次の記事の続きです.
YOLO(You Only Look Once )をざっくばらんに説明する①
https://qiita.com/NoriakiOshita/items/cbd122cbb4bcd6286f12
前回の記事ではバウンディングボックスについて曖昧に書いていましたので,本記事ではその補足記事です.
まず、画像をS×S分割したひとつひとつの要素をセルと呼びます.
目的
1.各セルがどのオブジェクトに属しているかを推定することです.
2.1を行ったあとは信頼スコアをIoUによって計算してバウンディングボックスをオブジェクトにつき一つにします.(前記事参照.)
具体的方法
まず画像から沢山のバウンディングボックスが検出されます.
ですが一つのオブジェクトにはひとつのバウンディングボックスのみ表示したいです.
これを信頼スコアを用いて一つにします.(これをNMSなどと呼びます.)
各セルはのCの条件付きクラス確率$Pr(Class_i | Object)$も予測します。これらの確率は、オブジェクトを含むセルに基づいて調整されます。
各バウンディングボックスは5つの要素を含みます矩形領域のためのx, y, w, h,と信頼度です.
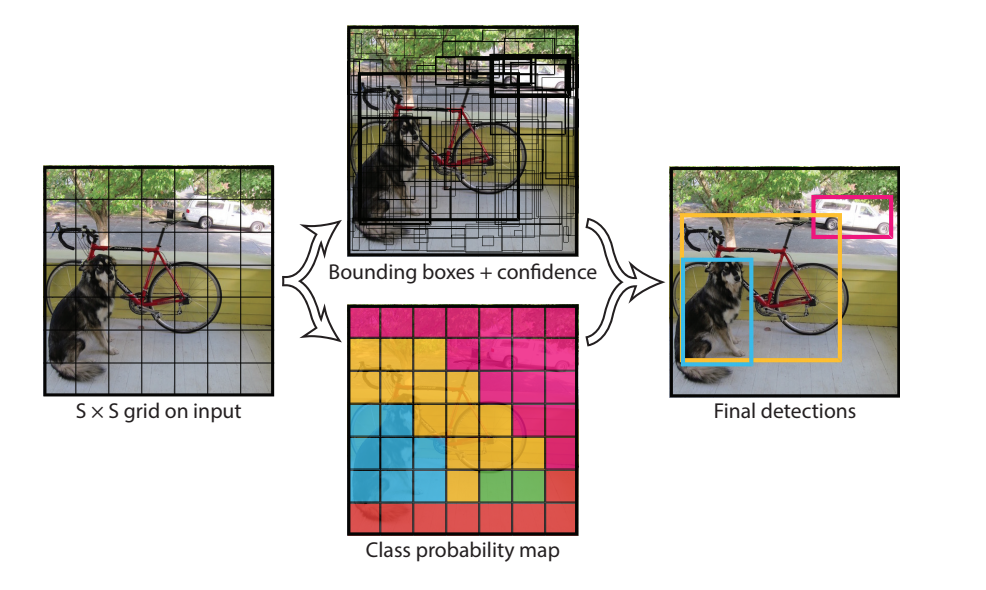
図1. 参考文献[1]から
この情報を用いて損失関数を最小化します.

図2. 参考文献[1]から
参考文献
[1]「You Only Look Once:Unified, Real-Time Object Detection」
https://arxiv.org/pdf/1506.02640.pdf