Abstract
漫画研究というのは日本ではちらほらあるものの、世界的にみるとまだ十分ではないように感じる。
実際の人間と漫画の人間とでは目の大きさや鼻などの形やバランスが異なり、損失関数などの設計も変わる場合がある。
とりあえずは上のような難しいことは考えずYolov3というモデルで漫画の登場人物が男か女かを認識することを考える。
結果は以下の通りである。ここまでのプロセスを解説する。

(諫山創:進撃の巨人1)
Yolov3
Yolov31のv3はバージョン名であり、Yolo(You only look once:一度しか見ない)の略称である。
簡単な説明は私の記事ですが2と3を参考にしてください。
詳細は4を参考にしてください。
Implements
まずは1を参考にしてGithubからdarknetをダウンロードなどを済ます。
次に教師データを作成する。
ツールはtzutalinさんのLabelImgを使用する。
デフォルトでクラス名が設定されているのでdataディレクトリ内のpredefined_classes.txtを自分のクラス名に編集する。
この例では
man
woman
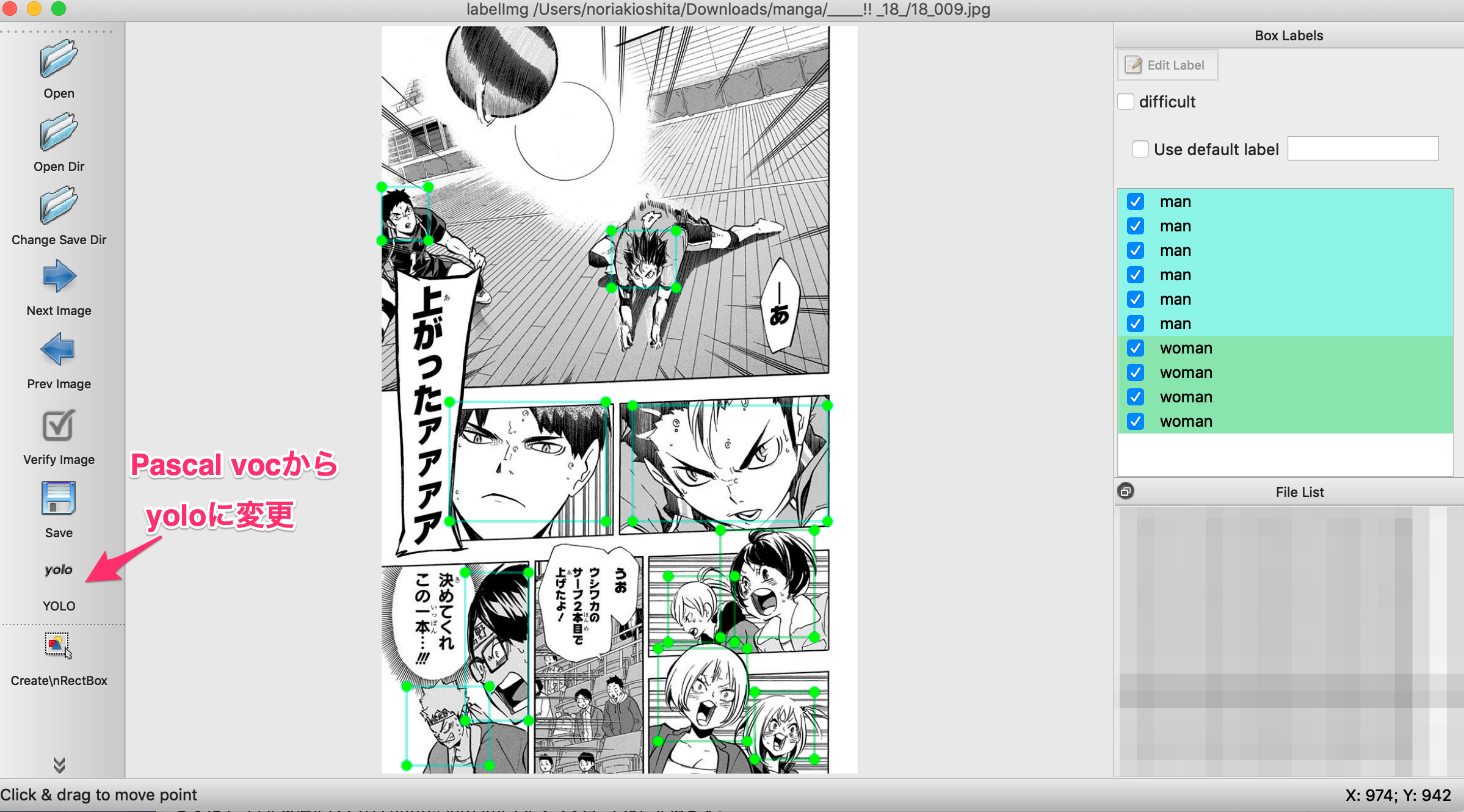
そして5を参考にして、train.txtを作成する。train.txtは各画像のパスが書かれたファイルである。
5を参考にすると実行ディレクトリ内にtrain.txtが作成されるのでこれを一つにする。
cat /path1/train.txt /path2/train.txt /path3/train.txt > /path4/train.txt
もう一つtest.txtも必要である。できればtrain.txtからランダムに抽出して(サンプル数が少ないときは)9:1くらいの割りが望ましいと思う。
サンプル数が多い時は7:3などにすれば良い。
次にyolo側の設定を説明する。
①1を参考にしてdarknet/cfg/yolov3.cfgを探す。
②そのファイル名をdarknet/cfg/yolov3-obj.cfgに変更する。
③次にdarknet/cdg/yolov3-obj.cfg内のclasses=2に変更する(クラスが2なのでもし3クラスなら3にする)
④次にfilters=255からfilters=21に変更する。(filters=255が複数あるので全てfilters=21にする。)
ちなみにyolov2とyolov3でfiltersの計算式が違うので注意。
yolov3では$filters=num/3*(classes + 5)=9/3*(2+5)=21$である。
※numはdarknet/cfg/yolov3.cfgに書いてある。デフォルトでは9。
※あとmax_batchesがepochs数の設定なので、変更を忘れないこと。
次にクラス名が書かれたdarknet/cfg/faces.namesを作成する。
man
woman
次にdarknet/cfg/faces.dataを作る。
classes = 2
train = cfg/train.txt
valid = cfg/test.txt
names = cfg/faces.names
backup = backup/
うるさいようだが、もしもクラス数がが2ではなく3ならばclasses=3に設定する。
ここまでくればあとは学習のみである。
GPUを使用する場合は(CPUで訓練するならばこの作業は必要ない。その場合は200epochsで1日かかるくらい遅いので相当な覚悟が必要。)
darknet/Makefileを変更する。(※変更後に必ずmakeする。しないとCPUで動作する。)
GPU = 1
CUDNN = 1
以下省略
・・・
訓練
wget https://pjreddie.com/media/files/darknet53.conv.74
./darknet detector train cfg/faces.data cfg/yolov3-obj.cfg darknet53.conv.74
訓練終了結果
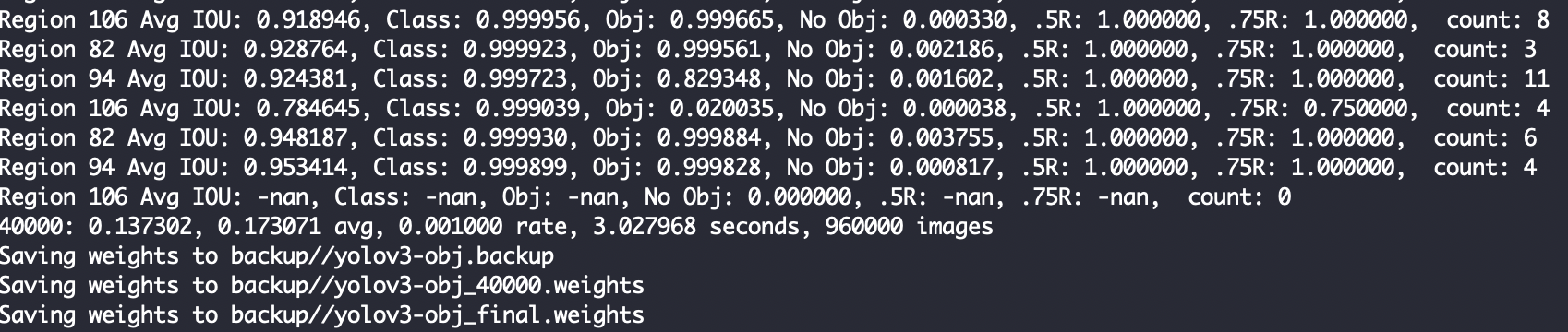
Avg IOUが精度だと思ってほしい、0.5以上いくと良いとされる。この例では0.9以上なのでほぼ的中している。
(過学習かの判断材料は不明。分かれば追記します。)
訓練した後の結果の表示は以下の通りである。
./darknet detector test cfg/faces.data cfg/yolov3-obj.cfg yolov3-obj_〇〇〇〇.weights path/to/image.jpg
darknet/predictions.jpg に結果が保存される。
Conclusions
結果はまあまあだった。漫画だと学習していない漫画の画像をテストしてみると認識結果が悪いことがわかった。
現実世界の人間とは違って漫画の作者の独特の書き方があるからだと思われる。
しかし、精度としては割とよく認識できてたのは流石のdarknet様様である。