はじめに
モチベーション
ビッグデータ分析・機械学習周りのクラウドサービスを触る中で、AWSのGlueというサービス知りました。サーバーレスにETLジョブを実行できるサービスで、とても使い勝手が良さそうだと感じましたが、使用できるのがSpark(PySpark or Scala Spark)のみであったため、この機会に習得したいと思い学習を開始しました。学習記録として本記事を執筆しましたが、内容としては構築・運用といったデータエンジニアリング寄りの内容ではなく、データ加工や機械学習など「使う」ことを焦点を当てた内容になります。Sparkを触ったことがない方や分散処理アレルギーの方の助けになれば幸いです。
※GlueではSpark以外にも普通のPython scriptも使えますが、分散処理は行えません。
学習手順
① Udemy講座 『Spark and Python for Big Data with PySpark』
② 公式ドキュメント・記事を漁りながらひたすら実装
環境
Doker HubよりJupyter/pyspark-notebook:latestのイメージをpullしそのまま使用。DesktopにPySpark学習用のディレクトリ('PySpark')を作成しマウント。
$ docker pull jupyter/pyspark-notebook
$ docker run -it -v ~/Desktop/PySpark/:/home/jovyan/work -p 8888:8888 jupyter/pyspark-notebook
※本記事執筆時点では、Spark 3.0.1を使用しています。
Sparkの概要
特徴
- OSSの分散処理フレームワーク
- オンメモリ処理、リソース最適化などにより処理が爆速
- スケジューリングやタスク分割などをフレームワーク側でうまいことやってくれる
- Pythonを含む複数の言語(Python, Scala, Java, R, SQL)から使える
- 機械学習やストリーム処理など機能が充実している
どんな時に使う?
- 1台のサーバーで扱いきれない大規模データを処理したい時
- データ量がスケールしても動く仕組みが欲しい時
- 特にリアルタイム処理や機械学習を行いたい時
PySparkの2つのプログラミングモデル(RDDとDataFrame)
- RDDはクラスタに分散したデータを抽象化して1つのデータとして扱うためのオブジェクトで、DataFrameはさらにRDDを構造化データとして扱えるようにしたオブジェクトである。
- RDDはコレクション操作のように処理を記述するのに対し、DataFrameはSQLライクに記述する。
- RDDが非構造データに対する柔軟な処理が行えるのに対し、DataFrameはスキーマを利用した構造化データを処理する。
- RDDが行志向の処理であるのに対し、DataFrameは列志向の処理である。
- (PySparkの場合)RDDではWorkerノードでの処理がタスクごとにPythonプロセスに変換されるのに対し、DataFrameではJVM上で行われる(下図)。
- DataFrameを基にした高級API(Strictured Streaming, Spark ML, Graph Frame)が作られている。
※ ScalaとJavaでは、さらにこれらの良いとこ取りをしたようなDatasetのAPIがサポートされている。

Scalaは必須か??
SparkといえばScalaというイメージが強い方も多いかと思います。Sparkは元々がScalaで書かれているため、やはりScalaを使うことのメリットも大きく、Scala vs Pythonの議論は度々起こるみたいです。処理速度に関しては、DataFrameを扱えるようになってから言語間の差はほとんどなくなったようです。Pythonの方がデータ分析のためのライブラリが豊富であることなどを考えると、個人的にはまずはPySparkからやってみるのが良いのではと思います。もちろん両方使えるのがベストですが、ScalaはPythonと比べ学習コストが高いため、今回はPySparkを使用します(Scalaは絶賛学習中)。
ビッグデータ分析におけるSpark
ビッグデータの分析や機械学習のプロジェクトにおいて、Sparkが具体的にどの部分に使われるのか、AWSのアーキテクチャを例に取りながら見ていきます。
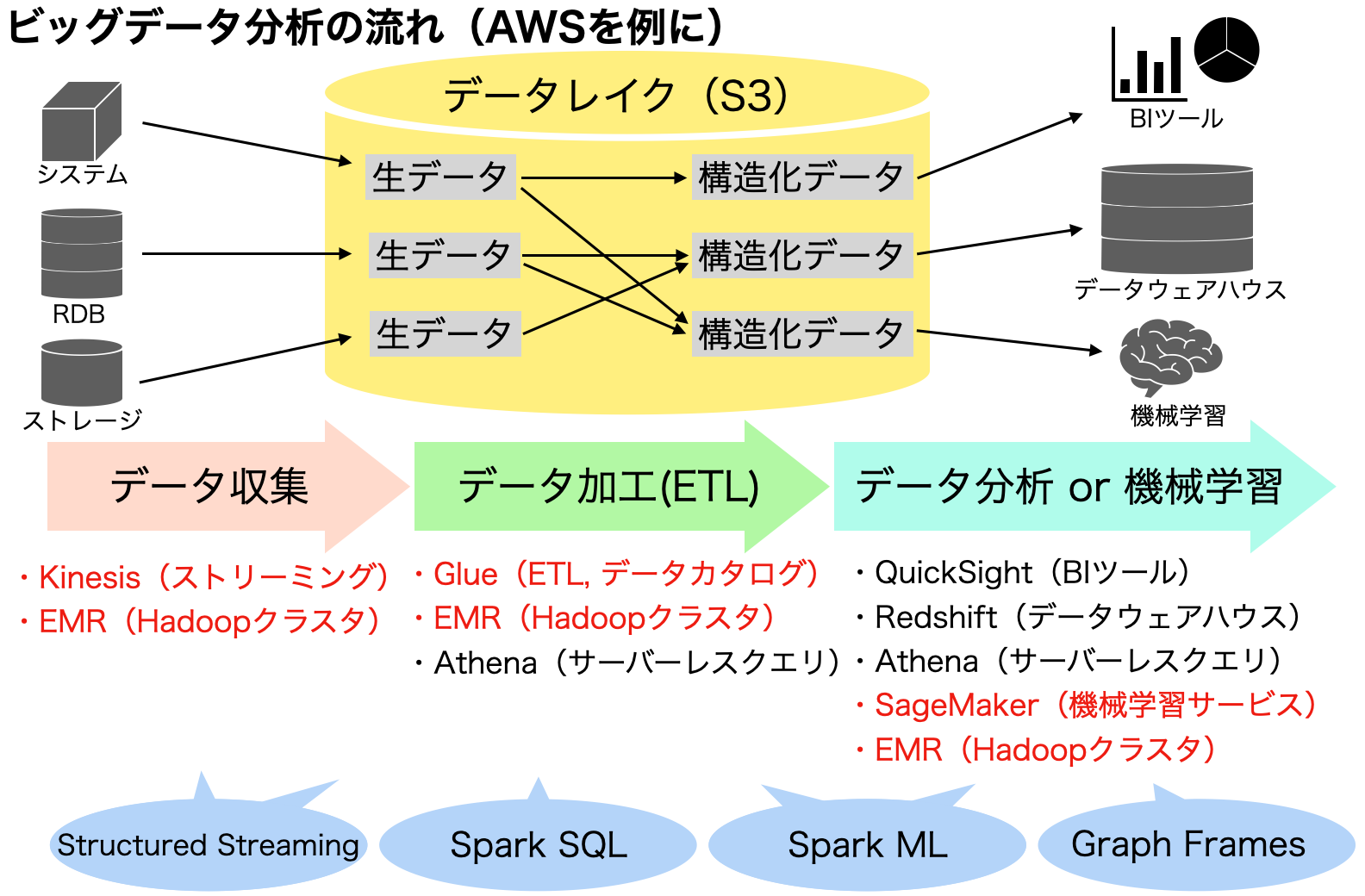
プロセスとしては、データソースから必要なデータを集める「データ収集」、集めたデータを分析や機械学習で使いやすいように変換する「データ加工(ETL)」、そしてBIツールやデータウェアハウスなどを利用した「データ分析( or 機械学習)」の大きく3つに分けられますが、Sparkはこの3つのどのプロセスでも利用され、用途に応じた高級APIも用意されています。一貫してSparkが使えるというのも、他の分散処理エンジンとは異なる特徴かと思います。
AWSでSparkを使う方法として、最もわかりやすいのはEMRでHadoopクラスタを立ち上げる方法です。その場合には、Zeppelin(Jupyter Notebookのようなもの)を使うか、SSHでマスターノードにアクセスしてSpark shellを起動するかしてSparkのコードを書いていくことが多いようです。他にも、Sage Makerのように間接的にEMRを起動させたり、Glueのようなサーバーレスなサービスでも使用することができます。
AWS Glueを使ったETL
Glueには大きく「データカタログ」と「ETL」の機能があります。データカタログはApache Hiveメタストア互換のマネージドサービスで、メタデータ(スキーマ・ロケーションなど)管理を行うものになります。ETLでは、サーバーレスにETLジョブを実行することができ、ジョブの実行やテーブルの作成・更新を自動で行うクローラーという機能もあります。カラム選択やparquet変換、partition化などよくやるような簡単な操作であればGUI操作のみで実行することができ、その際に自動でスクリプトが生成されるため、さらに柔軟な処理を行いたい場合はそこに追記する形でコードを書いていくことができます。
Sparkでの機械学習
Spark MLには、以下のような手法が実装されています。
- 前処理系
PCA / SVD / StandardScaler / MinMaxScaler /OneHotEncoding / LabelEncoding / PolynominalExpansion / NGram / Tokenizer / StopWordRemover / TF-IDF / Word2Vec … - モデル
LinearRegression / LogisticRegression / SVM / DecisionTree / RandomForest / GBDT / Kmeans / LDA / ALS / NMF … - 評価・チューニング
TrainValidationSplit / CrossValidation / GridSearch / 各種評価
見てみると、Scikit-learnで実装されているよく使うような手法はほとんど実装されているように感じました。また、外部パッケージの開発も進んでおり、例えばMicrosoft社が提供するMML Sparkではコンペでもよく使われるLightGBMが使えたり、AWSのSageMakerではXGBoostが使えたり、さらにはDeep Learning系モデルを提供するものもあります。実装例については、是非以下の記事を読んでいただけると幸いです。
Sparkに実装されていない手法を使うには?
Sparkのライブラリにすでに多くの機械学習手法が実装されていますが、やはりPythonに比べると未実装の機能も多くあります。そんな未実装の処理を実装したい時に使えるのがUDF(User Defined Function)です。UDFには普通のUDFとPandas_UDFの2種類がありますが、後者が推奨されています。公式ドキュメントによると、UDFをベクトル化によって高速に処理できるようにしたのがPandas_UDFのようです。あまり気にせずPandas_UDFを使っていれば良いかと思います。
例として、Janome(Pythonの日本語形態素解析ようライブラリ)を使用した単語分割の実装コードを載せておきます(あくまで簡単に書けることを示すためのものです。実装については別記事でも書く予定です)。
# Pandas DataFrameの場合
from janome.tokenizer import Tokenizer
# JanomeのTokenizerのインスタンスを立て、単語分割してリストとして返す関数を定義
janome = Tokenizer()
def janome_tokenizer(text):
return [tok for tok in janome.tokenize(text, wakati=True)]
# DataFrameに対してapply()メソッドで上の関数を適用
df['tokenized_comments'] = df['comments'].apply(janome_tokenizer)
# PySpark DataFrameの場合
from janome.tokenizer import Tokenizer
from pyspark.sql.types import StringType, ArrayType
from pyspark.sql.functions import pandas_udf, PandasUDFType
# ここは同じ
janome = Tokenizer()
def janome_tokenizer(text):
return [tok for tok in janome.tokenize(text, wakati=True)]
# UDFを定義
@pandas_udf(ArrayType(elementType=StringType()), PandasUDFType.SCALAR)
def janome_wakati(pds): #入力はPandas.Series
pds = pds.apply(janome_tokenizer)
return pds
# Spark DataFrameに定義した関数を適用
tokenized_df = df.withColumn('tokenized_comments', janome_wakati(data.select("comments")))
このように、UDFを使えばPandasのSeriesやDataFrameで行っていた処理をPySparkでも簡単に実装することができます。Pandas_UDFには3つのタイプ(SCALAR, GROUPED_AGG, GROUPED_MAP)があり、ざっくりいうと1つのSeriesを扱う時にはSCALAR、複数のSeriesを扱う時にはGROUPED_AGG、DataFrameを扱う時にはGROUPED_MAPを使います。上の例だと、テキストデータが入った1つのカラムを受け取り、単語分割後のリストが入った1つのカラムを返しているため、SCALARを使っています。
注意点として、UDFを使用した場合にはワーカーノードでのタスクの実行は、JVM上ではなくPythonプロセスに1つひとつ変換されて行われるため、その分遅くなります(RDDとDataFrameの図参照)。あくまでSparkのライブラリで実装できない処理のみ使うのが良いかと思います。
おわりに
今回はSparkに関して学んだことを、「ビッグデータ分析・機械学習」の観点からざっくりとまとめてみました。ローカル1台でも動かせること、ScalaでなくPythonでも十分にSparkのメリットを活かせること、Pandas/SQL/Scikit-learnに慣れていればPySparkは扱いやすいこと、以上3点が分かればSparkを学ぶハードルがグッと下がるのではと感じました。次の記事から、PySparkを使って色々と実装してみたことを紹介していければと思います。ありがとうございました。
※ 参考
https://ohke.hateblo.jp/entry/2018/09/01/234500
https://www.slideshare.net/hadoopxnttdata/apache-spark-nttdata-devsummit2016
https://hktech.hatenablog.com/entry/2019/01/08/194519
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f
https://qiita.com/paulxll/items/98cd3d3d8adbf6197660
『AWSではじめるデータレイク』(テッキーメディア)
『ビッグデータを支える技術』(技術評講社)
『Spark and Python for Big Data with PySpark』(Udemy)