はじめに
Microsoft Ignite 2025のセッション「BRK289: Customized AI That Understands Your Business With Copilot Tuning」を視聴しました。

このセッションでは、Microsoft 365 Copilotを企業固有のビジネスニーズに合わせてカスタマイズする「Copilot Tuning」について、技術的な詳細とともに解説されていました。
汎用的なAIと企業固有の業務プロセスの間にはギャップがあり、それをどう埋めるかは多くの企業が直面している課題だと思います。このセッションでは、その課題に対するMicrosoftのアプローチが詳しく説明されており、非常に興味深い内容でした。
この記事では、Copilot Tuningの技術的な基礎から実践的な活用方法、そして企業導入時の考慮点まで、セッションから得られた学びをまとめています。
汎用AIと企業固有AIのギャップ
セッションの冒頭で強調されていたのは、AI生産性向上の実現には「テナント知識と経験」が不可欠だという点です。
汎用的なAIは確かに強力ですが、以下のような限界があります:
- 業界固有の知識を持たない
- 企業固有のプロセスを理解していない
一方で、企業には数十年にわたって蓄積された貴重な知識があります:
- 文書作成のトーン、知識、フォーマットのベストプラクティス
- ビジネス成果に対する重要性の判断基準
- 企業固有のプロセスや役割の理解
汎用AIと企業知識のギャップ

どの企業も独自の業務フローや用語体系を持っていて、それを理解せずにシステムを導入しても十分な効果は得られません。AIも同じなのかなと思います。
Copilot Tuningのビジョンと4つの原則
Microsoftが掲げるCopilot Tuningのビジョンは「Microsoft 365 Copilotをビジネスにパーソナライズする」ことです。
このビジョンを実現するための4つの原則が示されていました:
- データと専門知識はあなたのもの: 企業のデータと専門知識が独自の価値を生み出す
- 誰でもCopilotをチューニング可能: 情報ワーカーが自分のタスクに合わせてCopilotを調整できる
- エンタープライズ保護とガバナンス: セキュリティとガバナンスが確保されている
- ビジネスに合わせてパーソナライズ: 企業固有のニーズに対応
Copilot Tuningのビジョン
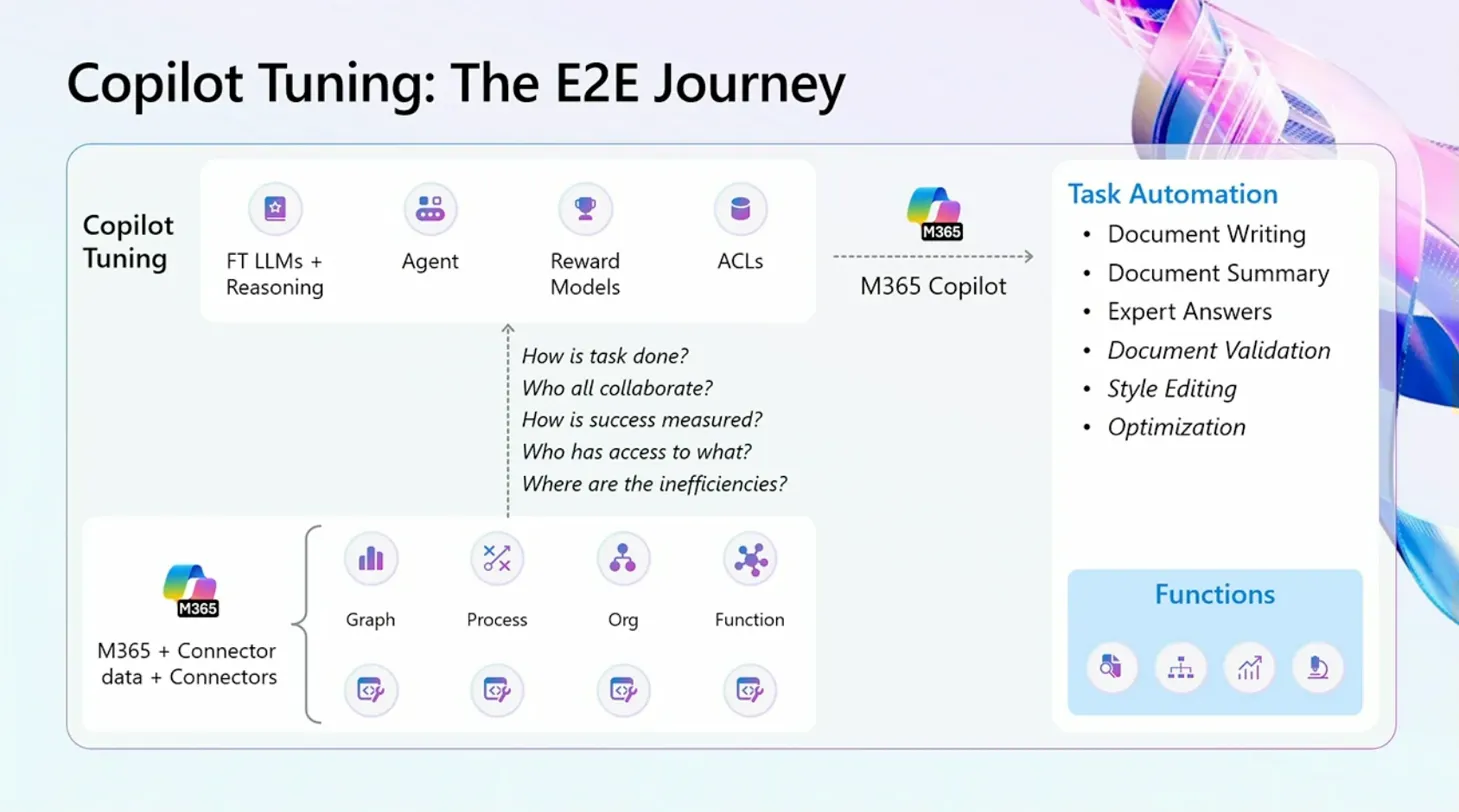
この4つの原則の中で特に重要だと感じたのは、「誰でもチューニング可能」という点です。従来のAIカスタマイズはデータサイエンティストやエンジニアの領域でしたが、情報ワーカー自身が調整できるようになることで、より実務に即したカスタマイズが可能になりそうです。
ファインチューニングの技術体系
Copilot Tuningでは、3つの段階的なファインチューニング技術が使用されています。
Supervised Tuning: 話し方を学ぶ
Supervised Tuning(教師あり学習)では、企業固有の文法、構造、フォーマット、トーン、スタイルを学習します。
例えば法律事務所の場合、組織の構文やセマンティクス(トーンとスタイル)に沿った法的文書を生成できるようになります。
Reasoning Finetuning: 思考を学ぶ
Reasoning Finetuningでは、既存の文献、過去の成果、クライアントのコンテキストを通じて推論し、企業の思考に基づいた議論を展開できるようになります。
法律事務所の例では、過去の判例や企業の戦略を踏まえて、勝訴の可能性を最大化する論理を構築できます。
Agentic Finetuning: 働き方を学ぶ
Agentic Finetuningでは、複数のエージェントとファインチューニングされたモデルを組み合わせて、完全な役割やAI同僚を実現します。
法律事務所の例では、パラリーガルやアソシエイトのような役割を果たすAIが実現できます。
ファインチューニングの技術体系

この3段階のアプローチは非常に理にかなっていると感じました。単に文章の形式を真似るだけでなく、思考プロセスや業務の進め方まで学習できる点が、実用的なカスタマイズを可能にするのだと思います。
データ準備の効率化技術
ファインチューニングには高品質な学習データが必要ですが、それを人手で準備するのは大変です。セッションでは、データ準備を効率化する2つの技術が紹介されていました。
Sargy: 高品質データセットの生成
Sargyは、ノイズの多い顧客データから高品質なデータセットを作成する技術です。
主なアイデア:
- AIを使ってファインチューニング用のデータセットを生成
- AI生成データで報酬モデルを訓練
- 報酬分布が低信頼のAI生成物を特定
- 低信頼データのみに人間のラベル付けを集中
この手法により、異なるデータセットで人間のアノテーションを10%未満に削減できたとのことです。
Sybil: データ準備の自動化
Sybilは、意図と品質サンプルから学習データを自動生成する技術です。
GeneratorとDiscriminatorを組み合わせて、品質の高いデータを効率的に生成します。
データ準備のコスト削減は、企業でのAI導入において非常に重要な課題です。この技術により、少ない人手でファインチューニングが可能になれば、導入のハードルが大きく下がりそうだと感じました。
強化学習による継続的改善: DRO
DRO(Direct Reasoning Optimization)は、検証不可能なタスクに対して新しい報酬シグナルを作成する技術です。
主なアイデア:
- 参照ドキュメントへの思考の連鎖の整合性を測定する報酬シグナル
- 訓練中のモデル自身を使って報酬を計算
- 報酬を使ってオープンエンドな推論をファインチューニング
- 高品質な学習データを優先し、コストを削減しながらパフォーマンスを向上
DROにより、段落修正タスクで勝率が30%向上したとのことです。
この「モデル自身を使って報酬を計算する」というアプローチは興味深いと思いました。人間がすべてを評価するのではなく、AIが自己改善のサイクルを回せるようになれば、継続的な品質向上が期待できそうです。
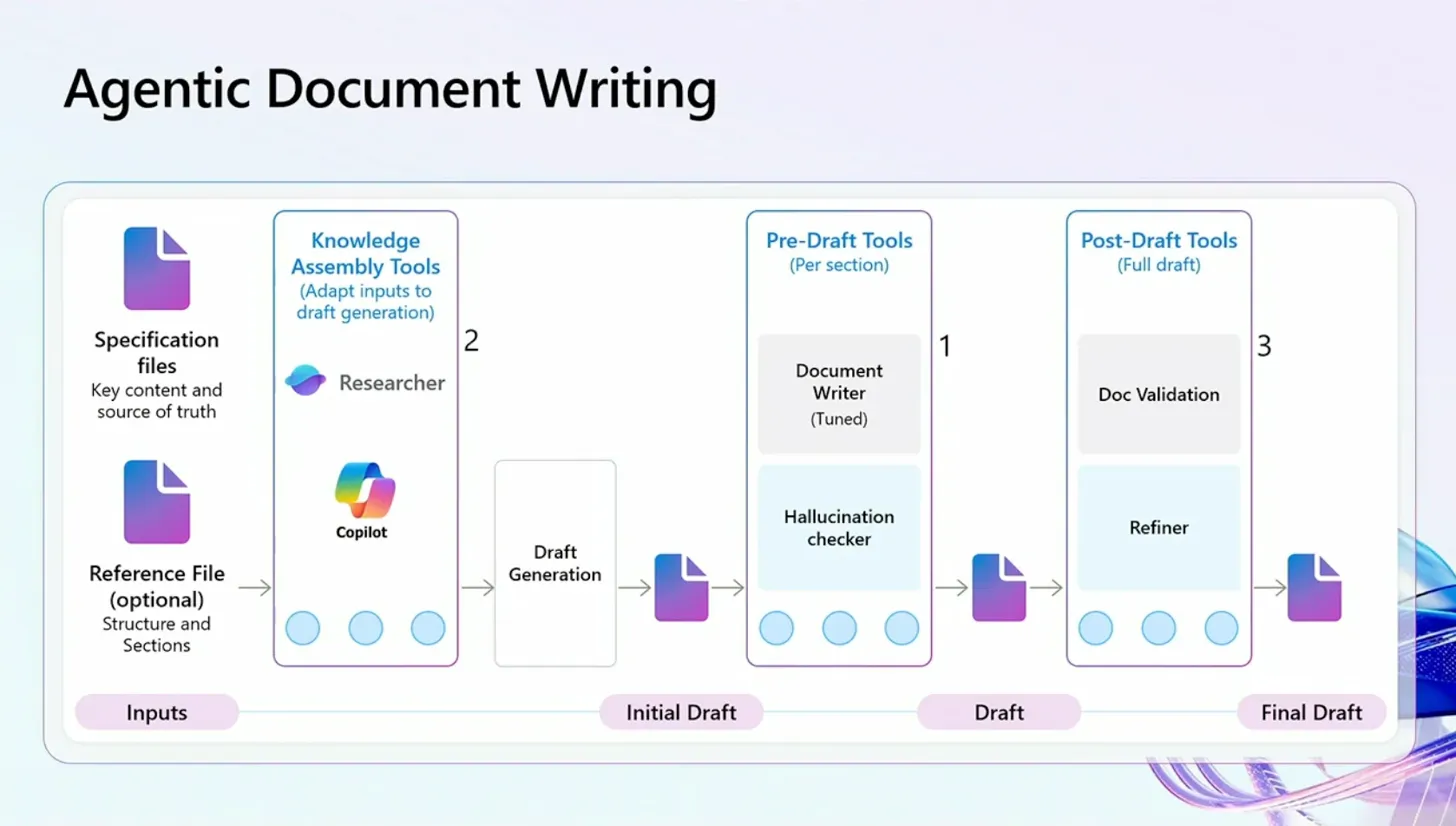
実用例: Document Writingエージェント
セッションでは、Document Writingエージェントの具体例が詳しく説明されていました。
エージェントの機能
Document Writingエージェントは以下の機能を提供します:
- 仕様書から組織のスタイルに沿った洗練された文書を生成
- 文書作成時間を数日から数分に短縮
- 仕様を参照テンプレートに自動マッピング
- セクションごとに設定可能なツールでデータ強化と検証
- フォーマット、コンプライアンスチェック、品質保証のための文書後処理ツール
エージェントの構成フロー
- 入力: 仕様ファイルと参照ファイル(オプション)
- Knowledge Assembly Tools: ResearcherとCopilotを使ってドラフトを生成
-
Pre-Draft Tools(セクションごと):
- Document Writer(チューニング済み)
- Hallucination checker
-
Post-Draft Tools(完全なドラフト):
- Doc Validation
- Refiner
Document Writingエージェントのフロー
この具体例を見て、実際の業務にどう適用できるかイメージが湧きました。提案書作成や技術文書作成など、定型的なフォーマットがある文書作成業務では、すぐに効果が出そうだと感じます。
セキュリティとガバナンス
企業でAIを活用する上で、セキュリティとガバナンスは最重要課題です。Copilot Tuningでは以下の仕組みが提供されています。
テナント分離環境でのファインチューニング
- Microsoft 365 Graphからのテナント分離されたデータ抽出
- テナント分離環境でのデータ準備
- Microsoft 365トラストバウンダリ内でのトレーニング
ACLの継承
ファインチューニングされたモデルは、使用されたデータからACL(アクセス制御リスト)を継承します。これにより、推論時にもデータアクセス権限が適切に管理されます。
AI Adminコントロール
管理者は以下のような詳細なコントロールが可能です:
- チューニングの有効化範囲(全ユーザー、特定ユーザー/グループ、無効化)
- オープンソースモデルチューニングの有効/無効
- チューニング可能なエージェントの管理
- 共有エージェントインベントリでのチューニング可能エージェントの管理
日本企業でAIを導入する場合、セキュリティとガバナンスへの懸念が大きな障壁になることが多いです。テナント分離やACL継承といった仕組みがあることで、情報システム部門も安心して導入を検討できるのではないかと思います。
企業での活用を考えてみて
活用可能性
Copilot Tuningは、以下のような業務で大きな効果が期待できそうです:
文書作成業務: 提案書、契約書、技術文書など、定型フォーマットがある文書の作成を大幅に効率化できる可能性があります。特に、企業固有の用語や表現スタイルを学習させることで、修正の手間が減りそうです。
専門知識の活用: 過去の成功事例や社内のベストプラクティスを学習させることで、経験の浅いメンバーでも高品質なアウトプットが出せるようになるかもしれません。
業務の標準化: 企業固有のプロセスやルールをAIに学習させることで、業務の標準化と品質の均一化が進む可能性があります。
導入時の課題
一方で、実際の導入にはいくつかの課題もありそうです:
学習データの準備: Sargyなどの技術で効率化されているとはいえ、初期の学習データ準備には一定の工数が必要です。どのデータを使うか、品質をどう担保するかの判断が重要になりそうです。
効果測定の難しさ: ファインチューニングの効果をどう測定するかは難しい課題だと感じました。単に生成速度だけでなく、品質や実用性をどう評価するか、明確な基準が必要になります。
組織の文化: AIが生成した文書を信頼できるか、どこまで人間がレビューすべきかなど、組織の文化や考え方によって受け入れ方が変わりそうです。
コストと効果のバランス: ファインチューニングには一定のコストがかかります。どの業務から始めるか、投資対効果を見極める必要があります。
まとめ
このセッションを通じて、Copilot Tuningの技術的な基盤と実用的な活用方法について理解を深めることができました。
主な学び:
- 汎用AIと企業固有知識のギャップを埋めるために、3段階のファインチューニング技術が提供されている
- データ準備の効率化技術により、少ない人手でカスタマイズが可能になっている
- セキュリティとガバナンスが適切に設計されており、企業での利用に耐えうる仕組みになっている
- Document Writingなど、具体的な業務での活用例が示されており、実用化のイメージが持てる
Copilot Tuningは、AIを企業の実務に適用する上での大きな一歩になる可能性を感じました。ただし、導入にあたっては、学習データの準備、効果測定、組織文化への配慮など、技術面以外の課題にも丁寧に対応する必要がありそうです。
まずは小規模に試しながら、自社に合った活用方法を見つけていきたいと思います。