はじめに
今回は S3 へのデータアップロードをトリガーに、アップロードされたデータを推論し、結果を S3 に保存する関数を作成しました。
その内容を記載します。
前提
- SageMakerでデプロイできるモデルがある。
※今回作成した Lambda 関数を使う際には、事前にモデルをデプロイしておく必要があります。
※私は画像検出のモデルを使用します。
関数の作成/設定
- まず、AWS のコンソールから Lambda と検索し、 Lambda を選択します。

- 左の一覧から関数を選択し、右上の関数の作成を選択します。

- 一から作成にチェックをつけ下へスクロール。

- 関数名に任意の名前を入力し、ランタイムは Python3.7 を選択してください。

- 実行ロールは基本的な Lambda アクセス権限で新しいロールを作成を選択し、関数の作成を選択します。

- 作成が完了すると、次のような画面が表示されます。

- 少し下にスクロールし左のトリガーの追加から S3 を選択してください。

- 選択したら、更に下にスクロールし各種設定を行います。
- バケット名 : データをアップロードするバケットを選択します。
- イベントタイプ : PUT を選択します。
- プレフィックス : データのアップロードを検知するフォルダを指定します。
- サフィックス : 検知するデータの末尾の形式を指定します。
私は画像検出のモデルを使用するので、.jpgと入力しています。 - トリガーの有効化 : チェックを付けておきます。

- 下にスクロールして、右下の追加を選択します。

- 追加したら、右上の保存ボタンを選択して、設定を保存します。

- 保存したら、少し上にスクロールして、赤枠で囲まれた部分を選択し、下にスクロール。

- すると、以下のような画面がでてきます。
赤枠内に、実際のプログラムを記述します。

- 今回私が作成したプログラムは以下の通りです。
import json
import boto3
def lambda_handler(event, context):
s3 = boto3.client("s3")
sagemaker = boto3.client("sagemaker-runtime", region_name="ap-northeast-1")
#S3にアップロードされた画像データ情報を取得
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
input_data = s3.get_object(Bucket=bucket, Key=key)
#画像データをバイナリデータに変換
body = input_data['Body'].read()
b = bytearray(body)
#推論
endpoint_response = sagemaker.invoke_endpoint(
#エンドポイント名を設定
EndpointName='auto-endpoint',
Body=b,
ContentType='image/jpeg'
)
results = endpoint_response['Body'].read()
print(endpoint_response)
print(results)
split_s3_path = key.split('/')
for i in split_s3_path:
if 'jpg' in i:
full_file_name = i
file_name = i.split('.')[0]
#output_keyに推論結果の保存パスを設定
output_key = 'dog-face/lambda/推論結果/'+file_name+'.json'
#S3に推論結果をjsonファイルで保存
s3.put_object(Body=results,Bucket=bucket,Key=output_key)
#copy_keyに推論後画像を格納するパスを設定
copy_key = 'dog-face/lambda/推論済み画像/'+full_file_name
#S3のアップロードされたデータを別フォルダにコピーして元データは削除
s3.copy_object(Bucket=bucket,Key=copy_key,CopySource={'Bucket': bucket, 'Key': key})
s3.delete_object(Bucket=bucket,Key=key)
プログラムは下記の流れになっています。
- S3にアップロードされたデータを推論。
- 推論結果を保存。
- アップロードされたデータを、別フォルダにコピーし、アップロードされたデータを削除。
- プログラムを書き終えたら、もう一度右上の保存を選択します。

実行ロール の設定
さきほど何もいじらずに作成した、実行ロールに、S3とSageMakerのフルアクセスをアタッチします。
※今回はテストのため、フルアクセスをアタッチしますが、本番で利用する際は適切なIAMロールを作成してください。
- IAMを開き、左の欄からロールを選択し、検索欄にLambda関数を作成した時に付けた名前を入力してください。

- 入力し、出てきたロールを選択します。

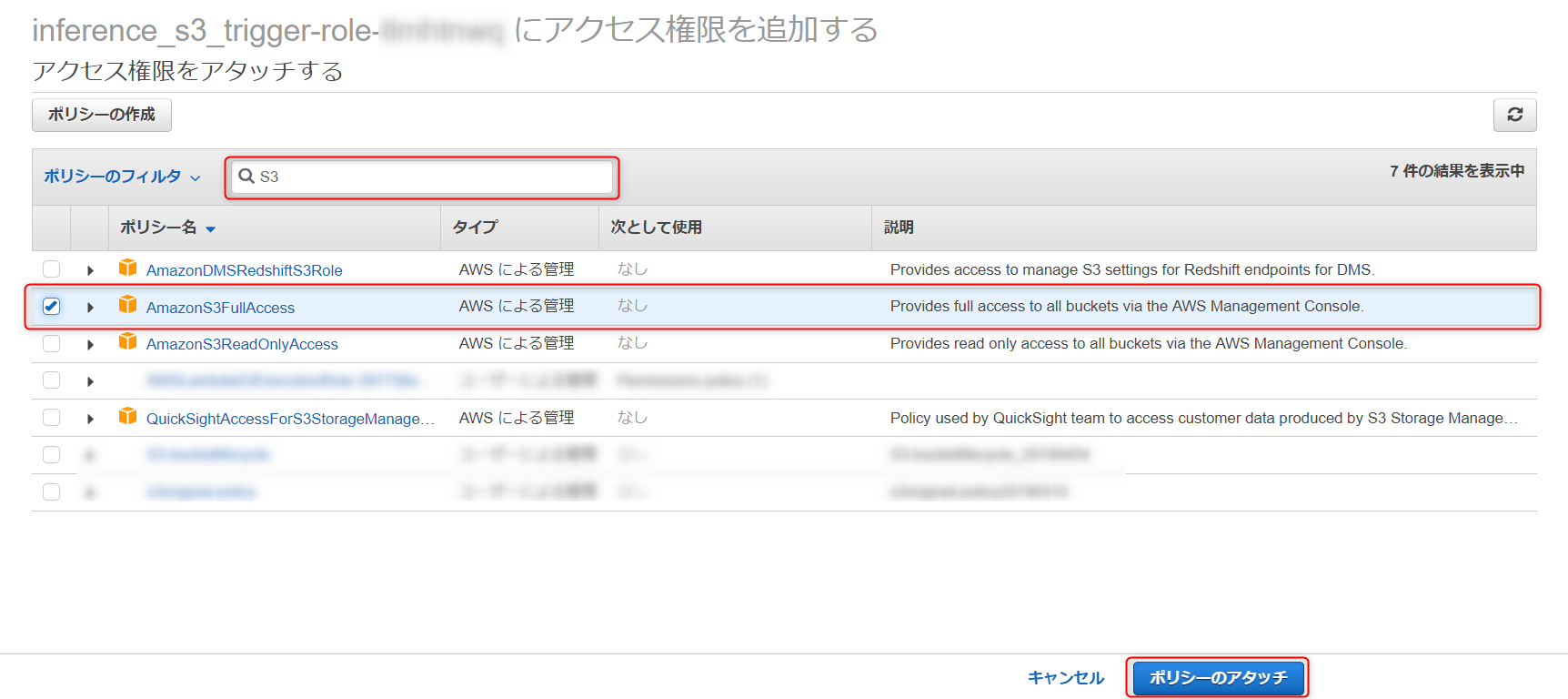
- ポリシーのアタッチを選択します。

- 検索バーに S3 と入力し、S3 のフルアクセスにチェックを付けて、ポリシーのアタッチを選択します。
- 同様に、検索バーに SageMaker と入力し、SageMaker のフルアクセスにチェックを付けて、ポリシーのアタッチを選択します。

- すると、2つのポリシーがアタッチされたことが確認できます。

実際にS3にデータをアップロードし、Lambda 関数を起動してみる。
この手順に入る前に使用するモデルをデプロイしてください。
- Lambda関数作成時に設定した画像アップロードフォルダに画像をアップロードします。

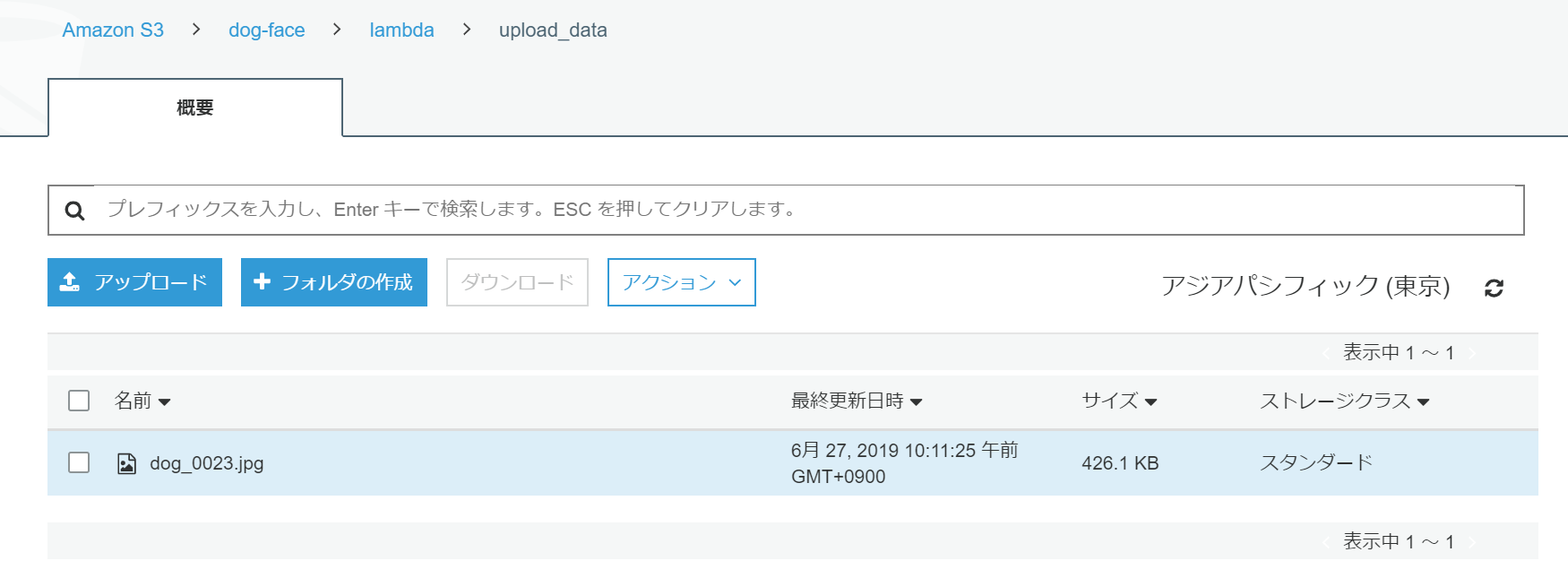
- アップロードしたら、作成したLambda関数を開いて、モニタリングタブを選択し、CloudWatch のログ表示を選択します。

- するとこのような形で、Lambda 関数の起動ごとにログが記録されています。
ログを開くと Lambda 関数が正常に動作しているか確認できます。

- 正常に動作している場合、S3に、推論結果が保存され、アップロードしたデータは別フォルダに格納され、削除されます。



- ちなみに推論結果を可視化した画像はこちらになります。

最後に
今回は、S3へのデータアップロードをトリガーに、推論を行いました。
トリガーを変更することで、他にもいろいろな処理ができますので、ぜひ試してみてください。