
NoSQLデータベースであるDynamoDBに今更ながら入門してみようと思います。
こちらの記事を参考に手を動かしながら、感覚をつかもうと思います。
AWS再入門 Amazon DynamoDB 編
また、DynamoDBにはハッシュキー、レンジキーといった概念があるので、それらを理解する為にこちらを参考にさせて頂きます。
- コンセプトから学ぶAmazon DynamoDB【Amazon RDSとの比較篇】
- コンセプトから学ぶAmazon DynamoDB【ハッシュキーテーブル篇】
- コンセプトから学ぶAmazon DynamoDB【複合キーテーブル篇】
Amazon DynamoDBはマネージドなNoSQLデータベースです。RDBMSとは違い、リレーションやトランザクションといった概念がありません。しかし、キャパシティが自動でスケールするなど管理する項目が少ないのが特徴です。また、RDSとは以下の点が違います。
RDS DynamoDB 一貫性 強力 結果整合なので基本的に弱い(強整合性指定も可能) 原子性 ある ない(同じアイテム内の更新であれば可能) 検索条件 SQLのWHERE句で自由自在 事前指定のキーまたはインデックスのみ 可用性 メンテナンスウィンドウあり 基本的に常に利用可 拡張性 スケールアップのみで天井が低い シャーディングによるスケールアウトが可能
結果整合性はS3と同じですね。データ更新直後はデータが取得できなかったり、古いものが取得される可能性があります。
Black Belt Techをぺたっと張っておきます。
DynamoDBの特徴
-
データは3箇所のAZに保存されるので信頼性が高い
-
ストレージは必要に応じて自動的にパーティショニングされる
-
テーブルごとにReadとWriteそれぞれに対し、必要な分だけのスループットキャパシティを割り当てることができる
-
例えば下記のようにプロビジョンする
- Read : 1,000 – Write : 100
- 書き込みワークロードが上がってきたら
- Read : 500 – Write : 1,000
- この値はDB運用中にオンラインで変更可能 – ただし、スケールダウンに関しては日に4回までしかできないので注意
-
使った分だけの従量課金制のストレージ
-
データ容量の増加に応じたディスクやノードの増設作業は一切不要
DynamoDBの整合性モデル
- Write
- 少なくとも2つのAZでの書き込み完了が確認とれた時点でAck
- Read
- デフォルト
- 結果整合性のある読み込み
- 最新の書き込み結果が反映されない可能性がある
-
Consistent Readオプション
- GetItem、Query、Scanでは強力な整合性のある読み込みオプ ションが指定可能
- Readリクエストを受け取る前までのWriteがすべて反映されたレスポンスを保証
- Capacity Unitを2倍消費する
- デフォルト
結果整合性ですが、Consistent Readを設定することで、Writeがすべて反映されたレスポンスが取得出来るようです。これで古いデータを取得する事が無くなると思います。
DynamoDBの料金体系
- Read・Writeそれぞれ25キャパシティユニットまでは無料
- 書き込み $0.00742 :10 ユニットの書き込み容量あたり/1 時間
- 読み込み $0.00742 : 50 ユニットの読み込み容量あたり/1 時間
- キャパシティユニット 上記で「ユニット」と呼ばれている単位のこと
- 書き込み
- 1ユニット:最大1KBのデータを1秒に1回書き込み可能
- 読み込み
- 1ユニット:最大4KBのデータを1秒に1回読み込み可能 (強い一貫性を持たない読み込みであれば、1秒辺り2回)
- 書き込み
1秒間に100KBのデータを書き込むには100ユニット必要で、読み込みには25ユニット必要となるわけですね。
テーブル操作
HTTPベースのAPIで操作するようです。APIは上の通り。
テーブル設計
キーについて
DynamoDBには主に「table」「item(項目)」「attribute(属性)」という3つの概念が現れます。それに従属する概念として「キー」「インデックス」が出てきます。まずはこの辺りを整理していきましょう。
tableというのはみなさん分かりやすいでしょう。概ねRDBで言うところのテーブルに相当し、itemの集合体です。itemについても、概ねRDBで言うところのrow(行)に相当し、attributeの集合体です。そしてattributeといのも、概ねRDBで言うところのcolumn(列)に相当します。
Hashテーブル
'{ "id": {"N": "1"}, "first_name": {"S": "Jun"}, "last_name": { "S": "Chiba"}, "Score": {"N": "50"}}'
このようなデータがあるとします。Hashキーは単体でプライマリーキーとして利用出来るので、idをHashキーにします。
Hashキーのみ使用している場合はで検索にidしか使えないので、GetItemもしくはScanで検索する事になります。
aws> dynamodb --profile dynamodb_user get-item --table-name test --key '{ "id": {"N": "1"} }'
{
"Item": {
"first_name": {
"S": "Jun"
},
"last_name": {
"S": "Chiba"
},
"Score": {
"N": "50"
},
"id": {
"N": "1"
}
}
}
aws> dynamodb --profile dynamodb_user scan --table-name test
{
"Count": 1,
"Items": [
{
"first_name": {
"S": "Jun"
},
"last_name": {
"S": "Chiba"
},
"Score": {
"N": "50"
},
"id": {
"N": "1"
}
}
],
"ScannedCount": 1,
"ConsumedCapacity": null
}
Hashキーの重複は出来ませんので、id:1を追加する事は出来ません。
Hash+Rangeテーブル
ハッシュキーテーブルでは、table作成時に1つのattributeを選び、それをハッシュキーとして宣言しました。
そうではなく、table作成時に2つのattributeを選び、1つをハッシュキーとして、もう一つをレンジキーと呼ばれるキーとして宣言する、という方法があります。
ダミーデータを投入しました。tableのキーはこのようになっています。
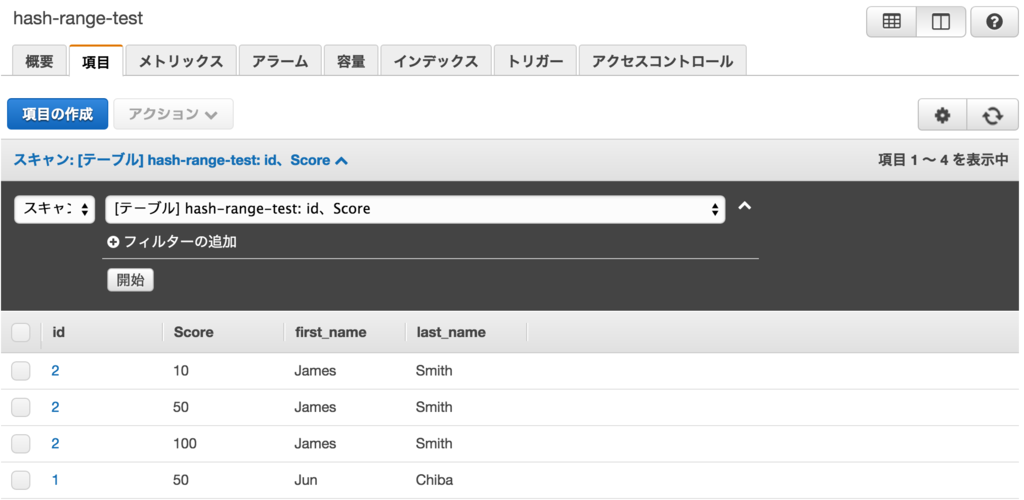
aws> dynamodb --profile dynamodb_user describe-table --table-name hash-range-test
{
"Table": {
"TableArn": "arn:aws:dynamodb:ap-northeast-1:123456789:table/hash-range-test",
"AttributeDefinitions": [
{
"AttributeName": "Score",
"AttributeType": "N"
},
{
"AttributeName": "id",
"AttributeType": "N"
}
],
"ProvisionedThroughput": {
"NumberOfDecreasesToday": 0,
"WriteCapacityUnits": 5,
"ReadCapacityUnits": 5
},
"TableSizeBytes": 0,
"TableName": "hash-range-test",
"TableStatus": "ACTIVE",
"KeySchema": [
{
"KeyType": "HASH",
"AttributeName": "id"
},
{
"KeyType": "RANGE",
"AttributeName": "Score"
}
],
"ItemCount": 0,
"CreationDateTime": 1450872773.111
}
}
では、id=2でScoreが10から90の間にあるitemを取得します。
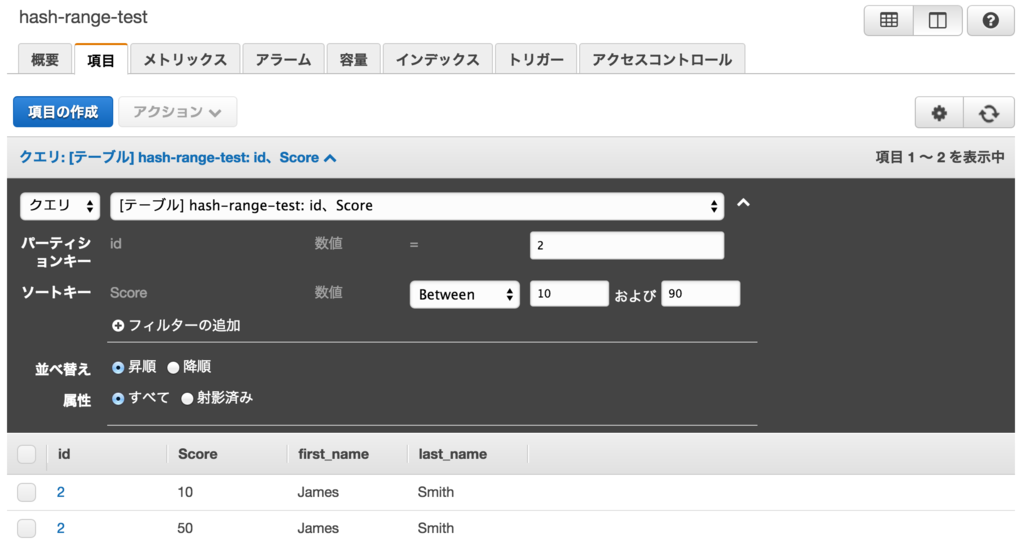
ちゃんと取得出来ましたね!Between検索が出来ています。
Hashキーでパーティショニングされ、さらにそのパーティションのRangeキーで検索がされるみたいです。
ハッシュキーテーブル 複合キーテーブル Scan 全件取得 全件取得 GetItem hash-keyに対するequal-to条件値を1つ指定して、0〜1件取得 hash-keyとrange-key両者に対するequal-to条件値を指定して、0〜1件取得 Query (無意味) hash-keyに対するequal-to条件値を1つ、range-keyに対する範囲条件(optional)を指定して、0〜複数件取得
DynamoDBではホットパーティションに気をつける必要があります。ホットパーティションは一部のパーティションのみに負荷が掛かる事を指します。
例えば。前述の「レンジキーの範囲だけで検索(つまりrange BETWEEN x AND yによる検索)」の例を考えてみましょう。裏側のイメージが出来ていない人は、表面的なことだけを考えてこんなことを考えるかもしれません。
「あ! ハッシュキー内でしか範囲検索できないのならば、ハッシュキーは固定で1とかにしておいて、そして使わなければいいんだ。そうすれば全件に対する範囲検索ができるぞー!」
この例だとHashキーが1で固定されているので、全て同じパーティションにデータが入ってしまい、せっかくのパーティション機能が活用されていません。データ件数が少ないと問題は出てきにくいですが、件数が増えると負荷が掛かってしまいますので、パーティション設計は大切です。
まとめ
簡単な操作しかしていませんが、他にローカルセカンダリインデックスやグローバルセカンダリインデックスなど設定があります。高速、高可用性を備えたDynamoDBはとても魅力的だと思います。