目標
AWSのDynamoDBを構築し、簡単なテーブル操作をAWSコンソール及びAWS CLI上で実行
DynamoDBとは
AWSが提供するキーバリュー型のマネージドデータストアサービスです。
データが3つのAZに分散して格納されるため耐久性が高く、格納容量に上限がありません。
また、キーバリュー形式でレイテンシーが低いため、キャッシュやWEBセッションの格納先としても利用されます。
より詳しくは以下記事が参考になります。
【AWS】今更ながらDynamoDB入門
参考AWSドキュメント
作業の流れ
| 項番 | タイトル |
|---|---|
| 1 | DynamoDBを構築する |
| 2 | DynamoDBテーブルをAWSコンソール上から操作 |
| 3 | DynamoDBテーブルをAWS CLIで操作 |
手順
1.DynamoDBを構築する
①Amazon DynamoDBコンソールへアクセス
②テーブルの作成をクリック
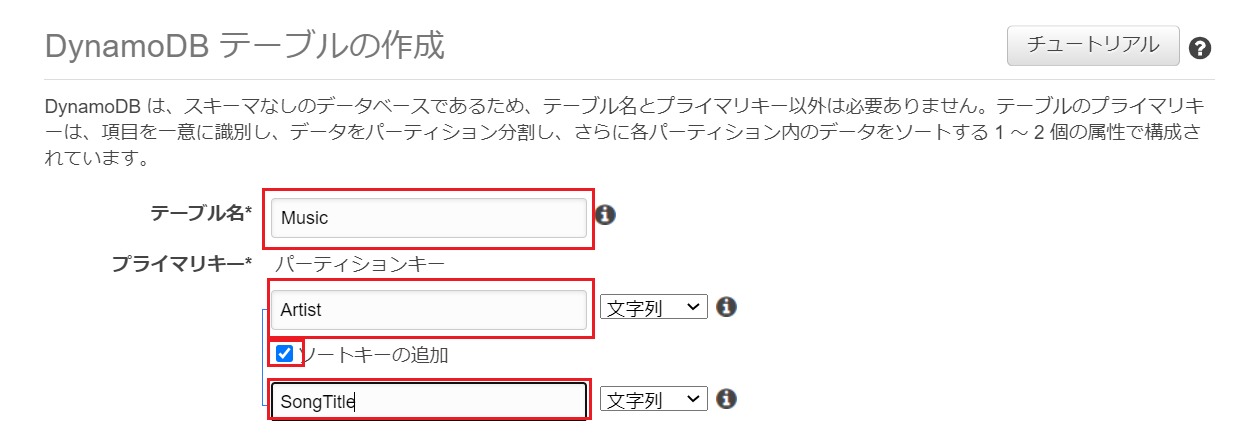
③DynamoDB テーブルのテーブル名とプライマリキーの設定
まず、DynamoDBのテーブル名とプライマリキー(※)の設定を行います。
サンプルとして以下のように設定
テーブル名: Music
パーティションキー: Artist
ソートキー(任意設定): SongTitle
※DynamoDBのプライマリキーに関して
プライマリキー
「パーティションキー」または「パーティションキーとソートキーの複合キー」のこと。
プライマリキーによってデータは一意に識別される。
パーティションキー(設定必須)
このキーへの格納値に従ってどのパーティションにデータが保存されるかが決まるため、
広範囲の値を持ちうるキーを設定することが推奨のようです(各パーティションへのアクセスが均等に分散され、性能向上につながる)。
ソートキー(設定任意)
設定することで、各パーティション内のデータをソートすることが可能となり、
かつAPIではソートキーを指定して取り出すデータの範囲をフィルタできるようです。
より詳しくは以下記事参考
DynamoDBのキー・インデックスについてまとめてみた
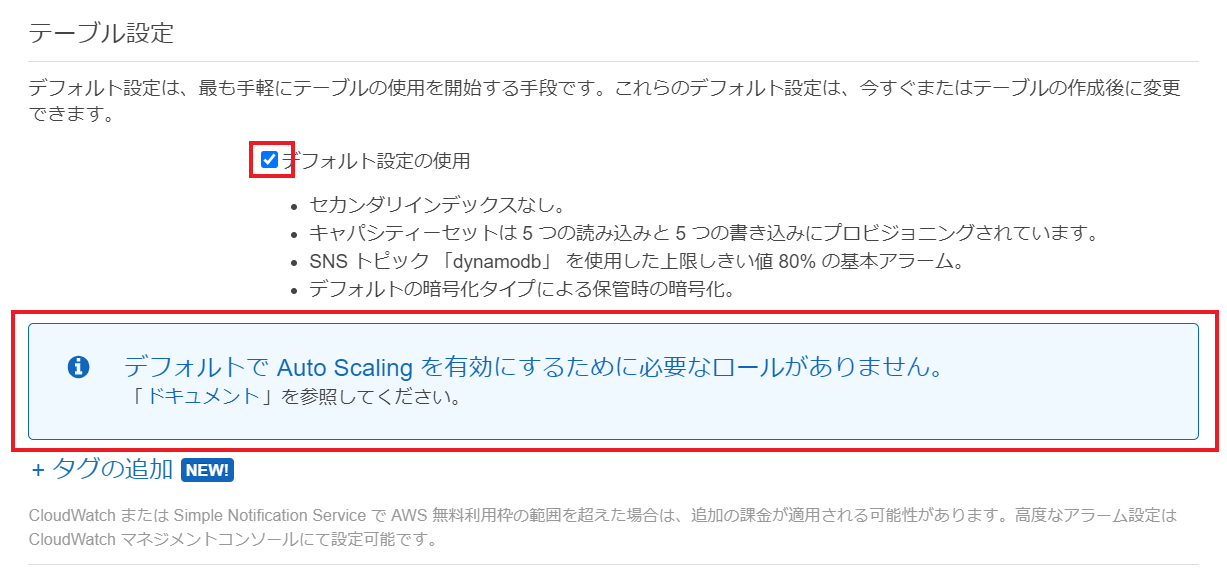
④スループットキャパシティのAutoScaling用ロール作成(任意設定)
設定は任意です。
DynamoDBではRCU(読み込みスループットキャパシティ)とWCU(書き込みスループットキャパシティ)という指標を利用して、
単位時間あたりの読み込み・書き込み量を決定しています。
そのRCUとWCUのAutoScaling機能(自動拡張・縮小)を利用するためのIAMロールがデフォルトでは存在しないため新規作成します。
まずはデフォルト設定の使用のチェックを外します。
DynamoDB Auto Scaling サービスにリンクされたロールにチェックされていること確認
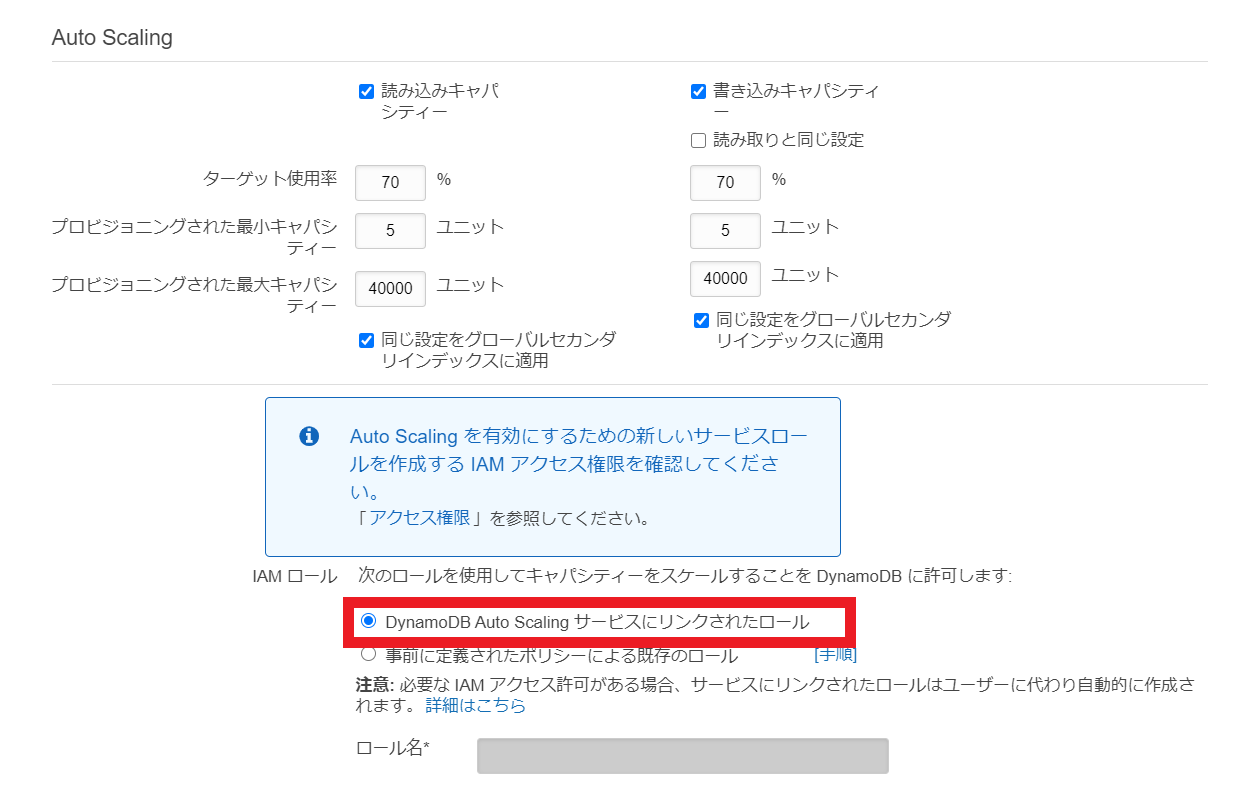
他項目は今回は設定変更無しとします。
最後に作成をクリック
⑤テーブル作成確認
テーブル一覧に追加されたらOKです

2.DynamoDBテーブルをAWSコンソール上から操作
本記事では手順省略致します。
以下AWSドキュメントの「ステップ 2: NoSQL テーブルにデータを追加する」以降を参考に簡単なテーブル操作を試すことができます。
NoSQL テーブルを作成してクエリを実行する
3.DynamoDBテーブルをAWS CLIで操作
いくつかサンプルとして実行してみます。
より詳しいコマンドは以下記事参照
aws cli で DynamoDB を使う
AWS CLIでDynamoDB操作(挿入, 取得, 更新, 削除)
put-item(データ格納)
$ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "FirstSong" }}'
$ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "SecondSong" }}'
$ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Michael" }, "SongTitle": { "S": "FirstSong" }}'
scan(データ一覧)
$ aws dynamodb scan --table-name Music
{
"Count": 3,
"Items": [
{
"SongTitle": {
"S": "FirstSong"
},
"Artist": {
"S": "Ryosuke"
}
},
{
"SongTitle": {
"S": "SecondSong"
},
"Artist": {
"S": "Ryosuke"
}
},
{
"SongTitle": {
"S": "FirstSong"
},
"Artist": {
"S": "Michael"
}
}
],
"ScannedCount": 3,
"ConsumedCapacity": null
}
get-item( 単一データ取得 )
$ aws dynamodb get-item --table-name Music --key '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "SecondSong" }}'
{
"Item": {
"SongTitle": {
"S": "SecondSong"
},
"Artist": {
"S": "Ryosuke"
}
}
}
query( 条件に一致するItem取得 )
[ec2-user@ip-172-31-34-150 ~]$ aws dynamodb query --table-name Music --key-condition-expression 'Artist = :Artist' --expression-attribute-values '{ ":Artist"
: { "S": "Ryosuke" }}'
{
"Count": 2,
"Items": [
{
"SongTitle": {
"S": "FirstSong"
},
"Artist": {
"S": "Ryosuke"
}
},
{
"SongTitle": {
"S": "SecondSong"
},
"Artist": {
"S": "Ryosuke"
}
}
],
"ScannedCount": 2,
"ConsumedCapacity": null
}