はじめに
本記事では、前記事に引き続きPySparkを使った機械学習の実装練習として、MovieLensデータを使用して簡単なレコメンドシステムを実装してみました。データセットはこちらからml-small-latest.zipをダウンロードし解凍して使用しました。アルゴリズムの種類や使用データなどレコメンドシステムの概要を簡単に説明した後に、Sparl MLで実装されていALSModelを実装していきます。
実行環境
DockerでJupyter/pyspark-notebook:latestのimageをpullしそのまま使っています(Python 3.8.6, Spark 3.0.1)。詳しくはこちらの記事をご覧ください。
レコメンドの概要
レコメンドとは?
商品情報や行動履歴データをもとに、ユーザーにおすすめの商品を「推薦」するものです。通販サイトなどでよく見る「この商品を購入した人は合わせてこの商品も購入しています」などが例です。
レコメンドシステムで使われるデータ
レコメンドシステムで使われるデータには、大きく「商品の属性情報」と「ユーザーの行動履歴」があります。前者は、商品ごとの値段やカテゴリ、説明文など、その商品を特徴付けるデータが該当します。後者は各ユーザーの購入履歴や、評価履歴などが該当します。本記事で使用するMovieLensでいうと、movies.csvに入っているデータが属性情報、rating.csvに入っているデータが行動履歴になります。
- 「属性データ」
| movieId | title | genres |
|---|---|---|
| 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 5 | Father of the Bride Part II (1995) | Comedy |
- 「行動履歴データ」
| userId | movieId | rating | timestamp |
|---|---|---|---|
| 1 | 1 | 4.0 | 964982703 |
| 1 | 3 | 4.0 | 964981247 |
| 1 | 6 | 4.0 | 964982224 |
| 1 | 47 | 5.0 | 964983815 |
| 1 | 50 | 5.0 | 964982931 |
レコメンドアルゴリズムの種類
レコメンドシステムで使われているアルゴリズムについて、ここでは代表的なものを3つ取り上げ、メリットデメリットをみていこうと思います。
-
ルールベース
「商品Aを買ったら商品Bを」「購入回数が5回以上のユーザーには商品Cを」など予めルールを決めておき、それに従ってレコメンドするもの(非機械学習手法)。シンプルでわかりやすいというメリットはあるが、ルールを定める作業が手間であり、商品やユーザーが増えていった時に応用が聞きにくいことがデメリットとなる。 -
コンテンツベース
属性情報を使用して商品同士の類似度を算出し、購入した商品と類似度の高い商品をレコメンドするもの。代表的な例としては、商品カテゴリ情報からTf-Idfなどにより特徴量を抽出し、各商品の特徴ベクトルからcos類似度を求める方法がある。ルールベースと比較すると実装が容易で精度が高くなりやすい点がメリットであり、さらに行動履歴情報を使用しないためコールドスタート問題も起こらない(3. 協調フィルタリング参照)。一方で、同じようなものしかレコメンドされず目新しい商品との出会い(セレンディビティ)が生じないため、行動履歴データが十分にある際には協調フィルタリングより精度が劣る傾向がある。
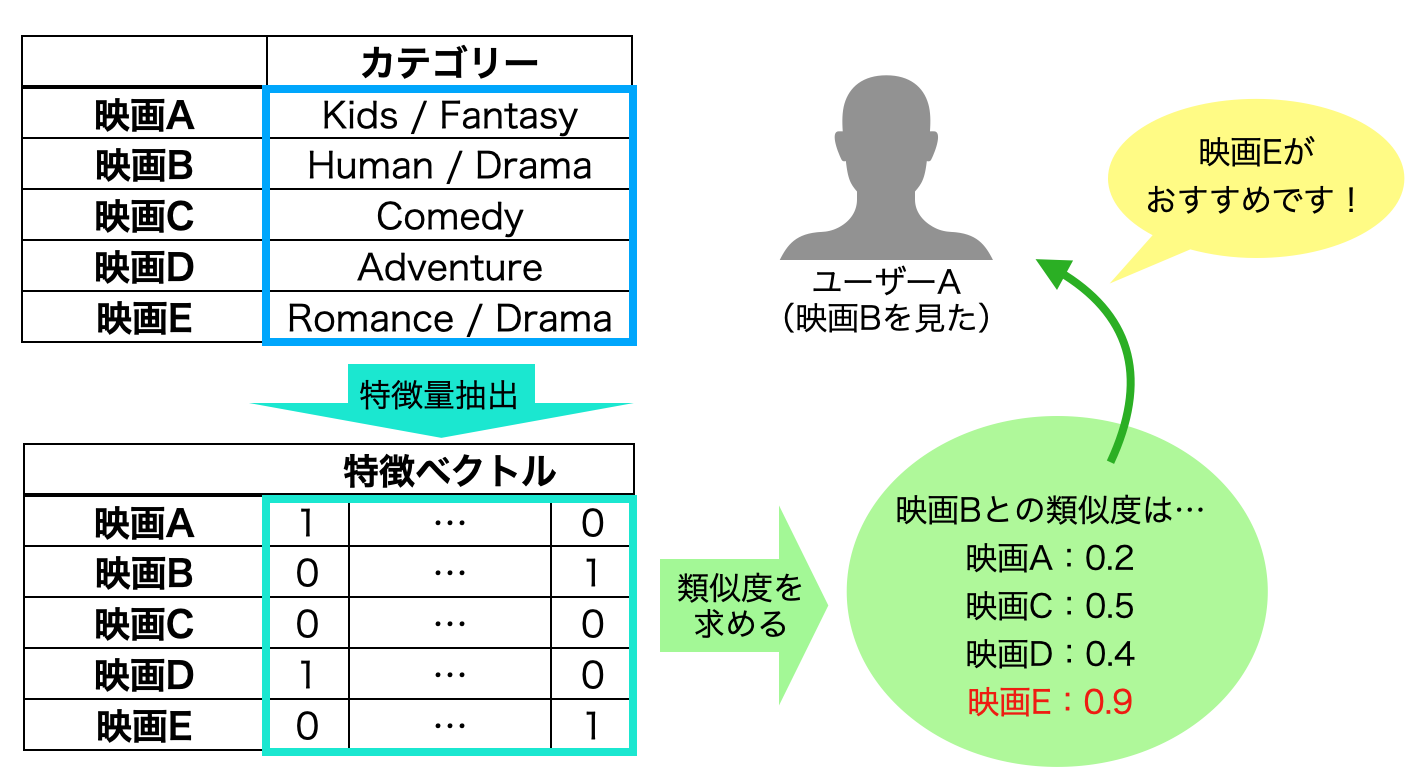
3. 協調フィルタリング
ユーザーの行動履歴データから商品同士の類似度、あるいはユーザー同士の類似度を算出しレコメンドするもので、前者をアイテムベース、後者をユーザーベースと呼ぶ。行動履歴データは、(アイテム数)×(ユーザー数)のかなり巨大なデータとなり、またそのほとんどがnull(計算の際には0に置き換える)となるSparseデータになる。そのため、特徴ベクトルの次元を圧縮するために行列分解を行うことが多い。協調フィルタリングでは行列分解の中でも、行列の要素を全て0以上にするNMF(非負値行列分解)がよく使われる。コンテンツベースよりもセレンディビティが生じやすく、精度も高くなる傾向があるのがメリットである一方、行動履歴情報の量が不十分な時にはうまく機能せず(コールドスタート問題)、新商品や新規ユーザーに対する精度も悪くなってしまうのがデメリットである。
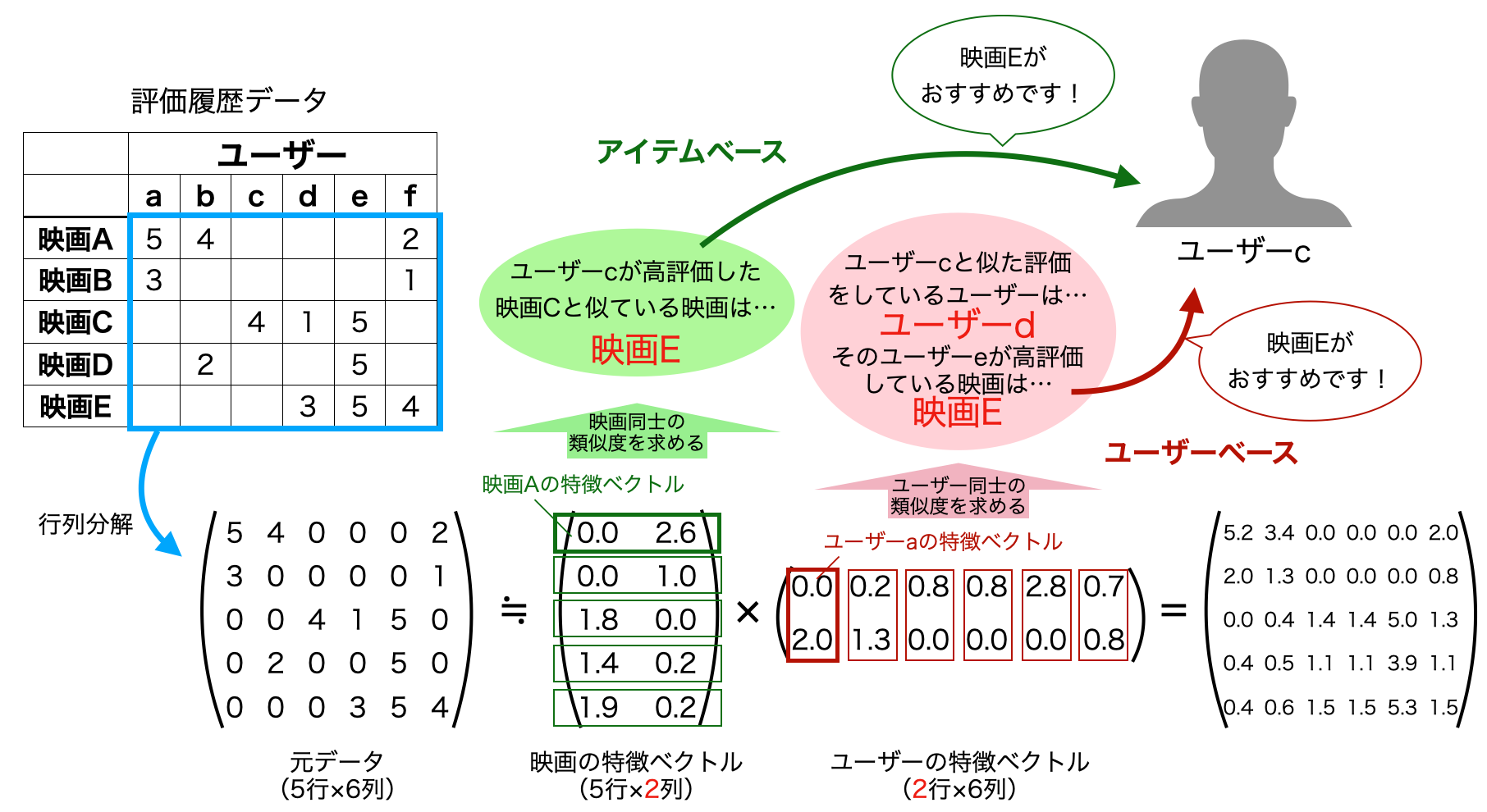
※その他のレコメンドアルゴリズム
上で紹介した「コンテンツベース」と「協調フィルタリング」はあくまでアルゴリズムの大きな括りであり、具体的な計算手法は多岐にわたります。またそれ以外にも、両者の良いとこどりをしたような**Smart Adaptive Recommendations (SAR)**や、Deep Learningを使用したものもあります。SARに関してはMicrosoftが公開しているSparkの外部パッケージ(MML Spark)に実装されているため、今後実装してみようと思います。
PySparkで協調フィルタリングの実装
データの概要を確認
DataFrameの扱いなどについては、前記事をぜひ読んでいただけると幸いです。
# セッション起動
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('ALS').getOrCreate()
# データ読み込み
ratings = spark.read.csv('ratings.csv', header=True, inferSchema=True)
movies = spark.read.csv('movies.csv', header=True, inferSchema=True)
# ratingsのshapeとスキーマ確認
print('ratings_shape:', (ratings.count(), len(ratings.columns)))
ratings.printSchema()
>>>
ratings_shape: (100836, 4)
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true)
# ratingsを5件表示
ratings.show(5)
>>>
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1| 4.0|964982703|
| 1| 3| 4.0|964981247|
| 1| 6| 4.0|964982224|
| 1| 47| 5.0|964983815|
| 1| 50| 5.0|964982931|
+------+-------+------+---------+
# moviesのshapeとスキーマ確認
print('movies_shape:', (movies.count(), len(movies.columns)))
movies.printSchema()
>>>
movies_shape: (9742, 3)
root
|-- movieId: integer (nullable = true)
|-- title: string (nullable = true)
|-- genres: string (nullable = true)
# moviesを5件表示
movies.show(5)
>>>
+-------+--------------------+--------------------+
|movieId| title| genres|
+-------+--------------------+--------------------+
| 1| Toy Story (1995)|Adventure|Animati...|
| 2| Jumanji (1995)|Adventure|Childre...|
| 3|Grumpier Old Men ...| Comedy|Romance|
| 4|Waiting to Exhale...|Comedy|Drama|Romance|
| 5|Father of the Bri...| Comedy|
+-------+--------------------+--------------------+
# ユーザー数を調べる
ratings.select('userId').distinct().count()
>>>
610
# 評価のある映画の数を調べる
ratings.select('movieId').distinct().count()
>>>
9724
ALSの実装
ALSとは交互最小二乗法のことで、NMFの手法の一つになります。Spark MLに実装されているレコメンドアルゴリズムは現時点ではこのALSのみなので、今回はこれを使っていきます。引数rankで圧縮したい次元数を指定しています。また、Scikit-learnでNMFを実装する際には事前に縦方向をmovieID, 横方向をuserIDとしたマトリクス形式(ピボットテーブル)にratingsデータを加工する必要がありますが、Spark MLのALSではそのままuserColとitemColを指定することができます。
from pyspark.ml.recommendation import ALS, ALSModel
# モデルの作成
als = ALS(
rank=20,
maxIter=10,
regParam=0.1,
userCol='userId',
itemCol='movieId',
ratingCol='rating',
seed=0
)
# モデルの学習
als_model = als.fit(ratings)
movie, userの特徴ベクトルはそれぞれ.itemFactorsと.userFactorsでDataFrame形式で取得することができます。shapeを確認してみると、どちらも20次元になっていることがわかります。
# movieの特徴ベクトル(W)とuserの特徴ベクトル(H)を取得
W_movies = als_model.itemFactors
H_users = als_model.userFactors
# WとHのshapeを確認
W = W_movies.select('features').collect()
H = H_users.select('features').collect()
print('W:', (len(W), len(W[0][0])))
print('H', (len(H), len(H[0][0])))
>>>
W: (9724, 20)
H: (610, 20)
moviesベクトルの類似度を確認してみる
試しに、movieの特徴ベクトルを使って類似度を確認してみます。movieId=1, 3114, 176579はそれぞれ『Toy Story』『Toy Story2』『Cage Dive』になるので、この3つの映画の類似度を比較してみます。
# 下の3つで試してみる
movies.filter('movieId IN (1, 3114, 176579)').show()
>>>
+-------+------------------+--------------------+
|movieId| title| genres|
+-------+------------------+--------------------+
| 1| Toy Story (1995)|Adventure|Animati...|
| 3114|Toy Story 2 (1999)|Adventure|Animati...|
| 176579| Cage Dive (2017)|Drama|Horror|Thri...|
+-------+------------------+--------------------+
cos類似度の計算は、現時点ではSpark MLで実装されていません。Mllibの方では実装されていたようですが、今回は簡単にnumpyのarrayに変換して計算してみます。
# cos類似度をnumpyで計算する
import numpy as np
tmp = W_movies.filter('id IN (1, 3114, 176579)').orderBy('id').select('features').collect()
# 各movieの特徴ベクトルを取得
toystory1_vec = np.array(tmp[0][0])
toystory2_vec = np.array(tmp[1][0])
cagedive_vec = np.array(tmp[2][0])
# cos類似度を算出する
print('Toy StoryとToy Story 2の類似度:', (toystory1_vec @ toystory2_vec) / (np.linalg.norm(toystory1_vec) * np.linalg.norm(toystory2_vec)))
print('Toy StoryとCage Diveの類似度 :', (toystory1_vec @ cagedive_vec) / (np.linalg.norm(toystory1_vec) * np.linalg.norm(cagedive_vec)))
>>>
Toy StoryとToy Story 2の類似度: 0.9472396175366493
Toy StoryとCage Diveの類似度 : 0.7528829246037524
結果を確認すると、『Toy Story』と『Toy Story2』の類似度は、『Toy Story』と『Cage Dive』の類似度と比較してかなり高くなっていることがわかります。
レコメンドを実行する
.recommendForAllUsers()を使うと、指定したユーザーごとにレコメンドすべき映画を優先順位が高い順に取得できます。引数numItemsで上位何検分取得するか指定できます。
# userID:100におすすめの映画
tmp = als_model.recommendForAllUsers(numItems=10).filter('userId = 100')
tmp.select('recommendations.movieId').collect()
>>>
[Row(movieId=[33649, 74282, 5867, 7121, 1066, 26528, 7071, 179135, 26073, 84273])]
# レコメンドされた映画の詳細確認
movies.filter('movieId IN (106642, 33649, 87234, 1046, 93988, 2843, 171495, 1755, 318, 177593)').show()
>>>
+-------+--------------------+--------------------+
|movieId| title| genres|
+-------+--------------------+--------------------+
| 318|Shawshank Redempt...| Crime|Drama|
| 1046|Beautiful Thing (...| Drama|Romance|
| 1755|Shooting Fish (1997)| Comedy|Romance|
| 2843|Black Cat, White ...| Comedy|Romance|
| 33649| Saving Face (2004)|Comedy|Drama|Romance|
| 87234| Submarine (2010)|Comedy|Drama|Romance|
| 93988|North & South (2004)| Drama|Romance|
| 106642|Day of the Doctor...|Adventure|Drama|S...|
| 171495| Cosmos| (no genres listed)|
| 177593|Three Billboards ...| Crime|Drama|
+-------+--------------------+--------------------+
全体的に'Drama', 'Romance', 'Comedy'などに分類される映画がレコメンドされています。では次に、実際にuseId:100のユーザがこれまで高評価してきた映画をみてみます。今回は評価:5をつけた映画のみフィルターをかけてみます。
# useId=100, rating=5でフィルターをかける
tmp = ratings.filter('userId = 100 AND rating = 5')
# movieデータと結合する
tmp.join(movies, tmp.movieId == movies.movieId, how='inner').select(['title', 'genres']).show()
>>>
+--------------------+--------------+
| title| genres|
+--------------------+--------------+
| Top Gun (1986)|Action|Romance|
|Terms of Endearme...| Comedy|Drama|
|Christmas Vacatio...| Comedy|
|Officer and a Gen...| Drama|Romance|
|Sweet Home Alabam...|Comedy|Romance|
+--------------------+--------------+
これまでにも、'Drama', 'Romance', 'Comedy'といったジャンルの映画を高評価していたことが確認でき、嗜好に合った映画がレコメンドされているように感じます。また、注目すべきはmovieId:171495の『Cosmos』も上位に入っていることです。genresが(no genres listed)となっているため、これはコンテンツベースのアルゴリズムではおそらく上位には入らなかったと考えられます。
上ではユーザー視点でレコメンドを行いましたが、recommendForAllItems()を使うとアイテム視点でレコメンドを行うことができます。例えば「ある商品を売り込みたいが、どのユーザーにレコメンドすれば買ってくれる確率が高いか」を考え、効率的に宣伝したいときなどに使えます。
# movieId:100の映画を高評価しそうなユーザーを3人表示する
tmp = als_model.recommendForAllItems(numUsers=3).filter('movieId = 100')
tmp.select('recommendations.userId').collect()
>>>
[Row(userId=[429, 584, 35])]
おわりに
PySparkで協調フィルタリングによるレコメンドを実装してみました。Spark MLで実装されているのは今のところ今回使用したALSだけですが、外部パッケージや各種クラウドサービスで提供されているパッケージでは他のアルゴリズムも実装されているようなので、今後試していければと思います。ありがとうございました。
参考
https://toukei-lab.com/recommend-algorithm
https://ohke.hateblo.jp/entry/2018/09/08/233000