はじめに
マーケティングの分析手法について、Pythonで実際のデータを触りながら学びたいと思い、その学習記録を残す目的で記事を書きました。今回は顧客分析手法のデシル分析とRFM分析になります。
使用データ
Kaggleで公開されているOnline Retail Data Setを使用します。
実行環境
Google Craboratoryで動かしています。Pythonと各ライブラリのバージョンは以下の通りです。
- Python: 3.6.9
- Numpy: 1.19.4
- Pandas: 1.1.5
- Matplotlib: 3.2.2
- Seaborn: 0.11.0
- Scikit-learn: 0.22.2.post1
顧客のセグメント分析概要
顧客をある特性ごとに分割することで、優良顧客を見つけたり、効率的に広告を打つことなどができるようになります。セグメント分けには性別や年齢などの属性を使う方法もありますが、ここでは購買履歴データを使用した2つの分析手法を扱います。
デシル分析とは
顧客を、購入金額順に並べて10分割することでセグメント分けする方法です。
RFM分析とは
以下3つの指標により顧客をセグメント分けする方法です。
- Recency:直近何日前に利用したか
- Frequency:ある期間中にどれくらいの頻度で利用したか
- Monetary:ある期間中に利用した合計金額
デシル分析の実装
データの読み込み, EDA, 前処理
# 基本モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
データ型を指定してデータを読み込みます。
# データ読み込み
dtypes = {
'InvoiceNo': 'object',
'StockCode': 'object',
'Description': 'object',
'Quantity': 'int8',
'InvoiceDate': 'datetime64[ns]',
'UnitPrice': 'float64',
'CustomerID': 'object',
'Country': 'object'
}
raw_data = pd.read_csv('./data/OnlineRetail.csv', dtype=dtypes, engine='python')
# 概要確認
print(raw_data.shape)
raw_data.head(20)
>>>
(541909, 8)
各カラムを簡単に説明すると
- InvouceNo:発注番号
- StockCode:商品番号
- Description:商品説明
- Quantity:購入個数
- InvouceDate:購入日時
- UnitPrice:商品単価
- CustomerID:顧客番号
- Country:国
デシル分析では、Quantity, UnitPrice, CustomerIDを使用します。もう少しデータを調べてみると
# 欠損値などを確認
raw_data.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 541909 non-null object
1 StockCode 541909 non-null object
2 Description 540455 non-null object
3 Quantity 541909 non-null int8
4 InvoiceDate 541909 non-null datetime64[ns]
5 UnitPrice 541909 non-null float64
6 CustomerID 406829 non-null object
7 Country 541909 non-null object
dtypes: datetime64[ns](1), float64(1), int8(1), object(5)
memory usage: 29.5+ MB
CustomerIDカラムに欠損があります。また、
# 数値変数の統計量確認
raw_data.describe()

QuantityとUnitPrice一部に負の値が入っていることがわかります。購入のキャンセル時などに負の値が入るなど何かしらのルールがあるみたいですが、今回は0以上のデータのみ使用することにします。また、CutomerIDが欠損したデータも除いておきます。
# クレンジング
data = raw_data.query('Quantity >= 0 & UnitPrice >= 0').dropna(axis=0, subset=['CustomerID'])
デシル分析
総額(数量×単価)カラムを作成しておきます。
# 総額 = 数量 × 単価を計算
data['TotalPrice'] = data['Quantity'] * data['UnitPrice']
# 顧客ごとの購入総額を求める
decil = data[['CustomerID', 'TotalPrice']].groupby('CustomerID').sum().reset_index()
decil.head()

この値を用いて、上位から10%ずつに分割していきます。
# 分位点を求める
parties = decil.quantile(q=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]).to_dict()
parties
>>>
{'TotalPrice': {0.1: 151.812,
0.2: 240.62800000000001,
0.3: 340.95799999999997,
0.4: 474.1039999999999,
0.5: 656.6899999999999,
0.6: 905.4079999999998,
0.7: 1309.4160000000002,
0.8: 1954.0280000000002,
0.9: 3488.1160000000036}}
# 分位点で分ける関数を定義
def cal_decil(x, col, df):
if x <= df[col][0.1]:
return 1
elif x <= df[col][0.2]:
return 2
elif x <= df[col][0.3]:
return 3
elif x <= df[col][0.4]:
return 4
elif x <= df[col][0.5]:
return 5
elif x <= df[col][0.6]:
return 6
elif x <= df[col][0.7]:
return 7
elif x <= df[col][0.8]:
return 8
elif x <= df[col][0.9]:
return 9
else:
return 10
# デシルスコアの算出
decil['Decil_score'] = decil['TotalPrice'].apply(cal_decil, args=('TotalPrice', parties))
decil.head()

顧客を1~10のランクに分割することができました。ここからは、各層が全体売り上げのどの程度貢献しているかみていきます。Pandasの.cumsum()や.cumprod()メソッドを使うことで、累積和や累積比率を計算することができます。
# 降順に並び替えて累積和・累積比率を求める
decil = decil.sort_values('TotalPrice', ascending=False)
decil['Cumsum'] = decil['TotalPrice'].cumsum()
decil['Cumprod'] = decil['Cumsum'] / decil['Cumsum'].max()
decil
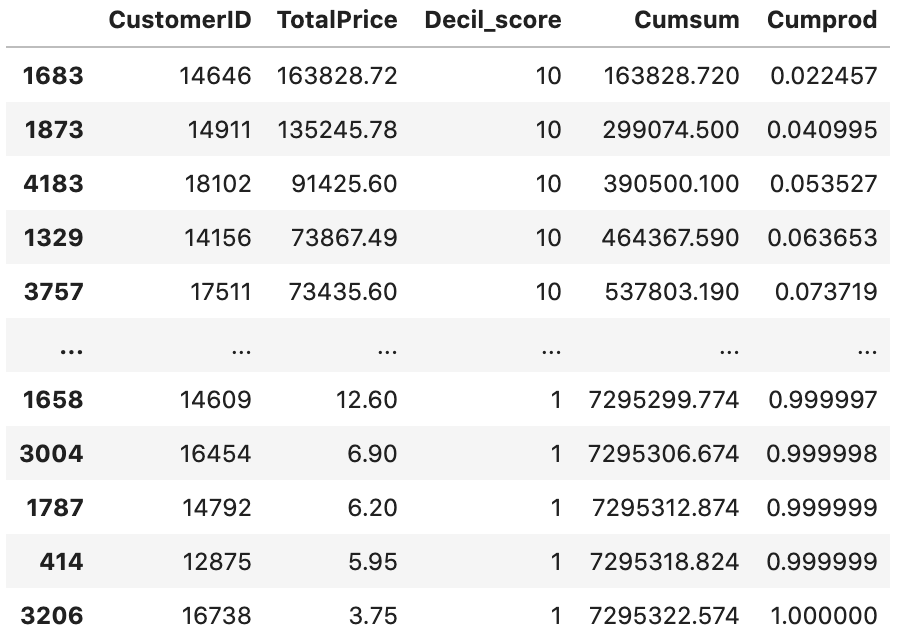
# 各階層の売り上げが占める割合
decil[['Decil_score', 'Cumprod']].groupby('Decil_score').max() \
.reset_index().sort_values('Decil_score', ascending=False)

結果を見てみると、購入総額の上位10%の顧客で全体売り上げの約55%, 上位20%で約70%, 上位30%で約80%を占めていることがわかります。
RFM分析の実装
RFM分析では、InvoiceDate, TotalPrice(デシル分析で作成したカラム), CustomerIDを使用します。
RFM値の算出
Recencyを計算するためには、現在時刻(分析時の時刻)を指定する必要があります。購買データの最終時刻が'2011-12-09 12:50:00'であるため、今回は現在時刻(NOW)を2011年12月10日(0:00)としておきます。
# 履歴の最新時刻を取得
data['InvoiceDate'].max()
>>>
Timestamp('2011-12-09 12:50:00')
# 現時刻を設定
import datetime as dt
NOW = dt.datetime(2011,12,10)
CustomerIDでGroupByし、agg関数を使ってRecency, Frequency, Monetaryを以下のように求めます。
# RFMの計算
rfm = data.groupby("CustomerID") \
.agg({"InvoiceDate": lambda date: (NOW - date.max()).days,
"InvoiceNo": lambda num: num.nunique(),
"TotalPrice": lambda price: price.sum()}).reset_index()
# カラム名変更
rfm.rename(columns={'InvoiceDate': 'recency',
'InvoiceNo': 'frequency',
'TotalPrice': 'monetary'}, inplace=True)
rfm.head()

セグメント分け
ここから、実際に算出した各指標を用いてセグメント分けしていきます。どのように分けるか(基準値や分割数)は状況により変える必要があります、今回は各指標について四分位点を用いて分割することにします。
四分位点でRFMスコアを求める
# 3指標それぞれの四分位点を求める
quantiles = rfm.quantile(q=[0.25,0.5,0.75])
quantiles_dict = quantiles.to_dict()
print(quantiles_dict)
>>>
{'recency': {0.25: 17.0, 0.5: 50.0, 0.75: 142.0},
'frequency': {0.25: 1.0, 0.5: 2.0, 0.75: 5.0},
'monetary': {0.25: 300.67499999999995, 0.5: 656.6899999999999, 0.75: 1601.0}}
# RFMを四分位点で分ける関数を定義
def cal_R(x, col, df):
if x <= df[col][0.25]:
return 1
elif x <= df[col][0.50]:
return 2
elif x <= df[col][0.75]:
return 3
else:
return 4
def cal_FM(x, col, df):
if x <= df[col][0.25]:
return 4
elif x <= df[col][0.50]:
return 3
elif x <= df[col][0.75]:
return 2
else:
return 1
# 各種スコアの算出
rfm['R_score'] = rfm.recency.apply(cal_R, args=('recency', quantiles_dict))
rfm['F_score'] = rfm.frequency.apply(cal_FM, args=('frequency', quantiles_dict))
rfm['M_score'] = rfm.monetary.apply(cal_FM, args=('monetary', quantiles_dict))
# 3指標を統合したスコアの算出
rfm["RFM_score"] = rfm.R_score.astype(str)+ rfm.F_score.astype(str) + rfm.M_score.astype(str)
rfm.reset_index(inplace=True)
rfm.head()
求めたスコアを使って、例えば「スコア4が2項目以上あれば優良顧客」などのようにセグメント分けをしていきます。
クラスタリング(k-means)
セグメント分けには、教師なしの機械学習手法(クラスタリング)を用いることもあるようです。試しにk-means方を使ってのセグメント分けを実装してみます。
# 標準化
from sklearn.preprocessing import StandardScaler
tmp = rfm[['R_score', 'F_score', 'M_score']]
ss = StandardScaler()
rfm_scaled = ss.fit_transform(tmp)
print(rfm_scaled)
>>>
array([[ 1.34301118, 1.15405079, 1.34141302],
[-1.33165772, -1.47067031, -1.34162009],
[ 0.45145488, -0.59576328, -0.44727572],
...,
[-1.33165772, 0.27914376, 1.34141302],
[-1.33165772, -1.47067031, -1.34162009],
[-0.44010142, -0.59576328, -1.34162009]])
分割するクラスター数は分析者が指定する必要がありますが、最適なクラスター数を考える一つの手法として、分割数を変えた時のitertia値(クラスタ内二乗誤差の和)の変化をみる方法があります。詳しくはこちらの記事がわかりやすいので是非。
# クラスタリング(分割数の検討)
from sklearn.cluster import KMeans
inertias = {}
for k in range(2, 10):
km = KMeans(n_clusters=k, random_state=1)
km.fit(rfm_scaled)
inertias[k] = km.inertia_
pd.Series(inertias).plot()
plt.xlabel("K (num of clusters)")
plt.ylabel("Inertia Score")
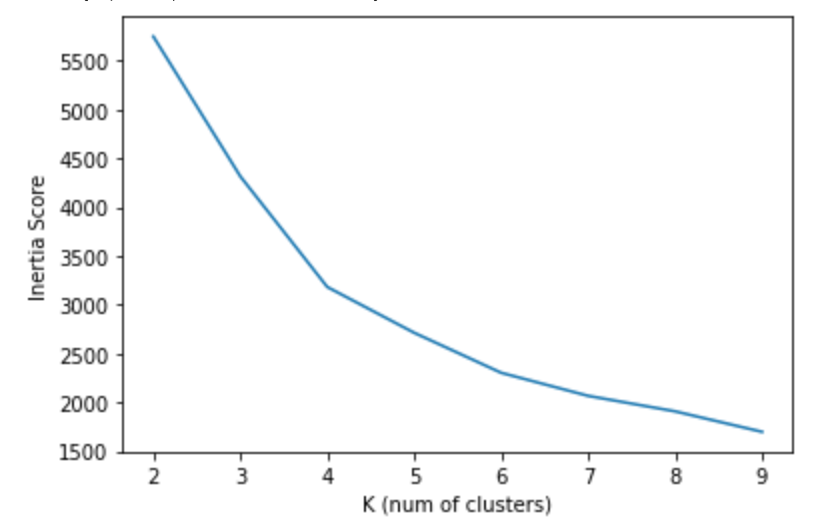
やや判断が難しいですが、今回は4つのクラスターに分割することにします。
# k=4でクラスタリング
k = 4
km = KMeans(n_clusters=k, random_state = 1)
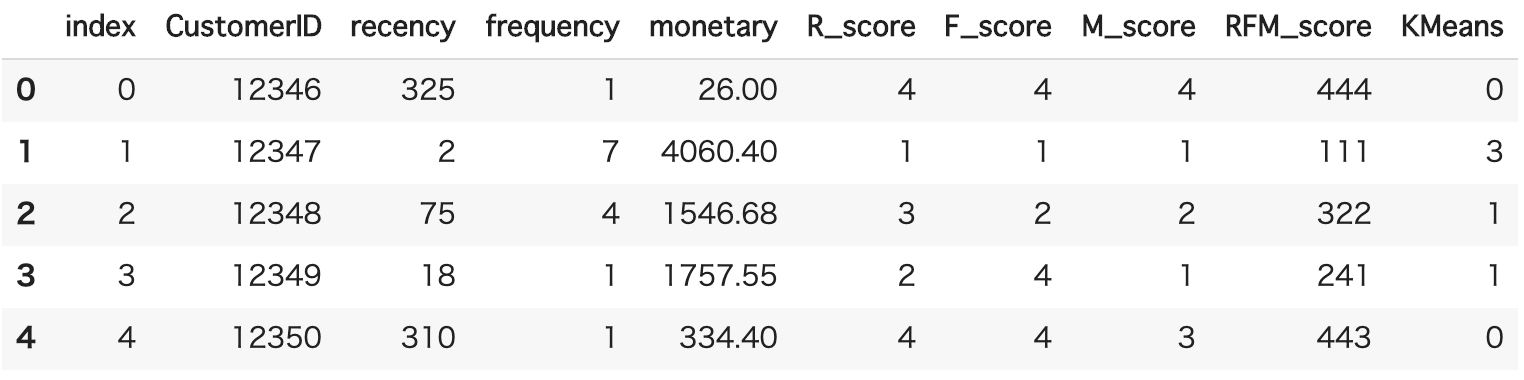
rfm["KMeans"] = km.fit_predict(rfm_scaled)
rfm.head()
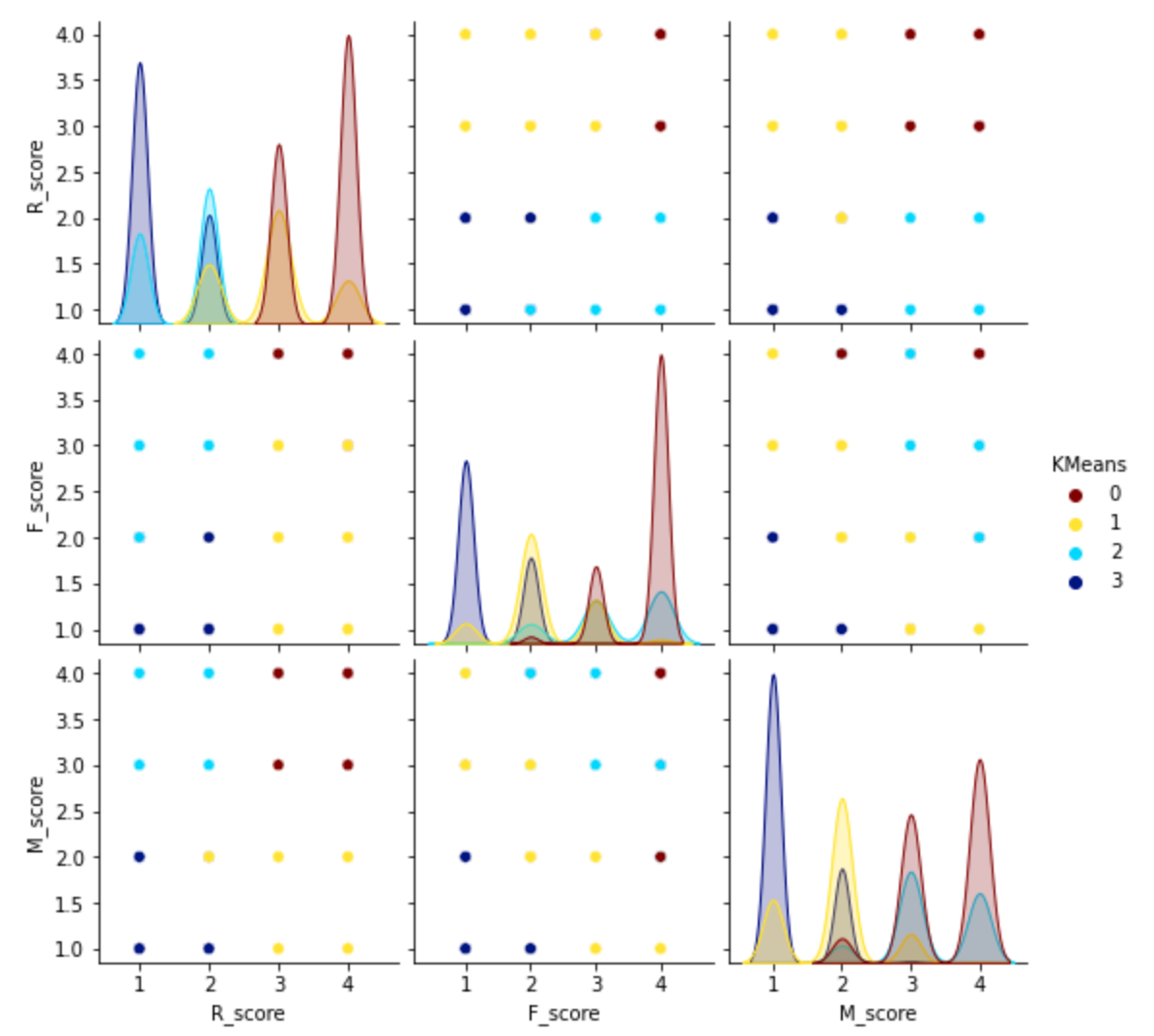
# 可視化
sns.pairplot(rfm[['R_score', 'F_score', 'M_score', 'KMeans']], hue="KMeans", palette='jet_r')
plt.show()
# 各クラスターの要素数の確認
rfm['KMeans'].value_counts()
>>>
0 1428
3 1112
1 997
2 782
Name: KMeans, dtype: int64
おわりに
デシル分析とRFM分析をPythonで実装してみました。Pandasの良い練習にもなりますし、やはり意味のあるデータ分析の方がモチベーションも維持しやすいと感じました。次は、商品分析に挑戦してみようと思います。
※参考
https://library.musubu.in/articles/10537#
https://www.albert2005.co.jp/knowledge/marketing/customer_product_analysis/decyl_rfm
https://qiita.com/deaikei/items/11a10fde5bb47a2cf2c2