この記事は ミライトデザイン Advent Calendar 2024 の22日目の記事です。
今年も懲りずに乱入させていただきました。
昨日は @kenta0629 さんの GA + BigQuery についての記事でしたね。
本日はDBのテーブル設計についての内容です。
本日のお題
例えば、ユーザーが複数の趣味をチェックできるようにしたい、という要件があったとします。

このように1レコードに対して複数の属性を持たせる必要があるときにどのようにテーブル設計したらいいのか考えてみよう、というのが今回のお題です。
環境
今回は MySQL でいろいろ検証してみます。
mysql --version
mysql Ver 8.0.40 for Linux on x86_64 (MySQL Community Server - GPL)
解決方法の検討
パターン1. 従属テーブルを作成する
🙂「ユーザーと趣味が1:Nなんだから、テーブル分けるのが筋でしょ。」
こう思ったあなたは RDB にとても造詣が深く、きっと「正規化」という言葉が大好きでしょう(?)。
下記のような趣味マスタを用意して、
SELECT * FROM hobbies;
+----+--------------+
| id | name |
+----+--------------+
| 1 | スポーツ |
| 2 | 読書 |
| 3 | 料理 |
| 4 | 音楽鑑賞 |
+----+--------------+
ユーザーと趣味を紐づけるように中間テーブルを用意しましょう。
CREATE TABLE users (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT 'ユーザー名'
);
CREATE TABLE user_hobby (
user_id BIGINT NOT NULL,
hobby_id BIGINT NOT NULL,
-- 一意制約を追加
CONSTRAINT uq_hobby_user UNIQUE (user_id, hobby_id),
-- users テーブルへの外部キー
CONSTRAINT fk_hobby_user_user FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE,
-- hobbies テーブルへの外部キー
CONSTRAINT fk_hobby_user_hobby FOREIGN KEY (hobby_id) REFERENCES hobbies(id) ON DELETE CASCADE
);
各テーブルにはそれぞれ下記のようなデータが入ることになります。
SELECT * FROM users;
+----+---------------+
| id | name |
+----+---------------+
| 1 | ユーザーA |
| 2 | ユーザーB |
| 3 | ユーザーC |
+----+---------------+
SELECT * FROM user_hobby;
+---------+----------+
| user_id | hobby_id |
+---------+----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 2 |
| 2 | 4 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
+---------+----------+
データを参照するときはJOINを使用したSELECT文を発行することになるでしょう。
SELECT
users.id, users.name, hobbies.id, hobbies.name
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
LEFT JOIN hobbies ON user_hobby.hobby_id = hobbies.id;
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 1 | スポーツ |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
| 2 | ユーザーB | 2 | 読書 |
| 2 | ユーザーB | 4 | 音楽鑑賞 |
| 3 | ユーザーC | 1 | スポーツ |
| 3 | ユーザーC | 2 | 読書 |
| 3 | ユーザーC | 3 | 料理 |
+----+---------------+------+--------------+
中間テーブル(user_hobby)が下記の図のように、2つのテーブルの橋渡しをしてくれています。

最もRDBらしく、お行儀のいい方法と言えるでしょう。
この方式は名著:SQLアンチパターンでも解決策として紹介されています。
パターン2. JSON型で1カラムに複数の値を保持する
🙂「中間テーブルとか作るの面倒だなぁ。そういえばMySQL8からJSON型が使いやすくなったんだっけ。」
こう考えたあなたは、新しい知識の吸収に余念がないモダンなエンジニアに違いありません。
(MySQL8のリリースは2018年のことだから全然新しくないだって??👺)
この方式だと、JSON型のカラムを用意すれば複数の値を簡単に保持できます。
CREATE TABLE users (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT 'ユーザー名',
hobbies JSON COMMENT '趣味'
);
SELECT * FROM users;
+----+---------------+-----------+
| id | name | hobbies |
+----+---------------+-----------+
| 1 | ユーザーA | [1, 4] |
| 2 | ユーザーB | [2, 4] |
| 3 | ユーザーC | [1, 2, 3] |
+----+---------------+-----------+
今回の要件としては PostgreSQL における配列型 などがより適しているかと思いますが、MySQLには配列型がないので今回はJSON型で代用しています。
パターン3. ビット演算を利用して1カラムに複数の値を保持する
🙂「ビット演算つかうと便利だよー」
こう思ったあなたは、競技プログラミングやアルゴリズムが大得意ですね?
これがメンタリズムです(嘘)。
まず、今までの趣味マスタに下記のような列 ? を増やしてみましょう。
| id | name | ? |
|---|---|---|
| 1 | スポーツ | 0001 |
| 2 | 読書 | 0010 |
| 3 | 料理 | 0100 |
| 4 | 音楽鑑賞 | 1000 |
この0と1の並びはなんぞ?と思った方もいるかと思いますが、これは各桁にそれぞれの趣味のON, OFFを割り当てたものになります。
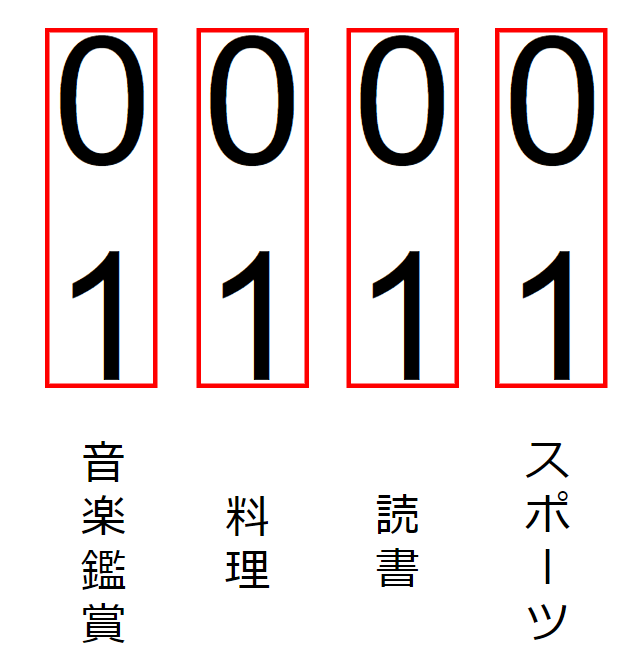
各桁の値が0か1かどうかで、それぞれの趣味にチェックが入っているかどうかを判定する、というやり方です。
例えば
-
0100... 「料理」にチェックあり -
1010... 「音楽鑑賞」と「読書」にチェックあり -
1101... 「音楽鑑賞」と「料理」と「スポーツ」にチェックあり
といった感じです。
各桁には0か1の値しか入らない、いわゆる2進数なのですが、この情報量のことをビットと呼びます。
このビットによる表現を使えば、1個のカラムだけで複数の趣味の情報を管理することができるというわけです。
実際にSQLで管理する場合は、2進数を10進数に変換してINT型で管理するか、ビット値型のカラムを用意することになるかと思います。
今回は比較のためにINT型とBIT型のカラムを2つ用意します。
CREATE TABLE users (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT 'ユーザー名',
hobbies_int INT COMMENT '趣味(INT)',
hobbies_bit BIT(10) COMMENT '趣味(BIT)'
);
SELECT * FROM users;
+----+---------------+-------------+--------------------------+
| id | name | hobbies_int | hobbies_bit |
+----+---------------+-------------+--------------------------+
| 1 | ユーザーA | 9 | 0x0009 |
| 2 | ユーザーB | 10 | 0x000A |
| 3 | ユーザーC | 7 | 0x0007 |
+----+---------------+-------------+--------------------------+
先ほどの 1010 のような2進数表記にしたい場合は一工夫必要になります。
SELECT
id,
name,
hobbies_int,
LPAD(CONV(hobbies_int, 10, 2), 4, '0') AS hobbies_int2,
hobbies_bit,
LPAD(CONV(hobbies_bit, 10, 2), 4, '0') AS hobbies_bit2
FROM users;
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 9 | 1001 | 0x0009 | 1001 |
| 2 | ユーザーB | 10 | 1010 | 0x000A | 1010 |
| 3 | ユーザーC | 7 | 0111 | 0x0007 | 0111 |
+----+---------------+-------------+--------------+--------------------------+--------------+
自分自身は案件で採用したことはありませんが、ゲームの状態異常のような複数のフラグを管理する方式として度々目にする方式です。
パターン4. カンマ区切りで保存する(アンチパターン)
🙂「複数の値が保持したい?せや、カンマ区切りで保存したろ。」
誰もが一度は考える(?)複数の値を保存するシンプルな方法です。
文字列型(VARCHAR or TEXT)のカラムを用意して、複数の趣味をカンマ区切りで保存しちゃいます(区切り文字は何でも構いません)。
CREATE TABLE users (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT 'ユーザー名',
hobbies VARCHAR(255) COMMENT '趣味'
);
SELECT * FROM users;
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | 1,4 |
| 2 | ユーザーB | 2,4 |
| 3 | ユーザーC | 1,2,3 |
+----+---------------+---------+
長く稼働している案件で偶に見かけることがありますね。
先に書いてしまいますが、こちらのパターンはSQLアンチパターンの第1章「ジェイウォーク(信号無視)」で紹介されている由緒正しい(?)アンチパターンとなっています。
それぞれのパターンを比較
それでは解決方法のパターンによって、どんなメリット・デメリットがあるか様々な角度から比較してみます。
ここからは自分の完全なる独断と偏見で◎、○、△、×の四段階で各パターンを評価していきます。
自分個人の考え方が色濃く反映されているので、鵜呑みにしないようにご注意ください。
可読性
本記事では「可読性」という言葉を「DBの値を見て、状態がわかりやすいかどうか」という意味合いで使用しています。
わかりやすいかどうかは個人の主観に依るところが大きいかと思いますが、そこはご容赦ください💦
早速、各パターンのDBの値を確認してみましょう。
①従属テーブルを作成する
SELECT * FROM users;
+----+---------------+
| id | name |
+----+---------------+
| 1 | ユーザーA |
| 2 | ユーザーB |
| 3 | ユーザーC |
+----+---------------+
SELECT * FROM user_hobby;
+---------+----------+
| user_id | hobby_id |
+---------+----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 2 |
| 2 | 4 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
+---------+----------+
個別のテーブル見ると、正直わかりづらいですね。
ただ、JOIN してちょっとひと手間加えれば、非常にわかりやすくなります。
SELECT
users.id, users.name, hobbies.id, hobbies.name
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
LEFT JOIN hobbies ON user_hobby.hobby_id = hobbies.id;
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 1 | スポーツ |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
| 2 | ユーザーB | 2 | 読書 |
| 2 | ユーザーB | 4 | 音楽鑑賞 |
| 3 | ユーザーC | 1 | スポーツ |
| 3 | ユーザーC | 2 | 読書 |
| 3 | ユーザーC | 3 | 料理 |
+----+---------------+------+--------------+
え、ユーザーが何人いるかわかりづらい??
そんな贅沢なあなたにはGROUP BY, GROUP_CONCATを使ったこんなプランをご用意しました。
SELECT
users.id, users.name,
GROUP_CONCAT(hobbies.id) AS hobby_ids,
GROUP_CONCAT(hobbies.name) AS hobbys
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
LEFT JOIN hobbies ON user_hobby.hobby_id = hobbies.id
GROUP BY users.id;
+----+---------------+-----------+----------------------------+
| id | name | hobby_ids | hobbys |
+----+---------------+-----------+----------------------------+
| 1 | ユーザーA | 1,4 | スポーツ,音楽鑑賞 |
| 2 | ユーザーB | 2,4 | 読書,音楽鑑賞 |
| 3 | ユーザーC | 1,2,3 | スポーツ,読書,料理 |
+----+---------------+-----------+----------------------------+
これで大分見やすくなったのではないでしょうか。
さて、可読性についての評価ですが、
⭕趣味マスタとJOINすると項目名も結果に含められるので非常に見やすい
❌SQLのひと手間が正直めんどくさいので、把握にコストがかかる
❌テーブル間の相関関係を理解しておく必要がある
ということで、評価は△とします。
②JSON型で1カラムに複数の値を保持する
SELECT * FROM users;
+----+---------------+-----------+
| id | name | hobbies |
+----+---------------+-----------+
| 1 | ユーザーA | [1, 4] |
| 2 | ユーザーB | [2, 4] |
| 3 | ユーザーC | [1, 2, 3] |
+----+---------------+-----------+
シンプルそのものです。
可読性についての評価は、
⭕SQLが非常にシンプル
⭕1レコードに対して紐づいている趣味が一目でわかる
❌趣味マスタと結合ができないので、趣味マスタを別途参照する必要がある
といったところですが、個人的にはこのシンプルさがとにかくわかりやすいと思うので、評価は○にします。
③ビット演算を利用して1カラムに複数の値を保持する
SELECT * FROM users;
+----+---------------+-------------+--------------------------+
| id | name | hobbies_int | hobbies_bit |
+----+---------------+-------------+--------------------------+
| 1 | ユーザーA | 9 | 0x0009 |
| 2 | ユーザーB | 10 | 0x000A |
| 3 | ユーザーC | 7 | 0x0007 |
+----+---------------+-------------+--------------------------+
さて、これだけ見るとどの趣味が有効か判断できませんね。
2進数表記に変更することで、少し把握しやすくなります。
SELECT
id,
name,
hobbies_int,
LPAD(CONV(hobbies_int, 10, 2), 4, '0') AS hobbies_int2,
hobbies_bit,
LPAD(CONV(hobbies_bit, 10, 2), 4, '0') AS hobbies_bit2
FROM users;
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 9 | 1001 | 0x0009 | 1001 |
| 2 | ユーザーB | 10 | 1010 | 0x000A | 1010 |
| 3 | ユーザーC | 7 | 0111 | 0x0007 | 0111 |
+----+---------------+-------------+--------------+--------------------------+--------------+
可読性についての評価は、
⭕SQLが比較的シンプル
⭕1レコードに対して紐づいている趣味が一目でわかる
❌2進数表記にするためのひと手間が必要
❌趣味マスタテーブルとの結合はできないので、どの桁がどの趣味に対応しているかは趣味マスタを別途参照する必要がある
ということで、JSON型より若干下と判断して△とします。
④カンマ区切りで保存する
SELECT * FROM users;
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | 1,4 |
| 2 | ユーザーB | 2,4 |
| 3 | ユーザーC | 1,2,3 |
+----+---------------+---------+
これはもうJSON型とほぼ同じですね。
というわけで、評価についても同じく○にします。
可読性の評価まとめ
| パターン | 評価 | 備考 |
|---|---|---|
| 従属テーブル | △ | ⭕趣味マスタとJOINすると項目名も結果に含められるので非常に見やすい❌SQLのひと手間が正直めんどくさいので、把握にコストがかかる ❌テーブル間の相関関係を理解しておく必要がある |
| JSON型 | ○ | ⭕SQLが非常にシンプル ⭕1レコードに対して紐づいている趣味が一目でわかる ❌趣味マスタと結合ができないので、趣味マスタを別途参照する必要がある |
| ビット演算を利用 | △ | ⭕SQLが比較的シンプル ⭕1レコードに対して紐づいている趣味が一目でわかる ❌2進数表記にするためのひと手間が必要 ❌趣味マスタテーブルとの結合はできないので、どの桁がどの趣味に対応しているかは趣味マスタを別途参照する必要がある |
| カンマ区切り | ○ | ⭕SQLが非常にシンプル ⭕1レコードに対して紐づいている趣味が一目でわかる ❌趣味マスタと結合ができないので、趣味マスタを別途参照する必要がある |
整合性
本記事では「整合性」という言葉を「データが正確で矛盾がない、不正なデータを登録できない」という意味合いで使用しています。
①従属テーブルを作成する
従属テーブルで管理を行う場合、MySQLが用意している様々な制約で整合性を担保することができます。
今回のケースでは、外部キー制約と一意制約を用いるとよいでしょう。
- 外部キー制約 ... 趣味マスタに存在しない値を保存できないようにする
- 一意制約 ... ユーザーが複数の同じ趣味を持てないようにする
上記の制約により、不正な状態のデータを登録しようとするとエラーが発生するようになります。
-- 趣味マスタに存在しない id=100 の趣味を登録しようとすると
INSERT INTO user_hobby (user_id, hobby_id) VALUES (1, 100);
-- 外部キー制約エラーで怒られる
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`exp`.`user_hobby`, CONSTRAINT `fk_hobby_user_hobby` FOREIGN KEY (`hobby_id`) REFERENCES `hobbies` (`id`) ON DELETE CASCADE)
-- 同じユーザー・趣味の組み合わせを複数登録しようとすると
INSERT INTO user_hobby (user_id, hobby_id) VALUES (1, 1);
-- 一意制約エラーで怒られる
ERROR 1062 (23000): Duplicate entry '1-1' for key 'user_hobby.uq_hobby_user'
整合性についての評価ですが、
⭕趣味マスタに存在しない値を登録できない
⭕1ユーザーが同じ趣味を複数持つ状態も登録できない
ということで、DBの制約を活用して不正な状態をうまく防げることを評価し◎とします。
②JSON型で1カラムに複数の値を保持する
大前提として、JSONといっても色々な形式のデータがあり得ます。
{"hoge": 1, "fuga": 2}{"a": {"b": 1, "c": 2}, "d": [3, 4, 5]}
今回のデータとしてほしいのはあくまで趣味IDの配列なので、上記のような形式は不正な状態のデータと言えるでしょう。
配列形式を保証する場合、CHECK制約とJSON関数を組み合わせることである程度の制御が可能です。
CREATE TABLE users (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT 'ユーザー名',
hobbies JSON COMMENT '趣味',
CHECK (JSON_TYPE(hobbies) = 'ARRAY') -- 配列であることを保証するCHECK制約を追加
);
-- 配列以外の形式を登録しようとすると
INSERT INTO users (name, hobbies) VALUES ('ユーザーD', '{"hoge": 1}');
-- CHECK制約で怒られる
ERROR 3819 (HY000): Check constraint 'users_chk_1' is violated.
-- 配列は問題なく登録できる
INSERT INTO users (name, hobbies) VALUES ('ユーザーE', '[1, 2, 3]');
Query OK, 1 row affected (0.01 sec)
また、
- 趣味マスタに存在しないIDを登録できないようにする
- 1ユーザーが同じ趣味を複数持たせない
上記の制御を入れる場合、トリガー を活用することで実現可能です。
下記は INSERT 時に重複する趣味を登録できないようにするトリガーの例です。
-- 趣味が重複しないような制御を追加
DELIMITER //
CREATE TRIGGER check_hobbies_unique
BEFORE INSERT ON users
FOR EACH ROW
BEGIN
-- JSON_EXTRACT と JSON_UNQUOTE を使って要素を取り出し、重複チェックを行う
IF (SELECT COUNT(*)
FROM (
SELECT JSON_UNQUOTE(JSON_EXTRACT(NEW.hobbies, CONCAT('$[', idx, ']'))) AS value
FROM (SELECT 0 AS idx UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4) AS indices
WHERE idx < JSON_LENGTH(NEW.hobbies)
) AS elements
GROUP BY value
HAVING COUNT(*) > 1in
) > 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Array contains duplicate values';
END IF;
END;
//
DELIMITER ;
-- 重複した趣味IDを登録しようとすると
INSERT INTO users (name, hobbies) VALUES ('ユーザーF', '[1, 1, 3]');
-- 重複エラーで怒られる
ERROR 1644 (45000): Array contains duplicate values
ただ、見ていただければわかるようにトリガーでの制約は結構複雑なので、個人的にはアプリケーションで整合性を担保する方針もありかなと思います。
トリガーでの制約を行う場合、登録・更新時の性能にも影響があることを頭に入れておきましょう。
自分のローカル環境で「趣味マスタに存在しないIDを登録できないようにする」「1ユーザーが同じ趣味を複数持たせない」トリガーを設定した場合、100万件の INSERT が 4.65 sec → 58.65 sec となったので、大量のデータを登録・更新する場合は注意が必要です。
さて、整合性についての評価ですが
⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない
⭕トリガーを利用すれば1ユーザーが同じ趣味を複数持つ状態も登録できない
❌JSON型は型としての自由度が高いので、意識的に制約を設ける必要がある
❌トリガーによる制約が複雑
というところです。
評価は△~○としておきます。
③ビット演算を利用して1カラムに複数の値を保持する
ビット演算を利用する場合、「料理、料理、音楽鑑賞」のような、同じデータが複数入るといった不整合はデータ形式上起こりえません(0200はあり得ない)。
一方で、趣味マスタに存在しない値を登録できないようにする、というのは外部キー制約による制御ができないため、JSON型同様、トリガーを利用するか、アプリケーション側で保障することになるでしょう。
評価としては、
⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない
⭕1ユーザーが同じ趣味を複数持つ状態は型として登録できない
❌トリガーによる制約が複雑
というところです。
JSON型よりは整合性を担保しやすいと判断して、評価は○としておきます。
④カンマ区切りで保存する
まずVARCAHR, TEXT型のカラムにカンマ区切りで登録しているこの方式はJSON型よりもさらに自由度が高く、何もしなければ不正な形式はいくらでも登録可能です。
また、
- 趣味マスタに存在しないIDを登録できないようにする
- 1ユーザーが同じ趣味を複数持たせない
こちらの制約は②JSON型で1カラムに複数の値を保持する同様、トリガーでの制約追加が可能です。
なので、整合性についての評価については②の下位互換といったところでしょうか。
⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない
⭕トリガーを利用すれば1ユーザーが同じ趣味を複数持つ状態も登録できない
❌文字列型は型としての自由度が高いので、意識的に制約を設ける必要がある
❌トリガーによる制約が複雑
独断と偏見で評価は×~△です。
整合性の評価まとめ
| パターン | 評価 | 備考 |
|---|---|---|
| 従属テーブル | ◎ | ⭕趣味マスタに存在しない値を登録できない ⭕1ユーザーが同じ趣味を複数持つ状態も登録できない |
| JSON型 | △~○ | ⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない ⭕トリガーを利用すれば1ユーザーが同じ趣味を複数持つ状態も登録できない ❌JSON型は型としての自由度が高いので、意識的に制約を設ける必要がある ❌トリガーによる制約が複雑 |
| ビット演算を利用 | ○ | ⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない ⭕1ユーザーが同じ趣味を複数持つ状態は型として登録できない ❌トリガーによる制約が複雑 |
| カンマ区切り | ×~△ | ⭕トリガーを利用すれば趣味マスタに存在しない値を登録できない ⭕トリガーを利用すれば1ユーザーが同じ趣味を複数持つ状態も登録できない ❌文字列型は型としての自由度が高いので、意識的に制約を設ける必要がある ❌トリガーによる制約が複雑 |
検索速度
続いては検索速度による比較です。
今回はユーザーを100万件登録した状態での検索速度を比較していきます。
速度計測に合わせてEXPLAINを実行し実行計画を取得していきます。
もし「EXPLAINなんてつかったことない」「実行計画ってなに??」という方がいたら、下記の記事が参考になるかもしれません。
100万件のレコードを登録する際に、カーディナリティが低いとインデックスを使用した効率的な検索が行われないため、趣味マスタを20件に増やしてデータを散らして検証しています。
①従属テーブルを作成する
まずは実行計画と実測値を見ていきましょう。
-- 実行計画を見てみると
EXPLAIN SELECT
users.id, users.name, user_hobby.hobby_id
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
WHERE user_hobby.hobby_id = 3;
-- インデックスが使用されている(typeにALLがないですね)
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+--------------------------+
| 1 | SIMPLE | user_hobby | NULL | ref | uq_hobby_user,fk_hobby_user_hobby | fk_hobby_user_hobby | 8 | const | 91924 | 100.00 | Using where; Using index |
| 1 | SIMPLE | users | NULL | eq_ref | PRIMARY | PRIMARY | 8 | exp.user_hobby.user_id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+--------------------------+
なかなか期待できそうです。
では実際に実行してみましょう。
SELECT
users.id, users.name, user_hobby.hobby_id
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
WHERE user_hobby.hobby_id = 3;
+---------+--------------+----------+
| id | name | hobby_id |
+---------+--------------+----------+
| ... | ... | ... |
| 999960 | name-999960 | 3 |
| 999980 | name-999980 | 3 |
| 1000000 | name-1000000 | 3 |
+---------+--------------+----------+
50000 rows in set (0.19 sec)
「0.19 sec」ということで、実測値はなかなか高速で優秀です。
ただ、検索結果を見てみると hobby_id=3 のレコードのみが表示されています。
もし一覧画面に、検索条件を満たすユーザーの他の趣味も表示する必要がある場合、この検索では不十分ということになります。
| ユーザー | 趣味 |
|---|---|
| ユーザーA | 料理、音楽鑑賞 |
| ユーザーC | スポーツ、読書、料理 |
| ... | ... |
上記の条件を満たすSQLでもう一度確認してみましょう。
-- 実行計画を見てみると
EXPLAIN SELECT
users.id, users.name, GROUP_CONCAT(user_hobby.hobby_id) as hobbies
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
WHERE users.id IN (SELECT user_id FROM user_hobby WHERE hobby_id = 3)
GROUP BY users.id, users.name; -- ユーザーを1行にまとめるために GROUP BY を使用
-- 全てのテーブルでインデックスが使用されている
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+----------------------------------------------+
| 1 | SIMPLE | user_hobby | NULL | ref | uq_hobby_user,fk_hobby_user_hobby | fk_hobby_user_hobby | 8 | const | 91924 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | users | NULL | eq_ref | PRIMARY | PRIMARY | 8 | exp.user_hobby.user_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | user_hobby | NULL | ref | uq_hobby_user | uq_hobby_user | 8 | exp.user_hobby.user_id | 1 | 100.00 | Using index |
+----+-------------+------------+------------+--------+-----------------------------------+---------------------+---------+------------------------+-------+----------+----------------------------------------------+
-- 実測値
SELECT
users.id, users.name, GROUP_CONCAT(user_hobby.hobby_id) as hobbies
FROM users
LEFT JOIN user_hobby ON users.id = user_hobby.user_id
WHERE users.id IN (SELECT user_id FROM user_hobby WHERE hobby_id = 3)
GROUP BY users.id, users.name;
+---------+--------------+---------+
| id | name | hobbies |
+---------+--------------+---------+
| ... | name-999980 | 1,2,3 |
| 999980 | name-999980 | 1,2,3 |
| 1000000 | name-1000000 | 1,2,3 |
+---------+--------------+---------+
50000 rows in set (0.46 sec)
先ほどよりも若干実行速度が遅くなっていますね。
さて、評価ですが
⭕インデックスが効いている
❌JOIN や GROUP BY が必要になる分、若干実行速度が落ちる
ということで○とします。
②JSON型で1カラムに複数の値を保持する
MySQL 8.0.17 以降では、JSON配列の検索に有効な Multi-Valued Index という機能が追加されています。
こちらのインデックスを追加してみましょう。
ALTER TABLE users
ADD INDEX idx_json_array ((CAST(hobbies AS CHAR(3) ARRAY)));
インデックスが追加されたら、早速実行計画と検索速度を見てみましょう。
-- 実行計画を確認してみると
EXPLAIN SELECT * FROM users FORCE INDEX(idx_json_array) WHERE JSON_CONTAINS(hobbies, '3', '$') ;
-- インデックス「idx_json_array」が使用されている(key の部分を見てね)
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | users | NULL | range | idx_json_array | idx_json_array | 15 | NULL | 55384 | 100.00 | Using where |
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+-------+----------+-------------+
-- 実測値
SELECT * FROM users FORCE INDEX(idx_json_array) WHERE JSON_CONTAINS(hobbies, '3', '$') ;
+--------+-------------+-----------+
| id | name | hobbies |
+--------+-------------+-----------+
| ... | ... | ... |
| 999982 | name-999982 | [1, 2, 3] |
+--------+-------------+-----------+
50000 rows in set (0.28 sec)
インデックスを使用した検索ではありますが、通常のインデックスに比べて実測値が意外とかかっている印象です(0.00 sec 叩きだしてほしかった><)。
カーディナリティが低いからなのか、JSON関数を使用する必要があるので性能が出づらいのか、今後も見ていきたいなと思います。
評価としては
⭕インデックスが効いている
❌通常のインデックスに比べて実測値がそこまで早くない
ということで○とします。
③ビット演算を利用して1カラムに複数の値を保持する
続いてはビット演算のパターンです。
ビット演算を利用した検索をするとき、果たしてインデックスは機能するのでしょうか。
まずはインデックスをおもむろに追加してみましょう。
ALTER TABLE users ADD INDEX idx_hobbies_int (hobbies_int);
ALTER TABLE users ADD INDEX idx_hobbies_bit (hobbies_bit);
SHOW CREATE TABLE users\G
*************************** 1. row ***************************
Table: users
Create Table: CREATE TABLE `users` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL COMMENT 'ユーザー名',
`hobbies_int` int DEFAULT NULL COMMENT '趣味(INT)',
`hobbies_bit` bit(10) DEFAULT NULL COMMENT '趣味(BIT)',
PRIMARY KEY (`id`),
KEY `idx_hobbies_int` (`hobbies_int`),
KEY `idx_hobbies_bit` (`hobbies_bit`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
それでは実行計画と実行速度を見ていきましょう。
特定の趣味を含むレコードを検索する場合、&をつかって論理積を取得することで検索が可能です。
まずは INT 型のカラムで検索した場合を見ていきます。
-- 実行計画を確認してみると
EXPLAIN SELECT * FROM users WHERE hobbies_int & b'00000100' = b'00000100';
-- インデックスは特に使用されない
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 997060 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
-- 実測値
+--------+-------------+-------------+--------------------------+
| id | name | hobbies_int | hobbies_bit |
+--------+-------------+-------------+--------------------------+
| ... | ... | ... | ... |
| 999962 | name-999962 | 7 | 0x0007 |
| 999982 | name-999982 | 7 | 0x0007 |
+--------+-------------+-------------+--------------------------+
50000 rows in set (0.21 sec)
続いて、BIT型の場合も見てみましょう。
-- 実行計画を確認してみると
EXPLAIN SELECT * FROM users WHERE hobbies_bit & b'00000100' = b'00000100';
-- インデックスは特に使用されない
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 997060 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
-- 実測値
+--------+-------------+-------------+--------------------------+
| id | name | hobbies_int | hobbies_bit |
+--------+-------------+-------------+--------------------------+
| ... | ... | ... | ... |
| 999962 | name-999962 | 7 | 0x0007 |
| 999982 | name-999982 | 7 | 0x0007 |
+--------+-------------+-------------+--------------------------+
50000 rows in set (0.21 sec)
インデックスは使用されていませんが、実測値は意外と早い(というかインデックスを使用した検索に負けていない)のが驚きです。
ただし、今回の検索は単一テーブルに対するシンプルな検索のため、他テーブルと結合した場合など複雑なSQLになればさらに遅くなる可能性があります。
評価としては
❌インデックスが効かない
⭕単純なクエリなら実測値は意外と優秀
というところです。
自分はインデックスが使用されずにチューニングの余地がなくて困ったことが何度もあるので、評価は△とします(完全に私怨)。
④カンマ区切りで保存する
カンマ区切りテキストに趣味IDが含まれているかを検索する場合、正規表現を使用した部分一致検索をすることになります。
注意点として、ここで不用意に LIKE を使用して検索すると思わぬ不具合に引っ掛かる可能性があります。
-- 1:スポーツを検索するときに LIKE を使用すると
SELECT * FROM users WHERE hobbies LIKE '%1%';
-- 将来的に id:10 とか1を含むマスタが増えたときに検索に引っ掛かってしまう
+----------+--------------+----------+
| id | name | hobbies |
+----------+--------------+----------+
| ... | ... | ... |
| 9999999 | name-9999999 | 1,4 |
| 10000001 | name-xxxxxxx | 2, 3, 10 |
+----------+--------------+----------+
この場合、正規表現を使用して単語境界を照合するなどの工夫が必要でしょう。
https://dev.mysql.com/doc/refman/8.0/ja/regexp.html
-- 単語境界を意識した正規表現を使用することで
SELECT * FROM users WHERE id > '9999998' and hobbies REGEXP '\\b1\\b';
-- 将来的に id:10 とか1を含むマスタが増えても検索に引っ掛からなくなる
+----------+--------------+----------+
| id | name | hobbies |
+----------+--------------+----------+
| ... | ... | ... |
| 9999999 | name-9999999 | 1,4 |
+----------+--------------+----------+
この際、カラムにインデックスが存在しても使用されないため検索性能を改善するのが非常に難しくなってしまいます。
-- 実行計画を確認してみると
EXPLAIN SELECT * FROM users WHERE hobbies REGEXP '\\b3\\b';
-- type=ALL でテーブルスキャンになっている
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 997467 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
-- 実測値
SELECT * FROM users WHERE hobbies REGEXP '\\b3\\b';
+--------+-------------+---------+
| id | name | hobbies |
+--------+-------------+---------+
| ... | ... | ... |
| 999982 | name-999982 | 1,2,3 |
+--------+-------------+---------+
50000 rows in set (0.28 sec)
こちらもビット演算同様、インデックスは使用されていないが実測値は意外と早いという結果になりました。
評価としてはビット演算と同様、△とします
検索速度の評価まとめ
| パターン | 評価 | 備考 |
|---|---|---|
| 従属テーブル | 〇 | ⭕インデックスが効いている ❌JOIN や GROUP BY が必要になる分、若干実行速度が落ちる |
| JSON型 | 〇 | ⭕インデックスが効いている ❌通常のインデックスに比べて実測値がそこまで早くない |
| ビット演算を利用 | △ | ❌インデックスが効かない ⭕単純なクエリなら実測値は意外と優秀 |
| カンマ区切り | △ | ❌インデックスが効かない ⭕単純なクエリなら実測値は意外と優秀 |
更新速度
続いては更新時の性能について考察します。
ここでは
- ユーザーに特定の趣味を追加・削除する
- ユーザーの趣味を全て更新する(e.g.
スポーツ、料理を読書、音楽鑑賞に変更)
という2つのパターンの更新を考えてみます。
①従属テーブルを作成する
従属テーブルを使用するパターンでは「ユーザーに特定の趣味を追加・削除する」は中間テーブルのレコードを INSAERT, DELETE することで実現できます。
-- 変更前
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 1 | スポーツ |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
+----+---------------+------+--------------+
-- ユーザーAに趣味:料理を追加
INSERT INTO user_hobby (user_id, hobby_id) VALUES (1, 3);
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 1 | スポーツ |
| 1 | ユーザーA | 3 | 料理 |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
+----+---------------+------+--------------+
-- ユーザーAの趣味:スポーツを削除
DELETE FROM user_hobby WHERE user_id = 1 AND hobby_id = 1;
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 3 | 料理 |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
+----+---------------+------+--------------+
これは非常にシンプルですね。
では、「ユーザーの趣味を全て更新する」場合はどうでしょうか。
この場合、対象のユーザーに紐づく中間テーブルのレコードを一度削除し、新たにレコードをINSERTしなおすことになるでしょう。
-- 趣味を読書、音楽鑑賞に上書き
DELETE FROM user_hobby WHERE user_id = 1;
INSERT INTO user_hobby (user_id, hobby_id) VALUES
(1, 2),
(1, 4);
+----+---------------+------+--------------+
| id | name | id | name |
+----+---------------+------+--------------+
| 1 | ユーザーA | 2 | 読書 |
| 1 | ユーザーA | 4 | 音楽鑑賞 |
+----+---------------+------+--------------+
後述しますが、これは他のパターンが UPDATE 1回で済むのに比べ、明らかに更新コストが高いといえるでしょう。
特に趣味の選択肢がもっと多い場合などはそれに伴ってINSERTの回数が増えてコストが高くなっていきます。
とはいえ1ユーザーに対する変更と見ればそこまで神経質にならなくてもいいのかもしれません。
ただし、下記のような要件がある場合は要注意と言えるでしょう。
- ゲームなど、大量のアクセスによる更新処理が予想される
- マスタ一括更新など、同時に複数のレコードの値を更新する必要がある
さて、評価ですが
⭕特定の趣味を追加、削除する場合は特に問題なし
❌趣味を洗い替える場合は DELETE, INSERT を必要とするのでコストが高め
というところで評価は△とします。
②JSON型で1カラムに複数の値を保持する
JSON型の場合、特定の趣味を追加する場合は JSON関数を利用することになります。
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | [2, 4] |
+----+---------------+---------+
-- ユーザーAに趣味:料理を追加
UPDATE users SET hobbies = JSON_ARRAY_APPEND(hobbies, '$', 3) WHERE id = 1;
+----+---------------+-----------+
| id | name | hobbies |
+----+---------------+-----------+
| 1 | ユーザーA | [2, 4, 3] |
+----+---------------+-----------+
削除は、JSON_SEARCH 関数と JSON_REMOVE 関数を組み合わせる必要がありますが、なぜか数値型の場合に JSON_SEARCH による検索ができないみたいです😢
なので、一度SELECTしてアプリケーション側で要素を削除し、洗い替えと同様まるごと配列を更新することになるでしょう。
一方、配列を丸ごと更新するのは UPDATE 1回で簡単に実現できます。
UPDATE users SET hobbies = '[2,3]' WHERE id = 1;
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | [2, 3] |
+----+---------------+---------+
評価としては
⭕特定の趣味を追加はできる
❌特定の趣味の削除は数値型だとできない(文字列はできる)
⭕趣味を洗い替える場合は UPDATE 1回でコストが低い
ということで評価は○とします。
③ビット演算を利用して1カラムに複数の値を保持する
まず特定の趣味の追加、削除をしたい場合、それぞれビット演算で論理和、論理積と否定を利用することになります。
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 9 | 1001 | 0x0009 | 1001 |
+----+---------------+-------------+--------------+--------------------------+--------------+
-- ユーザーAに趣味:料理を追加
UPDATE users SET
hobbies_int = hobbies_int | b'0100', -- 論理和で趣味を追加
hobbies_bit = hobbies_bit | b'0100'
WHERE id =1;
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 13 | 1101 | 0x000D | 1101 |
+----+---------------+-------------+--------------+--------------------------+--------------+
-- ユーザーAの趣味:スポーツを削除
UPDATE users SET
hobbies_int = hobbies_int & ~b'0001', -- 否定と論理積を組み合わせると趣味を削除できる
hobbies_bit = hobbies_bit & ~b'0001'
WHERE id =1;
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 12 | 1100 | 0x000C | 1100 |
+----+---------------+-------------+--------------+--------------------------+--------------+
また、丸ごと更新するのは UPDATE 1回で実施可能です。
UPDATE users SET hobbies_int = b'0110', hobbies_bit = b'0110' WHERE id = 1;
+----+---------------+-------------+--------------+--------------------------+--------------+
| id | name | hobbies_int | hobbies_int2 | hobbies_bit | hobbies_bit2 |
+----+---------------+-------------+--------------+--------------------------+--------------+
| 1 | ユーザーA | 6 | 0110 | 0x0006 | 0110 |
+----+---------------+-------------+--------------+--------------------------+--------------+
⭕特定の趣味を追加、削除はできる
⭕趣味を洗い替える場合は UPDATE 1回でコストが低い
ということで、文句なしの◎です。
ゲーム関連の情報でこの方式が選ばれるのも納得です。
④カンマ区切りで保存する
まず特定の趣味の追加、削除については下手に関数などで頑張るより一度 SELECT してまるごとテキストを更新する方が楽だと思います。
丸ごと更新するのはパターン2, 3同様 UPDATE 1回でできます。
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | 2,4 |
+----+---------------+---------+
UPDATE users SET hobbies='2,3' WHERE id = 1;
+----+---------------+---------+
| id | name | hobbies |
+----+---------------+---------+
| 1 | ユーザーA | 2,3 |
+----+---------------+---------+
評価については
❌特定の趣味の削除はできない(本当はできるかもしれないけどしらない)
⭕趣味を洗い替える場合は UPDATE 1回でコストが低い
ということで△~○くらいでしょうか。
更新速度の評価まとめ
| パターン | 評価 | 備考 |
|---|---|---|
| 従属テーブル | △ | ⭕特定の趣味を追加、削除する場合は特に問題なし ❌趣味を洗い替える場合は DELETE, INSERT を必要とするのでコストが高め |
| JSON型 | ○ | ⭕特定の趣味を追加はできる ❌特定の趣味の削除は数値型だとできない(文字列はできる) ⭕趣味を洗い替える場合は UPDATE 1回でコストが低い |
| ビット演算を利用 | ◎ | ⭕特定の趣味を追加、削除はできる ⭕趣味を洗い替える場合は UPDATE 1回でコストが低い |
| カンマ区切り | △~○ | ❌特定の趣味の削除はできない ⭕趣味を洗い替える場合は UPDATE 1回でコストが低い |
比較まとめ
というわけで、各パターンの比較結果をまとめてみます。
| パターン | 可読性 | 整合性 | 検索速度 | 更新速度 |
|---|---|---|---|---|
| 従属テーブル | △ | ◎ | 〇 | △ |
| JSON型 | ○ | △~○ | 〇 | ○ |
| ビット演算を利用 | △ | ○ | △ | ◎ |
| カンマ区切り | ○ | ×~△ | △ | △~○ |
まだまだ考慮すべき事項はあるかと思いますが、今回はこのあたりで。
じゃあキミはどれ採用するの?
こう聞かれたときに、結局「要件次第」という結論に至ってしまうのが、自分が完全に理解できていないところですかね💦
いくつかの判断基準として
- データの整合性が何より大事な場合は従属テーブルを用意するパターンが一番安全
- 大量アクセスや一括更新など、更新処理を重視する場合はJSON型かビット演算
- 比較的JSON型はバランスがいい印象(データ見やすいしインデックスも効くし更新性能も十分)
- カンマ区切りはJSON型の完全下位互換なので選ばない
といったところでしょうか。
煮え切らない結論になってしまいましたが、次のテーブル設計の時はこれらを念頭に置いて設計を進めていきたいと思います💪
おわりに
超長文になってしまいましたが、いかがだったでしょうか。
(最後まで読めた人はいるのかな??)
自分としてはまだまだ調べたいことがありますが、実際に検証してみると思ったように動かなかったり検索速度が予想と違ったり、知らなかった解決法に出会えたりとなかなか勉強になりました。
明日は @suzuki-hoge さんのジェネリクスについての記事ですね。
自分は楽しみすぎて夜しか眠れません😪
ぜひ皆さんもご一緒に明日の記事で勉強しましょう!