はじめに
Microsoft Ignite 2025で、Azure Cosmos DBを使ったエージェントメモリの構築に関するセッション「From DEV to PROD: How to build agentic memory with Azure Cosmos DB」を視聴しました。

私自身、これまで多くのプロジェクトでCosmos DBを活用してきており、AIエージェントのメモリ管理についても実装経験があります。Short-term MemoryとLong-term Memoryの設計パターンは実務で試行錯誤しながら構築してきましたが、今回のセッションでは、自分が実践してきたアプローチがベストプラクティスとしてどう体系化されているのかを確認したいと考えました。
また、IntelepeerやWalmart Chileといった実際の本番環境での事例が紹介されるとのことで、自分の設計判断が他の企業の実装とどう一致・相違するのか、特にエンタープライズレベルでのスケール時の課題や工夫について知見を得られることを期待してこのセッションを選びました。
エージェントメモリとは何か
セッションではまず、メモリの定義から説明がありました。メモリとは「データや情報を書き込み、保存し、必要なときに取り出す心の機能」であり、「将来の行動に影響を与えるために時間をかけて情報を保持すること」と定義されています。
AIエージェントにおいても、人間の記憶と同様に、以下の3つのプロセスが重要になります:
- Write(書き込み): 何を、どのように、いつ、どう更新するか
- Store(保存): どこに、どんな構造で、忘れるタイミングは
- Retrieve(取り出し): 何を、どのように、どれだけの量を取り出すか
エージェントメモリには大きく分けて2種類があります。
**Short-term Memory(短期記憶)**は、現在のセッション内での会話履歴、ワーキングメモリ(一時的な状態や変数)、注意コンテキスト(エージェントが今考えていること)などを含みます。
**Long-term Memory(長期記憶)**は、セッションをまたいで保持されるもので、ファクチュアルメモリ(ユーザー固有の事実)、エピソディックメモリ(過去の注文やサポート履歴などの離散的なイベント)、セマンティックメモリ(カテゴリーや製品関係などの一般的な知識)に分類されます。
なぜAzure Cosmos DBなのか
エージェントメモリを構築する際、データベースに求められる要件は多岐にわたります。柔軟な検索方法、マルチテナンシー、柔軟なデータモデル、コスト効率、低レイテンシー検索、スケーラビリティ、そしてエンタープライズ対応が必要です。
データベース要件とAzure Cosmos DBの強み

Azure Cosmos DBがこれらの要件を満たす理由として、セッションでは以下の点が強調されていました:
クエリとセマンティック検索の統合: SQL-likeなシンタックスに加えて、ベクトル検索、フルテキスト検索、ハイブリッド検索が利用できます。これにより、構造化されたクエリと意味的な検索を組み合わせることが可能です。
設計によるマルチテナンシー: パーティションキー、コレクション、データベースレベルでのテナント分離が可能です。
NoSQLのスキーマフリー設計: ベクトルとデータをJSON形式で一緒に保存できます。エージェントの要求に応じてスキーマを柔軟に進化させられます。
コスト効率: サーバーレスモードでは、10万ベクトルの挿入と10万回の検索でわずか3ドルという驚異的なコストパフォーマンスを実現しています。
高速検索: 10億ベクトルに対して100ミリ秒未満の検索レイテンシーを実現し、あらゆるスケールでエージェントのグラウンディングに対応できます。
高い弾力性: データの自動シャーディングとインスタントオートスケールにより、予期しないトラフィックスパイクにも対応できます。
99.999%のアップタイム: Geo-replication、マルチリージョン対応、データマスキングなど、エンタープライズグレードの機能を備えています。
実際の事例として、OpenAIがChatGPTの会話履歴やユーザーインタラクションをCosmos DBに保存し、50以上のワークロードで活用しているという紹介がありました。トラフィックスパイクに対応しながらゼロダウンタイムを実現し、スキーマレスの柔軟性によってデータ構造を迅速に反復できたとのことです。
エージェントメモリの種類とデータモデル

Short-term Memory の設計
Short-term Memoryのデータモデルは、「1ターンごとに1ドキュメント」という設計パターンが推奨されています。

具体的なJSON構造では、各ドキュメントに以下の情報が含まれます:
-
id: テナントIDとスレッドIDの組み合わせ -
type: "turn"などのタイプ指定 -
threadId: 会話スレッドの識別子 -
messages: ユーザーとエージェントのメッセージ配列 -
embedding: ベクトル埋め込み -
metrics: レイテンシーなどのメトリクス情報
このモデルの利点は、ターンレベルの粒度で管理できること、リアルタイムコンテキストに効率的であること、マルチモーダルな検索に対応できること、セマンティックキャッシングをサポートできること、そしてスキーマが簡潔でエージェントやツールのニーズに応じて進化できることです。また、TTL(Time To Live)を使って古いメモリを自動的に削除できる点も実装上のメリットです。
Long-term Memory の設計
Long-term Memoryは「1つのサマリーごとに1ドキュメント」という設計になります。
ドキュメント構造には以下が含まれます:
-
type: "summary"などのタイプ -
user_id、thread_id: ユーザーとスレッドの識別子 -
summary: LLMが生成した会話のサマリー -
facts: 抽出された重要な事実の配列 -
embedding: 空の配列(後で生成) -
token_count: トークン数 -
last_updated: 最終更新日時
このモデルは、コンパクトで効率的であり、検索に最適化されており、更新が容易です。長期記憶として適している一方で、細かい詳細が失われる可能性があり、モデルに依存した精度、追加の計算コスト、潜在的な古さ、リプレイや監査には適さないという考慮点もあります。
セッションでは、Short-term MemoryからLong-term Memoryへの変換を、Azure FunctionsやAzure Container Appsなどのバックグラウンドワーカーで非同期処理することが推奨されていました。これにより、アプリケーションコードが非同期処理ジョブによって遅くならないようにできます。

パーティショニング戦略
Cosmos DBでエージェントメモリを設計する際、パーティションキーの選択は非常に重要です。セッションでは3つのパターンが紹介されていました。
ThreadID (GUID)をパーティションキーとする場合: 会話スレッドごとにデータを取得・更新するのが主なアクセスパターンで、各スレッドが比較的独立している場合に適しています。ユーザーやテナントをまたいだクエリはほとんど行わず、各スレッドをストレージと取得の自然な単位として扱う場合に有効です。
UserID/ThreadIDをパーティションキーとする場合: 特定のユーザーのすべてのスレッドを同じパーティションにグループ化し、「ユーザーXの最近のすべてのスレッド」や「スレッド間での最新のターン」といったクエリを効率的に実行できます。これにより、ユーザースコープとスレッドスコープの両方の局所性が得られます。
TenantID/UserID/ThreadIDをパーティションキーとする場合: マルチテナントシステムを運用し、テナントレベルでの分離やグループ化が必要で、その後ユーザーレベル、さらにスレッドレベルでの分離が必要な場合に使用します。最大の粒度と階層的な局所性を提供し、テナントが大規模でテナントごとにスケールする必要があるシナリオに対応します。
パーティションキーの設計は、Cosmos DBを使う上で最も悩ましい部分の一つです。、後からパーティションキーを変更するコストは非常に高いので、初期設計での慎重な検討は本当に重要だと改めて感じました。
実装のベストプラクティス
セッションでは、エージェントメモリを実装する際の実践的なTipsが数多く共有されていました。
スレッドのサマリー作成について: メモリタイプにタグを追加し、サマリーを「メモリアンカー」として複数の個別ターンを置き換えつつ、コアとなるナラティブは保持します。古いスレッドを再ハイドレートする際や、クロススレッド検索を行う際にサマリーを取得します。効率性を重視し、SLM(Small Language Model)や「mini/nano」バージョンのLLMを使用してコストとサマリー作成のレイテンシーを削減します。そして、Short-term MemoryからLong-term Memoryへの変換、サマリー作成、プルーニング、メタデータ更新などの処理をバックグラウンドワーカー(Azure FunctionsやAzure Container Appsなど)にオフロードし、アプリケーションコードが非同期処理によって遅くならないようにします。
ストレージと取得について: アクティブなセッションはメモリ(RAM)に保持し、プロンプトのグラウンディングと高速なトークンアセンブリのために現在の会話状態を保持します。古いメモリや即座には必要ないメモリが必要な場合にのみストレージから取得します。ターン(またはイベント)ごとに即座に永続化し、クラッシュやセッションドロップ時のデータ損失を回避します。再ハイドレート、セマンティック検索、コンテキスト検索のためには取得を使用します。エージェントを再ハイドレートする際やコンテキスト状態を再構築する際、または過去のインタラクションを検索する際に、ストレージから古いメモリをロードします。
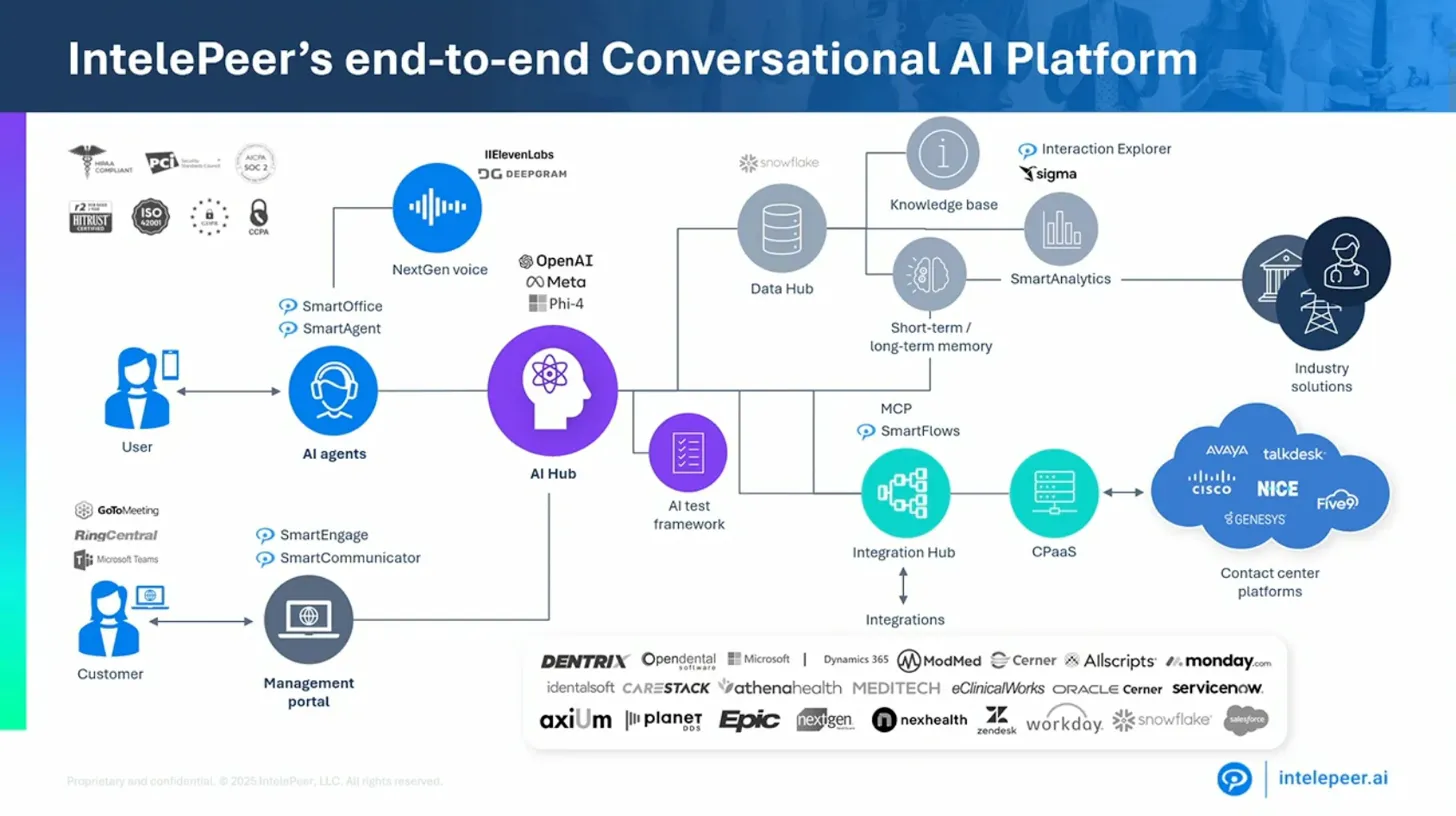
この図は、Intelepeerが実装しているエージェントメモリフレームワークの全体像です。ユーザーからの入力がGuardrailsとControllerを経由し、複数のSubAgentに分散され、それぞれがCosmos DBのShort-term MemoryとLong-term Memoryを参照しながら動作し、Processing Pipelineで処理されるという構造になっています。
これらのベストプラクティスの多くは、私も実装の中で経験的に学んできたことです。特に「アクティブセッションはRAMに保持し、必要な時だけストレージから取得する」という戦略は、レイテンシー要件が厳しいアプリケーションでは必須だと実感しています。また、SLMを使ったサマリー生成のコスト削減についても、実際に大規模運用するとコストが無視できなくなるため、早い段階から考慮すべきポイントだと思います。
実際の本番環境での活用例
セッションでは、IntelepeerとWalmart Chileという2つの実際の本番環境での活用事例が紹介されていました。
Intelepeerのケース: Intelepeerは、音声中心のエンタープライズ向け会話型AIプラットフォームを提供しており、ヘルスケアやその他の業界向けに複数のコンタクトセンタープラットフォームと統合しています。彼らが直面していた課題は、低レイテンシーの音声中心のエコシステムで、音声エージェントが学習、適応、成長できる高速で信頼性の高いメモリが必要だったことです。
具体的な要件としては、ネイティブマルチテナンシー(同じエージェントが複数の顧客にサービスを提供)、カスタム動作のオーバーライドや再利用可能なコンポーネントを持つエージェント設定、チャット・推論・分析といった複数のパターン、高速推論、ネイティブな可観測性、統合された評価機能、推論ベンダーに依存しない設計、Short-term Memoryとしてのコンテキストエンジニアリング、Long-term Memoryとしてのエージェント行動への影響などがありました。
Walmart Chileのケース: Walmart Chileでは、従業員と顧客の両方にサービスを提供するため、短期記憶と長期記憶の両方が必要でした。複数層のデータ(AIエージェント設定状態、個人ユーザーデータ、企業レベルデータ、垂直データ)を管理し、Cosmos DBとCosmos DB-based Graph(*) を活用しています。
両社の事例を聞いて、特に共感したのはマルチテナンシーとスキーマレスの柔軟性が高く評価されていた点です。私自身もマルチテナントシステムを構築する際、Cosmos DBのパーティショニング機能とスキーマフリーの設計が非常に役立ちました。Intelepeerの音声エージェントにおける低レイテンシー要件も、リアルタイム性が求められるアプリケーションでの課題として共感できます。他社の実装を知ることで、自分の設計が特異なものではなく、一定の普遍性を持っていることを確認できました。
Azure Cosmos DBの新機能
セッションでは、エージェントメモリに関連するCosmos DBの新機能も紹介されていました。
Vector Search(ベクトル検索)の新機能:
- Float16ベクトル: ストレージを50%削減しながらリコールを高く保つ
- パフォーマンス改善: より高速なベクトル挿入、インデックス作成、検索
- Semantic Reranker(Private Preview): AIを活用したクエリ結果の再ランキングで関連性を向上
- Modifiable vector indexes(2026年初頭に提供予定): 新しいコンテナを作成せずにベクトルポリシーとインデックスを追加・削除可能
Full-text Search(フルテキスト検索)の新機能:
- Fuzzy search(一般提供): 近似検索とタイポに強いテキスト検索
- 新しい言語(Public Preview): ドイツ語、フランス語、スペイン語に加え、イタリア語、ポルトガル語、ブラジルポルトガル語をサポート
- より高速な挿入とBM25スコアリング(一般提供): インデックス作成とフレーズ検索のRU課金とレイテンシーを削減
- カスタムストップワード(2026年初頭に提供予定): 柔軟でカスタマイズ可能なストップワードで検索関連性を向上
Float16ベクトルによるストレージ削減は、大規模なベクトルデータを扱う際のコスト問題を解決する可能性があります。私も過去にベクトルストレージのコストが予算を圧迫した経験があるため、この機能は非常に魅力的です。Semantic Rerankerも興味深い機能で、ベクトル検索だけでは上位に来ない関連性の高い結果を引き上げることができそうです。過去のプロジェクトで独自の再ランキングロジックを実装した経験がありますが、これがネイティブ機能として提供されることで、開発負担が大きく軽減されそうだと感じました。
導入時の課題と対策
組織的な課題: AIエージェントの導入には、技術者だけでなくビジネスサイドの理解と協力が不可欠です。私の経験でも、小規模な成功事例を積み重ねながら段階的に展開していくアプローチが最も効果的でした。
特に日本企業では、新しい技術の導入に対して慎重な姿勢を取ることが多いため、まずは限定的なスコープでPoC(概念実証)を行い、明確な成果を示すことが重要だと感じています。
セキュリティとガバナンス: エージェントが扱うデータには、個人情報や機密情報が含まれる可能性があるため、Cosmos DBのデータマスキング機能やアクセス制御を適切に設定し、監査ログを取得する仕組みを構築してきました。
Long-term Memoryに保存されたデータの保持期間やアーカイブポリシーについても、法的要件や業務要件に応じて適切に設計する必要があります。TTLを活用した自動削除は便利ですが、削除タイミングの判断は慎重に行うべきだと経験から学びました。
まとめ
このセッションを通じて、自分がこれまで実践してきたAzure Cosmos DBを使ったエージェントメモリ構築のアプローチが、ベストプラクティスとして体系化されていることを確認できました。以下が主な確認ポイントと新たな気づきです:
- Short-term MemoryとLong-term Memoryの分離、それぞれのデータモデル設計は、自分が実装してきたパターンとほぼ一致しており、設計判断の妥当性を確認できた
- パーティション戦略の3つのパターンは、過去の試行錯誤を通じて学んできたことと合致しており、特にマルチテナントシステムでは階層的なパーティションキーが有効であることを再確認
- サマリー生成のバックグラウンド処理、SLMの活用など、コスト効率と性能のバランスを取るための実践的なTipsは、自分の実装経験と共通しており知識の裏付けとなった
- IntelepeerやWalmart Chileの事例から、エンタープライズレベルでの実装における共通課題と解決策を確認でき、自分の設計が一定の普遍性を持っていることがわかった
- Float16ベクトルやSemantic Rerankerなどの新機能は、既存システムの改善に活用できる可能性があり、今後の実装に取り入れたい