企業のデータは、基幹系 DB、分析用 DWH、データレイクなど、複数のシステムに分散しています。「顧客マスタは Db2 に、売上データは Snowflake に、商品カタログはオブジェクトストレージにある」といった状況は、決して珍しくありません。
これらを横断的に分析しようとすると、従来は ETL でデータを物理的に一箇所に集める必要がありました。しかし、ETL にはデータ移動コストや鮮度の低下、パイプライン運用の負荷といった課題が伴います。
本記事では、watsonx.data のフェデレーション機能を活用して、Db2・Snowflake・オブジェクトストレージ上のデータを移動せずに統合し、MCP を介して IBM Bob から自然言語で横断的にアクセス・分析してみました。
フェデレーションとは
複数のデータソースに存在するデータを物理的に移動させることなく、1 つのデータベースのように統合してアクセスできる仕組みです。データは元の場所に置いたまま、クエリ実行時に各データソースへリアルタイムにアクセスします。
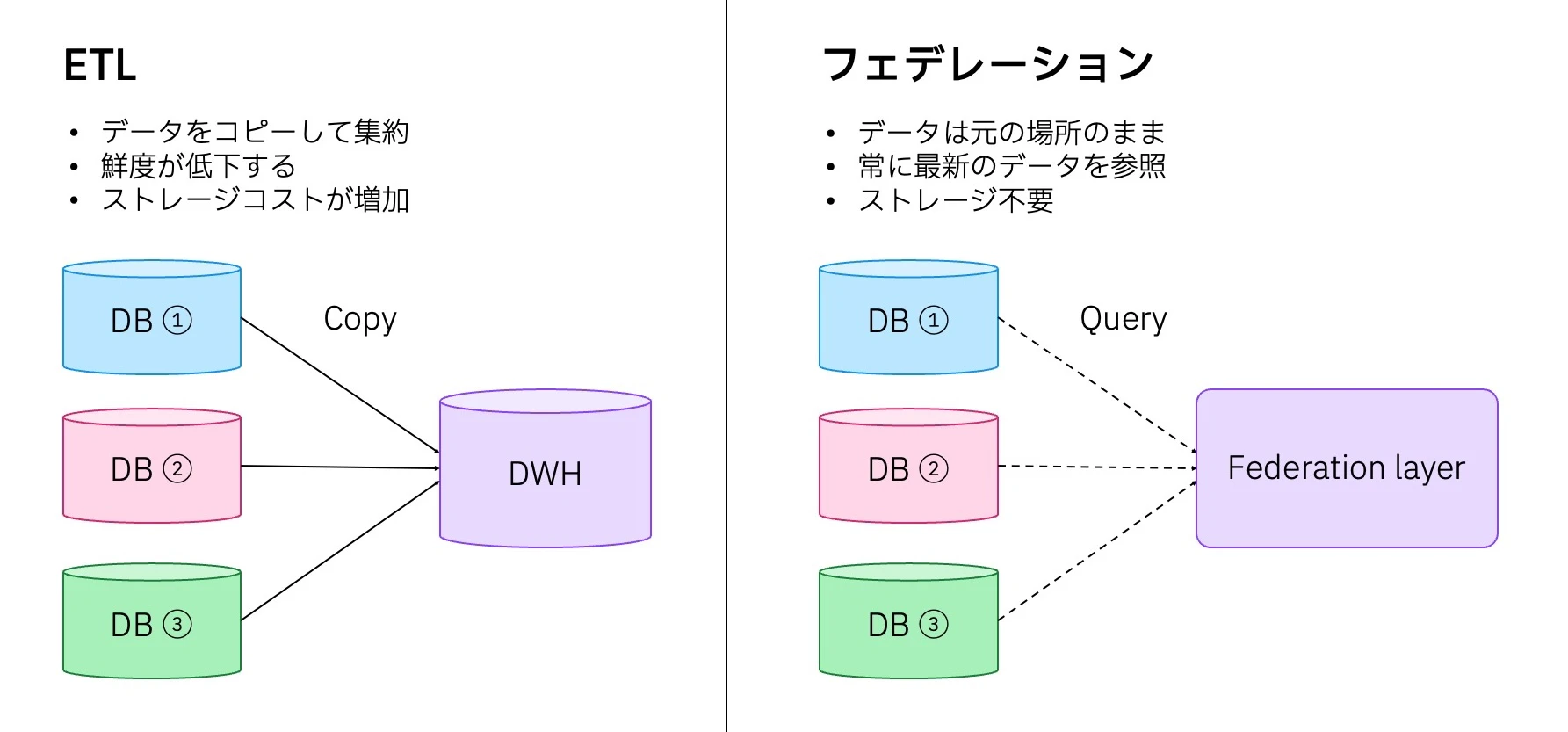
watsonx.data はこのフェデレーション機能を備えており、Db2・Snowflake・オブジェクトストレージなどの異種データソースに対して、1 つの SQL で横断的にクエリを実行できます。
全体アーキテクチャ
今回の環境の全体像は、以下の通りです。
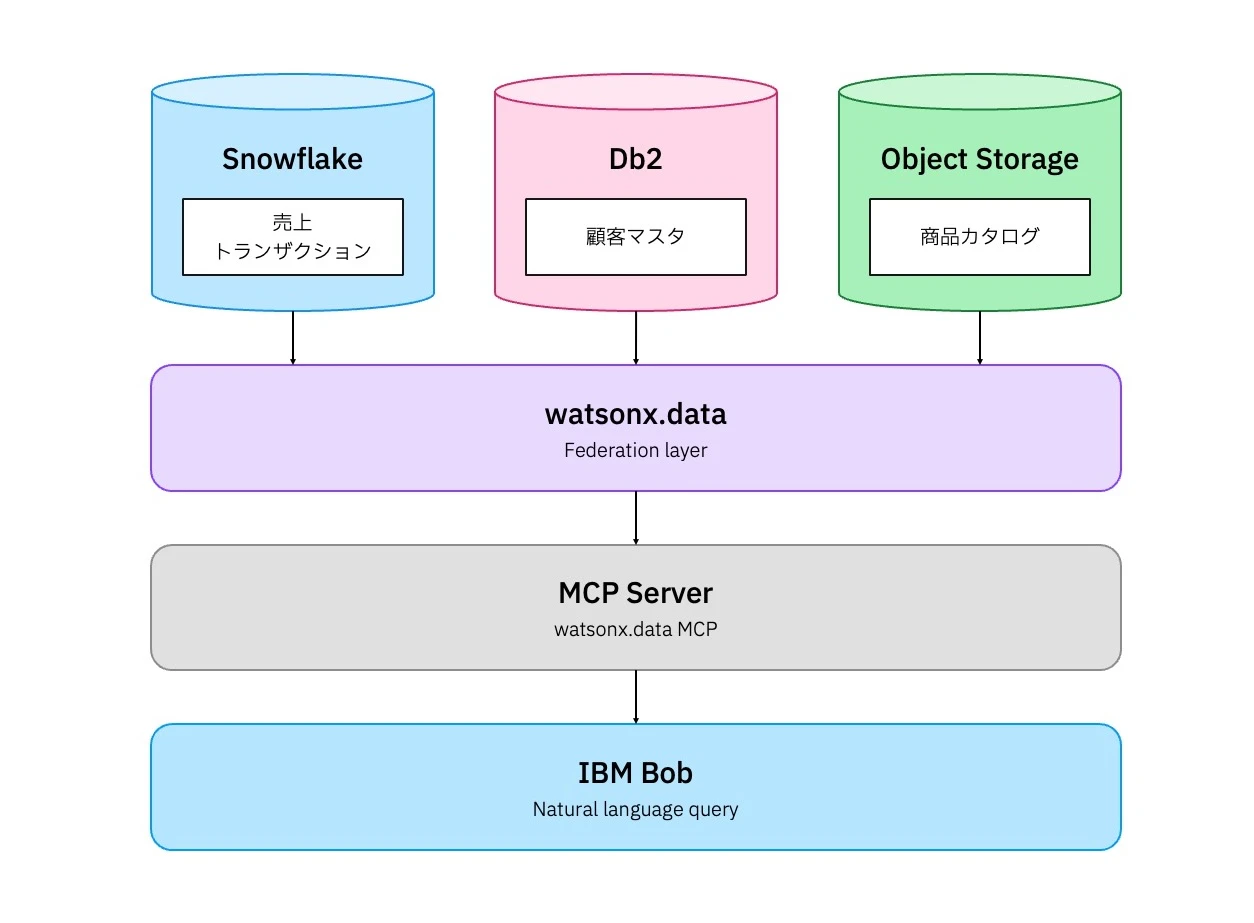
| コンポーネント | 説明 |
|---|---|
| Db2 | 基幹系 DB 顧客マスタを格納 |
| Snowflake | 分析系 DWH 売上トランザクションを格納 |
| Object Storage | データレイク 商品カタログを格納 |
| watsonx.data | 上記 3 つのデータソースをフェデレーションで仮想的に統合 |
| MCP Server | watsonx.data へのアクセスを AI に提供 |
| IBM Bob | 自然言語でデータにアクセスする AI コーディングアシスタント |
データソースの接続
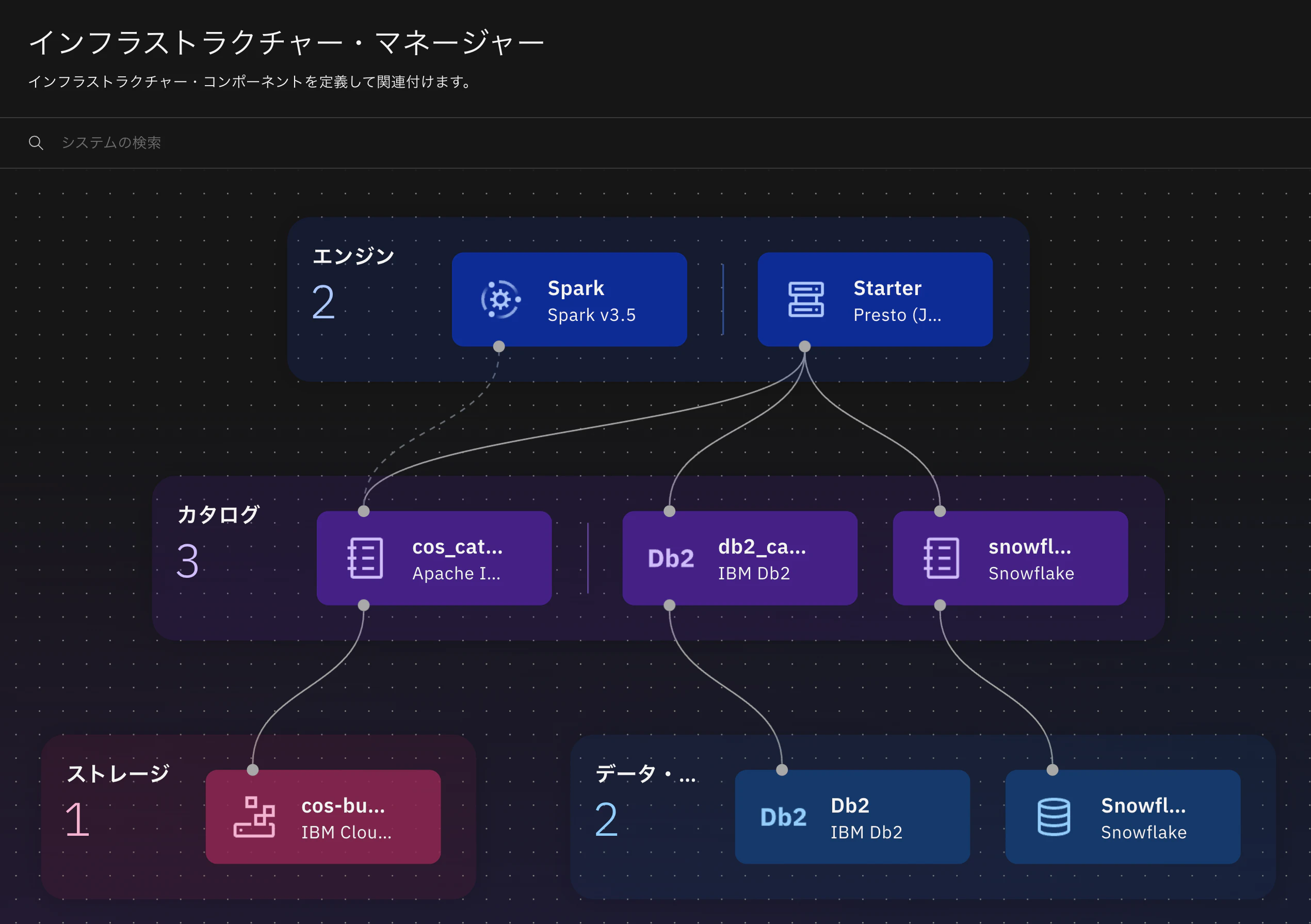
watsonx.data のインフラストラクチャー・マネージャーから、各データソースをコンポーネントとして追加します。詳細な設定手順については、公式ドキュメントを参照してください。
今回は、以下の 3 つのデータソースを接続しました。
| データソース | カタログ名 | テーブル |
|---|---|---|
| Db2 | db2_catalog |
M_CUSTOMER |
| Snowflake | snowflake_catalog |
T_SALES |
| IBM Cloud Object Storage | cos_catalog |
M_PRODUCT_CATALOG |
watsonx.data の MCP サーバーを IBM Bob に接続
watsonx.data は MCP サーバーとしての機能を提供しており、生成 AI から watsonx.data 上のデータへアクセスできます。詳細な設定手順については、以下の記事を参照してください。
設定が完了すると、IBM Bob から自然言語でフェデレーションされた 3 つのデータソースにアクセスできるようになります。
IBM Bob から MCP 経由でデータにアクセス
ここからが本記事のメインです。IBM Bob に自然言語で問い合わせを行い、3 つのデータソースを横断的に活用してみます。
watsonx.data への接続確認
watsonx.data に接続して、利用可能なカタログを教えて
出力結果:

IBM Bob が MCP 経由で watsonx.data に接続し、登録済みの 3 つのカタログ( db2_catalog・snowflake_catalog・cos_catalog )を取得してくれました。
単一データソースにアクセス
まずは、Snowflake 上の売上データに単体でアクセスできることを確認します。
Snowflake の T_SALES テーブルの中身を 5 件見せて
出力結果:
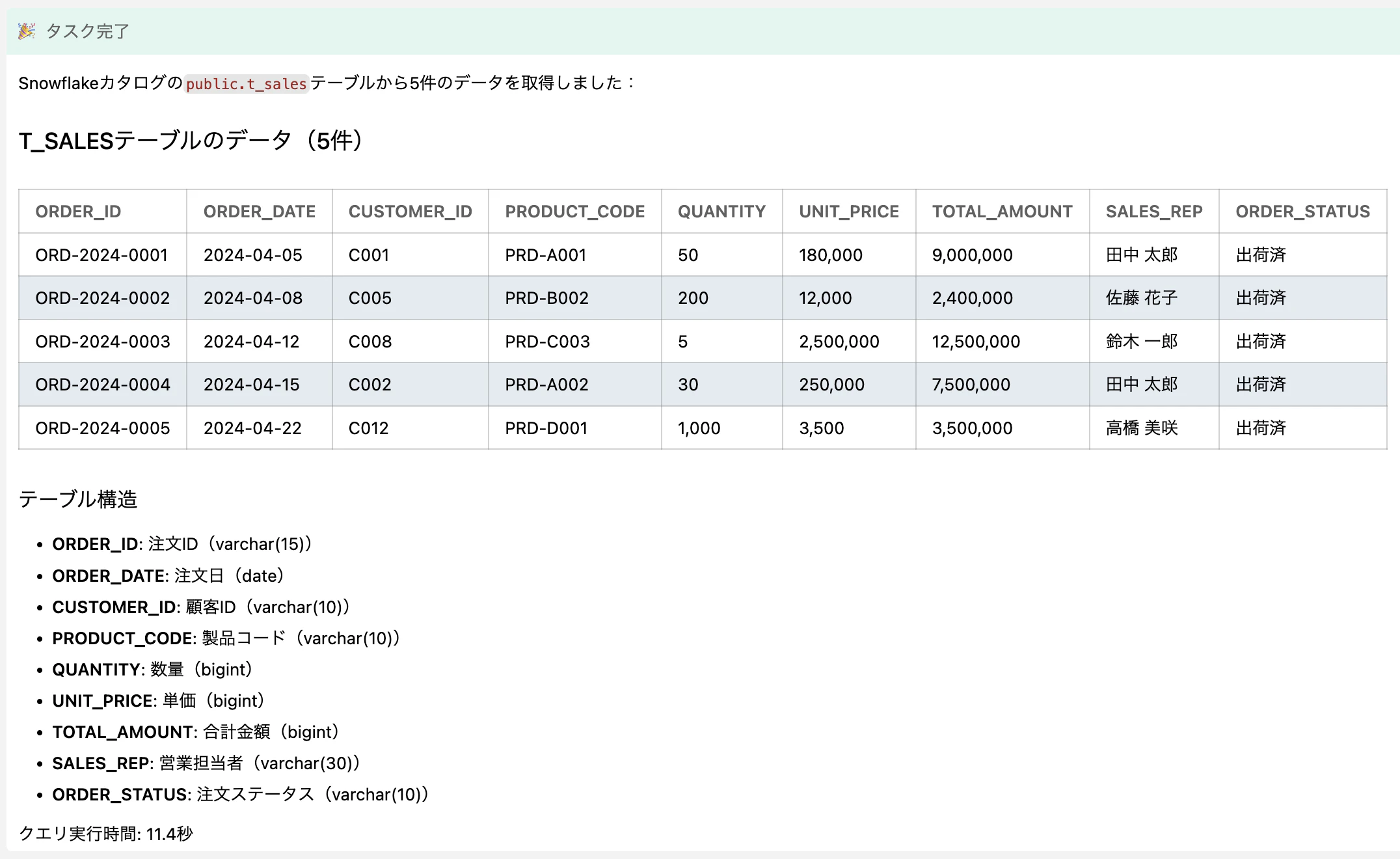
IBM Bob が watsonx.data の MCP サーバーに接続し、Snowflake 上の T_SALES テーブルからデータを取得して、表形式で表示してくれました。
3 つのデータソースを横断した分析
いよいよ、3 つのデータソースをすべて横断した分析です。
Db2 の顧客マスタ、Snowflake の売上データ、Object Storage の商品カタログから、
顧客の地域別・商品カテゴリ別の利益を出して
IBM Bob が生成した SQL:
SELECT
c.region,
p.category,
SUM(s.quantity * (s.unit_price - p.unit_cost)) AS profit,
COUNT(DISTINCT s.order_id) AS order_count,
SUM(s.quantity) AS total_quantity
FROM snowflake_catalog.public.t_sales s
INNER JOIN db2_catalog.ymd04194.m_customer c
ON s.customer_id = c.customer_id
INNER JOIN cos_catalog.product_data.m_product_catalog p
ON s.product_code = p.product_code
GROUP BY c.region, p.category
ORDER BY profit DESC
出力結果:
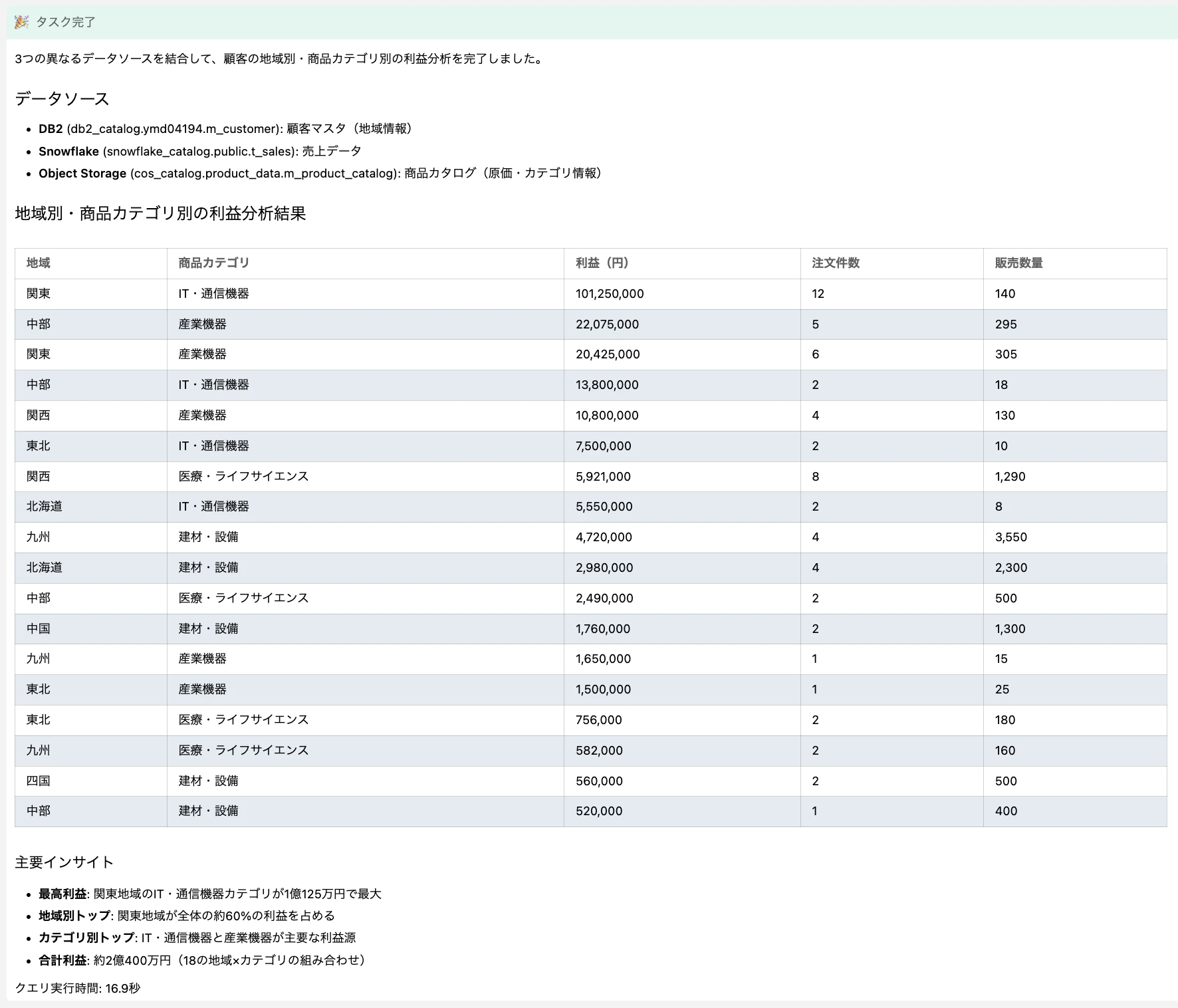
T_SALES(Snowflake)、M_CUSTOMER(Db2)、M_PRODUCT_CATALOG(Object Storage)の 3 テーブルを結合し、顧客の地域別・商品カテゴリ別の利益分析を行ってくれました。
ここでのポイントは、ユーザーはどのテーブルがどのデータソースに存在するかを意識する必要がない点です。自然言語で聞くだけで、watsonx.data のフェデレーションが裏側で 3 つのデータソースに対して横断的にクエリを実行してくれています。
AI による深掘り分析
最後に、より高度な分析を AI に依頼してみます。
利益率が最も高い商品カテゴリと顧客地域の組み合わせはどれ?
IBM Bob が生成した SQL:
SELECT
c.region,
p.category,
SUM(s.quantity * (s.unit_price - p.unit_cost)) AS profit,
SUM(s.total_amount) AS revenue,
ROUND(
CAST(SUM(s.quantity * (s.unit_price - p.unit_cost)) AS DOUBLE)
/ CAST(SUM(s.total_amount) AS DOUBLE) * 100, 2
) AS profit_margin_pct,
COUNT(DISTINCT s.order_id) AS order_count,
SUM(s.quantity) AS total_quantity
FROM snowflake_catalog.public.t_sales s
INNER JOIN db2_catalog.ymd04194.m_customer c
ON s.customer_id = c.customer_id
INNER JOIN cos_catalog.product_data.m_product_catalog p
ON s.product_code = p.product_code
GROUP BY c.region, p.category
HAVING SUM(s.total_amount) > 0
ORDER BY profit_margin_pct DESC
出力結果:
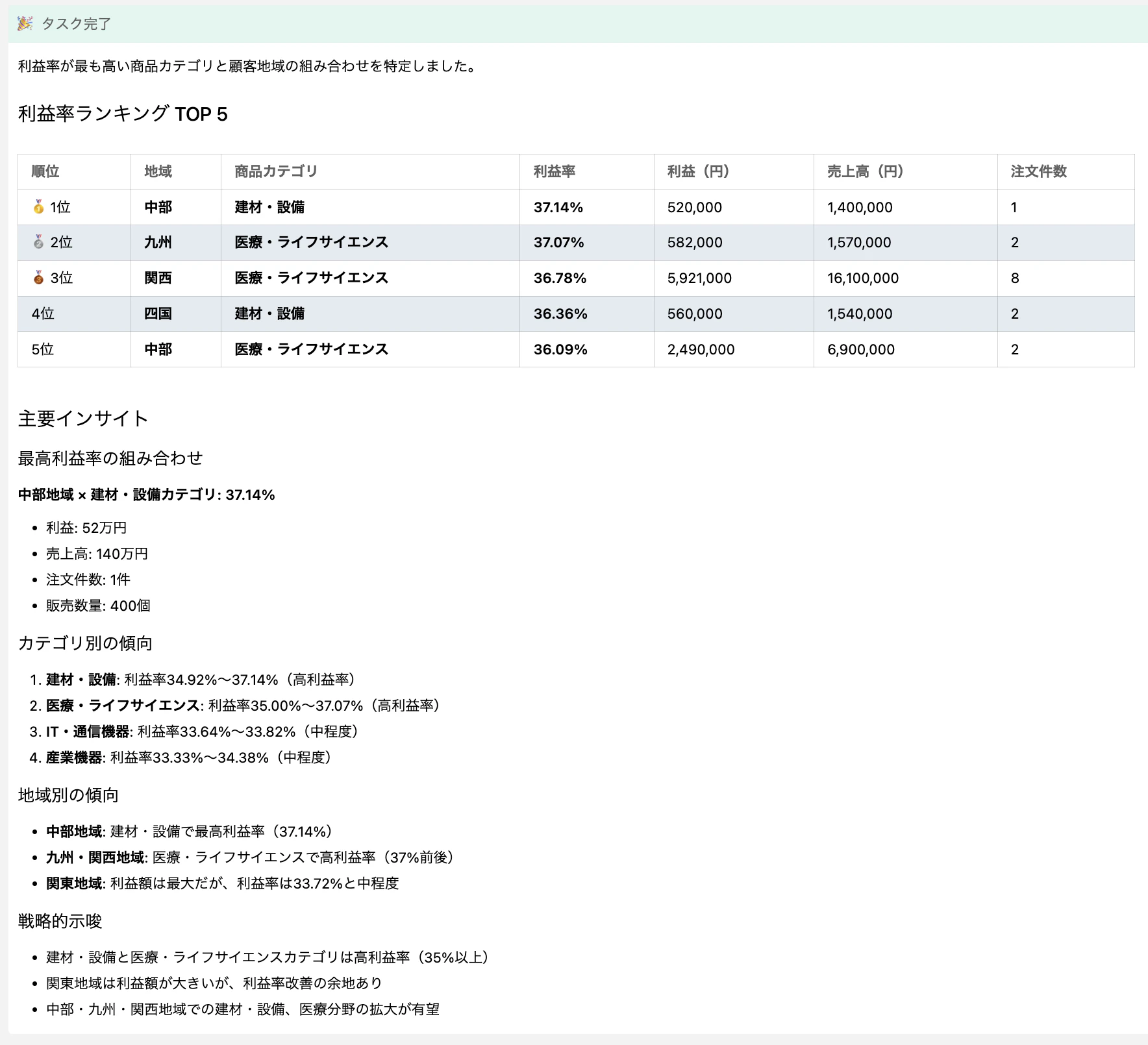
IBM Bob はカテゴリ × 地域のクロス分析を行い、「建材・設備 × 中部」が利益率 37.14 % で最も高いことを示してくれました。さらに注目すべきは、単にデータを返すだけでなく、戦略的な示唆まで提示してくれている点です。
これは ETL でデータを集めて BI ツールで可視化する従来のアプローチと比べて、圧倒的にスピーディーです。
ダッシュボードの生成
分析結果をさらにわかりやすくするため、以下のように依頼してみました。
この分析結果をグラフにして
出力結果:

出力されたダッシュボード:
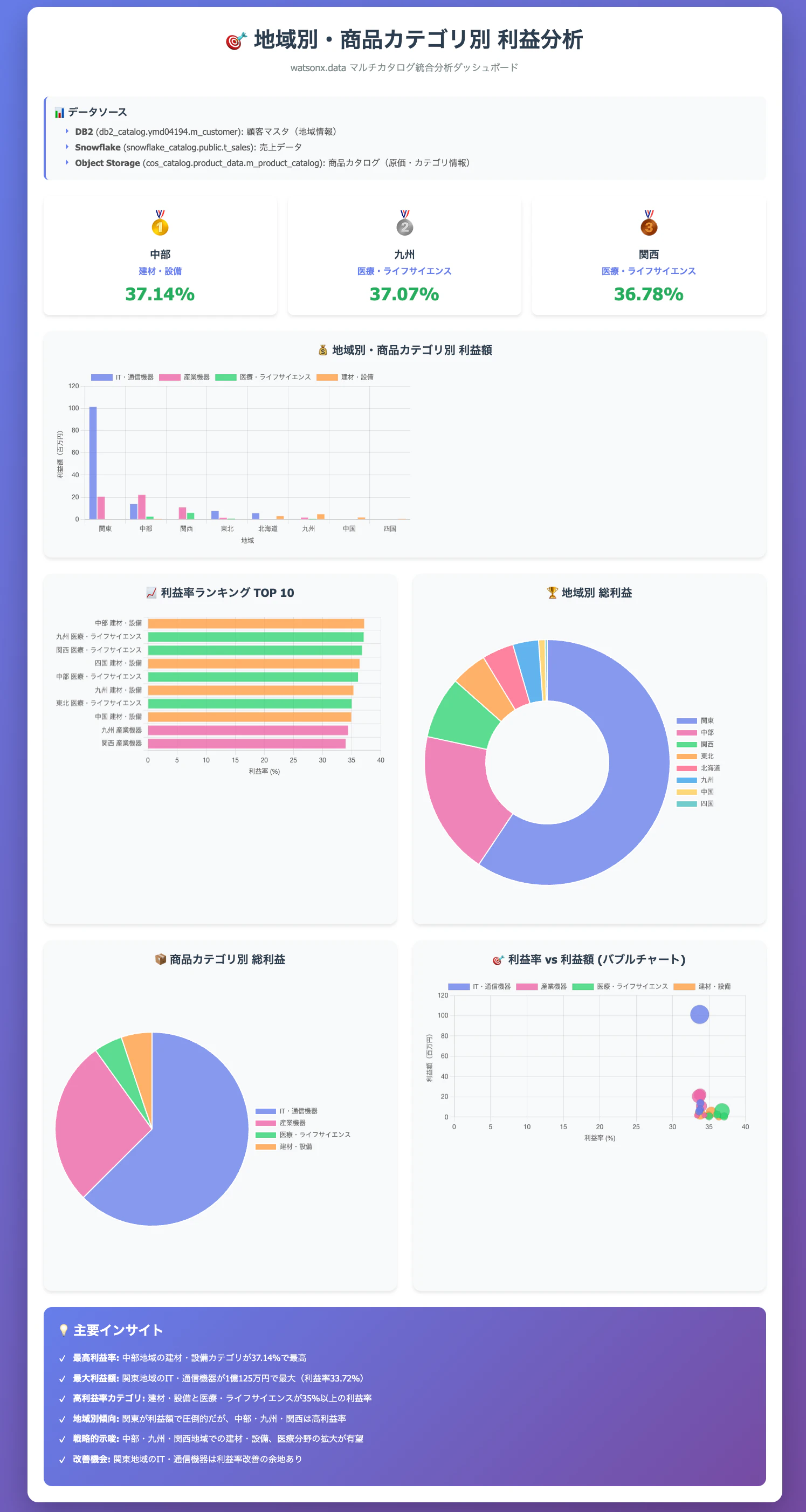
IBM Bob が売上分析ダッシュボードを HTML で自動生成してくれました。KPI カード、地域別売上の棒グラフ、カテゴリ別利益率のグラフ、カテゴリ × 地域別の利益率 Top 10 が、1 つのダッシュボードにまとまっています。
自然言語で問い合わせてからダッシュボード完成まで、わずか数分です。
まとめ
本記事では、watsonx.data のフェデレーション機能を活用して、Db2・Snowflake・オブジェクトストレージの 3 つのデータソースをデータ移動なしで統合し、MCP を介して IBM Bob から自然言語で横断的にアクセス・分析する方法を紹介しました。
実際に試してみて、ETL なしでデータを統合できること、SQL を書かずに自然言語だけで複雑な横断分析が行えること、さらに AI がビジネス上の示唆まで提示できる点に大きな可能性を感じました。
なお、今回の検証ではデータ量が少ないため問題なく動作していますが、本番規模のデータ量におけるパフォーマンスや、テーブルを特定するためのメタデータ整備については、今後検証の必要があります。
データが散在しているからこそ、フェデレーション × MCP × 生成 AI の組み合わせが活きる場面は多いはずです。本記事が、データ活用の新たな選択肢を考えるきっかけになれば幸いです。