上がりました。】
マイナビAgent (SE・システムエンジニア(IT/通信/インターネット) 求人一覧)
Webページの特徴
- 複数ページ (30項目/ページ、全体で約6,000件)
- 項目のラベルが複数個出現
- 各ページで10-11項目、20-21項目の項目間に広告が入る

<ul class="searchResultList">
<li class="sdw">
::maker
<a>
<div class="conditionsBox">
::before
<p class="company">(会社名)</p>
<p class="job">(概要)</p>
<ul class="tags pc">
<li>(タグ1)</li>👈👈 このliタグは現れたり現れなかったりする。現れるときは複数個の場合もある
:
<li>(タグn)</li>👈👈 このliタグは現れたり現れなかったりする。現れるときは複数個の場合もある
</ul>
::after
</div>
<div class="descriptionBox">
<div class="incomelocation">
<dl>
<dt class="income">年 収</dt>
<dd>(年収)</dd>
</dl>
<dl>
<dt class="location">勤務地</dt>
<dd>(勤務地)</dd>
</dl>
</div>
<dl class="pc">
<dt class="icnJob">仕事内容</dt>
<dd>(仕事内容)</dd>
</dl>
<div class="icnJob sp">(仕事内容)</div>
<dl class="pc">
<dt class="icnQual">応募条件</dt>
<dd>(応募条件)</dd>
</dl>
</div>
</a>
</li>
</ul>
取得するデータ
会社名 (Company)、年収 (Salary)、勤務地 (Place)、仕事内容 (Description)、応募条件 (Requirements)
結果
UiPathの場合
3ページ目までは間に入る広告は無視して順調に正しいデータを取得していたのですが、なぜか4ページ目の途中 (最初の広告の手前)で処理が終了してCSV出力になりました。よく調べてみると、「構造化データを抽出」(UiPath.Core.Activities.ExtractData)のプロパティに「結果の最大数」という要素があり、既定ではこれは100になっています。この値を増やすことで全データを取得できるようになります。

Automation Anywhereの場合
特に歯抜けなく、全データを正常に取り終わりました。
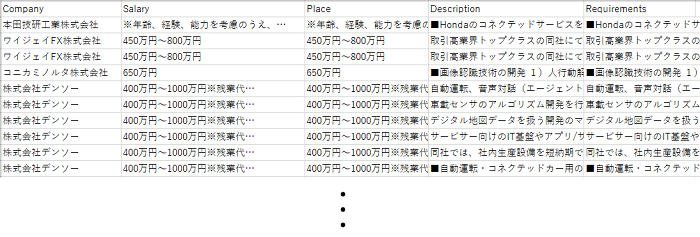
【この勝負はドローです。】
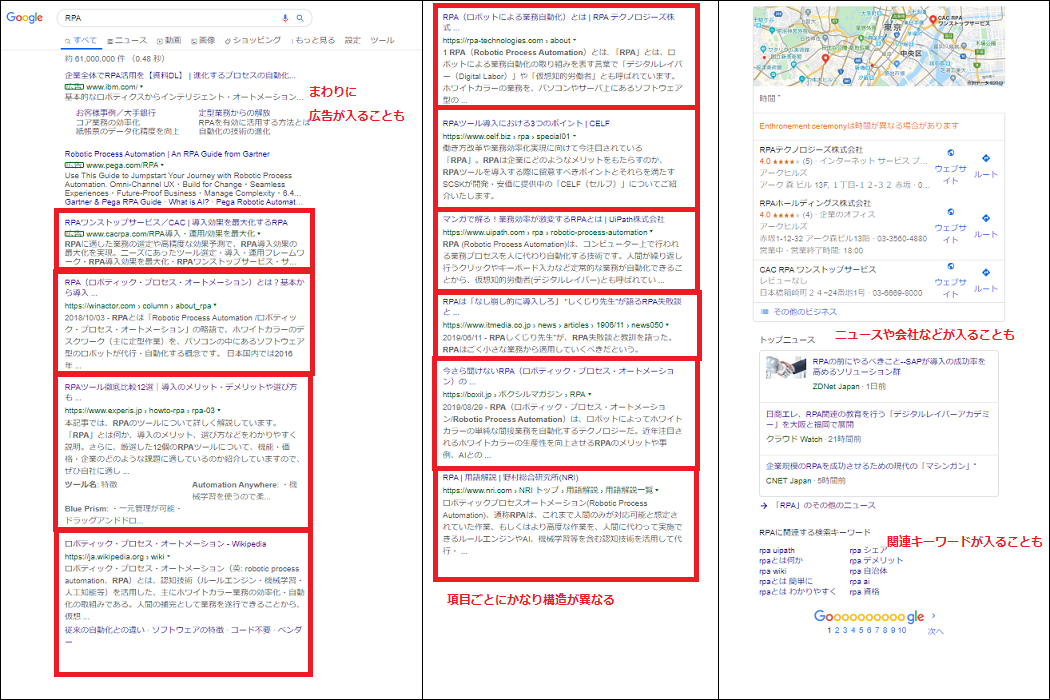
Google検索 (RPAと検索)
Webページの特徴
- 複数ページ (10項目/ページ、1ページ目は9項目になることも?)
- 広告や関連する会社、ニュース、キーワードなどが前後に入る
- 項目により要素が異なることがある
<div id="center_col">
<style>...</style>
<div id="taw">👈👈 広告枠 👈👈
<div></div>
<div style="padding:0 16px">...</div>
<div id="tvcap">
<div id="tads" class="C4eCVc c" aria-label="広告" role="region" data-ved="XXXX">...</div>
</div>
<script>...</script>
</div>
<div id="res" class="med" role="main">
<div id="topstuff"></div>
<div id="search">
<div data-ved="XXXX">
<h1 class="bNg8Rb">検索結果</h1>
<div id="rso" eid="XXXX" data-async-context="query:RPA">
<div class="bkWMgd">
<h2 class="bNg8Rb">ウェブ検索結果</h2>
<div class="srg">
<div class="g">👈👈 1項目目 👈👈
<div data-hveid="CAMQAA" data-ved="XXXX">
<div class="rc">
<div class="r">
<a>
<h3 class="LC20lb">(記事タイトル)</h3>
<br>
<div class="TbwUpd">
<cite class="iUh30 bc">(URL)</cite>
</div>
</a>
<span>...</span>
</div>
<div class="s">
<div>
<span class="st">(説明等のコンテンツ)</span>
</div>
<div id="ed_8" data-base-url="/search" data-ved="XXXX">...</div>
</div>
</div>
</div>
<div class="g">👈👈 2項目目 👈👈
(2項目目の同様の繰り返し)
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
取得するデータ
ページタイトル (Title)、ページURL (URL)、概要 (Description)
結果
UiPathの場合
11ページ目の途中まで、広告やその他の項目は無視して順調に正しいデータを取得しました。合計100項目、歯抜けなく取得しました。

Automation Anywhereの場合
TaskBotの構築画面で、ページ内の要素を指定するモードになった時に、なぜかページ要素を選択するための二重線の四角が表示されず、要素を認識しなかったため、TaskBotが作成できませんでした。
【この勝負ではUiPathに軍配が上がりました。】
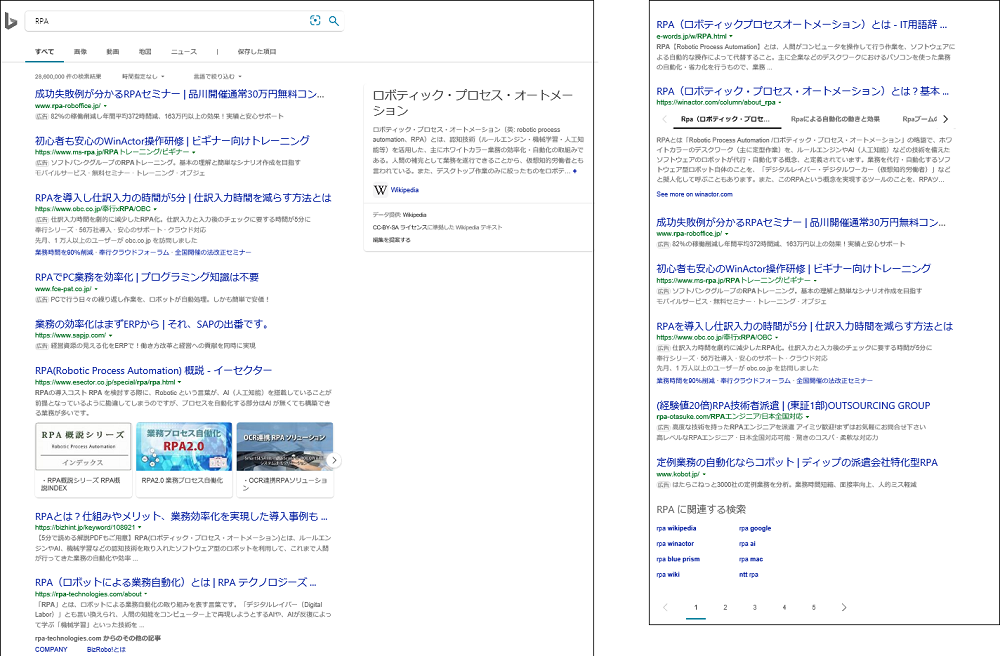
Bing検索 (RPAと検索)
Webページの特徴 (( Google とパターンは異なるがほぼ同じ、ただしバリエーションがより豊富?))
- 複数ページ (10項目/ページ、1ページ目は9項目になることも?)
- 広告や関連する会社、ニュース、キーワードなどが前後に入る
- 項目により要素が異なることがある
取得するデータ
ページタイトル (Title)、ページURL (URL)、概要 (Description)
結果
UiPathの場合
シーケンスの作成及び実行は正常に終了しました。ただし、中を見てみると、ページ内で途中から飛ばしてしまっている項目もあり、完全なデータではありませんでしたが、合計100件分がCSVに出力されました。(黄色から後のデータは2ページ目に飛んでしまっていました。後ろでも同じようなデータの飛びが散見されました)

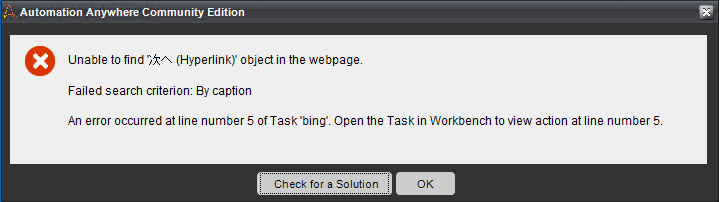
Automation Anywhereの場合
タグの指定とTaskBotの構築は正常に終わりました。実行してみると、2ページ目で以下のエラーが出て止まってしまいました。
CSVへの出力結果を見ると、最初のページでDescriptionがうまく取れていないところがあるようで、最初の6項目だけが取れていました。

【この勝負では両者とも不完全でしたが、できばえがより良いほうという意味でUiPathに軍配が上がりました。】
結論
試したページの中ではUiPathの方が動作安定性が良いように感じました。ただ、ページの構造によってRPAツールにも得手不得手があります。ちょっとだけ規則正しくない場合は、正しくデータをとれるかは検証してみて試すしかなさそうです。