この記事の概要と結果
最近知ったVARISTAというAutoML?を使ってKaggleタイタニックコンペにチャレンジしてみます。
スコアは0.80861でした。
Kaggleへ登録
Kaggleに登録していない人はKaggleに登録をしましょう。
登録は画面の右上から行ってください。
データの用意
今回のコンペティションはこちらの「Titanic: Machine Learning from Disaster」です。
コンペティションに移動したら「Data」タブを選択してください。
こちらをクリックしてもデータページに移動できます。
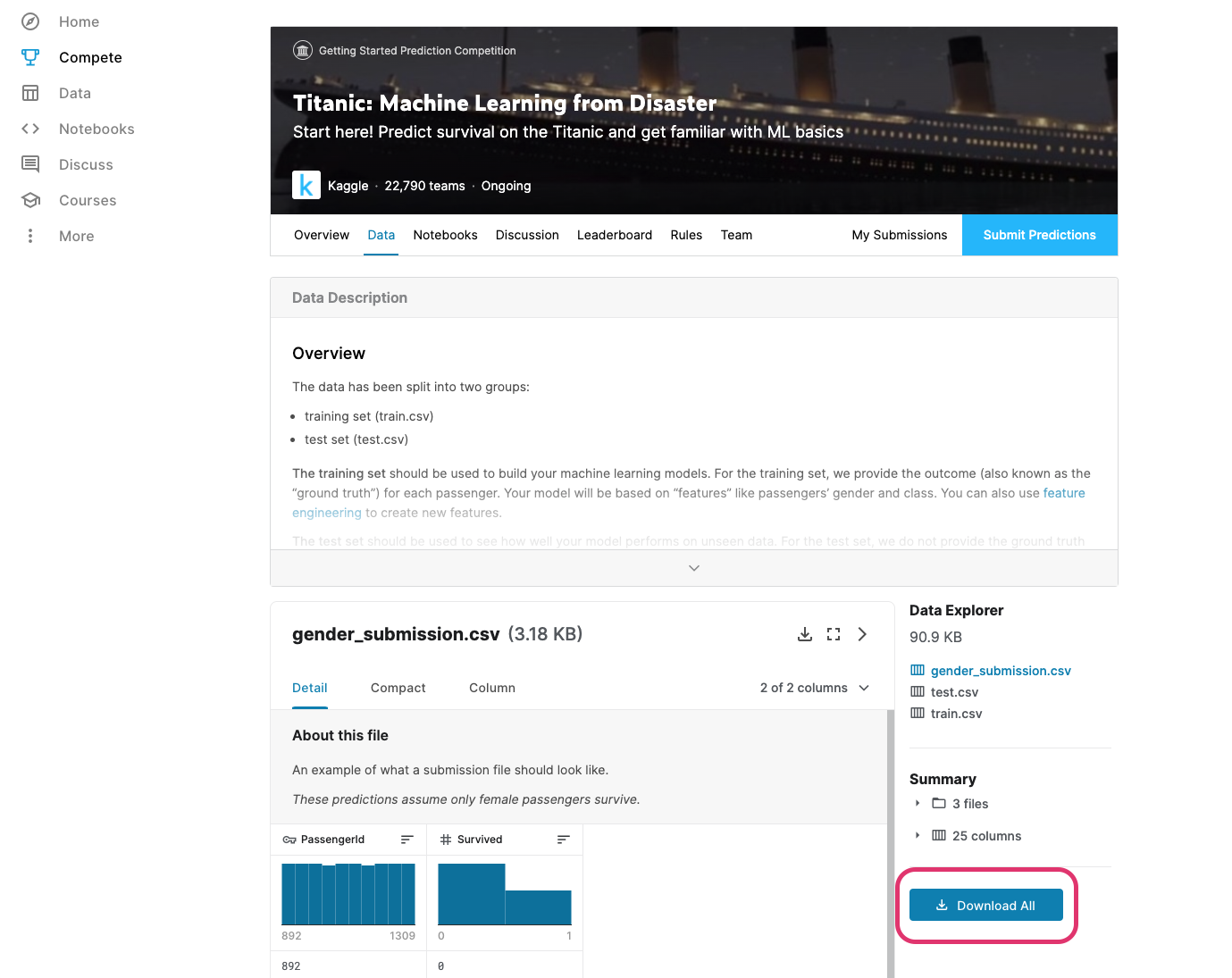
データ画面に移動したらDownload Allを選択します。
ダウンロードが完了したら、「titanic.zip」があると思いますので、このファイルを解凍してください。
解凍すると以下のファイルが確認できます。
それぞれのファイルの用途は以下の通りです。
| ファイル名 | 用途 |
|---|---|
| train.csv | 教師データ |
| test.csv | テストデータ |
| gender_submission.csv | 投稿用サンプルデータ |
データの変数説明
| 列名 | 日本語 |
|---|---|
| PassengerID | 乗客ID |
| Survived | 生存結果 (1: 生存, 0: 死亡) |
| Pclass | 客室の階級 1=Upper, 2=Middle, 3=Lower |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 兄弟、配偶者の数 |
| Parch | 両親、子供の数 |
| Ticket | チケット番号 |
| Fare | 乗船料金 |
| Cabin | 部屋番号 |
| Embarked | 乗船した港 Cherbourg、Queenstown、Southamptonの3種類 |
VARISTAへ登録
VARISTAのアカウントを作成します。
http://www.varista.aiに移動してトップページから登録します。
ちなみに、、このアカウントから登録するとサービス内で使えるクレジットになるのでもしよければこのリンクから飛んで頂けると嬉しいです。。
もし嫌な方は全然↑から飛んでもらっても構いません。。知らなかった・・。
https://console.varista.ai/welcome/jamaica-draft-coach-cup-blend
有料プランもあるみたいですが、とりあえずは無料で試しました。
プロジェクト作成とデータの確認
VARISTAにログイン後に、ワークスペースを任意の名前で作成します。
ワークスペースを作成したら、プロジェクトを作成します。
名前は適当にタイタニックとかでいいと思います。
ガイドに従って、データをアップロードします。
アップロードするデータは教師データの「train.csv」です。
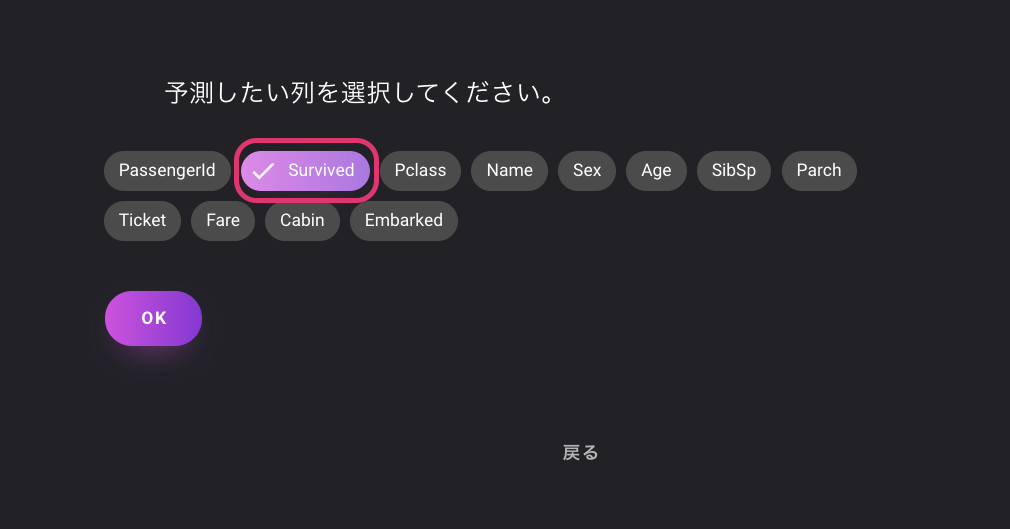
アップロードが完了したら、予測したい列を選択します。
今回のコンペにおいては、乗客の生存を予測したいので「Survived」を選択します。
設定が完了したSTARTを選択して次の画面に移動します。

ターゲットを選択したら準備完了です。
データの確認
ここでいきなり学習を開始してもいいのですが、せっかくなのでデータの中身をみてみます。
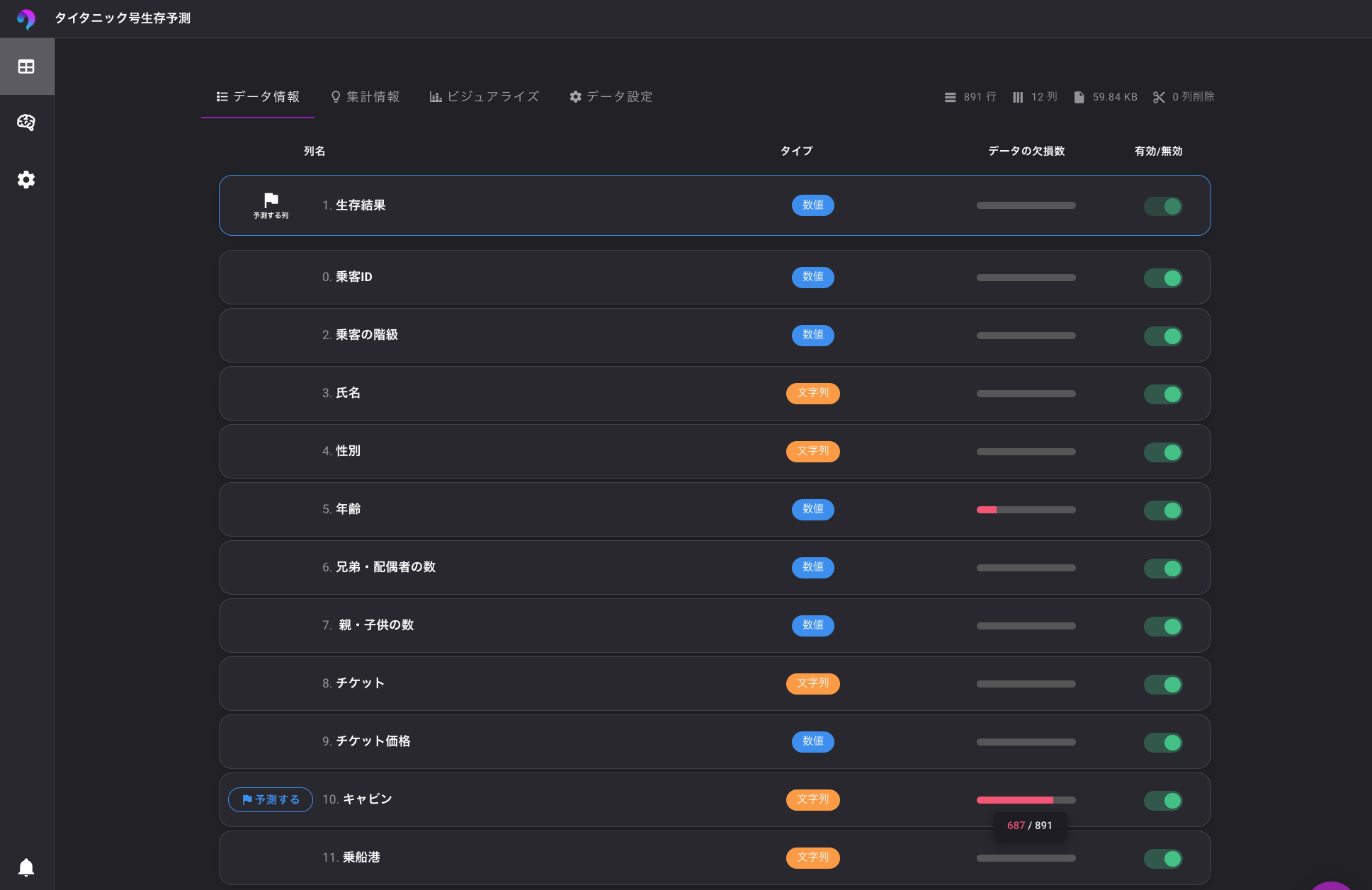
データメニューを選択し、先ほどアップロードした「train.csv」を選択します。

データの欠損を見てみると、年齢とキャビンのデータに欠損があることが確認できます。
ただ、VARISTAの場合は欠損データを自動で補完するようです。
データの分布を見てみましょう。
タブから「ビジュアライズ」を選択すると、特徴列のデータごとに分布を表示してくれるので便利です。
相関関係のタブを選択すると、予測したい列とそれぞれの列の相関関係を確認することができます。
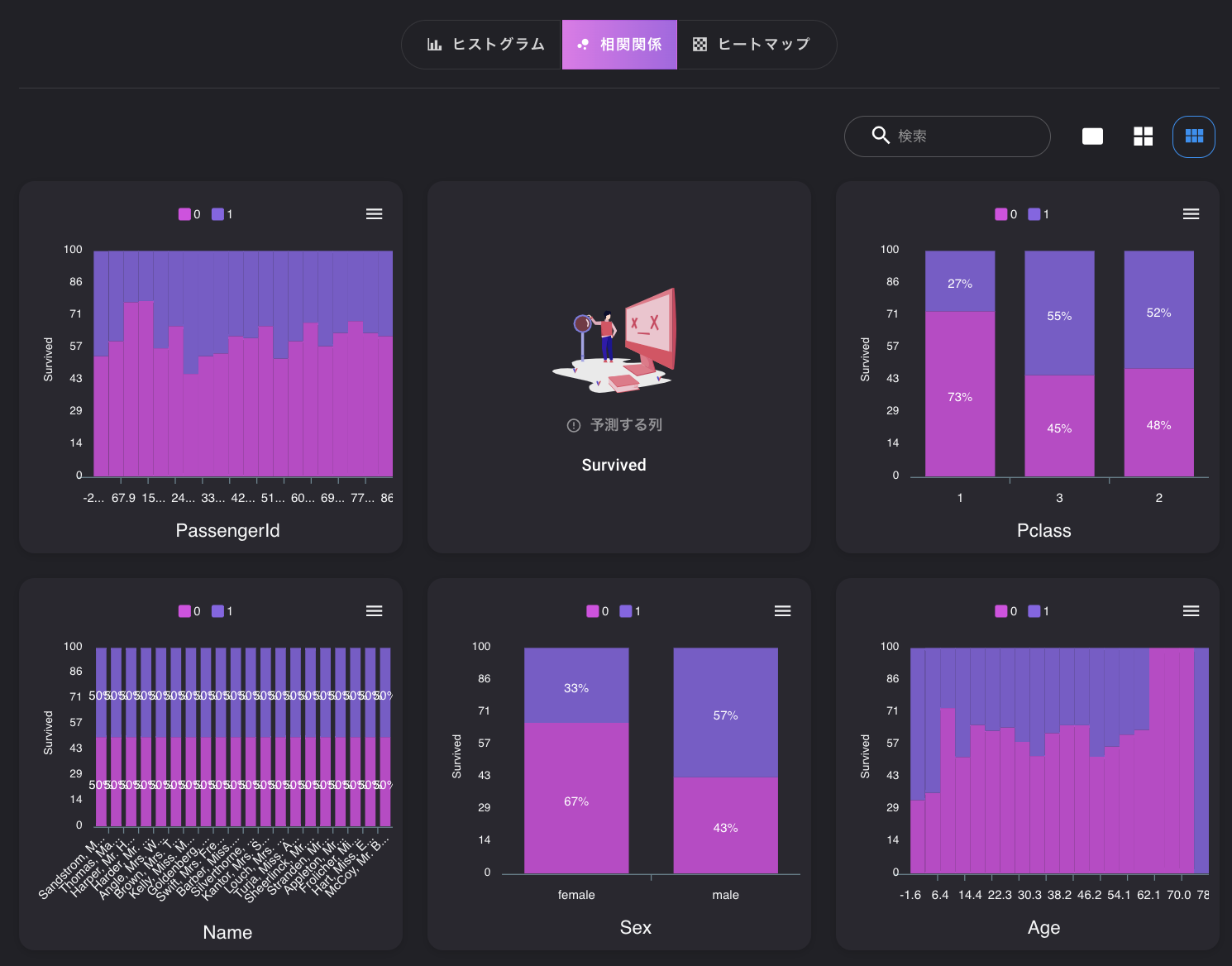
性別、年齢
0は死亡、1は生存と置き換えてみてください。
性別は大きく関係しており、女性の方が生存しているようです。
年齢は、概ね7才未満の生存率が高く、60才以降は死亡率が高いようです。中間は大きな差は無いようです。
子供は優先的に救助されたみたいです
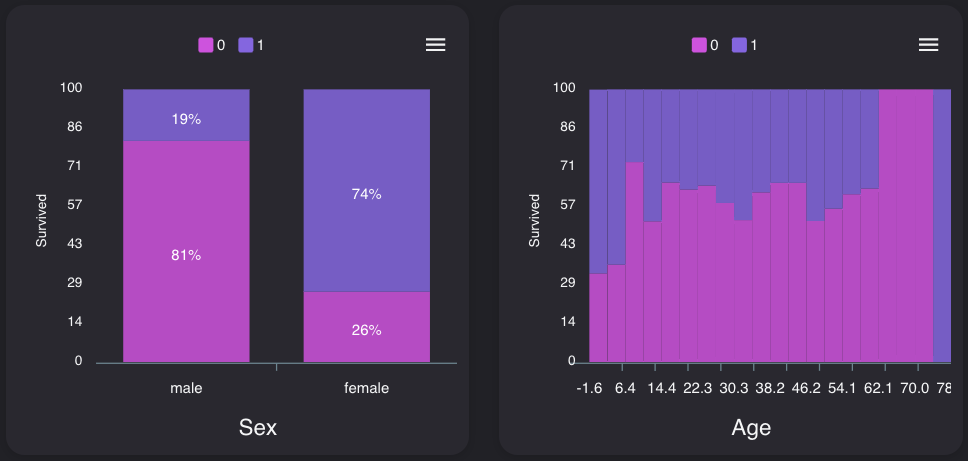
PClass
等級が高い方が、生存率が高いようです。
学習
実際に学習してみましょう。
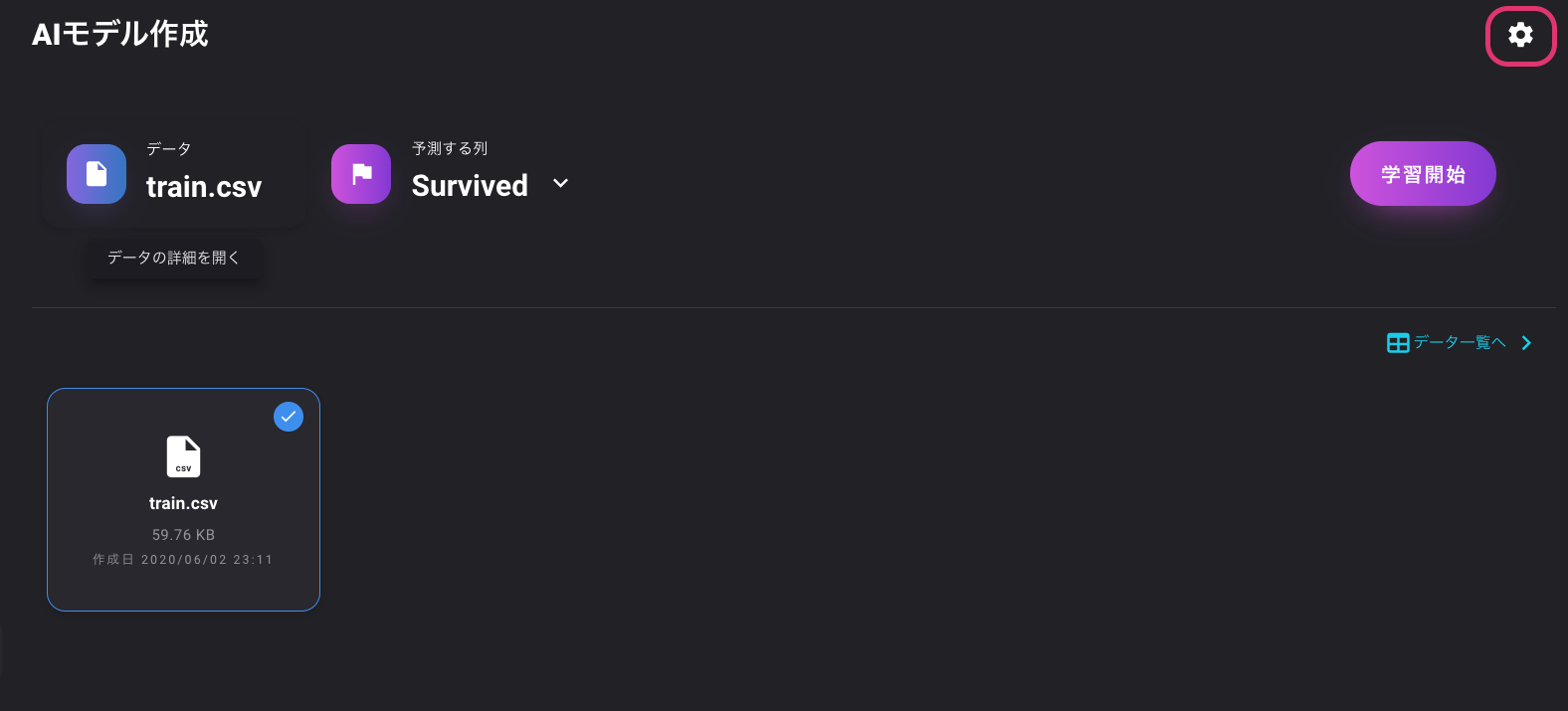
左のAIモデルを選択し、「AIモデルを作成」をクリックします。
次に、予測する列が「Survived」になっていることを確認し、学習開始ボタンをクリックします。
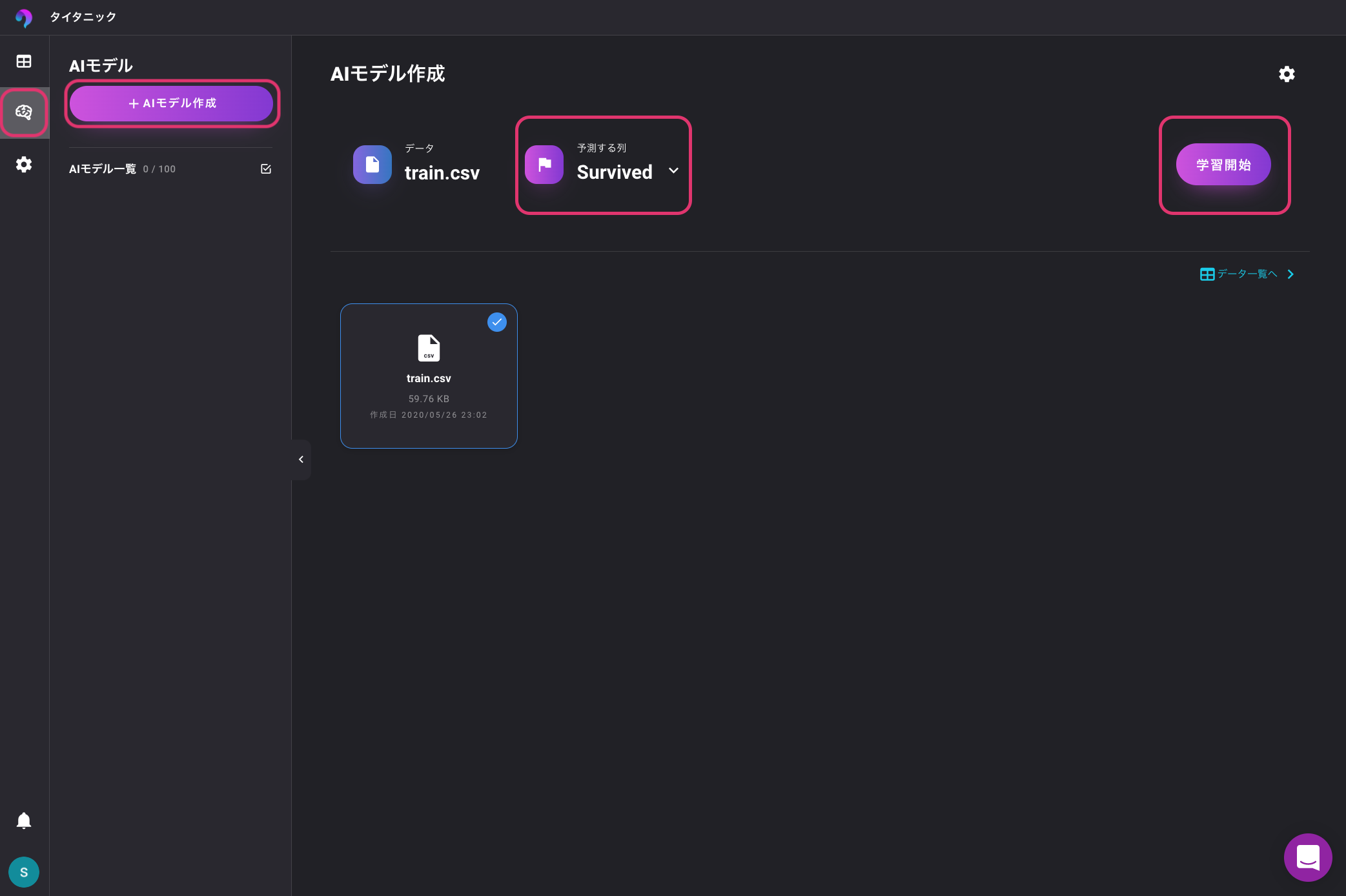
最近流行りの特にこちら側で何の設定をすることもなく自動で学習が開始します。
特徴量エンジニアリングを行い複数アルゴリズムで学習しているようです。
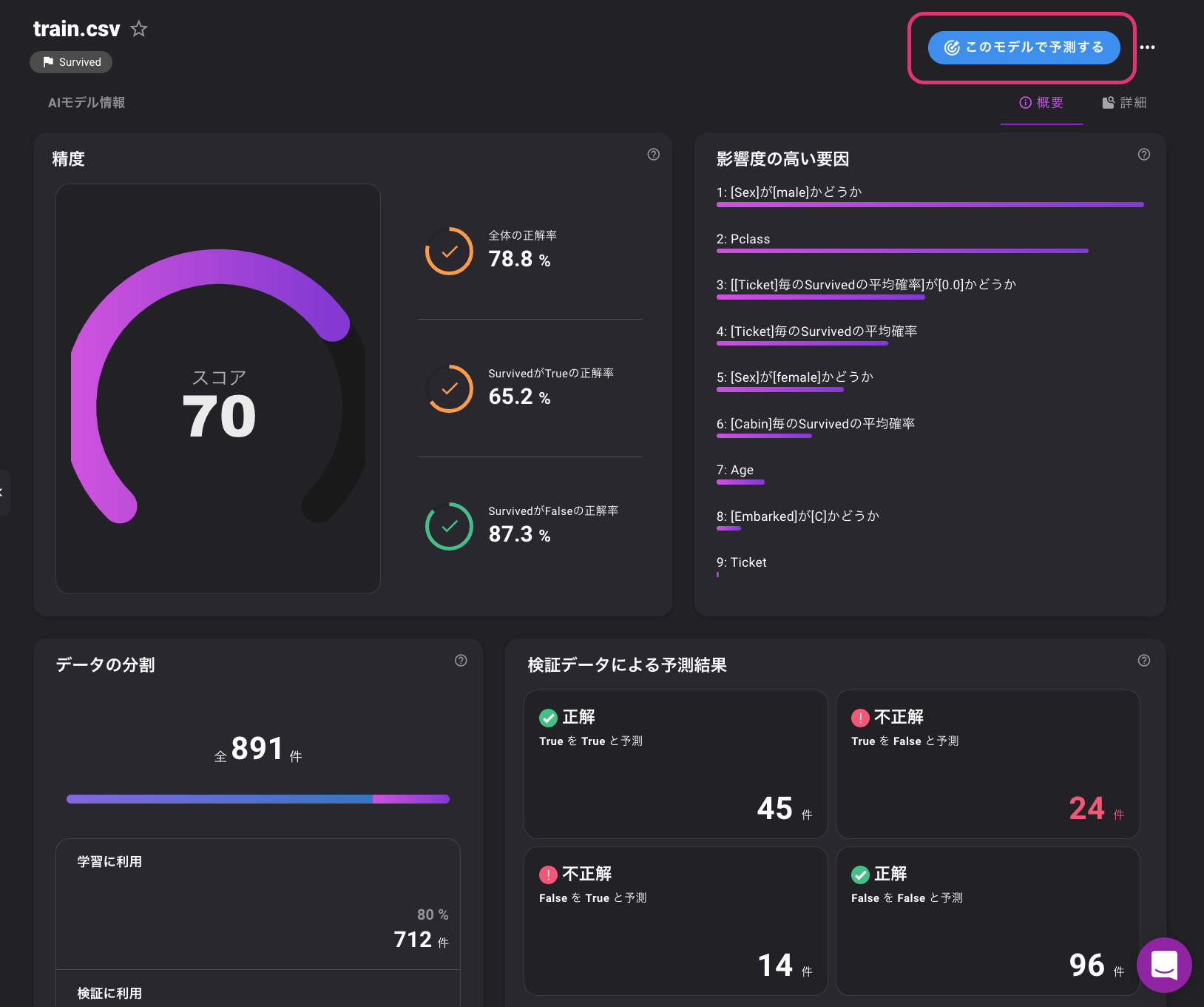
学習結果
スコア70と出ています。
影響度をみると、やはり生存には、性別とPclassが関わっているようですね。
Kaggleへの提出
↑の画面でこのモデルで予測するをクリックします。
ここをクリックして、出力形式を変更します。

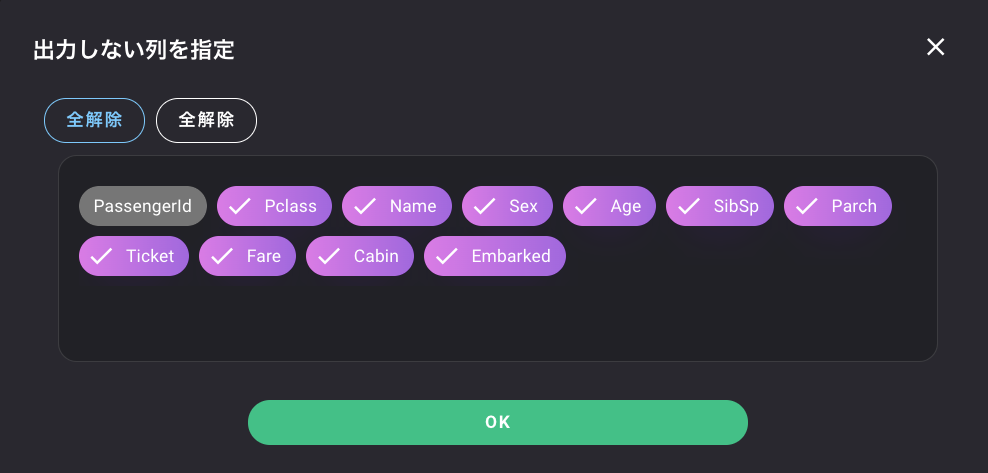
出力しない列を設定します。
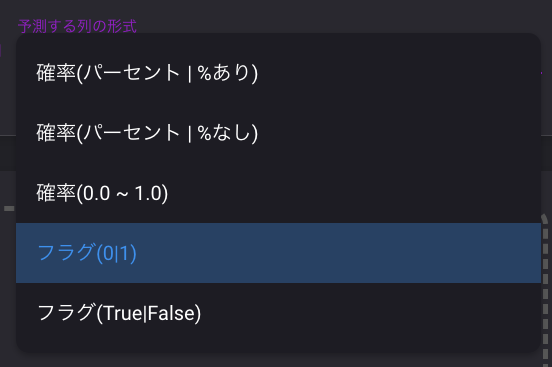
次に、出力する列の形式をフラグに変更します。
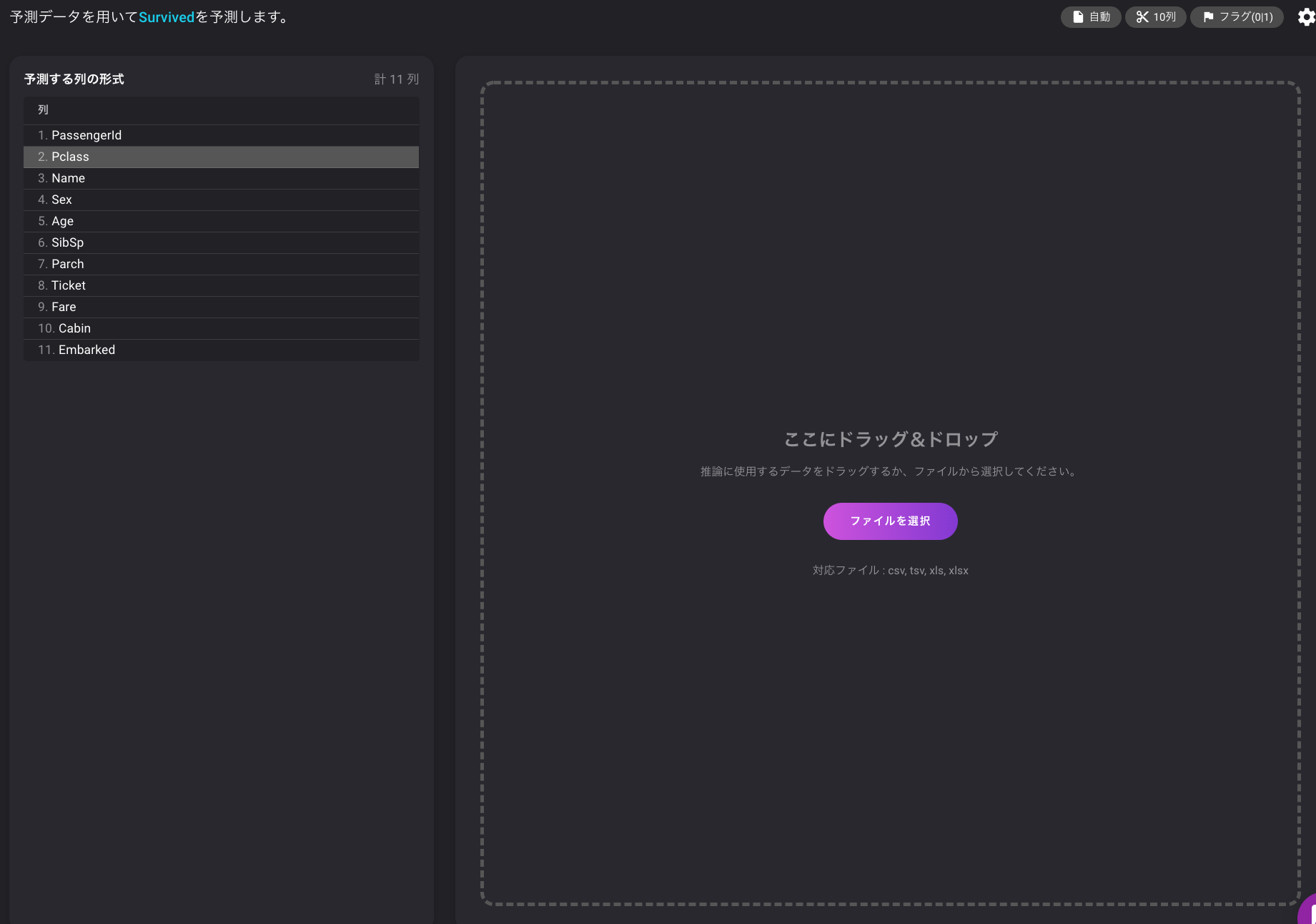
最後に、先ほどのダウンロードしたファイルにあるtest.csvをドラッグ&ドロップしましょう。
出来上がったファイルをダウンロードします。

ファイルを開くと、一番右列に生存したかどうかの予測が入っている事がわかります。
Kaggleに投稿するには不要な列があるので削除します。今回はMacのNumbersで除去しましたが、Windowsの場合はExcelなどがいいと思います。

Kaggleのコンペティション画面から「Submit Predictions」を選択して、先ほどダウンロードしたファイルをドラッグ&ドロップします。
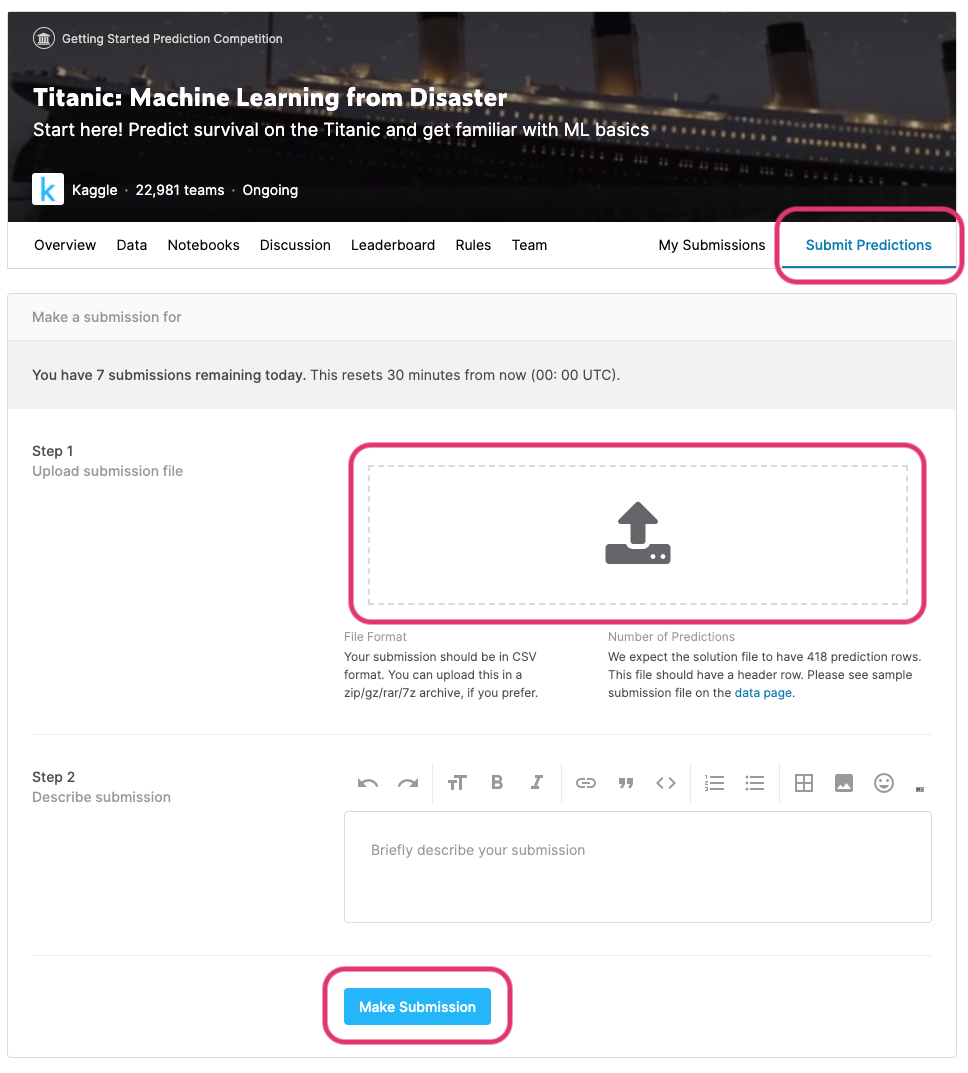
最後にMake Submissionを押して、投稿します。
しばらくすると、採点されスコアが出力されます。
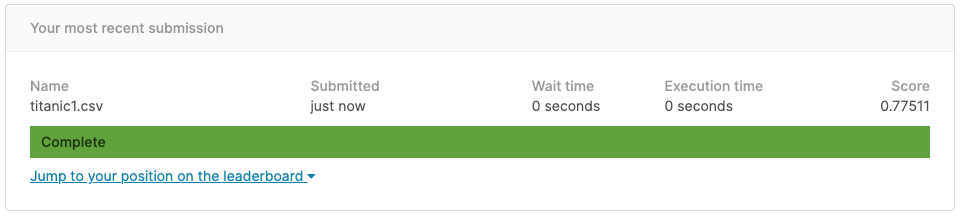
今回のスコアは0.77511でした。
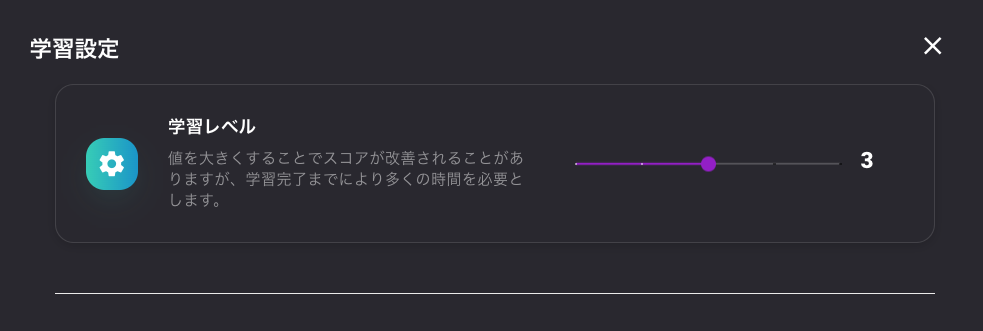
学習設定を変更してモデルの調整
学習設定から、学習レベル、検証データの割合、交差検証の分割数、ランダムシードの値を変更してみたら、スコアがよくなったので載せておきます。
モデルの学習開始画面右上の設定ボタンをクリックします。
値をこんな感じにしてみました。
あまり試していないのでもっといい設定の値があるのかもしれませんが、追って試してみます。
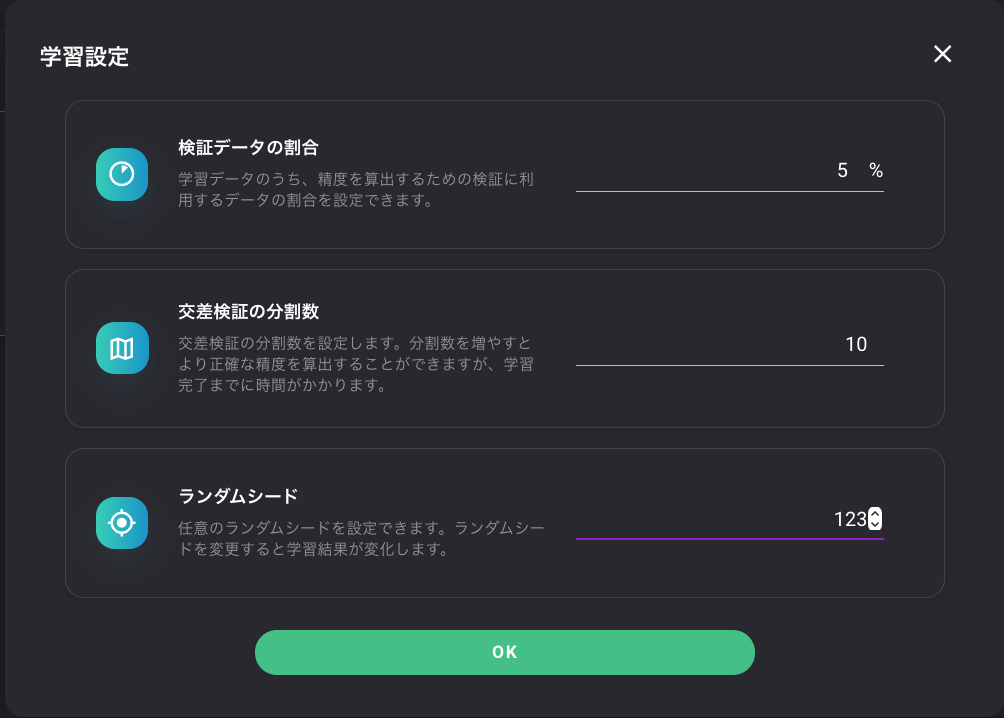
これで再度学習して再度KaggleにSubmitしてみます。
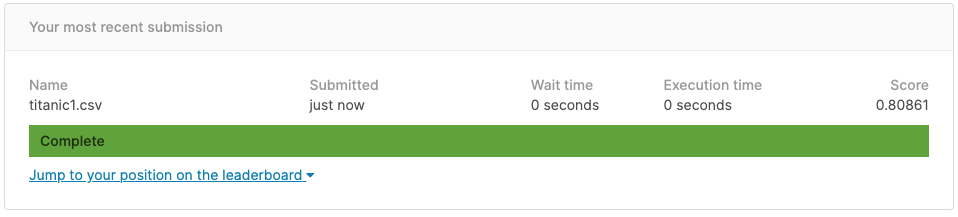
スコアは0.80861まで上がりました。
レベル3の学習に30分くらいかかるので、また色々と試して追加で書きたいと思います。