はじめに
この記事ではYOLO(You Only Look Once)のバックグラウンドをできるだけ数理的に説明することを試みる記事である.
YOLOの目的
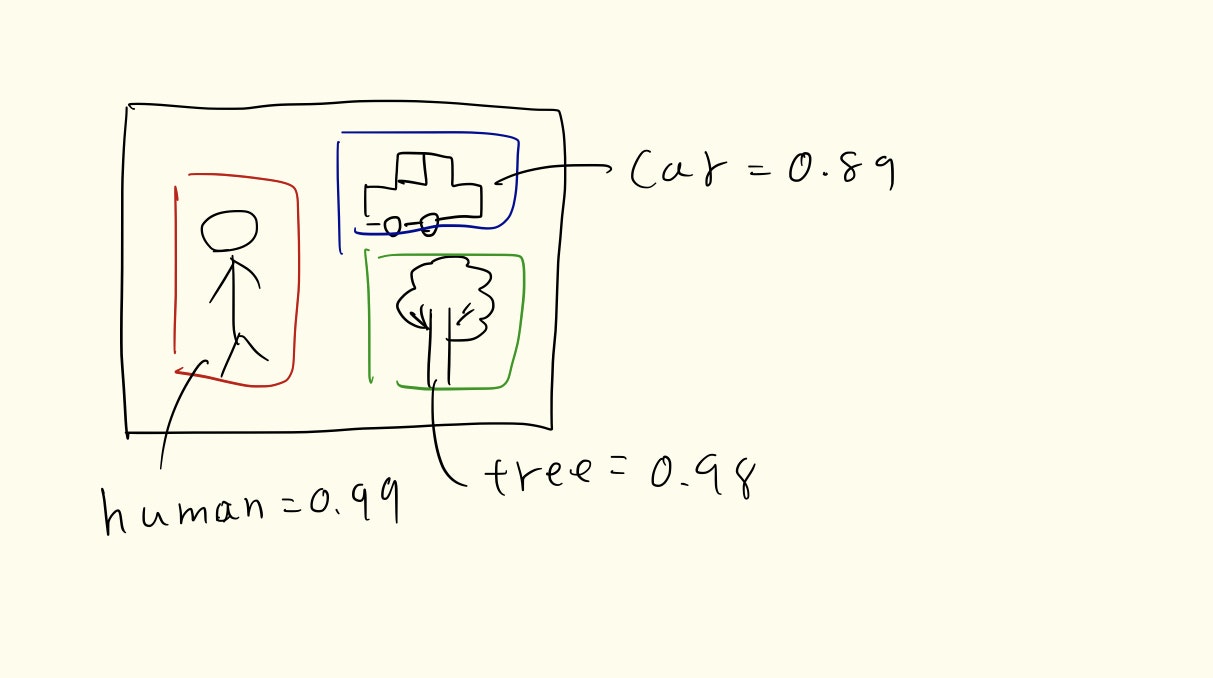
YOLOは物体を個別に認識したいというのが目的である.そのようなモデルは昔からあったが計算効率が悪く,一つのモデルで最初から最後まで完結する方が良いであろうという考えのもと生まれたものである.
YOLO仕組み
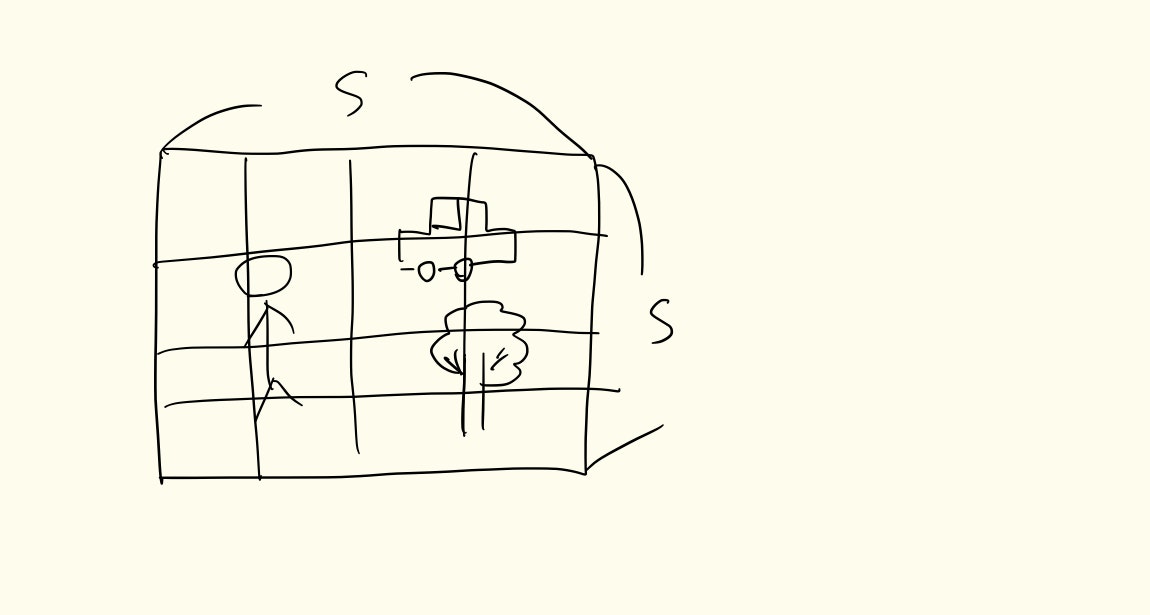
YOLOは与えられた画像XをS×Sに分割する.Sは任意の数字で良いと思うが論文ではS=7,つまり7×7で書かれている.(分割の数が増えれば計算量ももちろん増える.)
なぜS×Sに分割するかと言えばオブジェクトがバウンディングボックス(というよく分からない名前がついているが画像内に沢山の四角を生成してその四角ひとつひとつのこと) という,その四角にオブジェクトは含まれているのかを計算し,結論的にはどの物体がどれくらいかの割合で含まれているかを知りたいのである.
そこで,まずはキーワードを紹介したい.
$Pr(Object)$は四角にオブジェクトが含まれている確率である.
IoU(Intersection over Union)とは
\frac{T \bigcap P}{T \bigcup P}
Tは本当の物体を含む四角である,Pは予測された物体を含む四角である.
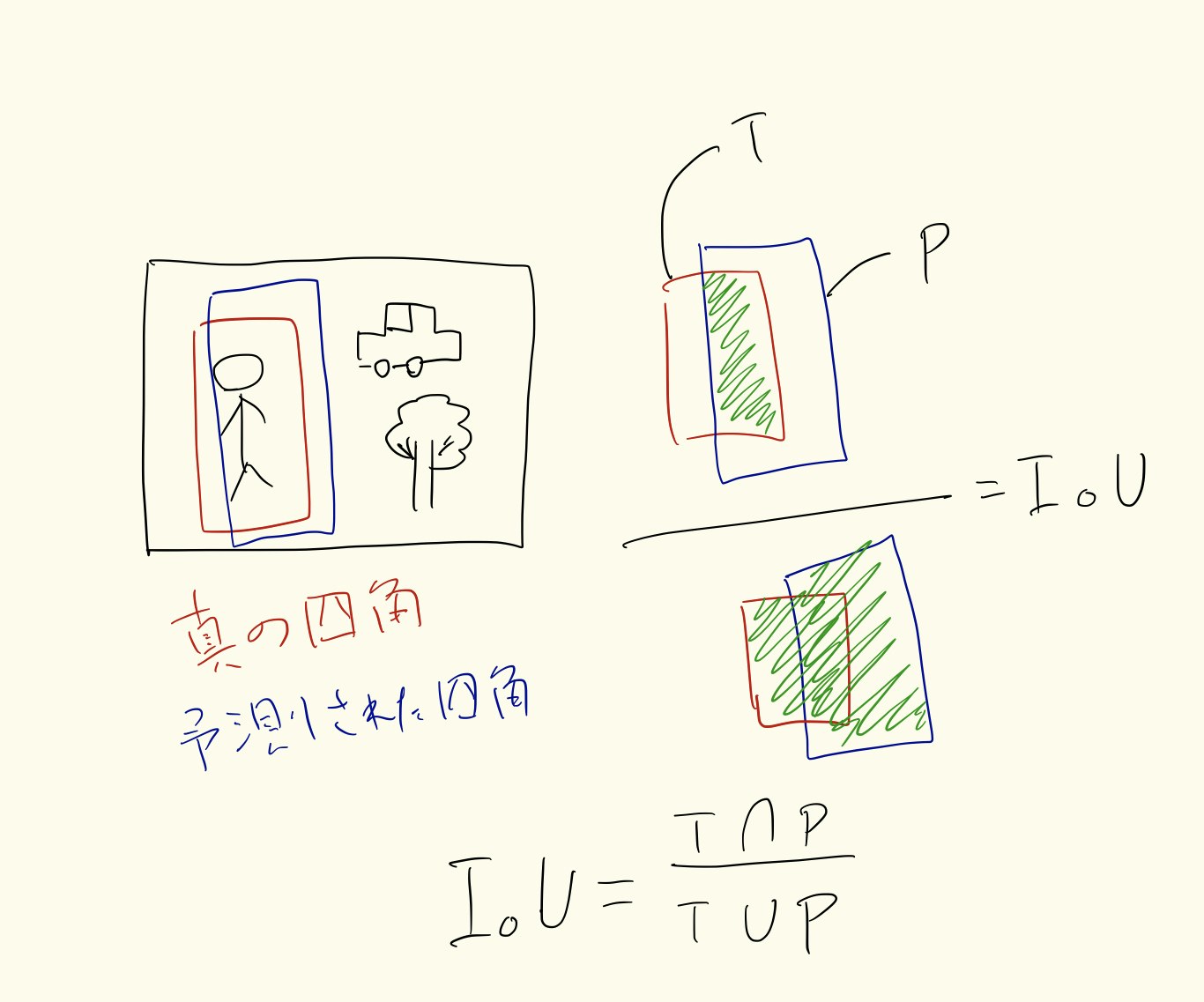
もちろんTとPが分離してたら空集合になるので0になる。値が小さいほど離れていることを意味する。
0.5以上で良いとされる。1になると覆ってるか、完全に重なっていることを意味する。
次に$Pr(Object)・IoU$とは先ほどの”四角が物体を含む確率”×”IoU(物体が被ってる比)”であるので,これを四角がどれくらい物体を含んでいるかを定義することが出来た.
次に$Pr(Class_i | Object)$とは$Class_i$(つまり存在する物体の個数,この例の場合は人と車と木で3であるので(i=1,2,3))に物体(Object)が含まれる条件付き確率である.
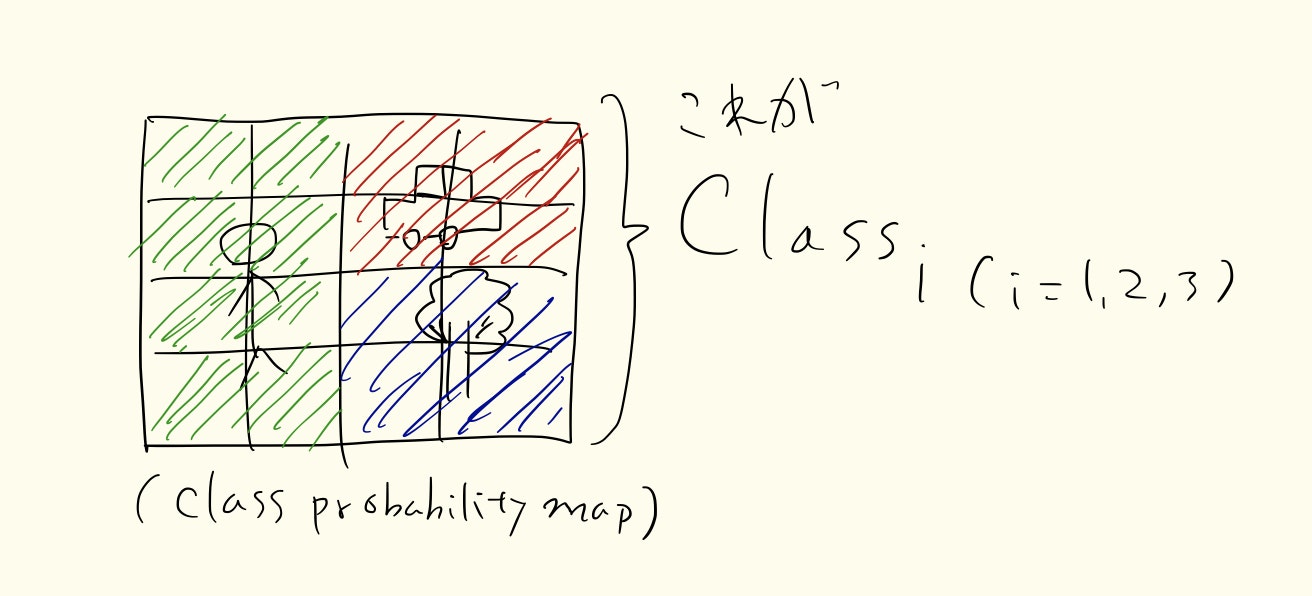
そして最後に$Pr(Class_i | Object)・Pr(Object)・IoU$="$Class_i$に物体(Object)が含まれているか"×"四角がどれくらい物体を含んでいるか"を計算するとどの物体をより含んでいるかの確率がでる.
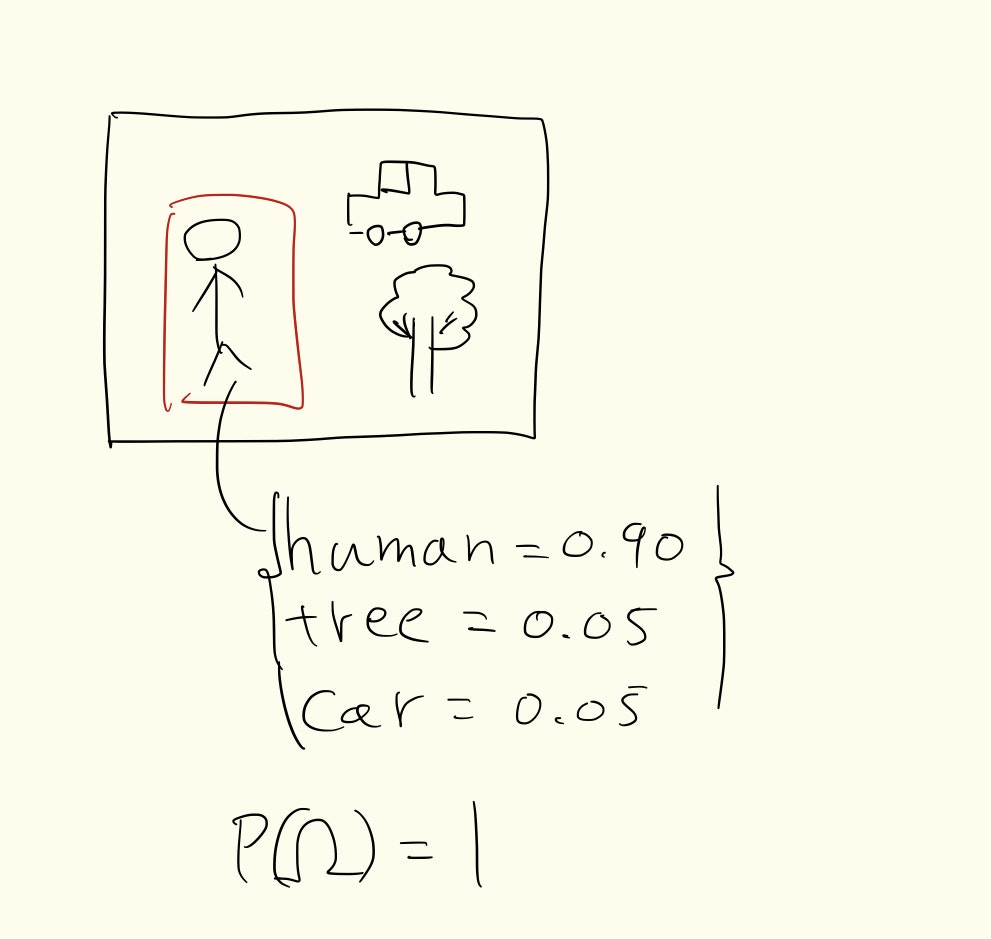
次回は損失関数やネットワークについて書く予定です.最終的に実装までいけたら良いなと思っています.
参考文献
https://arxiv.org/pdf/1506.02640.pdf
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088